
Servicenow AI Analysis Lab hat veröffentlicht Apriel-1.5-15B-Thecherein 15-Milliarden-Parameter-Open-Weights Multimodal Argumenting-Modell, das mit einem datenzentrierten ausgebildet ist Mitte Coaching Rezept-Kontinuelle Vorbeugung, gefolgt von beaufsichtigter Feinabstimmung-ohne Verstärkungslernen oder Präferenzoptimierung. Das Modell erreicht im Vergleich zu SOTA einen künstlichen Analyse -Index -Index -Rating von 52 mit 8 -fachen Kosteneinsparungen. Der Kontrollpunkt wird unter einem geliefert MIT -Lizenz zum Umarmen.
Additionally, was ist neu darin für mich?
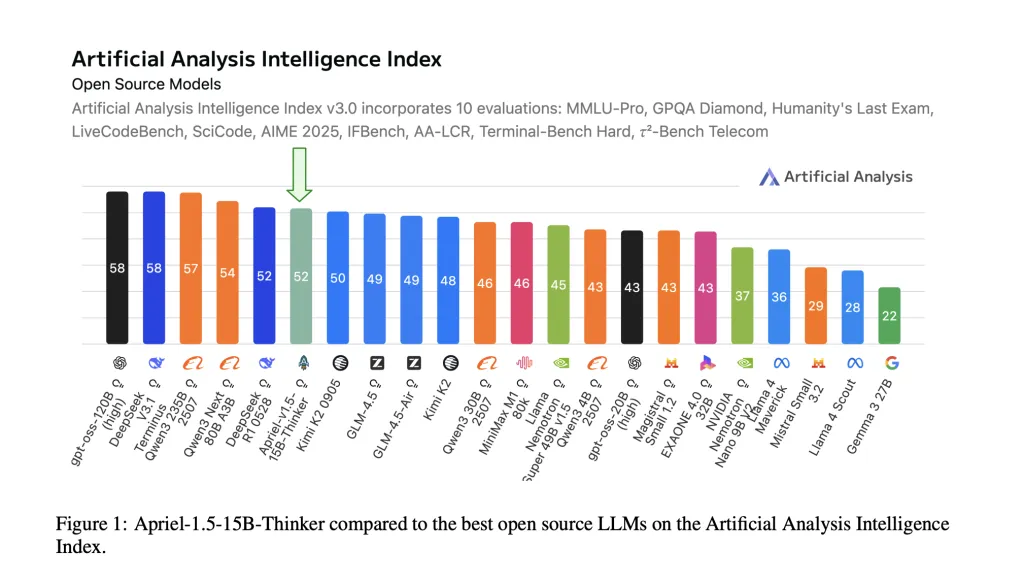
- Composite-Rating auf der Grenzebene auf kleinem Maßstab. Die Modellberichte Künstliche Analyse Intelligence Index (AAI) = 52Matching Deepseek-R1-0528 auf dieser kombinierten Metrik, während er dramatisch kleiner ist. AAI aggregiert 10 Bewertungen von Drittanbietern (MMLU-PRO, GPQA Diamond, letzte Prüfung der Humanity, LivecodeBench, Scicode, Aime 2025, Ifbench, AA-LCR, terminal-Financial institution-Hart, τ²-Bench-Telekommunikation).
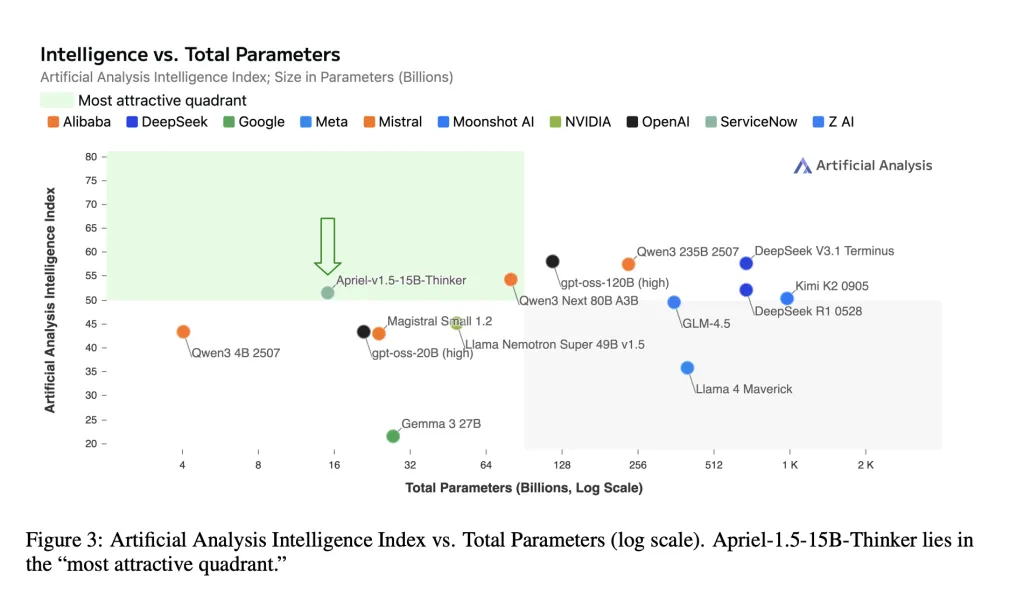
- Single-GPU-Bereitstellung. Die Modellkarte gibt den 15B-Checkpoint „Passend für eine einzelne GPU“ an und zielt auf lokale und luftgeräte Bereitstellungen mit festen Speicher- und Latenzbudgets ab.
- Offene Gewichte und reproduzierbare Pipeline. Gewichte, Schulungsrezept und Evaluierungsprotokoll sind für die unabhängige Überprüfung öffentlich.
OK! Ich habe es verstanden, aber was ist der Trainingsmechanismus?
Foundation und Upscaling. Apriel-1.5-15B-Thecher startet von Mistrals Pixtral-12b-Base-2409 Multimodal Decoder-Imaginative and prescient Stack. Das Forschungsteam gilt Tiefe Upscaling– Decodierschichten von 40 → 48 – dann Projektionsnetz-Arbeit Um den Visionscodierer mit dem vergrößerten Decoder auszurichten. Dies vermeidet die Voranwälte von Grund auf, während die Einsatzfähigkeit der Single-GPU beibehalten wird.
CPT (kontinuierliche Vorabbau). Zwei Phasen: (1) gemischte Textual content-+Bilddaten zum Erstellen von grundlegendem Denken und Dokument-/Diagrammverständnis; (2) gezielte synthetische visuelle Aufgaben (Rekonstruktion, Übereinstimmung, Erkennung, Zählen), um räumliche und kompositorische Argumentation zu schärfen. Die Sequenzlängen erstrecken sich auf 32K- bzw. 16K-Token, wobei die selektive Verlustplatzierung auf Reaktionstoken für Befehlsformatproben selektive Verlust platziert.
Sft (beaufsichtigte Feinabstimmung). Hochwertige Daten für Argumentations-Hint-Anweisungen für Mathematik, Codierung, Wissenschaft, Werkzeuggebrauch und Anweisungen folgen; Zwei zusätzliche SFT-Läufe (geschichtete Untergruppe; längere Kontext) sind Gewichtsmeister Um den endgültigen Checkpoint zu bilden. Kein RL (Verstärkungslernen) oder RLAIF (Verstärkungslernen aus KI -Suggestions).
Daten Hinweis. ~ 25% des Tiefen-Upscaling-Textmixes stammt von Nvidias Nemotron Sammlung.
O ‚Wow! Erzähl mir dann von seinen Ergebnissen?
Style Textual content Benchmarks (Cross@1 / Genauigkeit).
- Aime 2025 (American Invitational Arithmetic Examination 2025): 87,5–88%
- GPQA Diamond (Google-Probe-Beantwortung von Google-Profis-Fragen, Diamond-Break up): ~ 71%
- IfBench (Anweisungsverfolgung von Benchmark): ~ 62
- τ²-Bench (Tau-Quadrat-Financial institution) Telecom: ~ 68
- LivecodeBench (Funktionscode Korrektheit): ~ 72,8
Verwendung VlMevalkit Für die Reproduzierbarkeit erzielt Apriel wettbewerbsfähig über wettbewerbsfähig MMMU / MMMU-PRO (massives multimodales Verständnis multimodal), Logicvista, Mathvision, Mathvista, Mathverse, Mmstar, Charxiv, AI2D, Blinkmit stärkeren Ergebnissen zu Dokumenten/Diagrammen und Textual content-dominanter mathematischer Bilder.
Lassen Sie uns alles zusammenfassen
Apriel-1.5-15B-Thinker zeigt, dass ein sorgfältiges Mid-Coaching (kontinuierliche Vorab- + beaufsichtigte Feinabstimmung, kein Verstärkungslernen) einen 52 für den Intelligenzindex (AAI) für die künstliche Analyse (AAI) liefern kann und gleichzeitig auf einer einzelnen Grafik-Verarbeitungseinheit eingesetzt werden kann. Die gemeldeten Bewertungen auf Aufgabenebene (z. B. Aime 2025 ~ 88, GPQA-Diamant ~ 71, IFBench ~ 62, Tau-Quadrat-Financial institution-Telecom ~ 68) richten sich mit der Modellkarte aus und platzieren Sie die 15-Milliarden-Parameter-Checkpoint im kostengünstigsten Band der aktuellen Grundstücke. Für Unternehmen bringt diese Kombination-Open-Gewichte, reproduzierbares Rezept und Latenz mit einer GPU-eine praktische Grundlinie für die Bewertung, bevor größere geschlossene Systeme in Betracht gezogen werden.
Asif Razzaq ist der CEO von Marktechpost Media Inc. Sein jüngstes Bestreben ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch die ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die von einem breiten Publikum technisch intestine und leicht verständlich sind. Die Plattform verfügt über über 2 Millionen monatliche Ansichten und veranschaulicht ihre Beliebtheit des Publikums.