
Warum schneiden aktuelle Audio-KI-Modelle oft schlechter ab, wenn sie längere Überlegungen generieren, anstatt ihre Entscheidungen auf den tatsächlichen Klang zu stützen? Das Forschungsteam von StepFun veröffentlicht Step-Audio-R1, ein neues Audio-LLM, das für die Berechnungsskalierung in Testzeiten entwickelt wurde und diesen Fehlermodus behebt, indem es zeigt, dass der Genauigkeitsabfall mit der Gedankenkette keine Audiobeschränkung, sondern ein Trainings- und Modalitätserdungsproblem ist.
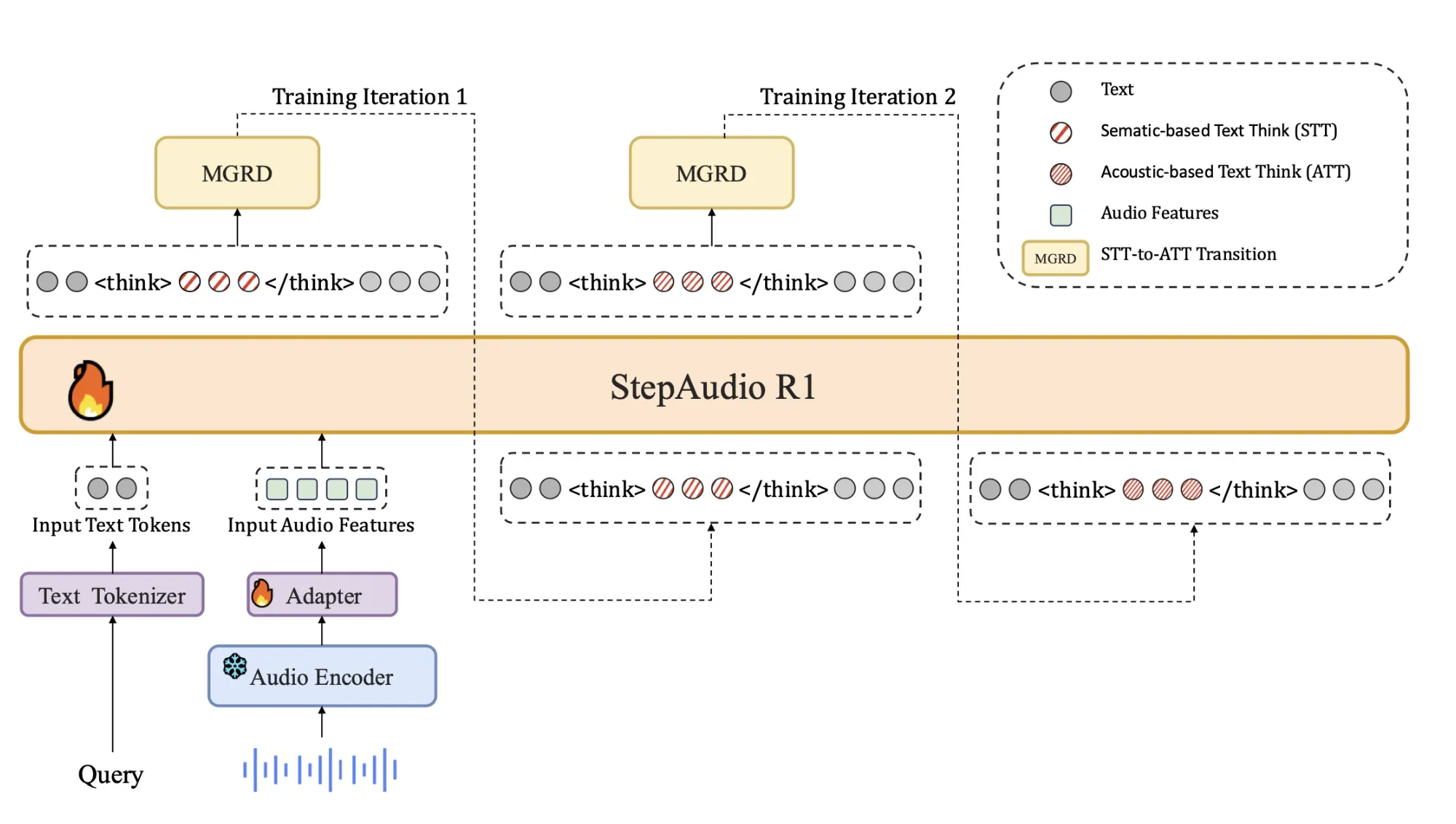
Das Kernproblem, die Begründung von Audiomodellen gegenüber Textsurrogaten
Die meisten aktuellen Audiomodelle erben ihr Argumentationsverhalten aus dem Texttraining. Sie lernen zu argumentieren, als würden sie Transkripte lesen, und nicht als würden sie zuhören. Das StepFun-Workforce nennt dies Textual Surrogate Reasoning. Das Modell verwendet imaginäre Wörter und Beschreibungen anstelle von akustischen Hinweisen wie Tonhöhenkontur, Rhythmus, Klangfarbe oder Hintergrundgeräuschmustern.
Dieses Missverhältnis erklärt, warum eine längere Gedankenkette oft die Audioleistung beeinträchtigt. Das Modell gibt mehr Token aus, um falsche oder modalitätsirrelevante Annahmen auszuarbeiten. Step-Audio-R1 greift hier an, indem es das Modell zwingt, Antworten anhand akustischer Beweise zu begründen. Die Trainingspipeline ist rund um die Modality Grounded Reasoning Distillation (MGRD) organisiert, die Argumentationsspuren auswählt und destilliert, die explizit auf Audiofunktionen verweisen.
Architektur
Die Architektur bleibt nah an den bisherigen Step-Audio-Systemen:
- Ein Qwen2-basierter Audio-Encoder verarbeitet Rohwellenformen mit 25 Hz.
- Ein Audioadapter sampelt die Encoder-Ausgabe um den Faktor 2 auf 12,5 Hz herunter und richtet Frames am Sprach-Token-Stream aus.
- Ein Qwen2.5 32B-Decoder nutzt die Audiofunktionen und generiert Textual content.
Der Decoder erzeugt im Inneren immer einen expliziten Argumentationsblock <assume> Und </assume> Tags, gefolgt von der endgültigen Antwort. Durch diese Trennung können Trainingsziele die Struktur und den Inhalt des Denkens beeinflussen, ohne den Fokus auf die Genauigkeit der Aufgabe zu verlieren. Das Modell wird als 33B-Parameter-Audio-Textual content-zu-Textual content-Modell veröffentlicht Hugging Face unter Apache 2.0.
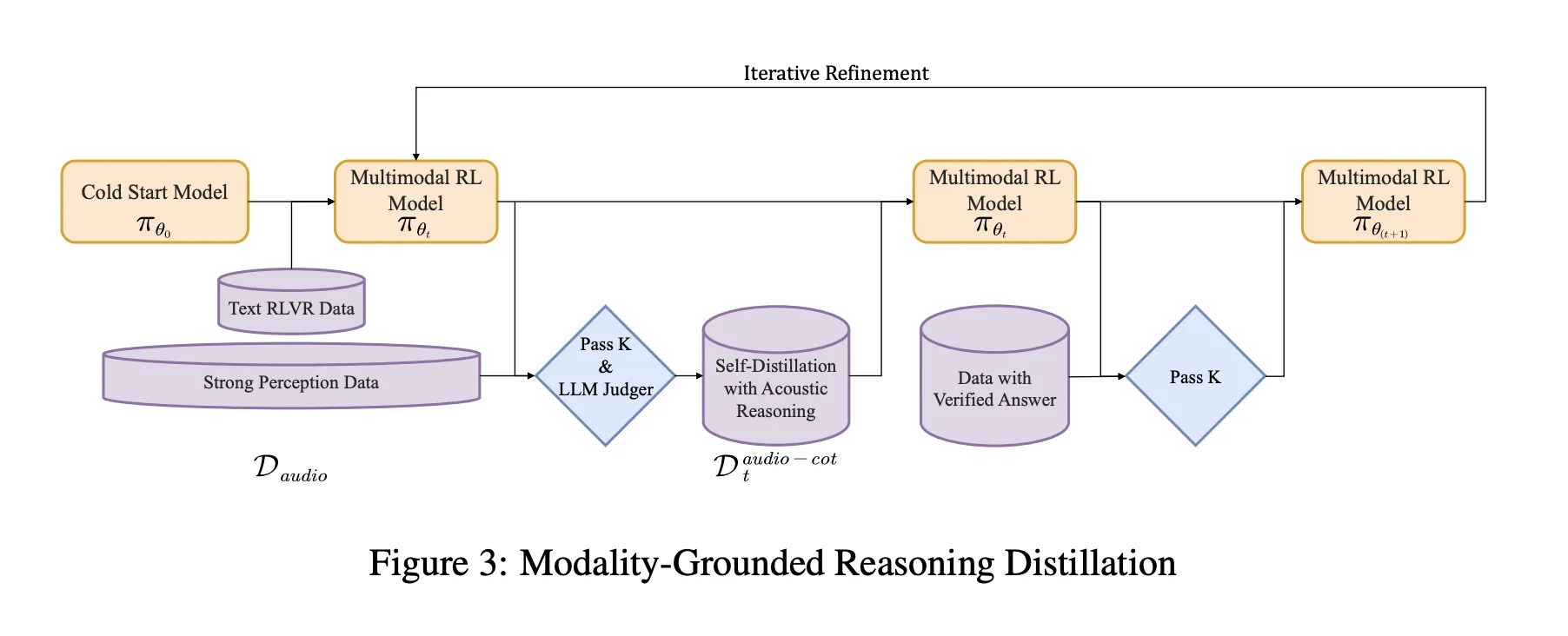
Trainingspipeline, vom Kaltstart bis zum Audio Grounded RL
Die Pipeline verfügt über eine überwachte Kaltstartphase und eine Verstärkungslernphase, die sowohl Textual content- als auch Audioaufgaben mischen.
Kaltstart verwendet etwa 5 Millionen Beispiele und deckt 1 Milliarde Token aus reinen Textdaten und 4 Milliarden Token aus gepaarten Audiodaten ab. Zu den Audioaufgaben gehören automatische Spracherkennung, paralinguistisches Verstehen und Dialoge im Stil von Audiofragen und Antworten. Ein Bruchteil der Audiodaten enthält eine Audiokette von Gedankenspuren, die von einem früheren Modell generiert wurden. Textdaten umfassen Multi-Flip-Dialoge, die Beantwortung von Wissensfragen, Mathematik und Code-Argumentation. Alle Beispiele haben ein gemeinsames Format, in das die Argumentation eingebettet ist <assume> Tags, auch wenn der Argumentationsblock zunächst leer ist.
Überwachtes Lernen trainiert Step-Audio-R1, diesem Format zu folgen und nützliche Argumente für Audio und Textual content zu generieren. Dies ergibt eine Grundkette des Denkverhaltens, ist jedoch immer noch auf textbasiertes Denken ausgerichtet.
Modalitätsbasierte Argumentationsdestillation MGRD
MGRD wird in mehreren Iterationen angewendet. Für jede Runde stellt das Forschungsteam Audiofragen, bei denen die Bezeichnung von tatsächlichen akustischen Eigenschaften abhängt. Zum Beispiel Fragen zur Sprecheremotion, zum Hintergrundgeschehen in Klangszenen oder zur musikalischen Struktur. Das aktuelle Modell erzeugt mehrere Argumentations- und Antwortkandidaten professional Frage. Ein Filter behält nur Ketten, die drei Einschränkungen erfüllen:
- Sie beziehen sich auf akustische Hinweise, nicht nur auf Textbeschreibungen oder imaginäre Transkripte.
- Sie sind als kurze Schritt-für-Schritt-Erklärungen logisch schlüssig.
- Ihre endgültigen Antworten sind gemäß Labels oder programmatischen Prüfungen korrekt.
Diese akzeptierten Spuren bilden einen destillierten Audio-Gedankenketten-Datensatz. Das Modell wird anhand dieses Datensatzes zusammen mit den ursprünglichen Textbegründungsdaten feinabgestimmt. Darauf folgt Reinforcement Studying with Verified Rewards, RLVR. Bei Textfragen basieren die Belohnungen auf der Richtigkeit der Antwort. Bei Audiofragen mischt der Belohnungsmix die Antwortkorrektheit und das Argumentationsformat mit einer typischen Gewichtung von 0,8 für Genauigkeit und 0,2 für Argumentation. Das Coaching verwendet PPO mit etwa 16 erfassten Antworten professional Eingabeaufforderung und unterstützt Sequenzen mit bis zu etwa 10.240 Token, um eine lange Beratung zu ermöglichen.
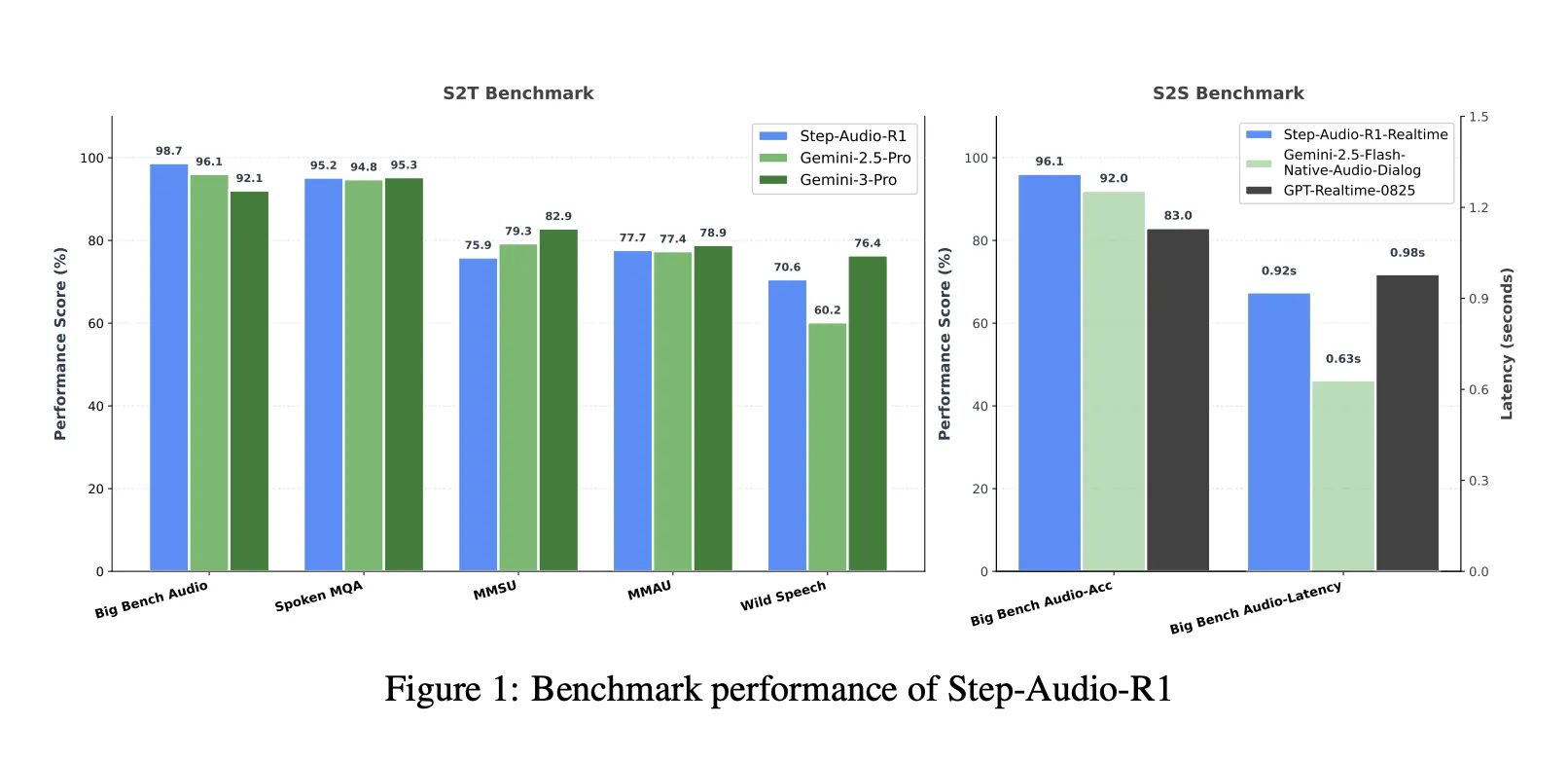
Benchmarks, die die Lücke zum Gemini 3 Professional schließen
Bei einer kombinierten Sprache-zu-Textual content-Benchmark-Suite, die Massive Bench Audio, Spoken MQA, MMSU, MMAU und Wild Speech umfasst, erreicht Step-Audio-R1 eine durchschnittliche Punktzahl von etwa 83,6 Prozent. Gemini 2.5 Professional meldet etwa 81,5 Prozent und Gemini 3 Professional erreicht etwa 85,1 Prozent. Allein auf Massive Bench Audio erreicht Step-Audio-R1 etwa 98,7 Prozent und ist damit höher als bei beiden Gemini-Versionen.
Für das Rede-to-Speech-Argumentation nutzt die Step-Audio-R1-Echtzeitvariante die Streaming-Stile „Hören beim Denken“ und „Denken beim Sprechen“. Beim Speech-to-Speech von Massive Bench Audio wird eine Argumentationsgenauigkeit von etwa 96,1 Prozent erreicht, wobei die Latenz des ersten Pakets etwa 0,92 Sekunden beträgt. Dieser Wert übertrifft GPT-basierte Echtzeit-Basiswerte und native Audiodialoge im Gemini 2.5 Flash-Stil, während die Interaktion weniger als eine Sekunde beträgt.
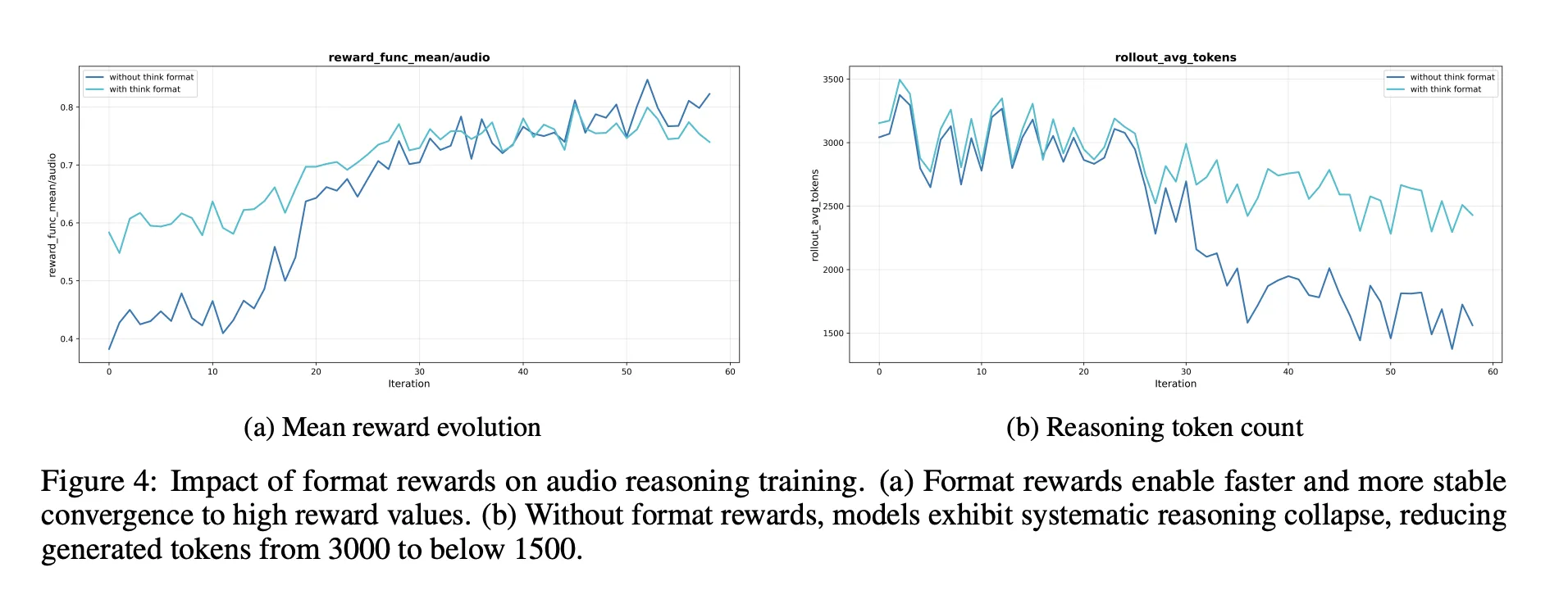
Ablationen, worauf es beim Audio-Argument ankommt
Der Ablationsabschnitt bietet mehrere Designsignale für Ingenieure:
- Eine Belohnung im Argumentationsformat ist erforderlich. Ohne diese Möglichkeit verkürzt oder entfernt Verstärkungslernen tendenziell die Gedankenkette, was zu niedrigeren Audio-Benchmark-Ergebnissen führt.
- RL-Daten sollten auf Probleme mit mittlerem Schwierigkeitsgrad abzielen. Die Auswahl von Fragen, bei denen „Go“ bei 8 in einem mittleren Bereich liegt, führt zu stabileren Belohnungen und sorgt für eine lange Argumentation.
- Das Skalieren von RL-Audiodaten ohne eine solche Auswahl hilft nicht. Die Qualität der Eingabeaufforderungen und Beschriftungen ist wichtiger als die bloße Größe.
Die Forscher beschreiben außerdem eine Selbsterkennungs-Korrekturpipeline, die die Häufigkeit von Antworten wie „Ich kann nur Textual content lesen und keinen Ton hören“ in einem Modell reduziert, das auf die Verarbeitung von Geräuschen trainiert ist. Hierbei wird die direkte Präferenzoptimierung für kuratierte Präferenzpaare verwendet, bei denen das korrekte Verhalten darin besteht, Audioeingaben zu bestätigen und zu verwenden.
Wichtige Erkenntnisse
- Step-Audio-R1 ist eines der ersten Audio-Sprachmodelle, das eine längere Gedankenkette in einen konsistenten Genauigkeitsgewinn für Audioaufgaben umwandelt und so den bei früheren Audio-LLMs aufgetretenen Fehler bei der invertierten Skalierung behebt.
- Das Modell zielt explizit auf Textual Surrogate Reasoning ab, indem es die Modality Grounded Reasoning Destillation verwendet, die nur diejenigen Argumentationsspuren filtert und destilliert, die auf akustischen Hinweisen wie Tonhöhe, Klangfarbe und Rhythmus statt auf imaginären Transkripten beruhen.
- Architektonisch kombiniert Step-Audio-R1 einen Qwen2-basierten Audio-Encoder mit einem Adapter und einem Qwen2.5 32B-Decoder, der immer generiert
<assume>Argumentationssegmente vor den Antworten und wird als 33B-Audio-Textual content-zu-Textual content-Modell unter Apache 2.0 veröffentlicht. - Bei umfassenden Audio-Verständnis- und Argumentations-Benchmarks, die Sprache, Umgebungsgeräusche und Musik abdecken, übertrifft Step-Audio-R1 Gemini 2.5 Professional und erreicht eine Leistung, die mit Gemini 3 Professional vergleichbar ist, und unterstützt gleichzeitig eine Echtzeitvariante für Sprache-zu-Sprache-Interaktion mit geringer Latenz.
- Das Trainingsrezept kombiniert groß angelegte überwachte Gedankenketten, modalitätsbasierte Destillation und Reinforcement Studying mit verifizierten Belohnungen und bietet einen konkreten und reproduzierbaren Entwurf für die Erstellung zukünftiger Audio-Argumentationsmodelle, die tatsächlich von der Skalierung der Testzeitberechnung profitieren.

Redaktionelle Anmerkungen
Step-Audio-R1 ist eine wichtige Veröffentlichung, da es die Gedankenkette von einer Belastung in ein nützliches Werkzeug für das Audio-Argumentieren umwandelt, indem es sich direkt mit textuellem Ersatzdenken mit Modality Grounded Reasoning Destillation und Reinforcement Studying mit verifizierten Belohnungen befasst. Es zeigt, dass die Skalierung der Testzeitberechnung Audiomodellen zugute kommen kann, wenn die Argumentation in akustischen Merkmalen verankert ist und Benchmark-Ergebnisse liefert, die mit Gemini 3 Professional vergleichbar sind, während sie gleichzeitig offen und für Ingenieure praktisch nutzbar bleiben. Insgesamt verwandelt diese Forschungsarbeit die erweiterte Überlegung in Audio-LLMs von einem konsistenten Fehlermodus in ein kontrollierbares und reproduzierbares Entwurfsmuster.
Schauen Sie sich das an Papier, Repo, Projektseite Und Modellgewichte. Schauen Sie sich gerne bei uns um GitHub-Seite für Tutorials, Codes und Notebooks. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser E-newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Asif Razzaq ist CEO von Marktechpost Media Inc.. Als visionärer Unternehmer und Ingenieur setzt sich Asif dafür ein, das Potenzial der künstlichen Intelligenz für das soziale Wohl zu nutzen. Sein jüngstes Unterfangen ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch eine ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die sowohl technisch fundiert als auch für ein breites Publikum leicht verständlich ist. Die Plattform verfügt über mehr als 2 Millionen monatliche Aufrufe, was ihre Beliebtheit beim Publikum verdeutlicht.