In diesem Artikel erfahren Sie, wie Vektordatenbanken funktionieren, von der Grundidee der Ähnlichkeitssuche bis hin zu den Indizierungsstrategien, die eine groß angelegte Recherche praktisch machen.
Zu den Themen, die wir behandeln werden, gehören:
- Wie Einbettungen unstrukturierte Daten in Vektoren umwandeln, die nach Ähnlichkeit durchsucht werden können.
- Wie Vektordatenbanken die Suche nach nächsten Nachbarn, Metadatenfilterung und Hybridabruf unterstützen.
- Wie Indizierungstechniken wie HNSW, IVF und PQ zur Skalierung der Vektorsuche in der Produktion beitragen.
Verschwenden wir keine Zeit mehr.
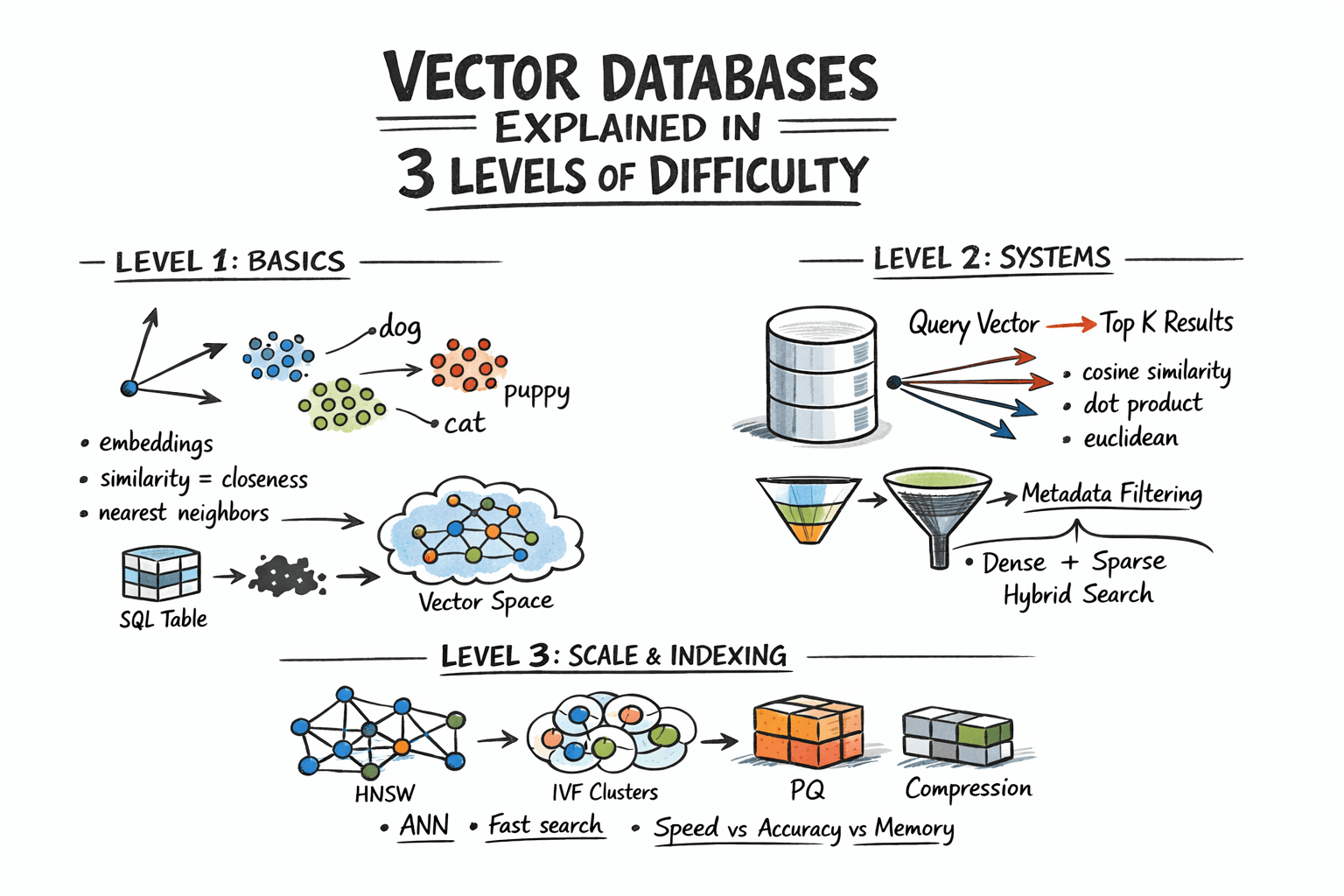
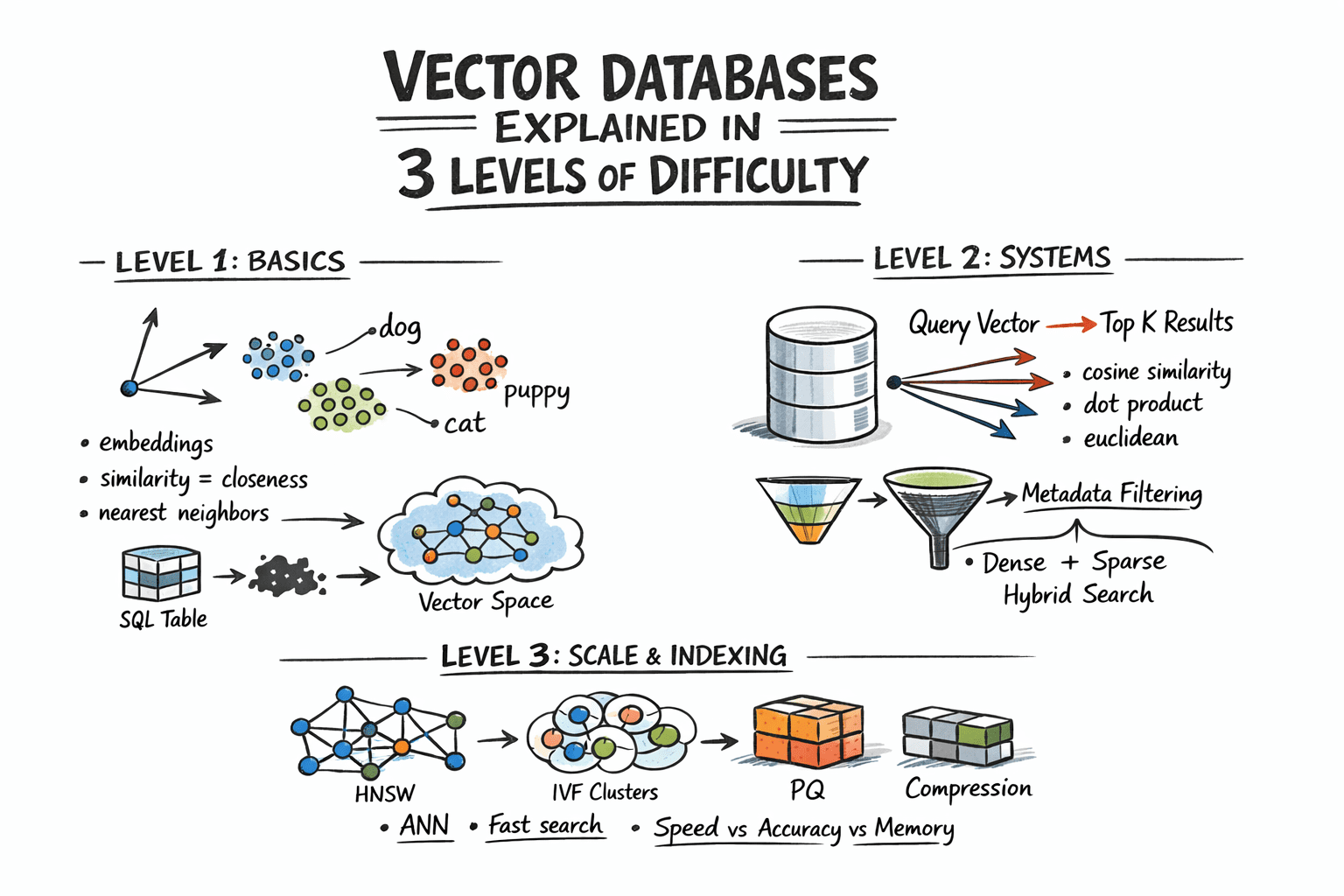
Vektordatenbanken in 3 Schwierigkeitsgraden erklärt
Bild vom Autor
Einführung
Herkömmliche Datenbanken beantworten eine klar definierte Frage: Existiert der Datensatz, der diesen Kriterien entspricht? Vektordatenbanken Beantworten Sie eine andere Frage: Welche Datensätze sind diesem am ähnlichsten? Dieser Wandel ist wichtig, weil eine riesige Klasse moderner Daten – Dokumente, Bilder, Benutzerverhalten, Audio – kann nicht nach exakter Übereinstimmung durchsucht werden. Die richtige Abfrage lautet additionally nicht „finde dies“, sondern „finde, was diesem nahe kommt“. Einbetten von Modellen Machen Sie dies möglich, indem Sie Rohinhalte in Vektoren umwandeln, wobei geometrische Nähe semantischer Ähnlichkeit entspricht.
Das Drawback ist jedoch die Größe. Der Vergleich eines Abfragevektors mit jedem gespeicherten Vektor bedeutet Milliarden von Gleitkommaoperationen bei Produktionsdatengrößen, und diese Mathematik macht eine Echtzeitsuche unpraktisch. Vektordatenbanken lösen dieses Drawback mit Näherungsalgorithmen für den nächsten Nachbarn, die die überwiegende Mehrheit der Kandidaten überspringen und dennoch zu einem Bruchteil der Kosten nahezu identische Ergebnisse wie eine umfassende Suche liefern.
In diesem Artikel wird erklärt, wie das auf drei Ebenen funktioniert: das grundlegende Ähnlichkeitsproblem und was Vektoren ermöglichen, wie Produktionssysteme Einbettungen mit Filterung und Hybridsuche speichern und abfragen und schließlich die Indizierungsalgorithmen und Architekturentscheidungen, die dafür sorgen, dass alles im großen Maßstab funktioniert.
Ebene 1: Das Ähnlichkeitsproblem verstehen
Herkömmliche Datenbanken speichern strukturierte Daten – Zeilen, Spalten, Ganzzahlen, Zeichenfolgen – und rufen sie mit exakten Suchvorgängen oder Bereichsabfragen ab. SQL ist hierfür schnell und präzise. Viele reale Daten sind jedoch nicht strukturiert. Textdokumente, Bilder, Audio- und Benutzerverhaltensprotokolle passen nicht genau in Spalten, und „genaue Übereinstimmung“ ist für sie die falsche Abfrage.
Die Lösung besteht darin, diese Daten als Vektoren darzustellen: Arrays mit Gleitkommazahlen fester Länge. Ein Einbettungsmodell wie Textual content-Embedding-3-small von OpenAIoder ein Visionsmodell für Bilder, wandelt Rohinhalte in einen Vektor um, der seine semantische Bedeutung erfasst. Ähnliche Inhalte erzeugen ähnliche Vektoren. Beispielsweise liegen das Wort „Hund“ und das Wort „Welpe“ im Vektorraum geometrisch nahe beieinander. Auch ein Foto einer Katze und eine Zeichnung einer Katze landen in der Nähe.
Eine Vektordatenbank speichert diese Einbettungen und ermöglicht die Suche nach Ähnlichkeit: „Finde mir die 10 Vektoren, die diesem Abfragevektor am nächsten kommen.“ Dies wird als Suche nach nächsten Nachbarn bezeichnet.
Ebene 2: Vektoren speichern und abfragen
Einbettungen
Bevor eine Vektordatenbank etwas bewirken kann, müssen Inhalte in Vektoren umgewandelt werden. Dies geschieht durch die Einbettung von Modellen – neuronalen Netzen, die Eingaben in einen dichten Vektorraum abbilden, typischerweise mit 256 bis 4096 Dimensionen, je nach Modell. Die spezifischen Zahlen im Vektor haben keine direkte Interpretation; Was zählt, ist die Geometrie: Nahe Vektoren bedeuten ähnliche Inhalte.
Sie rufen eine Einbettungs-API auf oder führen selbst ein Modell aus, erhalten ein Array von Floats zurück und speichern dieses Array zusammen mit Ihren Dokumentmetadaten.
Entfernungsmetriken
Ähnlichkeit wird als geometrischer Abstand zwischen Vektoren gemessen. Drei Metriken sind üblich:
- Kosinusähnlichkeit misst den Winkel zwischen zwei Vektoren und ignoriert dabei die Größe. Es wird häufig für Texteinbettungen verwendet, bei denen die Richtung wichtiger ist als die Länge.
- Euklidischer Abstand Misst die geradlinige Entfernung im Vektorraum. Es ist nützlich, wenn Größe eine Bedeutung hat.
- Punktprodukt ist schnell und funktioniert intestine, wenn Vektoren normalisiert werden. Viele Einbettungsmodelle sind für die Verwendung geschult.
Die Wahl der Metrik sollte mit der Artwork und Weise übereinstimmen, wie Ihr Einbettungsmodell trainiert wurde. Die Verwendung der falschen Metrik verschlechtert die Ergebnisqualität.
Das Drawback des nächsten Nachbarn
Das Finden der genauen nächsten Nachbarn ist in kleinen Datensätzen trivial: Berechnen Sie den Abstand von der Abfrage zu jedem Vektor, sortieren Sie die Ergebnisse und geben Sie den Anfang zurück Ok. Dies wird als Brute-Power- oder Flat-Suche bezeichnet und ist zu 100 % genau. Es skaliert auch linear mit der Datensatzgröße. Bei 10 Millionen Vektoren mit jeweils 1536 Dimensionen ist eine flache Suche für Echtzeitabfragen zu langsam.
Die Lösung ist ungefährer nächster Nachbar (ANN) Algorithmen. Diese tauschen ein geringes Maß an Genauigkeit gegen große Geschwindigkeitsgewinne ein. Produktionsvektordatenbanken führen unter der Haube ANN-Algorithmen aus. Die spezifischen Algorithmen, ihre Parameter und ihre Kompromisse werden wir im nächsten Degree untersuchen.
Metadatenfilterung
Die reine Vektorsuche liefert weltweit die semantisch ähnlichsten Elemente. In der Praxis wünscht man sich in der Regel etwas Ähnliches wie: „Finden Sie die ähnlichsten Dokumente, die diesem Benutzer gehören und nach diesem Datum erstellt wurden.“ Das ist Hybrid-Retrieval: Vektorähnlichkeit kombiniert mit Attributfiltern.
Die Implementierungen variieren. Die Vorfilterung wendet zuerst den Attributfilter an und führt dann ANN für die verbleibende Teilmenge aus. Bei der Nachfilterung wird zuerst ANN ausgeführt und dann die Ergebnisse gefiltert. Die Vorfilterung ist genauer, aber bei selektiven Abfragen teurer. Die meisten Produktionsdatenbanken verwenden eine Variante der Vorfilterung mit intelligenter Indizierung, um die Geschwindigkeit zu gewährleisten.
Hybridsuche: dicht + spärlich
Eine reine dichte Vektorsuche kann die Präzision auf Schlüsselwortebene verfehlen. Eine Abfrage nach „GPT-5-Veröffentlichungsdatum“ tendiert semantisch möglicherweise eher zu allgemeinen KI-Themen als zu dem spezifischen Dokument, das den genauen Ausdruck enthält. Die Hybridsuche kombiniert dichtes ANN mit spärlichem Abruf (BM25 oder TF-IDF), um semantisches Verständnis und Schlüsselwortgenauigkeit zu vereinen.
Der Standardansatz besteht darin, eine dichte und spärliche Suche parallel auszuführen und dann die Ergebnisse mit zu kombinieren reziproke Rangfusion (RRF) – ein rangbasierter Zusammenführungsalgorithmus, der keine Normalisierung der Bewertung erfordert. Die meisten Produktionssysteme unterstützen jetzt nativ die Hybridsuche.
Ebene 3: Indexierung für Skalierung
Ungefähre Algorithmen für den nächsten Nachbarn
Die drei wichtigsten Algorithmen für den ungefähren nächsten Nachbarn belegen jeweils einen anderen Punkt auf der Kompromissfläche zwischen Geschwindigkeit, Speichernutzung und Abruf.
Hierarchisch navigierbare kleine Welt (HNSW) erstellt einen mehrschichtigen Graphen, in dem jeder Vektor ein Knoten ist und dessen Kanten ähnliche Nachbarn verbinden. Höhere Schichten sind spärlich und ermöglichen eine schnelle Durchquerung großer Entfernungen. Die unteren Schichten sind für eine präzise lokale Suche dichter. Zum Zeitpunkt der Abfrage springt der Algorithmus durch dieses Diagramm zu den nächsten Nachbarn. HNSW ist schnell, speicherhungrig und liefert einen hervorragenden Rückruf. Dies ist in vielen modernen Systemen die Standardeinstellung.
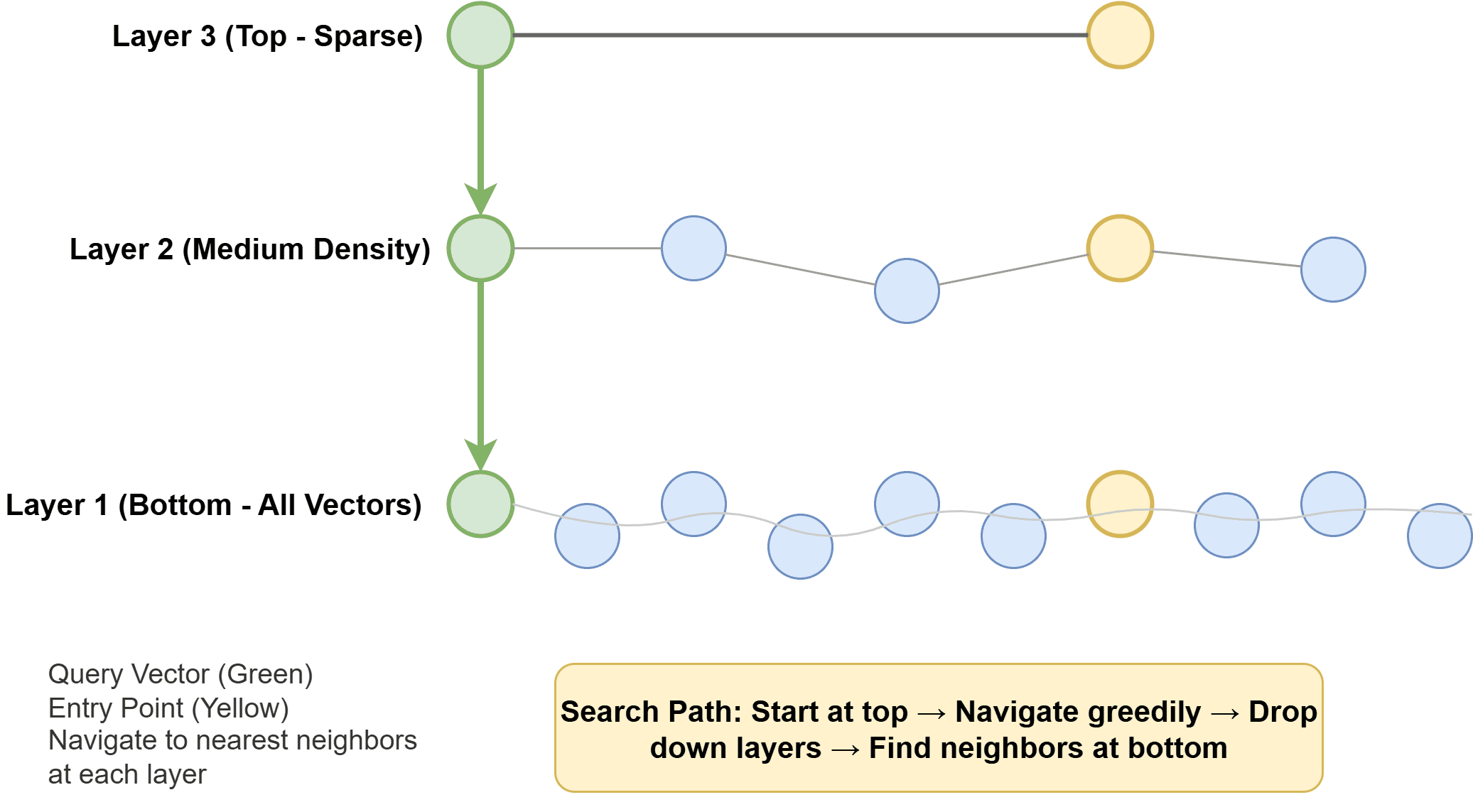
Wie die hierarchisch navigierbare kleine Welt funktioniert
Invertierter Dateiindex (IVF) gruppiert Vektoren mithilfe von k-means in Gruppen, erstellt einen invertierten Index, der jeden Cluster seinen Mitgliedern zuordnet, und durchsucht dann zum Zeitpunkt der Abfrage nur die nächstgelegenen Cluster. IVF verbraucht weniger Speicher als HNSW, ist aber oft etwas langsamer und erfordert einen Trainingsschritt zum Aufbau der Cluster.
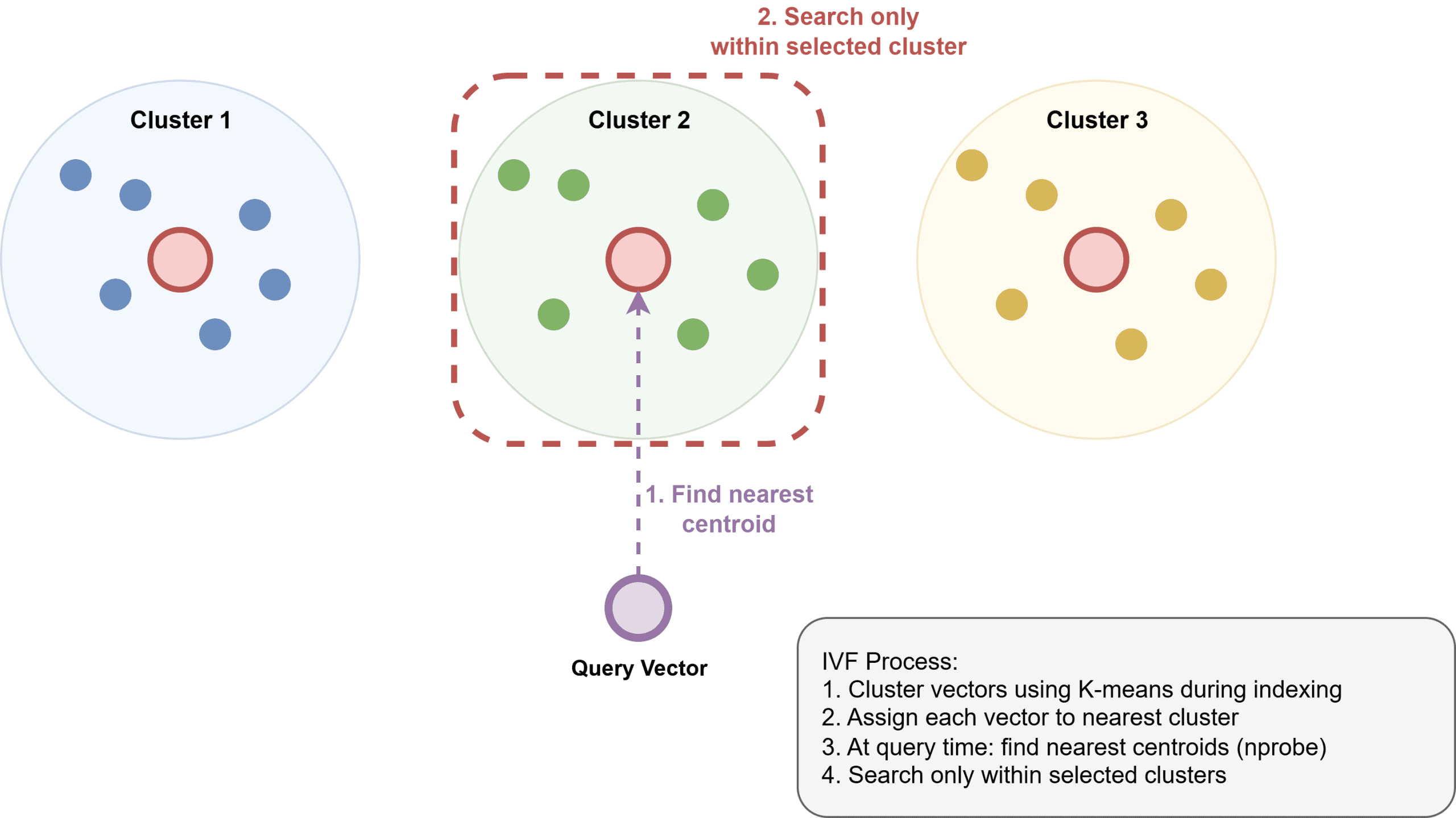
So funktioniert der invertierte Dateiindex
Produktquantisierung (PQ) komprimiert Vektoren, indem es sie in Untervektoren unterteilt und jeden einzelnen in ein Codebuch quantisiert. Dadurch kann die Speichernutzung um das 4- bis 32-fache reduziert werden, was Datensätze im Milliardenmaßstab ermöglicht. Es wird oft in Kombination mit IVF als IVF-PQ in Systemen wie verwendet Faiss.
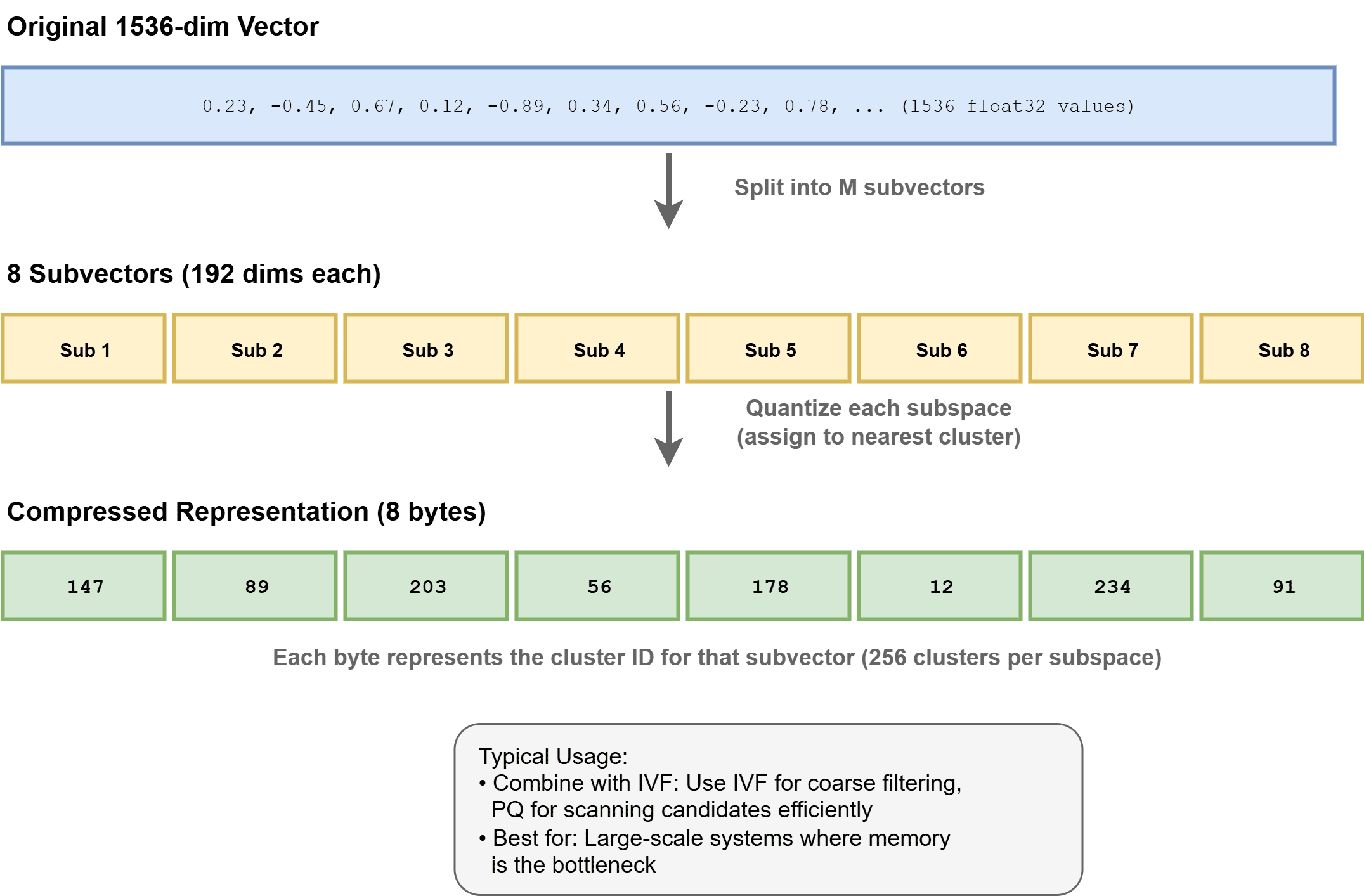
So funktioniert die Produktquantisierung
Indexkonfiguration
HNSW hat zwei Hauptparameter: ef_construction Und M:
ef_constructionsteuert, wie viele Nachbarn bei der Indexerstellung berücksichtigt werden. Höhere Werte verbessern im Allgemeinen die Erinnerung, der Aufbau dauert jedoch länger.Msteuert die Anzahl der bidirektionalen Verbindungen professional Knoten. HöherMverbessert normalerweise die Erinnerung, erhöht jedoch die Speichernutzung.
Sie passen diese basierend auf Ihrem Rückruf, Ihrer Latenz und Ihrem Speicherbudget an.
Zum Zeitpunkt der Abfrage ef_search steuert, wie viele Kandidaten untersucht werden. Eine Erhöhung verbessert die Erinnerung auf Kosten der Latenz. Dies ist ein Laufzeitparameter, den Sie optimieren können, ohne den Index neu zu erstellen.
Für IVF, nlist legt die Anzahl der Cluster fest und nprobe Legt fest, wie viele Cluster zum Zeitpunkt der Abfrage durchsucht werden sollen. Mehr Cluster können die Präzision verbessern, erfordern aber auch mehr Speicher. Höher nprobe verbessert die Erinnerung, erhöht aber die Latenz. Lesen Wie können die Parameter eines IVF-Index (wie die Anzahl der Cluster nlist und die Anzahl der Sonden nprobe) so abgestimmt werden, dass ein Zielrückruf mit der schnellstmöglichen Abfragegeschwindigkeit erreicht wird? um mehr zu erfahren.
Rückruf vs. Latenz
ANN lebt auf einer Kompromissoberfläche. Sie können jederzeit eine bessere Erinnerung erzielen, indem Sie einen größeren Teil des Indexes durchsuchen, aber Sie bezahlen dafür mit Latenz und Rechenleistung. Vergleichen Sie Ihre spezifischen Datensätze und Abfragemuster. Ein Recall@10 von 0,95 könnte für eine Suchanwendung großartig sein; Ein Empfehlungssystem benötigt möglicherweise 0,99.
Skalieren und Sharding
Ein einzelner HNSW-Index kann je nach Dimensionalität und verfügbarem RAM bis zu etwa 50–100 Millionen Vektoren in den Speicher eines Computer systems aufnehmen. Darüber hinaus führen Sie ein Shard durch: Partitionieren Sie den Vektorraum auf Knoten, verteilen Sie Abfragen auf Shards und führen Sie dann die Ergebnisse zusammen. Dies führt zu einem Koordinationsaufwand und erfordert eine sorgfältige Auswahl der Shard-Schlüssel, um Hotspots zu vermeiden. Um mehr zu erfahren, lesen Sie Wie skaliert die Vektorsuche mit der Datengröße?
Speicher-Backends
Für eine schnelle ANN-Suche werden Vektoren häufig im RAM gespeichert. Metadaten werden normalerweise separat gespeichert, häufig in einem Schlüsselwert- oder Spaltenspeicher. Einige Systeme unterstützen speicherzugeordnete Dateien zur Indizierung von Datensätzen, die größer als der Arbeitsspeicher sind und bei Bedarf auf die Festplatte übertragen werden. Dadurch wird etwas Latenz gegen Skalierung getauscht.
ANN-Indizes auf der Festplatte wie DiskANN (entwickelt von Microsoft) sind für die Ausführung auf SSDs mit minimalem RAM ausgelegt. Sie erreichen einen guten Rückruf und Durchsatz für sehr große Datensätze, bei denen der Speicher die Bindungsbeschränkung darstellt.
Vektordatenbankoptionen
Vektorsuchwerkzeuge lassen sich im Allgemeinen in drei Kategorien einteilen.
Zunächst können Sie auswählen speziell erstellte Vektordatenbanken wie zum Beispiel:
- Tannenzapfen: eine vollständig verwaltete, betriebsfreie Lösung
- Qdrant: ein Open-Supply-System auf Rust-Foundation mit starken Filterfunktionen
- Weben: eine Open-Supply-Possibility mit integriertem Schema und modularen Funktionen
- Milvus: eine leistungsstarke Open-Supply-Vektordatenbank, die für die groß angelegte Ähnlichkeitssuche mit Unterstützung für verteilte Bereitstellungen und GPU-Beschleunigung entwickelt wurde
Zweitens gibt es Erweiterungen bestehender Systeme, wie z pgvector für Postgreswas im kleinen bis mittleren Maßstab intestine funktioniert.
Drittens gibt es Bibliotheken wie:
- Faiss entwickelt von Meta
- Belästigen von Spotify, optimiert für leseintensive Workloads
Für neue RAG-Anwendungen (Retrieval-Augmented Technology) in mittlerem Umfang ist pgvector häufig ein guter Ausgangspunkt, wenn Sie Postgres bereits verwenden, da es den Betriebsaufwand minimiert. Wenn Ihre Anforderungen wachsen – insbesondere bei größeren Datensätzen oder komplexeren Filterungen – können Qdrant oder Weaviate zu überzeugenderen Optionen werden, während Pinecone ideally suited ist, wenn Sie eine vollständig verwaltete Lösung ohne zu wartende Infrastruktur bevorzugen.
Zusammenfassung
Vektordatenbanken lösen ein echtes Drawback: schnell herauszufinden, was im großen Maßstab semantisch ähnlich ist. Die Kernidee ist einfach: Inhalte als Vektoren einbetten und nach Entfernung suchen. Die Implementierungsdetails – HNSW vs. IVF, Recall-Tuning, Hybridsuche und Sharding – sind im Produktionsmaßstab von großer Bedeutung.
Hier sind einige Ressourcen, die Sie weiter erkunden können:
Viel Spaß beim Lernen!