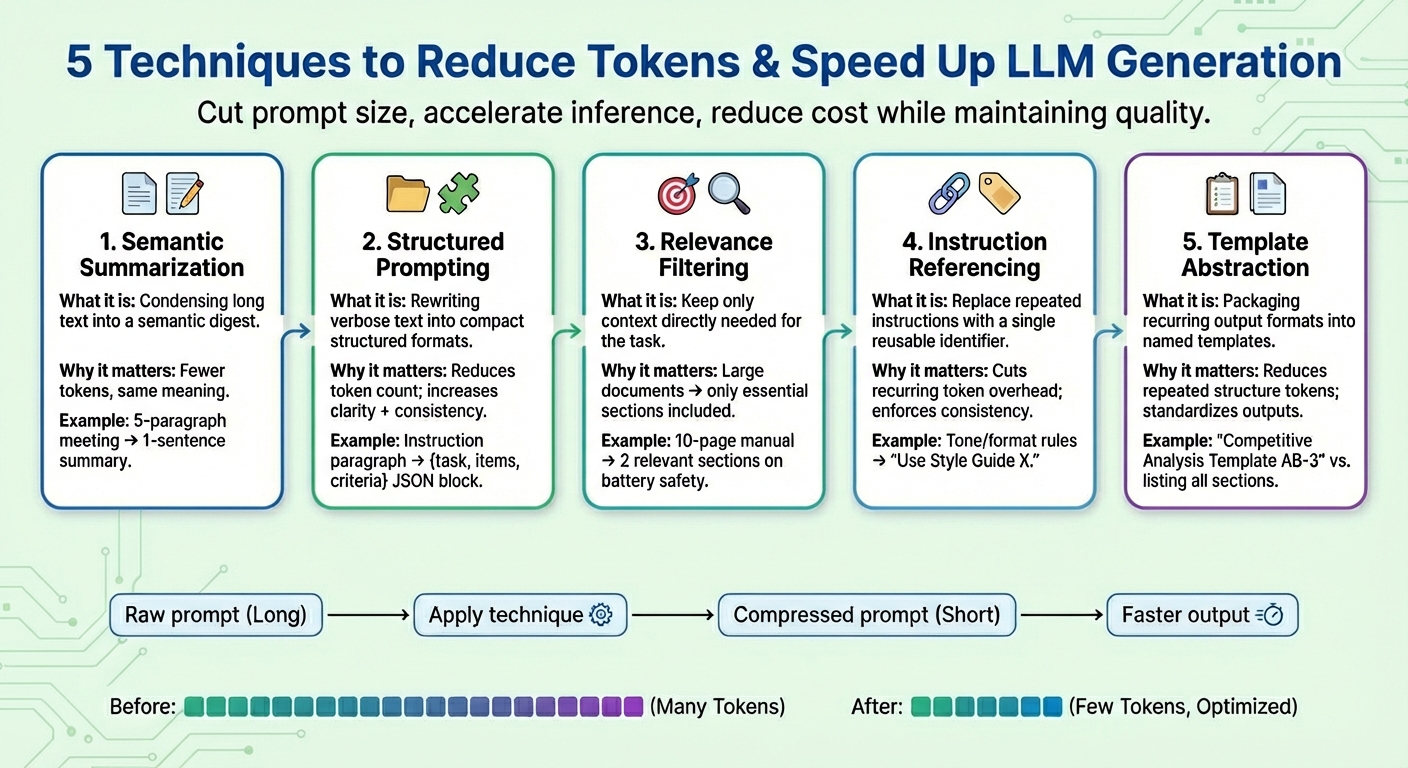
In diesem Artikel lernen Sie fünf praktische Immediate-Komprimierungstechniken kennen, die Token reduzieren und die Generierung großer Sprachmodelle (LLM) beschleunigen, ohne die Aufgabenqualität zu beeinträchtigen.
Zu den Themen, die wir behandeln werden, gehören:
- Was semantische Zusammenfassung ist und wann man sie verwendet
- Wie strukturierte Eingabeaufforderungen, Relevanzfilterung und Anweisungsreferenzierung die Anzahl der Token verringern
- Wo die Vorlagenabstraktion passt und wie man sie konsequent anwendet
Lassen Sie uns diese Techniken erkunden.
Schnelle Komprimierung zur Optimierung der LLM-Generierung und Kostensenkung
Bild vom Herausgeber
Einführung
Große Sprachmodelle (LLMs) werden hauptsächlich darauf trainiert, Textantworten auf Benutzeranfragen oder -aufforderungen zu generieren. Unter der Haube steckt eine komplexe Argumentation, die nicht nur die Sprachgenerierung durch Vorhersage jedes nächsten Tokens in der Ausgabesequenz beinhaltet, sondern auch ein tiefes Verständnis der linguistischen Muster rund um den Benutzereingabetext erfordert.
Schnelle Komprimierung Techniken sind ein Forschungsthema, das in letzter Zeit in der gesamten LLM-Landschaft an Aufmerksamkeit gewonnen hat, da langsame, zeitaufwändige Schlussfolgerungen, die durch größere Benutzeraufforderungen und Kontextfenster verursacht werden, entschärft werden müssen. Diese Techniken sollen dazu beitragen, die Token-Nutzung zu verringern, die Token-Generierung zu beschleunigen und die Gesamtrechenkosten zu senken, während gleichzeitig die Qualität des Aufgabenergebnisses so weit wie möglich erhalten bleibt.
In diesem Artikel werden fünf häufig verwendete Immediate-Komprimierungstechniken vorgestellt und beschrieben, um die LLM-Generierung in anspruchsvollen Szenarien zu beschleunigen.
1. Semantische Zusammenfassung
Bei der semantischen Zusammenfassung handelt es sich um eine Technik, die lange oder sich wiederholende Inhalte zu einer prägnanteren Model zusammenfasst und dabei ihre wesentliche Semantik beibehält. Anstatt die gesamten Gesprächs- oder Textdokumente iterativ in das Modell einzuspeisen, wird ein Digest übergeben, der nur das Wesentliche enthält. Das Ergebnis: Die Anzahl der Eingabe-Tokens, die das Modell „lesen“ muss, wird geringer, wodurch der Prozess der nächsten Token-Generierung beschleunigt und die Kosten gesenkt werden, ohne dass wichtige Informationen verloren gehen.
Stellen Sie sich einen langen Eingabeaufforderungskontext vor, der aus Besprechungsprotokollen besteht, etwa „In der gestrigen Sitzung überprüfte Iván die Quartalszahlen…“, wobei bis zu fünf Absätze zusammengefasst werden. Nach der semantischen Zusammenfassung könnte der verkürzte Kontext wie folgt aussehen: „Zusammenfassung: Iván überprüfte die Quartalszahlen, wies auf einen Umsatzrückgang im vierten Quartal hin und schlug Maßnahmen zur Kosteneinsparung vor.”
2. Strukturierte (JSON) Eingabeaufforderung
Bei dieser Technik geht es darum, lange, fließende Textinformationen in kompakten, halbstrukturierten Formaten wie JSON (d. h. Schlüssel-Wert-Paaren) oder einer Liste von Aufzählungspunkten auszudrücken. Die für strukturierte Eingabeaufforderungen verwendeten Zielformate führen typischerweise zu einer Reduzierung der Anzahl der Token. Dadurch kann das Modell Benutzeranweisungen zuverlässiger interpretieren, wodurch die Modellkonsistenz verbessert und Mehrdeutigkeiten reduziert und gleichzeitig Eingabeaufforderungen reduziert werden.
Strukturierte Eingabeaufforderungsalgorithmen können rohe Eingabeaufforderungen mit Anweisungen wie umwandeln Bitte stellen Sie einen detaillierten Vergleich zwischen Produkt X und Produkt Y bereit und konzentrieren Sie sich dabei auf Preis, Produktmerkmale und Kundenbewertungen in eine strukturierte Kind wie: {Aufgabe: „vergleichen“, Artikel: („Produkt X“, „Produkt Y“), Kriterien: („Preis“, „Funktionen“, „Bewertungen“)}
3. Relevanzfilterung
Bei der Relevanzfilterung wird das Prinzip der „Konzentrierung auf das Wesentliche“ angewendet: Sie misst die Relevanz von Teilen des Textes und bezieht in die abschließende Eingabeaufforderung nur die Kontextteile ein, die für die jeweilige Aufgabe wirklich related sind. Anstatt ganze Informationen wie Dokumente, die Teil des Kontexts sind, wegzuwerfen, werden nur kleine Teilmengen der Informationen beibehalten, die am meisten mit der Zielanfrage zu tun haben. Dies ist eine weitere Möglichkeit, die Eingabeaufforderungsgröße drastisch zu reduzieren und dem Modell dabei zu helfen, sich in Bezug auf Fokus und erhöhte Vorhersagegenauigkeit besser zu verhalten (denken Sie daran, dass die Generierung von LLM-Token im Wesentlichen eine viele Male wiederholte Aufgabe zur Vorhersage des nächsten Wortes ist).
Nehmen Sie zum Beispiel ein komplettes 10-seitiges Produkthandbuch für ein Mobiltelefon, das als Anhang hinzugefügt wird (Eingabeaufforderungskontext). Nach Anwendung der Relevanzfilterung bleiben nur einige kurze relevante Abschnitte zu „Akkulaufzeit“ und „Ladevorgang“ erhalten, da der Benutzer beim Laden des Geräts auf Sicherheitsaspekte hingewiesen wurde.
4. Befehlsreferenzierung
Bei vielen Aufforderungen werden dieselben Anweisungen immer wieder wiederholt, z. B. „Nehmen Sie diesen Ton an“, „Antworten Sie in diesem Format“ oder „Verwenden Sie prägnante Sätze“, um nur einige zu nennen. Durch die Befehlsreferenzierung wird für jeden gemeinsamen Befehl (der aus einer Reihe von Tokens besteht) ein Verweis erstellt, jeder Befehl nur einmal registriert und als einzelner Token-Bezeichner wiederverwendet. Immer wenn in zukünftigen Eingabeaufforderungen eine registrierte „gemeinsame Anfrage“ erwähnt wird, wird diese Kennung verwendet. Diese Strategie verkürzt nicht nur die Eingabeaufforderungen, sondern trägt auch dazu bei, über einen längeren Zeitraum hinweg ein konsistentes Aufgabenverhalten aufrechtzuerhalten.
Ein kombinierter Satz von Anweisungen wie „Schreiben Sie in einem freundlichen Ton. Vermeiden Sie Fachjargon. Halten Sie die Sätze prägnant. Geben Sie Beispiele an.“ könnte als „Use Type Information X“ vereinfacht werden. und dann wiederverwendet werden, wenn die entsprechenden Anweisungen erneut angegeben werden.
5. Vorlagenabstraktion
Einige Muster oder Anweisungen tauchen häufig in allen Eingabeaufforderungen auf – beispielsweise Berichtsstrukturen, Bewertungsformate oder schrittweise Vorgehensweisen. Die Vorlagenabstraktion wendet ein ähnliches Prinzip wie die Befehlsreferenzierung an, konzentriert sich jedoch darauf, welche Kind und welches Format die generierten Ausgaben haben sollten, und kapselt diese allgemeinen Muster unter einem Vorlagennamen. Dann wird die Vorlagenreferenzierung verwendet und das LLM übernimmt die Aufgabe, die restlichen Informationen zu füllen. Dies trägt nicht nur dazu bei, die Eingabeaufforderungen klarer zu halten, sondern reduziert auch das Vorhandensein wiederholter Token erheblich.
Nach der Vorlagenabstraktion kann eine Eingabeaufforderung in etwas wie „Erstellen Sie eine Wettbewerbsanalyse mit Vorlage AB-3“ umgewandelt werden. Dabei ist AB-3 eine Liste der für die Analyse angeforderten Inhaltsabschnitte, die jeweils klar definiert sind. Etwas wie:
Erstellen Sie eine Wettbewerbsanalyse mit vier Abschnitten:
- Marktüberblick (2–3 Absätze mit einer Zusammenfassung der Branchentrends)
- Aufschlüsselung der Wettbewerber (Tabelle zum Vergleich von mindestens 5 Wettbewerbern)
- Stärken und Schwächen (Stichpunkte)
- Strategische Empfehlungen (3 umsetzbare Schritte).
Zusammenfassung
In diesem Artikel werden fünf häufig verwendete Methoden zur Beschleunigung der LLM-Generierung in anspruchsvollen Szenarien durch Komprimierung von Benutzereingabeaufforderungen vorgestellt und beschrieben, wobei der Schwerpunkt häufig auf dem Kontextteil davon liegt, der in den meisten Fällen die Hauptursache für „überlastete Eingabeaufforderungen“ ist, die zu einer Verlangsamung von LLMs führen.