
Kann ein iterativer Draft-Revise-Löser, der einen latenten Scratchpad wiederholt aktualisiert, weitaus größere autoregressive LLMs auf ARC-AGI übertreffen? Samsung SAIT (Montreal) hat veröffentlicht Winziges rekursives Modell (TRM)– ein zweischichtiger rekursiver Reasoner mit ca. 7 Millionen Parametern, der Berichte erstellt 44,6–45 % Testgenauigkeit auf ARC-AGI-1 Und 7,8–8 % An ARC-AGI-2was die Ergebnisse übertrifft, die für wesentlich größere Sprachmodelle wie DeepSeek-R1, o3-mini-high und Gemini 2.5 Professional bei denselben öffentlichen Bewertungen gemeldet wurden. TRM verbessert auch Puzzle-Benchmarks Sudoku-Extrem (87,4 %) Und Labyrinthhart (85,3 %) gegenüber dem Prior Hierarchisches Argumentationsmodell (HRM, 27 Mio. Parameter)wobei weitaus weniger Parameter und ein einfacheres Trainingsrezept verwendet werden.
Was genau ist neu?
TRM entfernt die Zwei-Modul-Hierarchie und die Festkomma-Gradientennäherung von HRM zugunsten von a einzelnes kleines Netzwerk Das rekursiert auf einem latenten „Notizblock“ (z) und a aktuelle Lösungseinbettung (y):
- Einzelner winziger wiederkehrender Kern. Ersetzt die Zwei-Modul-Hierarchie von HRM durch ein zweischichtiges Netzwerk, das gemeinsam einen latenten Notizblock 𝑧 z und eine aktuelle Lösung, die 𝑦 y einbettet, verwaltet. Das Modell wechselt: suppose: replace 𝑧 ← 𝑓 ( 𝑥 , 𝑦 , 𝑧 ) z←f(x,y,z) für 𝑛 n innere Schritte; Akt: aktualisieren 𝑦 ← 𝑔 ( 𝑦 , 𝑧 ) y←g(y,z).
- Tief überwachte Rekursion. Der Suppose→Act-Block ist bis zu 16 Mal abgerollt mit gründlicher Aufsicht und einem erlernten Haltekopf, der während des Trainings verwendet wird (vollständiges Ausrollen zum Testzeitpunkt). Signale werden über (y,z)(y, z)(y,z) über Schritte hinweg übertragen.
- Voller Backprop durch die Schleife. Im Gegensatz zu HRMs einstufiger impliziter (Festkomma-)Gradient Näherung, TRM führt eine Rückwärtsausbreitung durch alle rekursiven Schritte durchwas das Forschungsteam für die Verallgemeinerung als wesentlich erachtet.
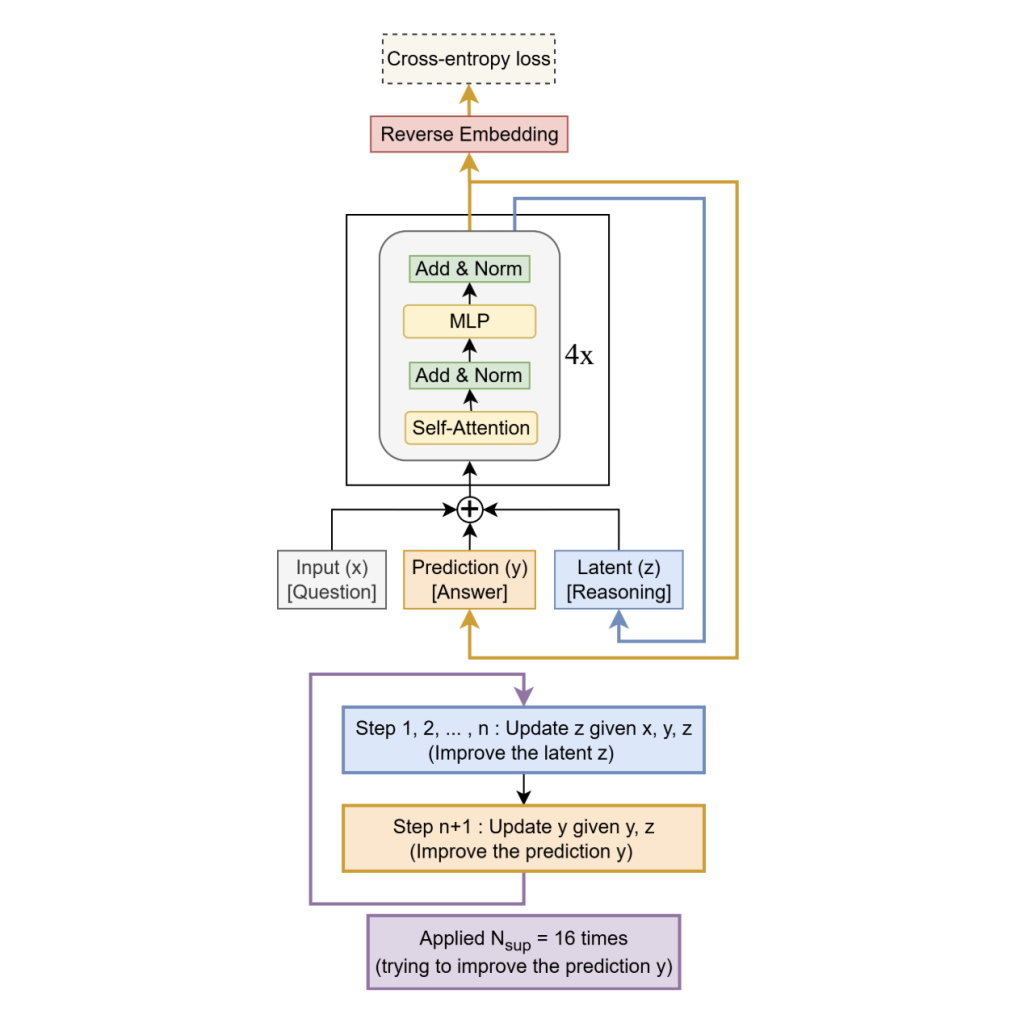
Architektonisch bleibt das leistungsstärkste Setup für ARC/Maze erhalten Selbstaufmerksamkeit; Für die kleinen festen Gitter von Sudoku tauscht das Forschungsteam die Selbstaufmerksamkeit gegen eine aus Token-Mixer im MLP-Mixer-Stil. Eine kleine EMA (exponentieller gleitender Durchschnitt) Übergewichte stabilisieren das Coaching auf begrenzten Daten. Nettotiefe wird effektiv erzeugt durch Rekursion (z.B, T = 3, n = 6) anstatt Schichten zu stapeln; bei Ablationen, zwei Schichten besser verallgemeinern als tiefere Varianten bei gleicher effektiver Rechenleistung.
Die Ergebnisse verstehen
- ARC-AGI-1 / ARC-AGI-2 (zwei Versuche): TRM-Attn (7M): 44,6 % / 7,8 % vs HRM (27 Mio.): 40,3 % / 5,0 %. Die vom Forschungsteam gemeldeten LLM-Grundwerte: DeepSeek-R1 (671B) 15,8 % / 1,3 %, o3-mini-hoch 34,5 % / 3,0 %, Gemini 2.5 Professional 37,0 % / 4,9 %; größere maßgeschneiderte Grok-4-Einträge sind höher (66,7–79,6 % / 16–29,4 %).
- Sudoku-Excessive (9×9, 1 km Zug / 423 km Take a look at): 87,4 % mit aufmerksamkeitsfreiem Mixer vs. HRM 55,0 %.
- Labyrinthhart (30×30): 85,3 % vs. HRM 74,5 %.
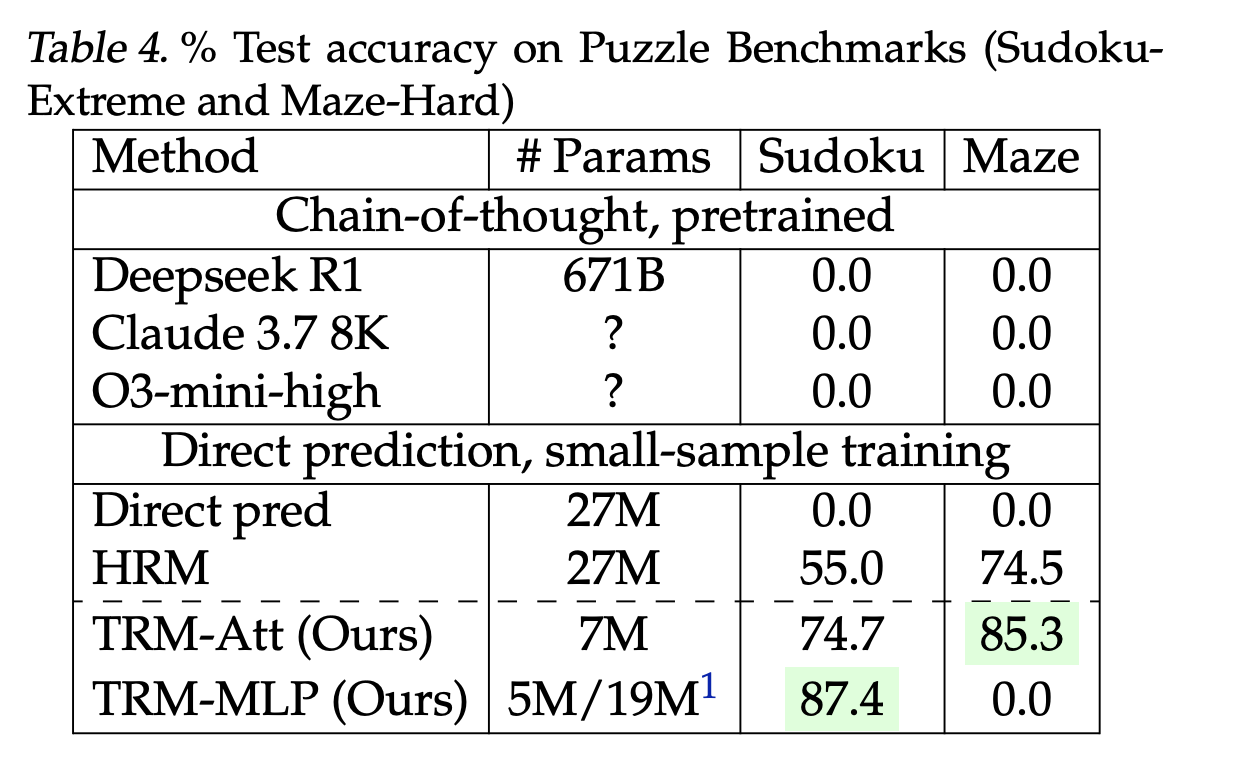
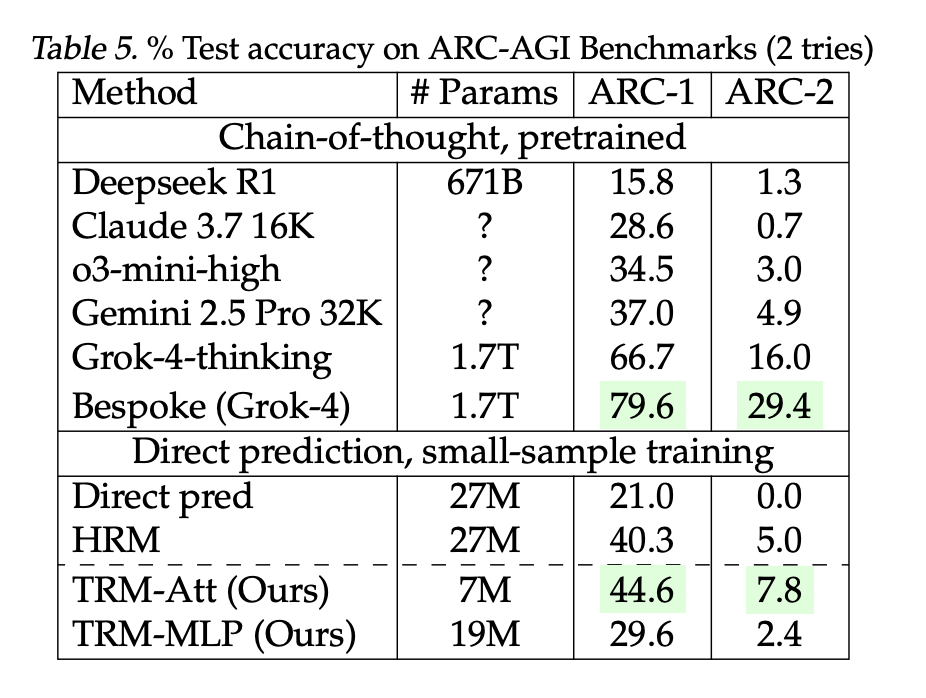
Diese sind direkte Vorhersage Modelle, die von Grund auf auf kleinen, stark erweiterten Datensätzen trainiert wurden – kein „Fewly-Shot-Prompting“. ARC bleibt das kanonische Ziel; Der breitere Kontext und die Regeln der Rangliste (z. B. ARC-AGI-2-Grenzwert für den Hauptpreis bei 85 % privatem Satz) werden von der ARC Prize Basis verfolgt.
Warum kann ein 7M-Modell bei diesen Aufgaben viel größere LLMs schlagen?
- Entscheidung-dann-Revision statt Token für Token: TRM entwirft eine vollständige Kandidatenlösung und verbessert sie dann latente iterative Konsistenzprüfungen gegen die Eingabe – Reduzierung der Belichtungsverzerrung durch autoregressive Dekodierung bei strukturierten Ausgaben.
- Rechenaufwand für Argumentation während der Testzeit, nicht für die Parameteranzahl: Effektive Tiefe entsteht durch Rekursion (emulierte Tiefe ≈ T·(n+1)·Schichten), was den Forschern zufolge bei konstanter Berechnung eine bessere Verallgemeinerung ergibt als das Hinzufügen von Ebenen.
- Strengere induktive Voreingenommenheit gegenüber Gitterbegründung: Bei kleinen festen Gittern (z. B. Sudoku) reduziert das aufmerksamkeitsfreie Mischen die Überkapazität und verbessert den Kompromiss zwischen Bias und Varianz. Die Selbstaufmerksamkeit bleibt bei größeren 30×30-Rastern erhalten.
Wichtige Erkenntnisse
- Architektur: Ein ~7M-paramiger, zweischichtiger rekursiver Löser, der latente „Denk“-Aktualisierungen 𝑧 ← 𝑓 ( 𝑥 , 𝑦 , 𝑧 ) z←f(x,y,z) und eine „Akt“-Verfeinerung 𝑦 ← 𝑔 ( 𝑦 , 𝑧 ) abwechselt y←g(y,z), unter intensiver Aufsicht bis zu 16 Schritte abgerollt; Gradienten werden durch die vollständige Rekursion propagiert (keine Festkomma-/IFT-Näherung).
- Ergebnisse: Berichte ~44,6–45 % An ARC-AGI-1 Und ~7,8–8 % An ARC-AGI-2 (zwei Versuche)und übertrifft damit mehrere viel größere LLMs, die im Vergleich der Forschungsarbeit genannt wurden (z. B. Gemini 2.5 Professional, o3-mini-high, DeepSeek-R1) unter dem angegebenen Evaluierungsprotokoll.
- Effizienz/Muster: Zeigt, dass die Zuweisung von Testzeitberechnungen zur rekursiven Verfeinerung (Tiefe durch Entrollen) die Parameterskalierung bei symbolisch-geometrischen Aufgaben übertreffen kann und ein kompaktes, von Grund auf neu entwickeltes Rezept mit öffentlich veröffentlichtem Code bietet.
Diese Untersuchung demonstriert einen zweischichtigen rekursiven Löser mit ca. 7 Millionen Parametern, der bis zu 16 Entwurfs-Überarbeitungs-Zyklen mit ca. 6 latenten Aktualisierungen professional Zyklus abwickelt und ca. 45 % für ARC-AGI-1 und ca. 8 % (zwei Versuche) für ARC-AGI-2 meldet. Das Forschungsteam veröffentlichte Code auf GitHub. ARC-AGI bleibt im großen Maßstab ungelöst (Ziel 85 % für ARC-AGI-2), sodass der Beitrag eher ein Ergebnis der Architektureffizienz als ein allgemeiner Schlussfolgerungsdurchbruch ist.
Schauen Sie sich das an Technisches Papier Und GitHub-Seite. Schauen Sie sich gerne bei uns um GitHub-Seite für Tutorials, Codes und Notebooks. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser E-newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Asif Razzaq ist CEO von Marktechpost Media Inc.. Als visionärer Unternehmer und Ingenieur setzt sich Asif dafür ein, das Potenzial der künstlichen Intelligenz für das soziale Wohl zu nutzen. Sein jüngstes Unterfangen ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch eine ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die sowohl technisch fundiert als auch für ein breites Publikum leicht verständlich ist. Die Plattform verfügt über mehr als 2 Millionen monatliche Aufrufe, was ihre Beliebtheit beim Publikum verdeutlicht.