
Ein Staff von Forschern der Stanford College hat veröffentlicht MedagentbenchEine neue Benchmark -Suite zur Bewertung von Wirkstoffen (Langwary Mannequin) in Gesundheitskontexten. Im Gegensatz zu früheren Fragen-Reply-Datensätzen bietet Medagentbench a EHR -Umgebung (Digital Digital Well being File) wobei KI-Systeme mehrstufige klinische Aufgaben interagieren, planen und ausführen müssen. Dies markiert eine signifikante Verschiebung von der Prüfung der statischen Begründung zur Beurteilung der Agentenfunktionen in Dwell-medizinische Workflows mit Toolbasis.
Warum brauchen wir im Gesundheitswesen Agenten -Benchmarks?
Die jüngsten LLMs haben sich über statische Chat-basierte Interaktionen hinweg bewegt Agentenverhalten-Interpretieren von Anweisungen auf hoher Ebene, Aufruf von APIs, Integration von Patientendaten und Automatisierung komplexer Prozesse. In der Medizin könnte diese Entwicklung helfen, sich anzusprechen Personalmangel, Dokumentationsbelastung und administrative Ineffizienzen.
Während allgemeine Benchmarks (z. B. Agentbench, Agentboard, Tau-Bench) vorhanden ist, gibt es. In der Gesundheitsversorgung fehlte ein standardisierter Benchmark Dies erfasst die Komplexität von medizinischen Daten, FHIR -Interoperabilität und Längsschnittpatientenaufzeichnungen. Medagentbench erfüllt diese Lücke, indem er einen reproduzierbaren, klinisch relevanten Bewertungsrahmen anbietet.
Was enthält Medagentbench?
Wie sind die Aufgaben strukturiert?
Medagentbench besteht aus 300 Aufgaben in 10 Kategoriengeschrieben von lizenzierten Ärzten. Zu diesen Aufgaben gehören das Abrufen von Patienteninformationen, das Laborergebnis, die Dokumentation, die Testordnung, die Überweisungen und das Medikamentenmanagement. Aufgaben durchschnittlich 2–3 Schritte und Spiegel -Workflows, die in stationärer und ambulanter Pflege auftreten.
Welche Patientendaten stützen den Benchmark?
Der Benchmark nutzt 100 realistische Patientenprofile Extrahiert aus Stanfords Starr -Datenrepository, das übertrifft 700.000 Aufzeichnungen einschließlich Labors, Vitalen, Diagnosen, Verfahren und Medikamentenaufträgen. Die Daten wurden für die Privatsphäre nicht identifiziert und gleichermaßen geschmückt, während die klinische Gültigkeit beibehalten wurde.
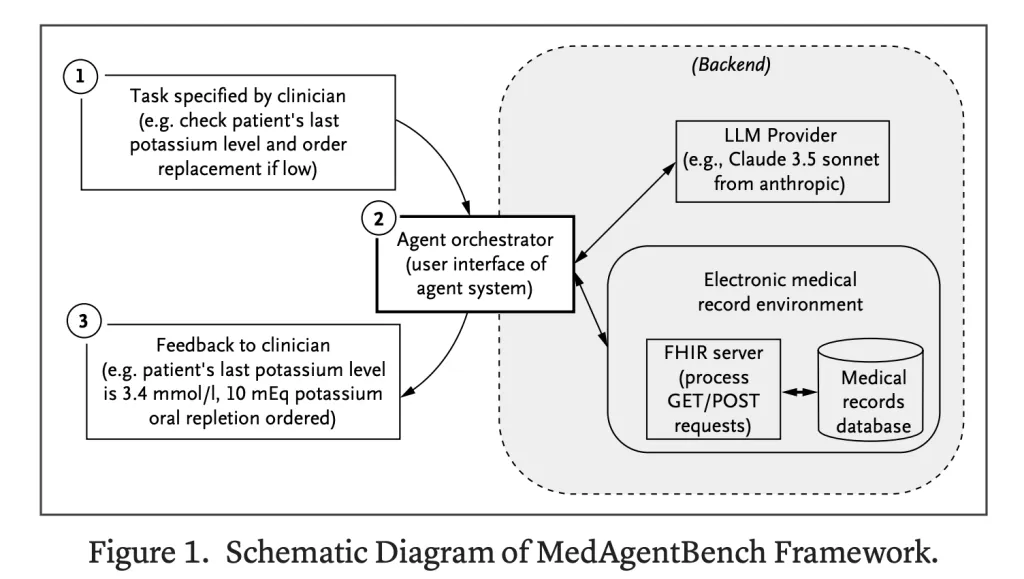
Wie wird die Umgebung gebaut?
Die Umwelt ist Fhir-konformUnterstützung sowohl Abruf (GET) als auch Änderung (Publish) von EHR -Daten. KI -Systeme können realistische klinische Wechselwirkungen simulieren, z. B. das Dokumentieren von Vitalen oder das Festlegen von Medikamentenaufträgen. Dieses Design macht den Benchmark direkt in lebende EHR -Systeme übersetzbar.
Wie werden Modelle bewertet?
- Metrisch: Aufgabenerfolgsrate (SR), gemessen mit strikter Cross@1 reale Sicherheitsanforderungen widerspiegeln.
- Modelle getestet: 12 führende LLMs einschließlich GPT-4O, Claude 3.5 Sonnet, Gemini 2.0, Deepseek-V3, Qwen2.5 und Lama 3.3.
- Agent Orchestrator: Eine Foundation -Orchestrierungs -Setup mit neun FHIR -Funktionen, beschränkt auf Acht Interaktionsrunden professional Aufgabe.
Welche Modelle haben am besten durchgeführt?
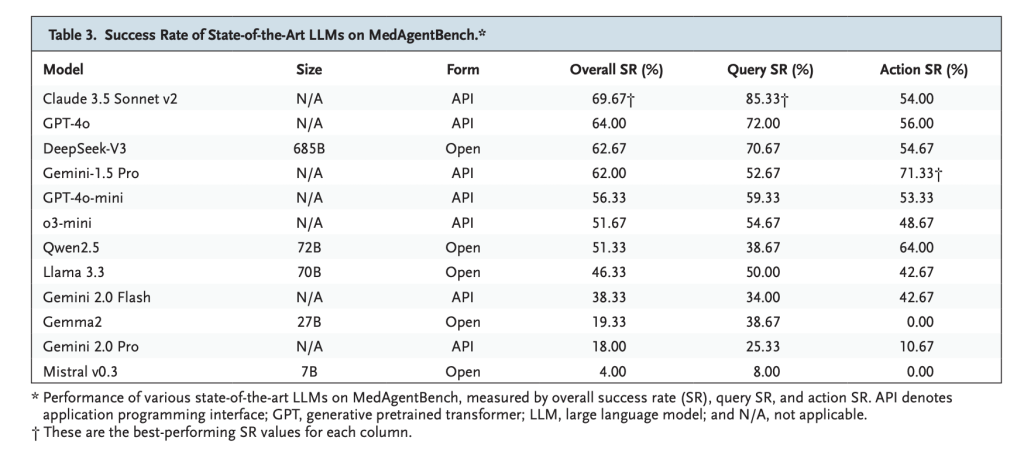
- Claude 3.5 Sonett V2: Am besten insgesamt mit 69,67% Erfolgbesonders stark in Abrufaufgaben (85,33%).
- Gpt-4o: 64,0% Erfolg und zeigt ausgewogene Abruf- und Aktionsleistung.
- Deepseek-V3: 62,67% Erfolg, führt zu Open-Gewicht-Modellen.
- Beobachtung: Die meisten Modelle haben sich hervorgetan bei Abfrageaufgaben aber kämpfte mit Aktionsbasierte Aufgaben Erfordernde eine sichere Ausführung von mehrstufigen.
Welche Fehler haben Modelle gemacht?
Es entstanden zwei dominante Versagensmuster:
- Anweisungseinhaltung Fehler – Ungültige API -Aufrufe oder falsche JSON -Formatierung.
- Ausgangsfehlanpassung – Bereitstellung vollständiger Sätze, wenn strukturierte numerische Werte erforderlich waren.
Diese Fehler unterstreichen Lücken in Präzision und Zuverlässigkeitbeide kritisch im klinischen Einsatz.
Zusammenfassung
Medagentbench stellt den ersten groß angelegten Benchmark für die Bewertung von LLM-Wirkstoffen in realistischen EHR-Umgebungen ein und kombiniert 300 auf klinischherbautete Aufgaben mit einer FHIR-konformen Umgebung und 100 Patientenprofilen. Die Ergebnisse zeigen eine starke potenzielle, aber begrenzte Zuverlässigkeit – Claude 3,5 Sonnet V2 führt bei 69,67% – die Lücke zwischen Abfrageerfolg und sicherer Aktionsausführung. Medagentbench ist zwar durch Einzelinstitutsdaten und EHR-fokussierte Umfang eingeschränkt und bietet einen offenen, reproduzierbaren Rahmen, um die nächste Technology verlässlicher AI-Agenten der Gesundheitsversorgung voranzutreiben
Schauen Sie sich das an PAPIER Und Technischer Weblog. Fühlen Sie sich frei, unsere zu überprüfen Github -Seite für Tutorials, Codes und Notizbücher. Fühlen Sie sich auch frei, uns zu folgen Twitter Und vergessen Sie nicht, sich unserer anzuschließen 100k+ ml Subreddit und abonnieren Unser Publication.

Michal Sutter ist ein Datenwissenschaftler bei einem Grasp of Science in Knowledge Science von der College of Padova. Mit einer soliden Grundlage für statistische Analyse, maschinelles Lernen und Datentechnik setzt Michal aus, um komplexe Datensätze in umsetzbare Erkenntnisse umzuwandeln.