Große Sprachmodelle (LLMs) stehen jetzt im Zentrum unzähliger KI -Durchbrüche – Chatbots, Codierungsassistenten, Fragen zum Beantworten, kreatives Schreiben und vieles mehr. Aber trotz ihrer Fähigkeiten bleiben sie Staatellos: Jede Abfrage kommt ohne Erinnerung an das, was zuvor kam. Ihre fest Kontextfenster bedeuten, dass sie nicht anhaltendes Wissen über lange Gespräche oder Aufgaben mit mehreren Sitzungen ansammeln können, und sie haben Schwierigkeiten, über komplexe Geschichten zu argumentieren. Jüngste Lösungen wie Abruf-Era (RAG) fügen vergangene Informationen an Auffordern hinzu, aber dies führt häufig zu lautem, ungefiltertem Kontext-das Modell mit zu viel irrelevante Particulars oder fehlende entscheidende Fakten.
Ein Forscherteam der Universität von München, Technische Universität von München, Universität von Cambridge und College of Hong Kong eingeführt Reminiscence-R1ein Rahmen, der LLM -Agenten lehrt, zu entscheiden, woran er sich erinnern und wie man es benutzt. Sein LLM -Agent lernt es zu aktiv verwalten und nutzen externe Speicher– Entfernen Sie, was bei der Beantwortung von Fragen das Hinzufügen, Aktualisieren, Löschen oder Ignorieren und -filterung durchführen und herausfiltern. Der Durchbruch? Es trainiert diese Verhaltensweisen mit Verstärkungslernen (RL)mit nur ergebnisbasierten Belohnungen, daher benötigt es minimale Aufsicht und verallgemeinert sich strong über Modelle und Aufgaben hinweg.
Aber warum LLMs mit dem Gedächtnis zu kämpfen haben?
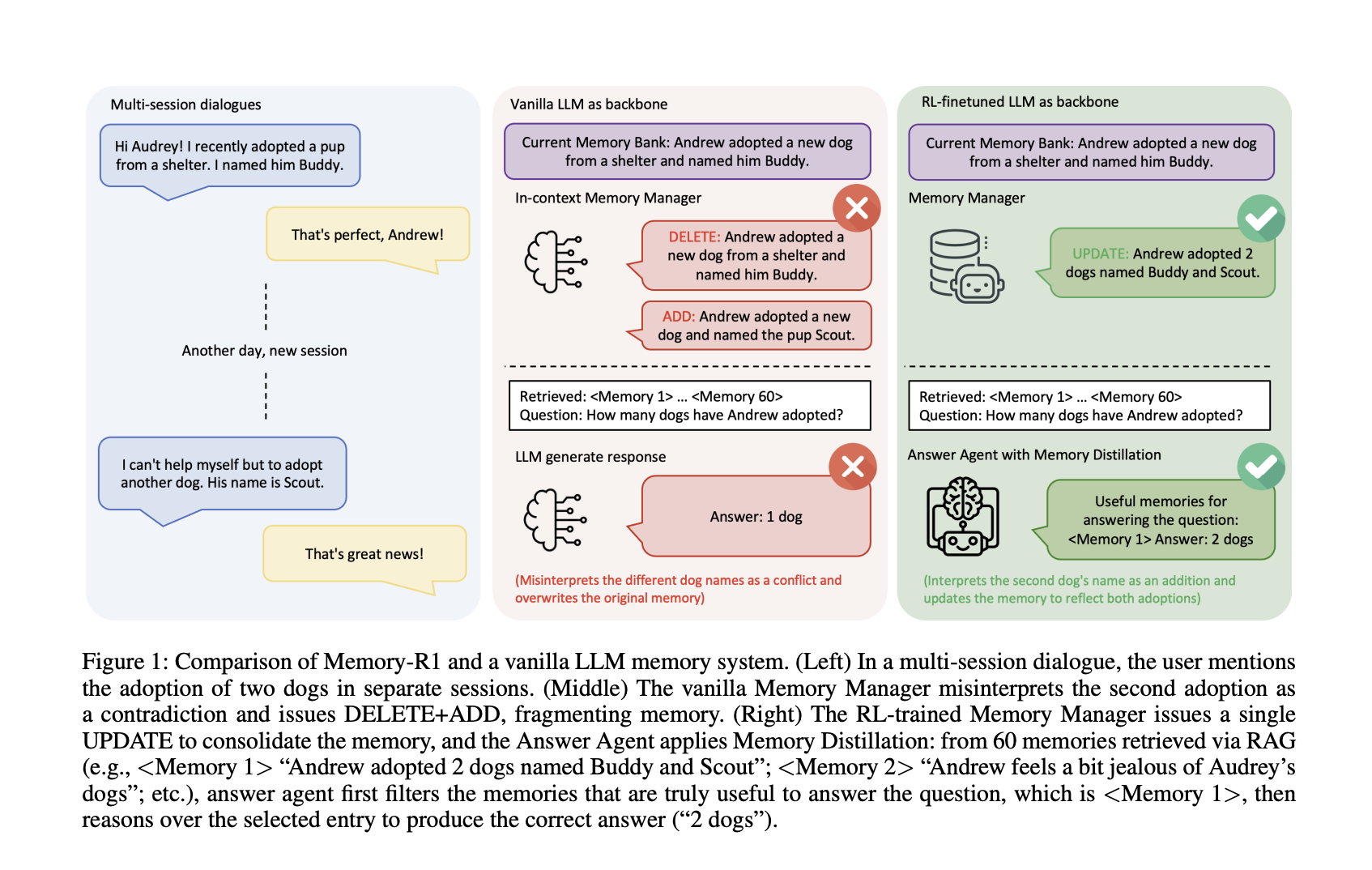
Stellen Sie sich ein Gespräch mit mehreren Sitzungen vor: In der ersten Sitzung sagt ein Benutzer: „Ich habe einen Hund namens Buddy adoptiert.“ Später fügen sie hinzu: „Ich habe einen anderen Hund namens Scout adoptiert.“ Sollte das System ersetzen die erste Aussage mit der zweiten, verschmelzen sie, oder ignorieren Das Replace? Vanilla Reminiscence Pipelines scheitern oft – sie könnten „Kumpel“ löschen und „Scout“ hinzufügen, wodurch die neuen Informationen eher als Widerspruch als als Konsolidierung interpretiert werden. Im Laufe der Zeit verlieren solche Systeme Kohärenz und Fragmentierung des Benutzerwissens, anstatt es weiterzuentwickeln.
Lappensysteme Informationen abrufen, aber filtern Sie sie nicht: Irrelevante Einträge verschmutzen das Denken, und das Modell wird durch Rauschen abgelenkt. Menschenim Gegensatz dazu dringend abrufen, aber dann selektiv filtern Was zählt. Die meisten KI -Speichersysteme sind statischstützt sich auf handgefertigte Heuristiken, um sich zu erinnern, anstatt aus Suggestions zu lernen.
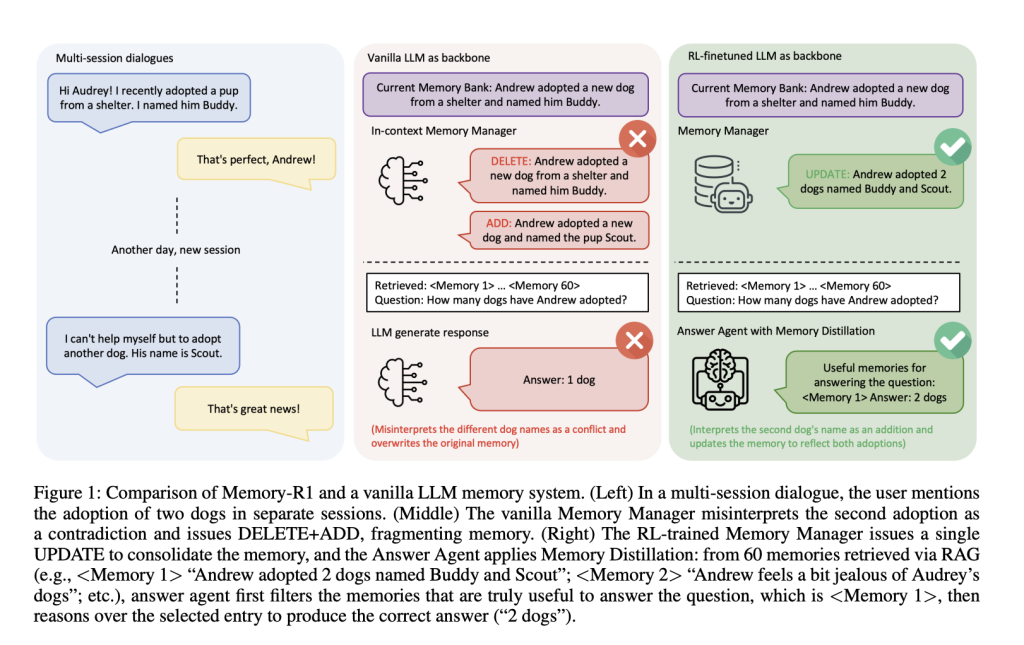
Das Reminiscence-R1-Framework
Reminiscence-R1 ist umgebaut Zwei spezialisierte, RL-Fantastic-abgestimmte Agenten:
- Speichermanager: Entscheidet, welche Speicheroperationen (HINZUFÜGENAnwesend AKTUALISIERENAnwesend LÖSCHENAnwesend Noop) Um nach jedem Dialog abzubauen, aktualisieren Sie die externe Speicherbank dynamisch.
- Antwortagent: Für jede Benutzerfrage ruft bis zu 60 Kandidatenerinnerungen ab. Destills Sie an die relevanteste Teilmenge, dann Gründe für diesen gefilterten Kontext, um eine Antwort zu generieren.
Beide Komponenten sind Ausgebildet mit Verstärkungslernen RL– entweder proximale Richtlinienoptimierung (PPO) oder Gruppenrelationsrichtlinienoptimierung (GRPO) – mit Nur Frage-Antwort-Korrektheit als Belohnungssignal. Dies bedeutet, dass die Agenten, anstatt manuell gekennzeichnete Speichervorgänge zu erfordern, durch Versuch und Irrtum lern endgültige Aufgabenleistung.
Reminiscence Supervisor: Lernen, Wissen zu bearbeiten
Nach jedem Dialog wechselt ein LLM wichtige Fakten. Der Speichermanager Ruft dann verwandte Einträge aus der Speicherbank ab und wählt einen Vorgang aus:
- HINZUFÜGEN: Fügen Sie neue Informationen vor, die noch nicht vorhanden sind.
- AKTUALISIEREN: Führen Sie neue Particulars in vorhandene Erinnerungen zusammen, wenn sie frühere Fakten ausarbeiten oder verfeinern.
- LÖSCHEN: Entfernen Sie veraltete oder widersprüchliche Informationen.
- Noop: Lassen Sie den Speicher unverändert, wenn nichts Relevantes hinzugefügt wird.
Ausbildung: Der Speichermanager wird basierend auf der Qualität der Antworten aktualisiert, die der Antwortagent aus der neu bearbeiteten Speicherbank generiert. Wenn ein Speichervorgang es dem Antwortagenten ermöglicht, genau zu antworten, erhält der Speichermanager eine optimistic Belohnung. Das ergebnisorientierte Belohnung Beseitigt die Notwendigkeit einer kostspieligen manuellen Annotation der Speichervorgänge.
Beispiel: Wenn ein Benutzer zum ersten Mal erwähnt, einen Hund namens Buddy zu adoptieren, fügt später hinzu, dass er einen anderen Hund namens Scout adoptiert hat, ein Vanillesystem könnte „Buddy“ löschen und „Scout“ hinzufügen und ihn als Widerspruch behandeln. Der RL-ausgebildete Speichermanager jedoch, Aktualisierungen Die Erinnerung: „Andrew adoptierte zwei Hunde, Buddy und Scout“ und behielt eine kohärente, sich entwickelnde Wissensbasis bei.
Ablation: RL Fantastic-Tuning verbessert die Speicherverwaltung erheblich-PPO und GRPO übertreffen sowohl heuristische Supervisor in Kontext. Das System lernt zu konsolidieren statt Fragment Wissen.
Antwortagent: Selektive Argumentation
Für jede Frage das System Ruft bis zu 60 Kandidatenerinnerungen ab mit Lappen. Aber anstatt all dies an die LLM zu füttern, die Antwortagent Erste Destills Das Set – nur die relevantesten Einträge aufbewahren. Nur dann erzeugt es eine Antwort.
Ausbildung: Der Antwortagent wird auch mit RL ausgebildet, wobei das verwendet wird genaue Übereinstimmung Zwischen seiner Antwort und der goldenen Antwort als Belohnung. Dies ermutigt es, sich darauf zu konzentrieren Lärm herausfiltern Und Argumentation über einen qualitativ hochwertigen Kontext.
Beispiel: Fragte: „Lebt John in der Nähe eines Strandes oder der Berge?“, Eine Vanille -LLM könnte „Berge“ ausgeben, die von irrelevanten Erinnerungen beeinflusst werden. Antwortagent von Reminiscence-R1 jedoch, Oberflächen nur Strandbezogene Einträge Vor der Antwort, was zu einer korrekten „Strand“ -Anantwort führt.
Ablation: RL-Feinabstimmung verbessert die Antwortqualität gegenüber dem statischen Abruf. Speicherdestillation (filtern irrelevante Erinnerungen heraus) steigert die Leistung weiter. Die Gewinne sind gleichmäßig größer mit einem stärkeren Speichermanagerzeigen Verbesserungen mit Verbesserungen.
Trainingsdateneffizienz
Reminiscence-R1 ist dateneffizient: Es erzielt starke Ergebnisse mit nur mit 152 Frage-Antwort-Paare zum Coaching. Dies ist möglich, weil der Agent von lernt Ergebnissenicht aus Tausenden von handgefertigten Speicheroperationen. Die Überwachung wird auf ein Minimal gehalten und das System skaliert zu großen, realen Dialoggeschichten.
Der LOCOMO -Benchmarkverwendet zur Bewertung, besteht aus Multi-Flip-Dialogen (ca. 600 Kurven professional Dialog, im Durchschnitt 26.000 Token) und zugehörige QA Lengthy-Horizon Reminiscence Administration.
Experimentelle Ergebnisse
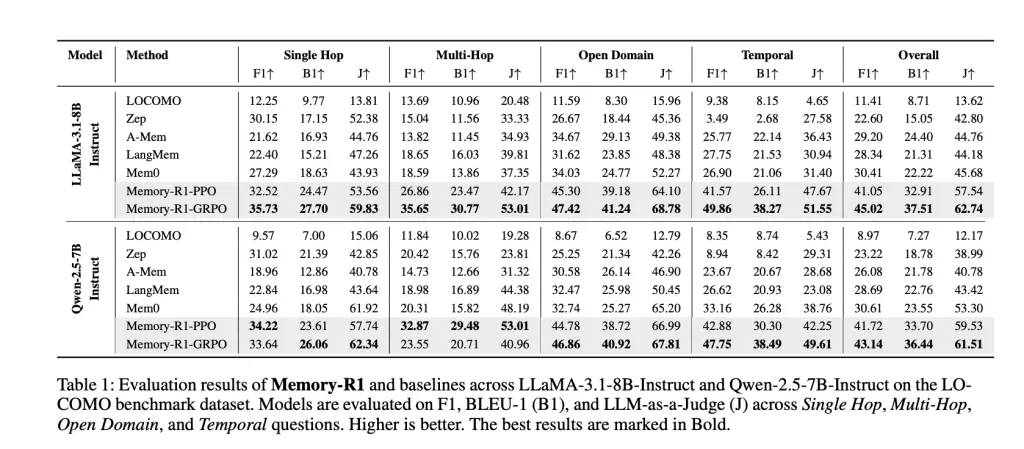
Reminiscence-R1 wurde auf getestet LAMA-3.1-8B-ISTRUCT Und Qwen-2.5-7b-Instruktur Backbones gegen wettbewerbsfähige Baselines (Lokomo, ZEP, A-MEM, Langmem, Mem0). Die wichtigsten Metriken sind:
- F1: Misst sich überlappen zwischen vorhergesagten und korrekten Antworten.
- Bleu-1: Erfasst die lexikalische Ähnlichkeit auf Unigrammebene.
- LLM-A-A-A-Choose: Verwendet ein separates LLM, um die sachliche Genauigkeit, Relevanz und Vollständigkeit zu bewerten – a Proxy für menschliches Urteil.
Ergebnisse: Meseria-r1-grpo erreicht die Beste GesamtleistungVerbesserung gegenüber MEM0 (die bisher beste Grundlinie) um 48% in F1, 69% in BLEU-1 und 37% in LLM-as-a-Choose auf LAMA-3,1-8B. Ähnliche Gewinne sind auf Qwen-2.5-7b zu sehen. Die Verbesserungen sind breitbasiertüber alle Fragetypen und verallgemeinern über Modellarchitekturen.
Warum ist das wichtig
Reminiscence-R1 zeigt das Speicherverwaltung und -nutzung können gelernt werden– Die Agenten müssen sich nicht auf spröde Heuristiken verlassen. Durch die Erde Entscheidungen in ergebnisorientiertem RL, das System:
- Konsolidiert automatisch das Wissen Wenn sich Gespräche entwickeln, anstatt sie zu fragmentieren oder zu überschreiben.
- Filtert Geräusche Bei der Beantwortung, Verbesserung der sachlichen Genauigkeit und der Argumentationsqualität.
- Lernt effizient mit wenig Aufsicht und Waage Zu den realen Langzeitaufgaben.
- Verallgemeinert über Modelle hinwegwas es zu einer vielversprechenden Grundlage für die nächste Era von agenten-, Gedächtnisbewusstsein-KI-Systemen macht.
Abschluss
Reminiscence-R1 Unshackles LLM-Agenten von ihren staatenlosen Einschränkungen und geben ihnen die Möglichkeit zu lernen-durch Verstärkung-, wie man langfristige Erinnerungen effektiv verwalten und nutzt. Durch Rahmung Speichervorgänge und Filterung als RL -Problemees erreicht Hochmoderne Leistung mit Minimale Aufsicht Und Starke Verallgemeinerung. Dies markiert einen wichtigen Schritt in Richtung KI -Systeme, die sich nicht nur fließend unterhalten, sondern auch wie Menschen lernt und vermitteln – um reichhaltigere, anhaltendere und nützlichere Erlebnisse für Benutzer überall zu finden.
FAQs
FAQ 1: Was macht Reminiscence-R1 besser als typische LLM-Speichersysteme?
Reminiscence-R1 verwendet das Verstärkungslernen, um das Gedächtnis aktiv zu steuern, um zu entscheiden, welche Informationen hinzugefügt, aktualisiert, löschen oder behalten werden-die intelligentere Konsolidierung und weniger Fragmentierung als statische, heuristische Ansätze anbieten.
FAQ 2: Wie verbessert Reminiscence-R1 die Antwortqualität aus langen Dialoggeschichten?
Der Antwortagent wendet eine „Speicherdestillation“ -Richtlinie an: Es filtert bis zu 60 errungene Erinnerungen, um nur die für jede Frage am relevantesten zu finden, um das Rauschen zu verringern und die sachliche Genauigkeit zu verbessern, verglichen mit einfachem Kontext an das Modell.
FAQ 3: Ist Reminiscence-R1 dateneffizient für das Coaching?
Ja, Reminiscence-R1 erzielt hochmoderne Gewinne mit nur 152 QA-Trainingspaaren, da die ergebnisbasierten RL-Belohnungen die Notwendigkeit einer kostspieligen manuellen Annotation der einzelnen Speichervorgänge beseitigen.
Schauen Sie sich das an Papier hier. Fühlen Sie sich frei, unsere zu überprüfen Github -Seite für Tutorials, Codes und Notizbücher. Fühlen Sie sich auch frei, uns zu folgen Twitter Und vergessen Sie nicht, sich unserer anzuschließen 100k+ ml Subreddit und abonnieren Unser Publication.
Asif Razzaq ist der CEO von Marktechpost Media Inc. Sein jüngstes Bestreben ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch die ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die von einem breiten Publikum technisch intestine und leicht verständlich sind. Die Plattform verfügt über über 2 Millionen monatliche Ansichten und veranschaulicht ihre Beliebtheit des Publikums.