
Tencent Hunyuan hat HunyuanOCR veröffentlicht, ein 1B-Parameter-Imaginative and prescient-Sprachmodell, das auf OCR und Dokumentverständnis spezialisiert ist. Das Modell basiert auf der nativen multimodalen Architektur von Hunyuan und führt Recognizing, Parsing, Informationsextraktion, visuelle Beantwortung von Fragen und Textbildübersetzung über eine einzige Finish-to-Finish-Pipeline aus.
HunyuanOCR ist eine leichtgewichtige Different zu allgemeinen VLMs wie Gemini 2.5 und Qwen3 VL, die bei OCR-zentrierten Aufgaben immer noch mit ihnen mithalten oder diese sogar übertreffen. Es zielt auf Produktionsanwendungsfälle wie das Parsen von Dokumenten, das Extrahieren von Karten und Quittungen, das Extrahieren von Videountertiteln und die Übersetzung mehrsprachiger Dokumente ab.
Architektur, native Auflösung ViT plus Light-weight LLM
HunyuanOCR verwendet 3 Hauptmoduleein visueller Encoder mit nativer Auflösung namens Hunyuan ViT, ein adaptiver MLP-Connector und ein leichtes Sprachmodell. Der Encoder basiert auf SigLIP-v2-400M und wurde erweitert, um beliebige Eingabeauflösungen durch adaptives Patching zu unterstützen, das das ursprüngliche Seitenverhältnis beibehält. Bilder werden entsprechend ihren ursprünglichen Proportionen in Teilstücke aufgeteilt und mit globaler Aufmerksamkeit verarbeitet, was die Erkennung bei langen Textzeilen, langen Dokumenten und Scans mit geringer Qualität verbessert.
Der Adaptive MLP Connector führt lernbares Pooling in der räumlichen Dimension durch. Es komprimiert die dichten visuellen Token in eine kürzere Sequenz, während Informationen aus textdichten Bereichen erhalten bleiben. Dies reduziert die an das Sprachmodell übergebene Sequenzlänge und verringert den Rechenaufwand, während OCR-relevante Particulars erhalten bleiben.
Das Sprachmodell basiert auf dem dicht strukturierten Hunyuan 0.5B-Modell und verwendet XD RoPE. XD RoPE teilt Rotationspositionseinbettungen in 4 Unterräume für Textual content, Höhe, Breite und Zeit auf. Dies gibt dem Modell eine native Möglichkeit, die 1D-Token-Reihenfolge mit dem 2D-Structure und der raumzeitlichen 3D-Struktur auszurichten. Dadurch kann derselbe Stapel mehrspaltige Seiten, seitenübergreifende Abläufe und Sequenzen von Videobildern verarbeiten.
Coaching und Schlussfolgerung folgen einem vollständigen Finish-to-Finish-Paradigma. Es gibt keine externe Layoutanalyse oder ein Nachbearbeitungsmodell in der Schleife. Alle Aufgaben werden als Eingabeaufforderungen in natürlicher Sprache ausgedrückt und in einem einzigen Vorwärtsdurchgang bearbeitet. Dieses Design verhindert die Fehlerausbreitung über Pipeline-Stufen hinweg und vereinfacht die Bereitstellung.

Daten und Pre-Coaching-Rezept
Die Datenpipeline erstellt mehr als 200 Millionen Bildtextpaare in neun realen Szenarien, darunter Straßenansichten, Dokumente, Werbung, handgeschriebener Textual content, Screenshots, Karten, Zertifikate und Rechnungen, Spieloberflächen, Videobilder und künstlerische Typografie. Das Korpus umfasst mehr als 130 Sprachen.
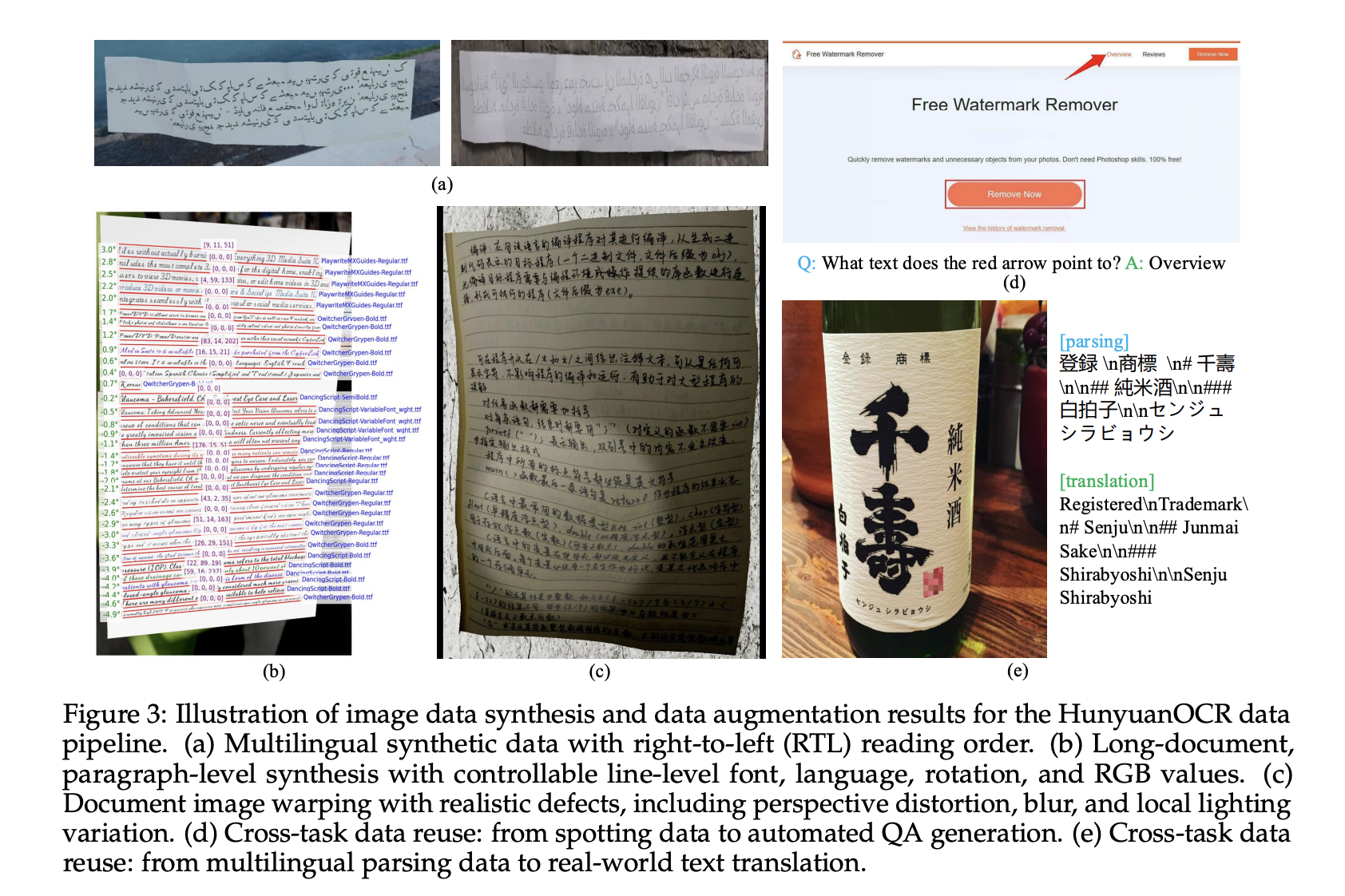
Synthetische Daten stammen von einem mehrsprachigen Generator, der Rechts-nach-Hyperlinks-Skripte und das Rendern auf Absatzebene unterstützt. Die Pipeline steuert Schriftart, Sprache, Drehung und RGB-Werte und wendet Verzerrungen, Unschärfen und lokale Beleuchtungsänderungen an, um cellular Aufnahmen und andere schwierige Bedingungen zu simulieren.
Das Vortraining besteht aus 4 Phasen. Stufe 1 führt die visuelle Sprachausrichtung mit reinem Textual content, synthetischen Parsing- und Erkennungsdaten sowie allgemeinen Untertiteldaten durch, wobei 50 B-Tokens und 8 Okay-Kontext verwendet werden. Stufe 2 führt ein multimodales Vortraining auf 300B-Tokens durch, die reinen Textual content mit synthetischen Recognizing-, Parsing-, Übersetzungs- und VQA-Beispielen mischen. Stufe 3 erweitert die Kontextlänge auf 32 KB mit 80 B-Tokens, die sich auf lange Dokumente und langen Textual content konzentrieren. Stufe 4 ist eine anwendungsorientierte, überwachte Feinabstimmung von 24 Milliarden Tokens an von Menschen kommentierten und harten Negativdaten unter Beibehaltung von 32.000 Kontexten und einheitlichen Anweisungsvorlagen.
Verstärkungslernen mit überprüfbaren Belohnungen
Nach einem überwachten Coaching wird HunyuanOCR durch verstärkendes Lernen weiter optimiert. Das Forschungsteam nutzt Group Relative Coverage Optimization GRPO und ein Reinforcement Studying with Verifiable Rewards-Setup für strukturierte Aufgaben. Beim Textual content-Recognizing basiert die Belohnung auf dem Schnittpunkt-zu-Union-Matching von Boxen in Kombination mit dem normalisierten Bearbeitungsabstand über Textual content. Beim Parsen von Dokumenten verwendet die Belohnung den normalisierten Bearbeitungsabstand zwischen der generierten Struktur und der Referenz.
Für VQA und Übersetzung verwendet das System einen LLM als Juror. VQA verwendet eine binäre Belohnung, die die semantische Übereinstimmung überprüft. Die Übersetzung verwendet ein Bewertungs-LLM im COMET-Stil mit Bewertungen in (0, 5), normalisiert auf (0, 1). Das Trainingsframework erzwingt Längenbeschränkungen und strenge Formate und weist keine Belohnung zu, wenn Ausgaben überlaufen oder das Schema brechen, was die Optimierung stabilisiert und gültige JSON- oder strukturierte Ausgaben fördert.
Benchmark-Ergebnisse, ein 1B-Modell, das mit größeren VLMs konkurriert
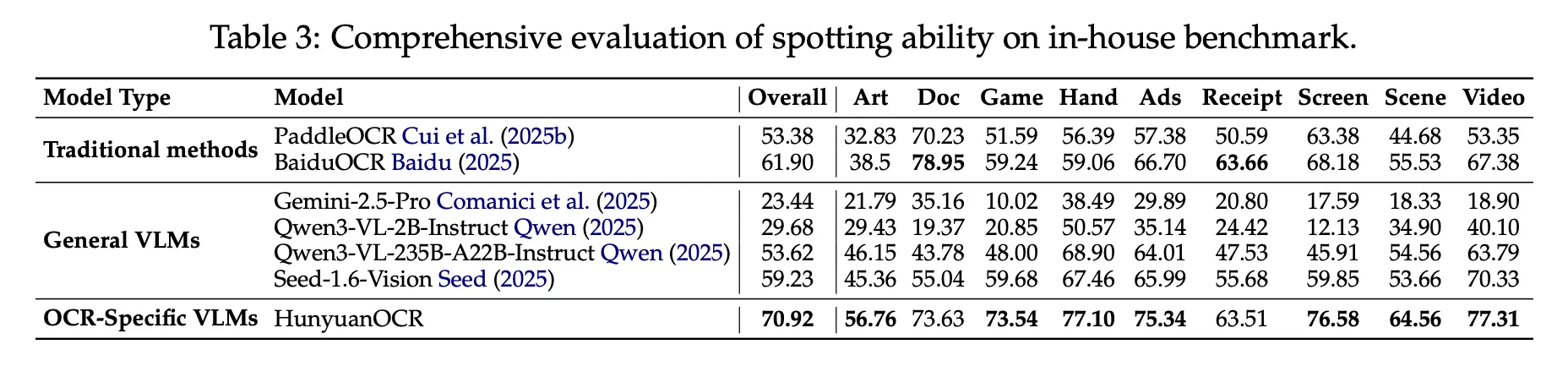
Beim internen Textual content-Recognizing-Benchmark von 900 Bildern in 9 Kategorien erreicht HunyuanOCR eine Gesamtpunktzahl von 70,92. Es übertrifft herkömmliche Pipeline-Methoden wie PaddleOCR und BaiduOCR sowie allgemeine VLMs wie Gemini 2.5 Professional, Qwen3 VL 2B, Qwen3 VL 235B und Seed 1.6 Imaginative and prescient, obwohl es weitaus weniger Parameter verwendet.
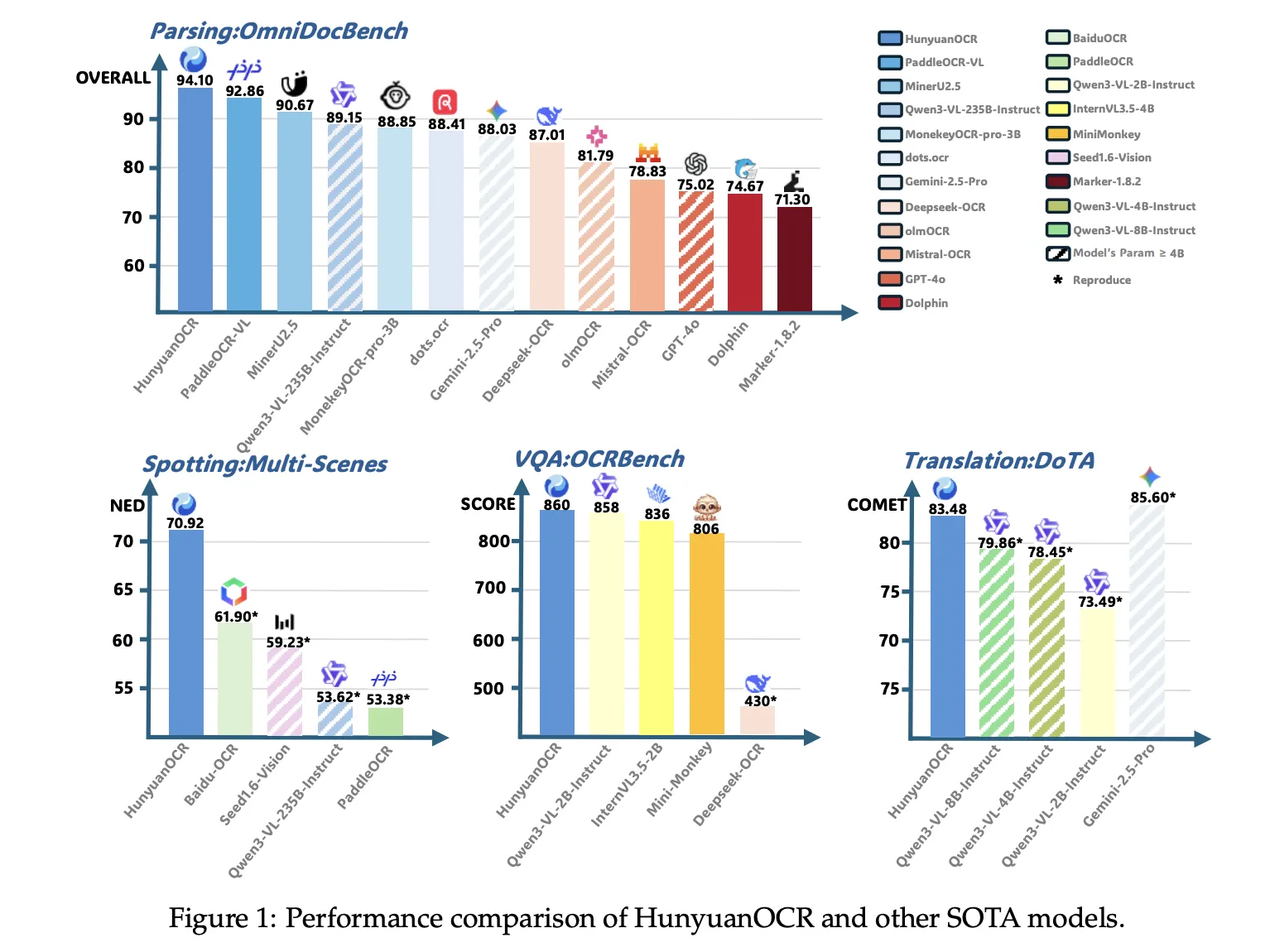
Auf OmniDocBench erreicht HunyuanOCR insgesamt 94,10, mit 94,73 für Formeln und 91,81 für Tabellen. Bei der Wild OmniDocBench-Variante, die Dokumente unter Falten und Lichtwechseln druckt und erneut erfasst, erreicht sie insgesamt 85,21 Punkte. Bei DocML, einem mehrsprachigen Parsing-Benchmark für 14 nicht-chinesische und nicht-englische Sprachen, erreicht es 91,03, und das Papier berichtet über hochmoderne Ergebnisse für alle 14 Sprachen.
Bei der Informationsextraktion und VQA erreicht HunyuanOCR eine Genauigkeit von 92,29 bei Karten, 92,53 bei Quittungen und 92,87 bei Videountertiteln. Auf OCRBench erreicht es einen Wert von 860, höher als DeepSeek OCR bei ähnlichem Maßstab und nahe an größeren allgemeinen VLMs wie Qwen3 VL 2B Instruct und Gemini 2.5 Professional.
Bei der Textual content-Bild-Übersetzung verwendet HunyuanOCR den DoTA-Benchmark und einen DocML-basierten internen Satz. Es erreicht eine starke COMET-Bewertung bei DoTA für die Übersetzung von Dokumenten aus dem Englischen ins Chinesische und das Modell gewinnt den ersten Platz im Observe 2.2 OCR free Small Mannequin des ICDAR 2025 DIMT-Wettbewerbs.
Wichtige Erkenntnisse
- Kompaktes Finish-to-Finish-OCR-VLM: HunyuanOCR ist ein 1B-Parameter-OCR-fokussiertes Imaginative and prescient-Sprachmodell, das ein ViT mit einer nativen Auflösung von 0,4B über einen MLP-Adapter mit einem Hunyuan-Sprachmodell mit 0,5B verbindet und Recognizing, Parsing, Informationsextraktion, VQA und Übersetzung in einer durchgängigen anweisungsgesteuerten Pipeline ohne externe Structure- oder Erkennungsmodule ausführt.
- Einheitliche Unterstützung für verschiedene OCR-Szenarien: Das Modell wird anhand von mehr als 200 Millionen Bildtextpaaren in 9 Szenarien trainiert, darunter Dokumente, Straßenansichten, Werbung, handschriftliche Inhalte, Screenshots, Karten und Rechnungen, Spieloberflächen und Videobilder, mit einer Abdeckung von über 130 Sprachen in der Schulung und Unterstützung für mehr als 100 Sprachen in der Bereitstellung.
- Datenpipeline plus verstärkendes Lernen: Das Coaching verwendet ein 4-Stufen-Rezept, Imaginative and prescient-Language-Alignment, multimodales Pre-Coaching, Lengthy-Context-Pre-Coaching und anwendungsorientierte überwachte Feinabstimmung, gefolgt von verstärkendem Lernen mit gruppenbezogener Richtlinienoptimierung und überprüfbaren Belohnungen für Recognizing, Parsing, VQA und Übersetzung.
- Starke Benchmark-Ergebnisse für Sub-3B-Modelle
HunyuanOCR erreicht beim OmniDocBench einen Wert von 94,1 für das Dokumentenverständnis und einen Wert von 860 beim OCRBench, was als modernstes Bildverarbeitungsmodell mit weniger als 3B-Parametern gilt und gleichzeitig mehrere kommerzielle OCR-APIs und größere offene Modelle wie Qwen3 VL 4B bei den Kern-OCR-Benchmarks übertrifft.
Redaktionelle Anmerkungen
HunyuanOCR ist ein starkes Sign dafür, dass OCR-spezifische VLMs zu einer praktischen Infrastruktur und nicht nur zu Benchmarks heranreifen. Tencent kombiniert eine 1B-Parameter-Finish-to-Finish-Architektur mit Native Imaginative and prescient Transformer, Adaptive MLP Connector und RL mit überprüfbaren Belohnungen, um ein einziges Modell bereitzustellen, das Recognizing, Parsing, IE, VQA und Übersetzung in mehr als 100 Sprachen abdeckt, und erreicht dabei Spitzenwerte bei OCRBench für Sub-3B-Modelle und 94,1 bei OmniDocBench. Insgesamt markiert HunyuanOCR einen wichtigen Wandel hin zu kompakten, anweisungsgesteuerten OCR-Engines, die für den Produktionseinsatz realistisch sind.
Schauen Sie sich das an Papier, Modellgewicht Und Repo. Schauen Sie sich gerne bei uns um GitHub-Seite für Tutorials, Codes und Notebooks. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser E-newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Asif Razzaq ist CEO von Marktechpost Media Inc.. Als visionärer Unternehmer und Ingenieur setzt sich Asif dafür ein, das Potenzial der künstlichen Intelligenz für das soziale Wohl zu nutzen. Sein jüngstes Unterfangen ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch eine ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die sowohl technisch fundiert als auch für ein breites Publikum leicht verständlich ist. Die Plattform verfügt über mehr als 2 Millionen monatliche Aufrufe, was ihre Beliebtheit beim Publikum verdeutlicht.