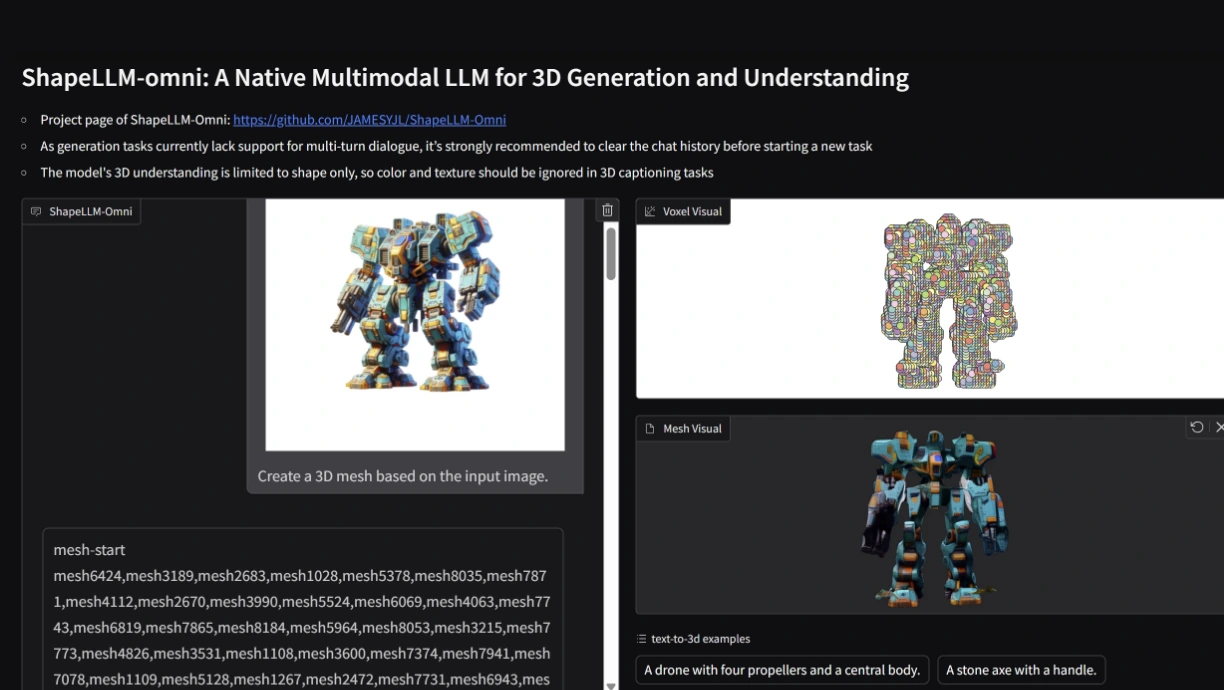

Shapellm-omni är en hweilt ny Typ av multimodal ai-modell som inne bara förstår och Generatorar Textual content Och Bilder, Utan även 3d-Objekt. Det här är ett stort steg framåt för ai-världen, där tidigare modeller som gpt-4o varit begonnsade bis tvådimensionella medier. Shapellm-omni är byggd för att förstå, Generationa Och Redigera 3D-Resurser-Och Kan Kombinera Dessa Med Textual content Och Bilder I Valfri Ordning.
Hur Fungerar Modellen?
Kärnan i Shapellm-omni är en avancerad 3D vektor-quantisierte Variationsautoencoder (VQVAE). Den Härrkomponenten Omvandlar 3D-Objekt (T.ex. Mesh-Modeller) Bis en diskret sekvens av tokens, vilket gör det möjligt för modellen att Bearbeta 3d-data på samma sattt som tex eller bild.
Modellen -Använder en voxelbaserad Repräsentation (64³ Voxelgrid) Some Kompimeras bis En Mindre Latent Repräsentation (16³ Grid) Och Därefter bis 1024 Diskreta -Token professional Objekt. Dessa Tokens ANVANDS LEDAN AV SPRåKMODELLEN För ATT Generera, Förstå Och Redigera 3d-innehåll.
För att träna modellen har forskarna byggt ett gigantikt dataset kallat 3d-alpaca, med över 700 000 högkvalitativa 3D-Resurser Och Miljontals Exempel På-Until-3D, bild-till-3d, 3d-till-text och 3D-Rrediging.