
Wie kann die Sprachbearbeitung so direkt und kontrollierbar werden wie das einfache Umschreiben einer Textzeile? StepFun AI verfügt über die Open-Supply-Lösung Step-Audio-EditX, ein 3B-Parameter-LLM-basiertes Audiomodell, das ausdrucksstarke Sprachbearbeitung in eine textähnliche Operation auf Token-Ebene umwandelt, statt in eine Signalverarbeitungsaufgabe auf Wellenformebene.
Warum Entwickler sich für steuerbares TTS interessieren?
Die meisten Zero-Shot-TTS-Systeme kopieren Emotionen, Stil, Akzent und Klangfarbe direkt aus einem kurzen Referenzaudio. Sie können natürlich klingen, aber die Kontrolle ist schwach. Stilaufforderungen in der Texthilfe gelten nur für domäneninterne Stimmen, und die geklonte Stimme ignoriert häufig die angeforderte Emotion oder den angeforderten Sprechstil.
Frühere Arbeiten versuchen, Faktoren mit zusätzlichen Encodern, gegnerischen Verlusten oder komplexen Architekturen zu entwirren. Step-Audio-EditX behält eine relativ verwickelte Darstellung bei und ändert stattdessen die Daten und das Put up-Trainingsziel. Das Modell lernt die Kontrolle, indem es viele Paare und Tripletts sieht, bei denen der Textual content festgelegt ist, sich aber ein Attribut mit großem Spielraum ändert.
Architektur, Twin-Codebuch-Tokenizer plus kompaktes Audio-LLM
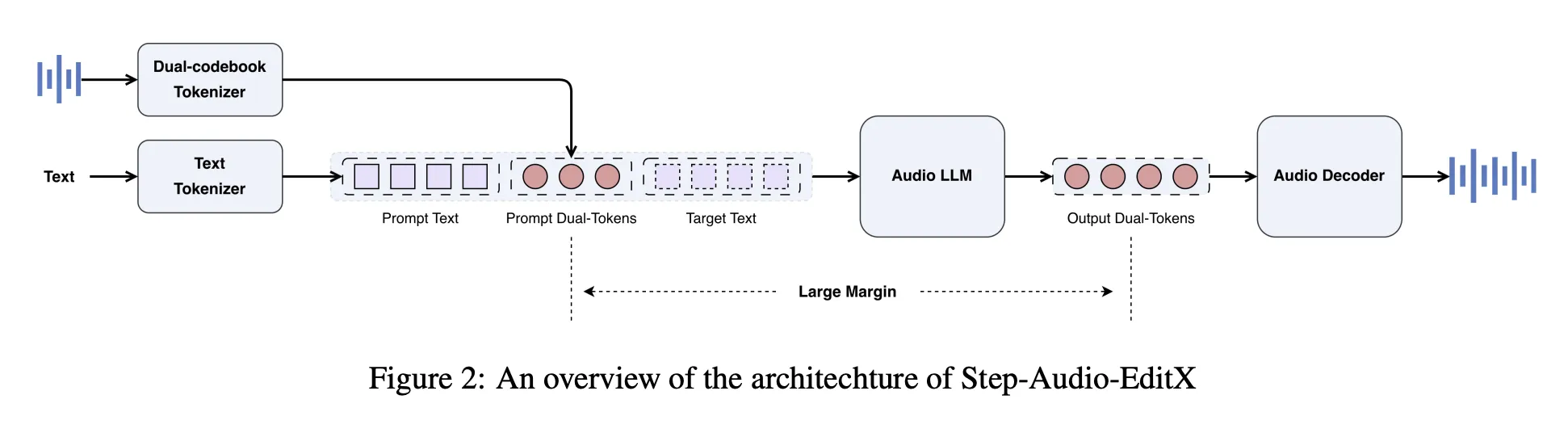
Step-Audio-EditX verwendet den Twin-Codebuch-Tokenizer von Step-Audio wieder. Sprache wird in zwei Token-Streams abgebildet, einen linguistischen Stream bei 16,7 Hz mit einem Codebuch mit 1024 Einträgen und einen semantischen Stream bei 25 Hz mit einem Codebuch mit 4096 Einträgen. Die Token sind im Verhältnis 2 zu 3 verschachtelt. Der Tokenizer speichert Prosodie- und Emotionsinformationen, sodass diese nicht vollständig entwirrt werden können.
Zusätzlich zu diesem Tokenizer erstellt das StepFun-Forschungsteam ein 3B-Parameter-Audio-LLM. Das Modell wird von einem Textual content-LLM initialisiert und dann auf einem gemischten Korpus mit einem 1:1-Verhältnis aus reinem Textual content und Twin-Codebook-Audio-Tokens in Chat-Stil-Eingabeaufforderungen trainiert. Der Audio-LLM liest Textual content-Tokens, Audio-Tokens oder beides und generiert als Ausgabe immer Twin-Codebook-Audio-Tokens.
Ein separater Audio-Decoder übernimmt die Rekonstruktion. Ein auf Diffusionstransformatoren basierendes Flussanpassungsmodul sagt Mel-Spektrogramme aus Audio-Tokens, Referenzaudio und einer Lautsprechereinbettung voraus, und ein BigVGANv2-Vocoder wandelt Mel-Spektrogramme in Wellenformen um. Das Stream-Matching-Modul wird auf etwa 200.000 Stunden hochwertiger Sprache trainiert, wodurch die Aussprache und die Ähnlichkeit der Klangfarben verbessert werden.
Synthetische Daten mit großem Spielraum statt komplizierter Encoder
Die Schlüsselidee ist das Lernen mit großem Spielraum. Das Modell wird nachträglich auf Drillinge und Vierlinge trainiert, die den Textual content unverändert lassen und nur ein Attribut mit einer deutlichen Lücke ändern.
Für Zero-Shot-TTS verwendet Step-Audio-EditX einen hochwertigen internen Datensatz, hauptsächlich Chinesisch und Englisch, mit einer kleinen Menge Kantonesisch und Sichuanesisch und etwa 60.000 Sprechern. Die Daten decken große Unterschiede in Stil und Emotion innerhalb und zwischen Sprechern ab.(arXiv)
Für die Bearbeitung von Emotionen und Sprechstilen erstellt das Staff synthetische Triolen mit großem Rand (Textual content, Audio-Impartial, Audio-Emotion oder -Stil). Synchronsprecher nehmen für jede Emotion und jeden Stil etwa 10 Sekunden lange Clips auf. Durch das Zero-Shot-Klonen von StepTTS werden dann neutrale und emotionale Versionen für denselben Textual content und denselben Sprecher erstellt. Ein Margin-Scoring-Modell, das an einem kleinen, von Menschen beschrifteten Satz trainiert wird, bewertet Paare auf einer Skala von 1 bis 10, und es werden nur Proben mit einem Rating von mindestens 6 aufbewahrt.
Die paralinguistische Bearbeitung, die Atmung, Lachen, gefüllte Pausen und andere Tags umfasst, verwendet eine halbsynthetische Strategie auf Foundation des NVSpeech-Datensatzes. Das Forschungsteam erstellt Vierlinge, bei denen das Ziel das Unique-NVSpeech-Audio und -Transkript ist und die Eingabe eine geklonte Model ist, bei der Tags aus dem Textual content entfernt wurden. Dies ermöglicht eine Überwachung der Zeitbereichsbearbeitung ohne Margenmodell.
Reinforcement-Studying-Daten nutzen zwei Präferenzquellen. Menschliche Annotatoren bewerten 20 Kandidaten professional Eingabeaufforderung auf einer 5-Punkte-Skala hinsichtlich Korrektheit, Prosodie und Natürlichkeit, und Paare mit einer Marge von mehr als 3 werden beibehalten. Ein Verständnismodell bewertet Emotionen und Sprechstil auf einer Skala von 1 bis 10, wobei Paare mit einem Abstand von mehr als 8 beibehalten werden.
Nach dem Coaching SFT plus PPO für Token-Sequenzen
Das Put up-Coaching besteht aus zwei Phasen: überwachte Feinabstimmung gefolgt von PPO.
In überwachte FeinabstimmungSystemansagen definieren Zero-Shot-TTS und Bearbeitungsaufgaben in einem einheitlichen Chat-Format. Für TTS wird die Eingabeaufforderungswellenform in zwei Codebuch-Tokens codiert, in eine Zeichenfolgenform umgewandelt und als Sprecherinformationen in die Systemansage eingefügt. Die Benutzernachricht ist der Zieltext und das Modell gibt neue Audio-Tokens zurück. Für die Bearbeitung enthält die Benutzernachricht Unique-Audio-Tokens sowie eine Anweisung in natürlicher Sprache, und das Modell gibt bearbeitete Tokens aus.
Durch verstärkendes Lernen wird dann die Befolgung der Anweisungen verfeinert. Ein 3B-Belohnungsmodell wird vom SFT-Kontrollpunkt aus initialisiert und mit Bradley Terry-Verlust auf Präferenzpaare mit großer Marge trainiert. Die Belohnung wird direkt anhand von Twin-Codebook-Token-Sequenzen berechnet, ohne dass die Wellenform dekodiert wird. Beim PPO-Coaching werden dieses Belohnungsmodell, ein Clip-Schwellenwert und eine KL-Strafe verwendet, um Qualität und Abweichung von der SFT-Richtlinie auszugleichen.
Step-Audio-Edit-Check, iterative Bearbeitung und Generalisierung
Um die Kontrolle zu quantifizieren, führte das Forschungsteam den Step-Audio-Edit-Check ein. Es verwendet Gemini 2.5 Professional als LLM zur Bewertung von Emotionen, Sprechstil und paralinguistischer Genauigkeit. Der Benchmark verfügt über 8 Sprecher, die aus Wenet Speech4TTS, GLOBE V2 und Libri Mild stammen, mit 4 Sprechern professional Sprache.
Das Emotionsset besteht aus 5 Kategorien mit 50 chinesischen und 50 englischen Eingabeaufforderungen professional Kategorie. Der Sprechstilsatz umfasst 7 Stile mit 50 Eingabeaufforderungen professional Sprache und Stil. Das paralinguistische Set verfügt über 10 Beschriftungen wie „Atmen“, „Lachen“, „Überraschung oh“ und „ähm“ mit 50 Eingabeaufforderungen professional Beschriftung und Sprache.
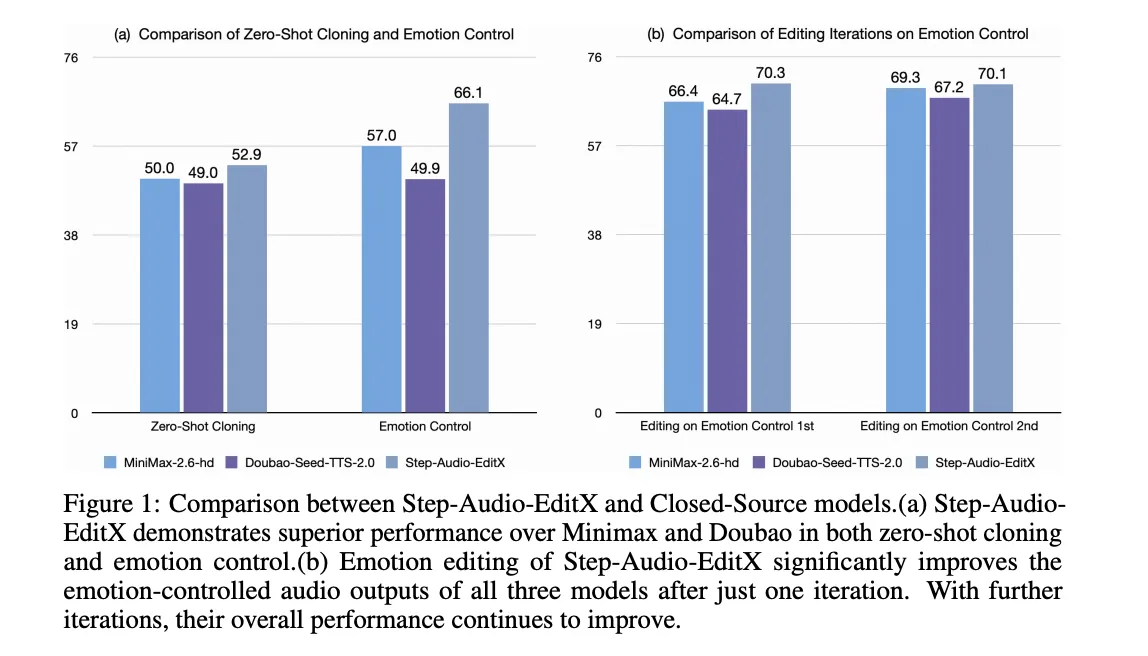
Die Bearbeitung wird iterativ ausgewertet. Iteration 0 ist der anfängliche Zero-Shot-Klon. Anschließend wendet das Modell drei Bearbeitungsrunden mit Textanweisungen an. Auf Chinesisch steigt die Emotionsgenauigkeit von 57,0 bei Iteration 0 auf 77,7 bei Iteration 3. Die Genauigkeit des Sprechstils steigt von 41,6 auf 69,2. Englisch zeigt ein ähnliches Verhalten, und eine prompte feste Ablation, bei der für alle Iterationen das gleiche Immediate-Audio verwendet wird, verbessert immer noch die Genauigkeit, was die Hypothese des großen Spielraums des Lernens unterstützt.

Das gleiche Bearbeitungsmodell wird auf vier Closed-Supply-TTS-Systeme angewendet: GPT 4o mini TTS, ElevenLabs v2, Doubao Seed TTS 2.0 und MiniMax Speech 2.6 hd. Bei allen verbessert eine Bearbeitungsiteration mit Step-Audio-EditX sowohl die Feelings- als auch die Stilgenauigkeit, und weitere Iterationen helfen weiterhin.
Paralinguistische Bearbeitung wird auf einer Skala von 1 bis 3 bewertet. Die durchschnittliche Punktzahl steigt von 1,91 bei Iteration 0 auf 2,89 nach einer einzigen Bearbeitung, sowohl in Chinesisch als auch in Englisch, was mit der nativen paralinguistischen Synthese in starken kommerziellen Systemen vergleichbar ist.

Wichtige Erkenntnisse
- Step Audio EditX verwendet einen Twin-Codebuch-Tokenizer und einen 3B-Parameter-Audio-LLM, sodass Sprache als diskrete Token behandelt und Audio auf textähnliche Weise bearbeitet werden kann.
- Das Modell stützt sich auf umfangreiche synthetische Daten für Emotionen, Sprechstil, paralinguistische Hinweise, Geschwindigkeit und Geräusche, anstatt zusätzliche entwirrende Encoder hinzuzufügen.
- Überwachte Feinabstimmung plus PPO mit einem Belohnungsmodell auf Token-Ebene richtet das Audio-LLM so aus, dass es den Anweisungen zur Bearbeitung natürlicher Sprache sowohl für TTS als auch für Bearbeitungsaufgaben folgt.
- Der Step Audio Edit Check-Benchmark mit Gemini 2.5 Professional als Juror zeigt deutliche Genauigkeitssteigerungen über 3 Bearbeitungsiterationen für Emotion, Stil und paralinguistische Kontrolle sowohl in Chinesisch als auch in Englisch.
- Step Audio EditX kann Sprache aus Closed-Supply-TTS-Systemen nachbearbeiten und verbessern, und der vollständige Stack, einschließlich Code und Prüfpunkten, steht Entwicklern als Open Supply zur Verfügung.
Step Audio EditX ist ein präziser Fortschritt in der steuerbaren Sprachsynthese, da es den Step Audio-Tokenizer beibehält, ein kompaktes 3B-Audio-LLM hinzufügt und die Steuerung durch große Margin-Daten und PPO optimiert. Die Einführung des Step Audio Edit Check mit Gemini 2.5 Professional als Juror macht die Bewertungsgeschichte hinsichtlich Emotion, Sprechstil und paralinguistischer Kontrolle konkreter, und die offene Model senkt die Hürde für praktische Audiobearbeitungsforschung. Insgesamt fühlt sich die Audiobearbeitung mit dieser Model der Textbearbeitung viel näher an.
Schauen Sie sich das an Papier, Repo Und Modellgewichte. Schauen Sie sich gerne bei uns um GitHub-Seite für Tutorials, Codes und Notebooks. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Asif Razzaq ist CEO von Marktechpost Media Inc.. Als visionärer Unternehmer und Ingenieur setzt sich Asif dafür ein, das Potenzial der künstlichen Intelligenz für das soziale Wohl zu nutzen. Sein jüngstes Unterfangen ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch eine ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die sowohl technisch fundiert als auch für ein breites Publikum leicht verständlich ist. Die Plattform verfügt über mehr als 2 Millionen monatliche Aufrufe, was ihre Beliebtheit beim Publikum verdeutlicht.