
Wenn neuronale Netze jetzt überall Entscheidungen treffen, von Code-Editoren bis hin zu Sicherheitssystemen, wie können wir dann tatsächlich die spezifischen Schaltkreise im Inneren sehen, die jedes Verhalten steuern? OpenAI hat eine neue mechanistische Interpretierbarkeit eingeführt Forschungsstudie Dadurch werden Sprachmodelle darauf trainiert, eine spärliche interne Verkabelung zu verwenden, sodass das Modellverhalten mithilfe kleiner, expliziter Schaltkreise erklärt werden kann.
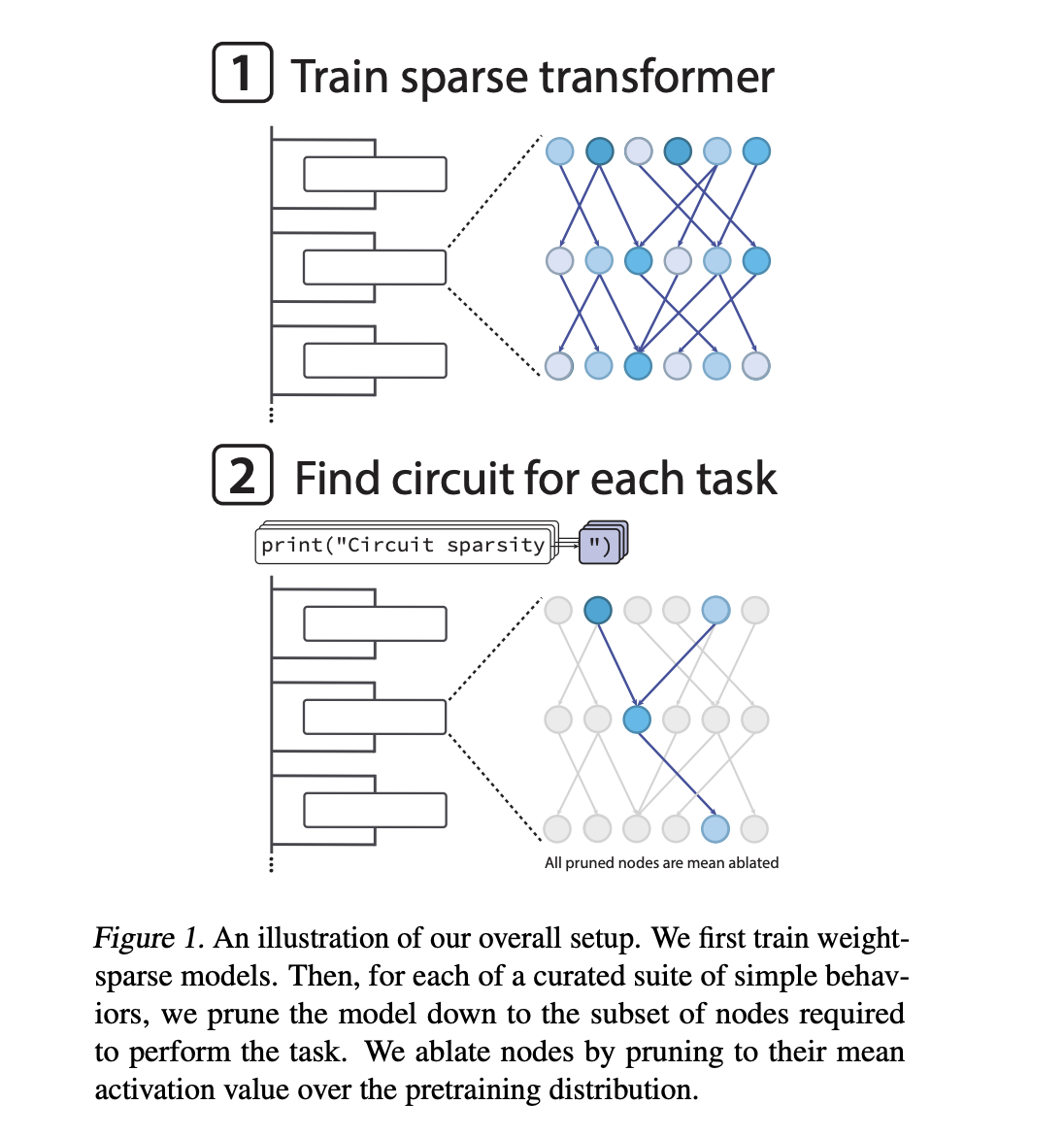
Trainieren Sie Transformatoren so, dass sie gewichtsarm sind
Die meisten Transformer-Sprachmodelle sind dicht. Jedes Neuron liest aus vielen Restkanälen und schreibt in diese, und Merkmale sind häufig überlagert. Dies erschwert die Analyse auf Schaltungsebene. In früheren OpenAI-Arbeiten wurde versucht, mithilfe von Sparse-Autoencodern spärliche Funktionsbasen auf dichten Modellen zu erlernen. Die neue Forschungsarbeit ändert stattdessen das Basismodell, sodass der Transformator selbst gewichtsärmer ist.
Das OpenAI-Crew trainiert reine Decoder-Transformatoren mit einer GPT 2-ähnlichen Architektur. Nach jedem Optimierungsschritt mit dem AdamW-Optimierer erzwingen sie einen festen Sparsity-Stage für jede Gewichtsmatrix und jeden Bias, einschließlich Token-Einbettungen. Es werden nur die größten Magnitudeneinträge in jeder Matrix beibehalten. Der Relaxation wird auf Null gesetzt. Während des Trainings verringert ein Glühplan schrittweise den Anteil der Parameter ungleich Null, bis das Modell eine Zielsparsity erreicht.
Im extremsten Fall ist etwa 1 von 1000 Gewichtungen ungleich Null. Auch die Aktivierungen sind etwas spärlich. Etwa jede vierte Aktivierung ist an einem typischen Knotenstandort ungleich Null. Der effektive Konnektivitätsgraph ist daher selbst bei großer Modellbreite sehr dünn. Dies fördert entwirrte Funktionen, die sauber auf die von der Schaltung verwendeten Restkanäle abgebildet werden.
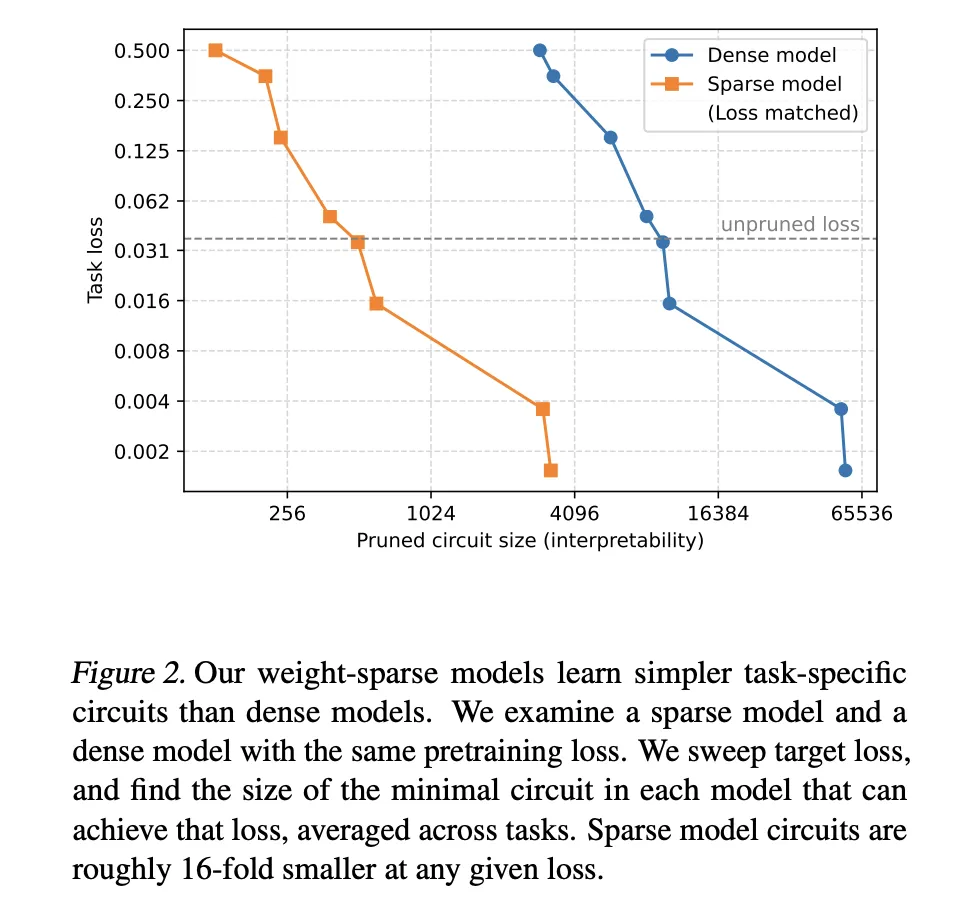
Messung der Interpretierbarkeit durch aufgabenspezifisches Bereinigen
Um zu quantifizieren, ob diese Modelle leichter zu verstehen sind, verlässt sich das OpenAI-Crew nicht nur auf qualitative Beispiele. Das Forschungsteam definiert eine Reihe einfacher algorithmischer Aufgaben, die auf der Vorhersage des nächsten Tokens in Python basieren. Ein Beispiel, single_double_quote, erfordert, dass das Modell einen Python-String mit dem richtigen Anführungszeichen schließt. Ein weiteres Beispiel, set_or_string, erfordert, dass das Modell zwischen .add und += wählt, je nachdem, ob eine Variable als Set oder String initialisiert wurde.
Für jede Aufgabe suchen sie nach dem kleinsten Teilnetz, einem sogenannten Circuit, das die Aufgabe bis zu einem festen Verlustschwellenwert noch ausführen kann. Die Beschneidung erfolgt knotenbasiert. Ein Knoten ist ein MLP-Neuron auf einer bestimmten Schicht, ein Aufmerksamkeitskopf oder ein Reststromkanal auf einer bestimmten Schicht. Wenn ein Knoten bereinigt wird, wird seine Aktivierung durch seinen Mittelwert über die Verteilung vor dem Coaching ersetzt. Das ist mittlere Ablation.
Die Suche verwendet kontinuierliche Maskenparameter für jeden Knoten und ein Heaviside-Gate, optimiert mit einem Straight-By way of-Schätzer wie einem Ersatzgradienten. Die Komplexität einer Schaltung wird als Anzahl der aktiven Kanten zwischen beibehaltenen Knoten gemessen. Die wichtigste Interpretierbarkeitsmetrik ist das geometrische Mittel der Kantenzählungen über alle Aufgaben hinweg.
Beispielschaltungen in Sparse-Transformatoren
Bei der Aufgabe „single_double_quote“ ergeben die spärlichen Modelle eine kompakte und vollständig interpretierbare Schaltung. In einer frühen MLP-Schicht fungiert ein Neuron als Anführungszeichendetektor, der sowohl bei einfachen als auch bei doppelten Anführungszeichen aktiviert wird. Ein zweites Neuron fungiert als Klassifikator für den Angebotstyp, der die beiden Angebotstypen unterscheidet. Später verwendet ein Aufmerksamkeitskopf diese Signale, um zur Eröffnungskursposition zurückzukehren und deren Typ in die Schlussposition zu kopieren.
In Bezug auf Schaltkreisgraphen verwendet der Mechanismus fünf Restkanäle, zwei MLP-Neuronen in Schicht 0 und einen Aufmerksamkeitskopf in einer späteren Schicht mit einem einzigen relevanten Abfrageschlüsselkanal und einem einzelnen Wertkanal. Wenn der Relaxation des Modells abgetragen wird, löst dieser Untergraph immer noch die Aufgabe. Wenn diese wenigen Kanten entfernt werden, versagt das Modell bei der Aufgabe. Die Schaltung ist daher sowohl ausreichend als auch notwendig im betrieblichen Sinne, wie er in der Arbeit definiert wird.

Bei komplexeren Verhaltensweisen, etwa der Typverfolgung einer Variablen mit dem Namen „Strom“ innerhalb eines Funktionskörpers, sind die wiederhergestellten Schaltkreise größer und nur teilweise verstanden. Das Forschungsteam zeigt ein Beispiel, bei dem eine Aufmerksamkeitsoperation den Variablennamen bei der Definition in das Token set() schreibt und eine andere Aufmerksamkeitsoperation später die Typinformationen von diesem Token zurück in eine spätere Verwendung von present kopiert. Dies ergibt immer noch einen relativ kleinen Schaltkreisgraphen.
Wichtige Erkenntnisse
- Konstruktionsbedingt gewichtsarme Transformatoren: OpenAI trainiert ausschließlich GPT-2-Decoder-Transformatoren, sodass quick alle Gewichte Null sind, etwa 1 von 1000 Gewichten ungleich Null ist, wodurch Sparsity über alle Gewichte und Bias hinweg, einschließlich Token-Einbettungen, erzwungen wird, was zu dünnen Konnektivitätsdiagrammen führt, die strukturell einfacher zu analysieren sind.
- Die Interpretierbarkeit wird als minimale Schaltungsgröße gemessen: Die Arbeit definiert einen Benchmark für einfache Python-Subsequent-Token-Aufgaben und sucht für jede Aufgabe nach dem kleinsten Teilnetzwerk in Bezug auf aktive Kanten zwischen Knoten, das noch einen festen Verlust erreicht, indem es Knotenebenenbereinigung mit Mittelwertablation und eine direkte Maskenoptimierung im Estimator-Stil verwendet.
- Es entstehen konkrete, vollständig rückentwickelte Schaltkreise: Bei Aufgaben wie der Vorhersage passender Anführungszeichen liefert das spärliche Modell einen kompakten Schaltkreis mit einigen Restkanälen, zwei wichtigen MLP-Neuronen und einem Aufmerksamkeitskopf, den die Autoren vollständig zurückentwickeln und als ausreichend und notwendig für das Verhalten verifizieren können.
- Sparsity liefert viel kleinere Schaltkreise mit fester Kapazität: Bei angepassten Verlustniveaus vor dem Coaching erfordern gewichtssparse Modelle Schaltkreise, die etwa 16-mal kleiner sind als die aus dichten Basislinien wiederhergestellten. Dies definiert eine Fähigkeitsinterpretierbarkeitsgrenze, bei der eine erhöhte Sparsity die Interpretierbarkeit verbessert und gleichzeitig die Rohkapazität leicht verringert.
Die Arbeit von OpenAI an gewichtsarmen Transformatoren ist ein pragmatischer Schritt, um die mechanistische Interpretierbarkeit in die Praxis umzusetzen. Durch die Durchsetzung der Sparsität direkt im Basismodell verwandelt das Papier abstrakte Diskussionen über Schaltkreise in konkrete Diagramme mit messbaren Kantenzahlen, klaren Notwendigkeits- und Hinlänglichkeitstests und reproduzierbaren Benchmarks für Python-Subsequent-Token-Aufgaben. Die Modelle sind klein und ineffizient, aber die Methodik ist für zukünftige Sicherheitsaudits und Debugging-Workflows related. Diese Forschung behandelt Interpretierbarkeit als eine erstklassige Designbeschränkung und nicht als eine nachträgliche Diagnose.
Schauen Sie sich das an Papier, GitHub-Repo Und Technische Particulars. Schauen Sie sich gerne bei uns um GitHub-Seite für Tutorials, Codes und Notebooks. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.

Michal Sutter ist ein Information-Science-Experte mit einem Grasp of Science in Information Science von der Universität Padua. Mit einer soliden Grundlage in statistischer Analyse, maschinellem Lernen und Datentechnik ist Michal hervorragend darin, komplexe Datensätze in umsetzbare Erkenntnisse umzuwandeln.