
Reinforcement Studying RL nach dem Coaching ist heute ein wichtiger Hebel für auf das Denken ausgerichtete LLMs, aber anders als vor dem Coaching conflict dies nicht der Fall prädiktiv Skalierungsregeln. Groups investieren Zehntausende GPU-Stunden in Läufe, ohne eine prinzipielle Möglichkeit zu haben, abzuschätzen, ob sich ein Rezept mit mehr Rechenleistung weiter verbessern wird. Eine neue Studie von Meta, UT Austin, UCL, Berkeley, Harvard und Periodic Labs liefert a Rechenleistungs-Framework–überprüft >400.000 GPU-Stunden– das modelliert den RL-Fortschritt mit a Sigmoidale Kurve und liefert ein erprobtes Rezept, ScaleRLdas den vorhergesagten Kurven bis folgt 100.000 GPU-Stunden.
Passen Sie ein Sigmoid an, kein Potenzgesetz
Das Vortraining entspricht häufig den Potenzgesetzen (Verlust vs. Rechenleistung). RL-Feinabstimmungsziele begrenzte Metriken (z. B. Erfolgsquote/durchschnittliche Belohnung). Das Forschungsteam zeigt sigmoidale Anfälle Zu Erfolgsquote vs. Trainingsberechnung sind empirisch robuster und stabiler als das Potenzgesetz passt, besonders wenn Sie es wollen aus kleineren Läufen extrapolieren zu größeren Budgets. Sie schließen das sehr frühe, laute Regime aus (~first 1,5.000 GPU-Stunden) und passen Sie den folgenden vorhersehbaren Teil an. Die sigmoidalen Parameter haben intuitive Rollen: Man legt die fest asymptotische Leistung (Obergrenze)ein anderer der Effizienz/Exponentund noch eins Mittelpunkt wo die Gewinne am schnellsten sind.
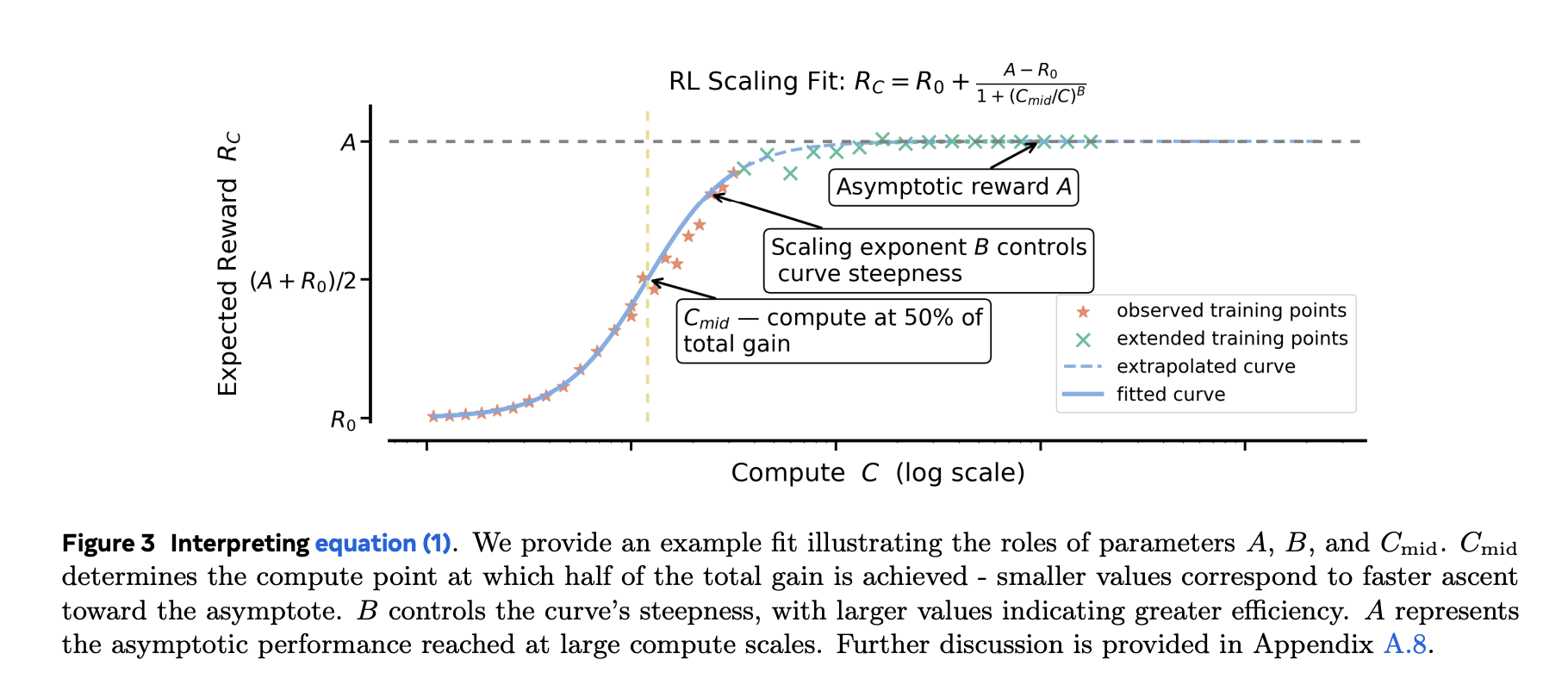
Warum das wichtig ist: Nach ca. 1–2.000 GPU-Stunden können Sie die Kurve anpassen und vorhersagen, ob sich der Anstieg auf 10.000–100.000 GPU-Stunden lohnt –vor Du verbrennst das Price range. Die Forschung zeigt auch, dass Potenzgesetzanpassungen zu irreführenden Obergrenzen führen können, es sei denn, Sie passen nur mit sehr hohem Rechenaufwand an, was dem Zweck einer frühen Prognose zuwiderläuft.
ScaleRL: ein Rezept, das vorhersehbar skaliert
ScaleRL ist nicht nur ein neuer Algorithmus; es ist ein Zusammensetzung der Wahlmöglichkeiten Dies führte zu einer stabilen, extrapolierbaren Skalierung in der Studie:
- Asynchrone Pipeline RL (Generator-Coach-Aufteilung auf GPUs) für Durchsatz außerhalb der Richtlinien.
- CISPO (abgeschnittene Wichtigkeitsstichprobe REINFORCE) als RL-Verlust.
- FP32-Präzision an den Logits um eine numerische Nichtübereinstimmung zwischen Generator und Coach zu vermeiden.
- Sofortige Schadensdurchschnittsermittlung Und Vorteilsnormalisierung auf Chargenebene.
- Erzwungene Längenunterbrechungen um außer Kontrolle geratene Spuren zu verschließen.
- Null-Varianz-Filterung (Drop-Eingabeaufforderungen, die kein Gradientensignal liefern).
- Kein positives Resampling (Entfernen Sie Eingabeaufforderungen mit hoher Erfolgsquote ≥0,9 aus späteren Epochen).
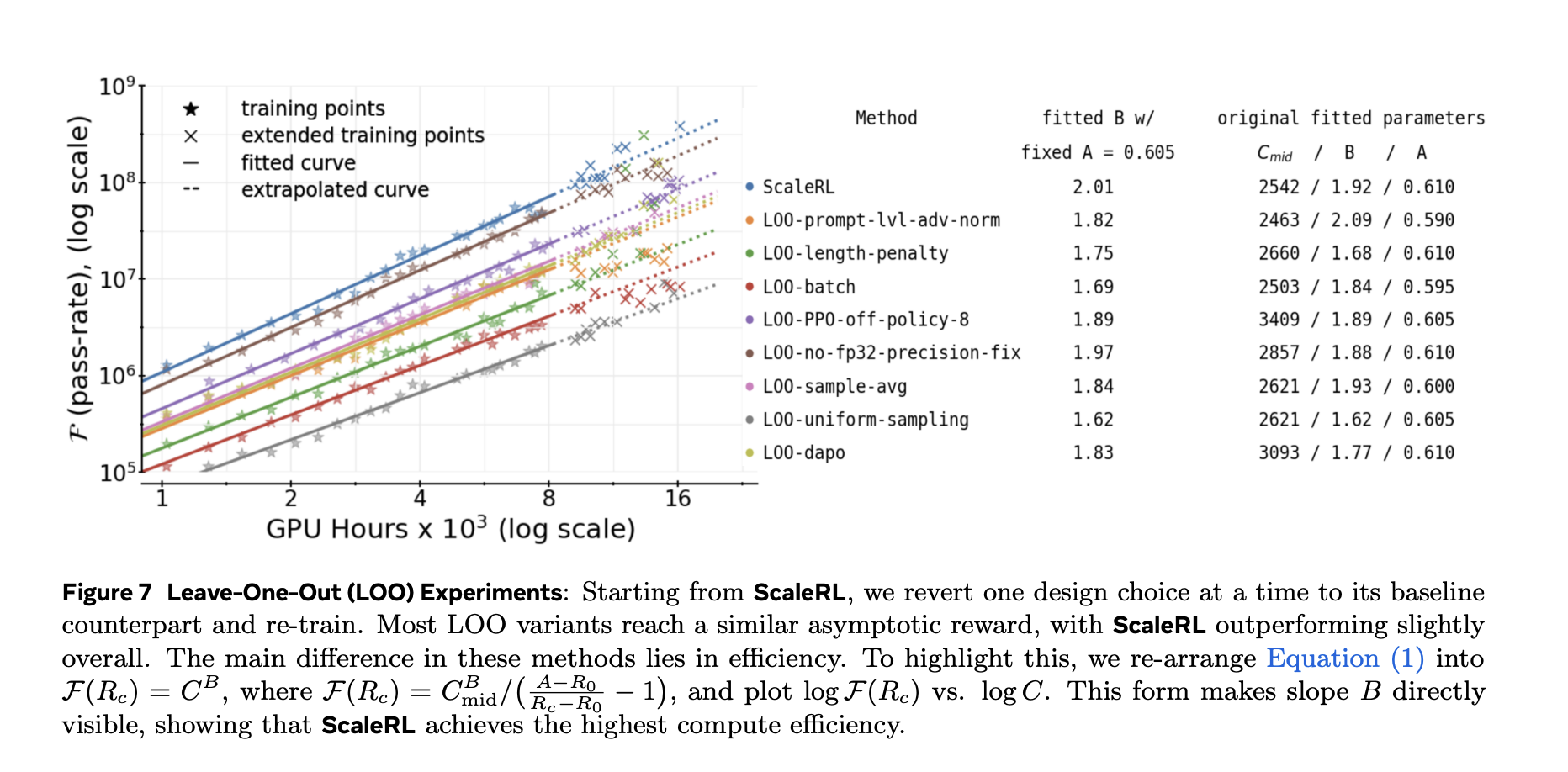
Das Forschungsteam validierte jede Komponente mit Go away-one-out (LOO)-Ablationen bei 16.000 GPU-Stunden und zeigen Sie, dass die angepassten Kurven von ScaleRL zuverlässig sind extrapolieren aus 8k → 16kdann in viel größeren Maßstäben halten – einschließlich eines einzelnen Laufs, der auf erweitert wird 100.000 GPU-Stunden.
Ergebnisse und Verallgemeinerung
Zwei wichtige Demonstrationen:
- Vorhersehbarkeit im großen Maßstab: Für ein 8B dicht Modell und a Lama-4 17B×16 MoE („Scout“)Die erweiterte Ausbildung aufmerksam verfolgt Sigmoid-Extrapolationen abgeleitet von kleineren Rechensegmenten.
- Downstream-Übertragung: Verbesserungen der Erfolgsquote bei einem iid-Validierungssatz Schiene Nachgelagerte Bewertung (z. B. AIME-24), was darauf hindeutet, dass die Rechenleistungskurve kein Datensatzartefakt ist.
Die Studie vergleicht auch angepasste Kurven für gängige Rezepte (z. B. DeepSeek (GRPO), Qwen-2.5 (DAPO), Magistral, MiniMax-M1) und Berichte höhere asymptotische Leistung und bessere Recheneffizienz für ScaleRL in ihrem Setup.
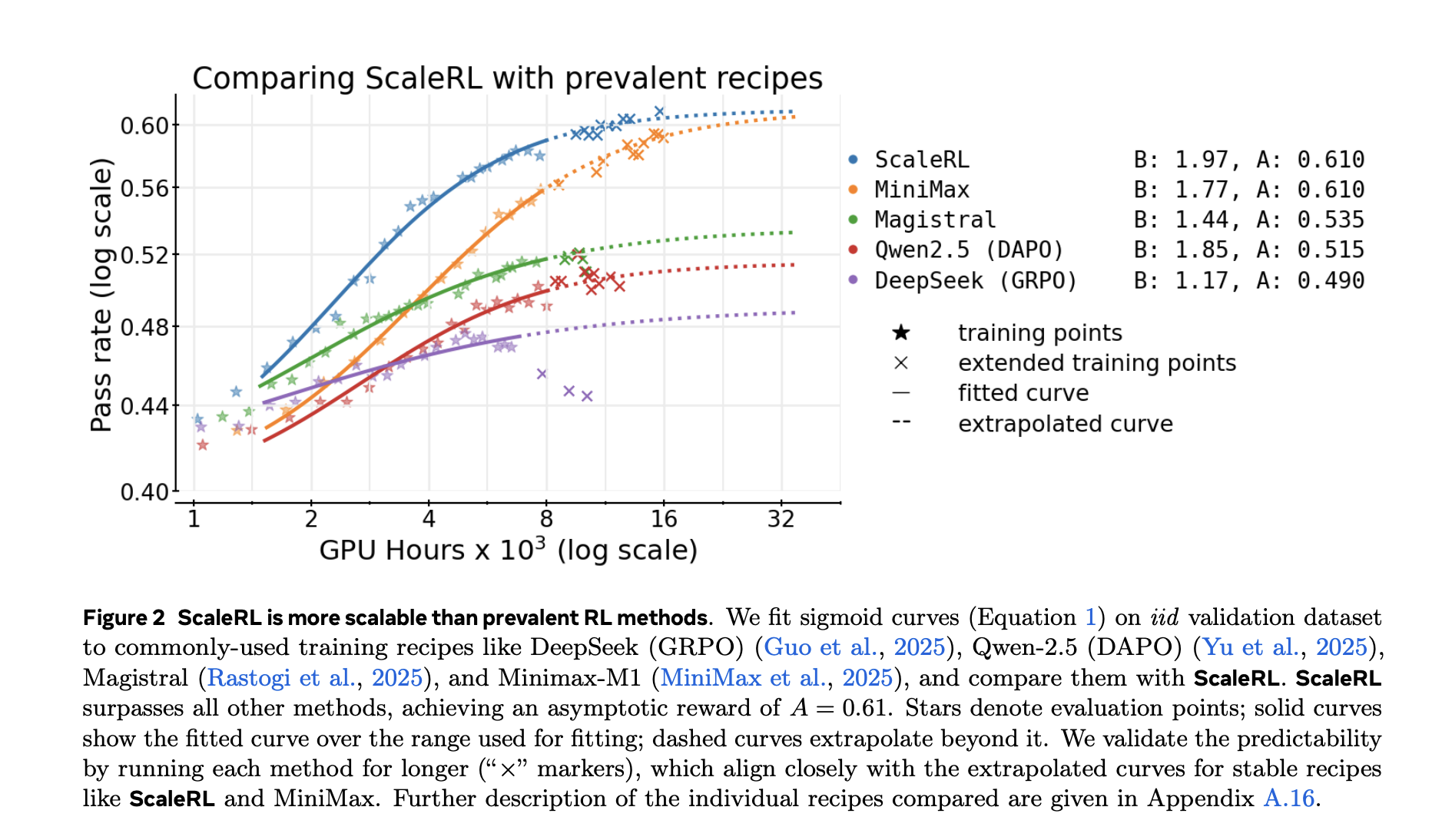
Welche Knöpfe bewegen die Decke im Vergleich zur Effizienz?
Mit dem Framework können Sie Designentscheidungen klassifizieren:
- Deckenbeweger (Asymptote): Skalierung Modellgröße (z. B. MoE) und längere Generationslängen (bis zu 32.768 Token) erhöhen die asymptotisch zwar die Leistung, kann jedoch den frühen Fortschritt verlangsamen. Größer globale Batchgröße kann auch die endgültige Asymptote anheben und das Coaching stabilisieren.
- Effizienzformer: Verlustaggregation, Vorteilsnormalisierung, Datenlehrplanund die Off-Coverage-Pipeline hauptsächlich ändern wie schnell Sie nähern sich der Decke, nicht der Decke selbst.
Operativ berät das Forschungsteam Kurven frühzeitig anpassen und Priorisierung von Interventionen, die das erhöhen Deckedann stimmen Sie das ab Effizienz Knöpfe, um es bei fester Rechenleistung schneller zu erreichen.
Wichtige Erkenntnisse
- Das Forschungsteam modelliert den RL-Fortschritt nach dem Coaching mit Sigmoidale Rechenleistungskurven (Erfolgsquote vs. Log-Compute) und ermöglicht eine zuverlässige Extrapolation – im Gegensatz zu Potenzgesetz-Anpassungen bei begrenzten Metriken.
- Ein Greatest-Observe-Rezept, ScaleRLvereint PipelineRL-k (Asynchrongenerator-Coach), CISPO Verlust, FP32-ProtokolleAggregation auf Eingabeaufforderungsebene, Vorteilsnormalisierung, unterbrechungsbasierte Längenkontrolle, Nullvarianzfilterung und No-Optimistic-Resampling.
- Anhand dieser Passungen hat das Forschungsteam vorhergesagt und abgestimmt längere Läufe bis zu 100.000 GPU-Stunden (8B dicht) und ~50.000 GPU-Stunden (17B×16 MoE „Scout“) auf Validierungskurven.
- Ablationen Zeige einige Auswahlmöglichkeiten, verschiebe die asymptotische Decke (A) (z. B. Modellmaßstab, längere Generationslängen, größere globale Cost), während andere sich hauptsächlich verbessern Recheneffizienz (B) (z. B. Aggregation/Normalisierung, Lehrplan, Off-Coverage-Pipeline).
- Das Framework bietet frühe Prognose um zu entscheiden, ob ein Lauf skaliert werden soll, und Verbesserungen bei der verteilungsinternen Validierung Verfolgen Sie Downstream-Metriken (z. B. AIME-24) zur Unterstützung der externen Validität.
Diese Arbeit verwandelt die RL-Nachschulung vom Versuch-und-Irrtum-Prinzip in ein vorhersehbares Engineering. Es passt sigmoidale Rechenleistungskurven (Erfolgsrate vs. Log-Berechnung) an, um Renditen vorherzusagen und zu entscheiden, wann gestoppt oder skaliert werden soll. Es bietet auch ein konkretes Rezept, ScaleRL, das asynchrone Generierung/Coaching im PipelineRL-Stil, den CISPO-Verlust und FP32-Logits für Stabilität verwendet. Die Studie berichtet über mehr als 400.000 GPU-Stunden an Experimenten und eine einmalige Erweiterung auf 100.000 GPU-Stunden. Die Ergebnisse unterstützen eine saubere Aufteilung: Einige Entscheidungen erhöhen die Asymptote; andere verbessern hauptsächlich die Recheneffizienz. Diese Trennung hilft Groups dabei, bahnbrechende Änderungen zu priorisieren, bevor sie die Durchsatzregler anpassen.
Schauen Sie sich das an PAPIER. Schauen Sie sich gerne bei uns um GitHub-Seite für Tutorials, Codes und Notebooks. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Asif Razzaq ist CEO von Marktechpost Media Inc.. Als visionärer Unternehmer und Ingenieur setzt sich Asif dafür ein, das Potenzial der künstlichen Intelligenz für das soziale Wohl zu nutzen. Sein jüngstes Unterfangen ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch eine ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die sowohl technisch fundiert als auch für ein breites Publikum leicht verständlich ist. Die Plattform verfügt über mehr als 2 Millionen monatliche Aufrufe, was ihre Beliebtheit beim Publikum verdeutlicht.