Frustrierende Probleme beim Debuggen im Information-Science-Code sind keine Syntaxfehler oder logische Fehler. Sie stammen vielmehr aus Code, der genau das tut, was er tun soll, sich dabei aber viel Zeit lässt.
Funktioneller, aber ineffizienter Code kann einen massiven Engpass in einem Information-Science-Workflow darstellen. In diesem Artikel werde ich eine kurze Einführung und einen Rundgang geben py-spyein leistungsstarkes Instrument zur Profilierung Ihres Python-Codes. Es kann genau bestimmen, wo Ihr Programm die meiste Zeit verbringt, sodass Ineffizienzen erkannt und behoben werden können.
Beispielproblem
Lassen Sie uns eine einfache Forschungsfrage aufstellen, um Code zu schreiben:
„Welcher Abflughafen hat bei allen Flügen zwischen US-Bundesstaaten und Territorien im Durchschnitt die längsten Flüge?“
Unten finden Sie ein einfaches Python-Skript zur Beantwortung dieser Forschungsfrage unter Verwendung von Daten, die aus dem abgerufen wurden Büro für Verkehrsstatistik (BTS). Der Datensatz besteht aus Daten aller Flüge innerhalb der US-Bundesstaaten und Territorien zwischen Januar und Juni 2025 mit Informationen zu den Abflug- und Zielflughäfen. Es sind ungefähr 3,5 Millionen Zeilen.
Es berechnet die Haversine-Distanz – der kürzeste Abstand zwischen zwei Punkten auf einer Kugel – für jeden Flug. Anschließend gruppiert es die Ergebnisse nach Abflughafen, um die durchschnittliche Entfernung zu ermitteln, und meldet die fünf besten.
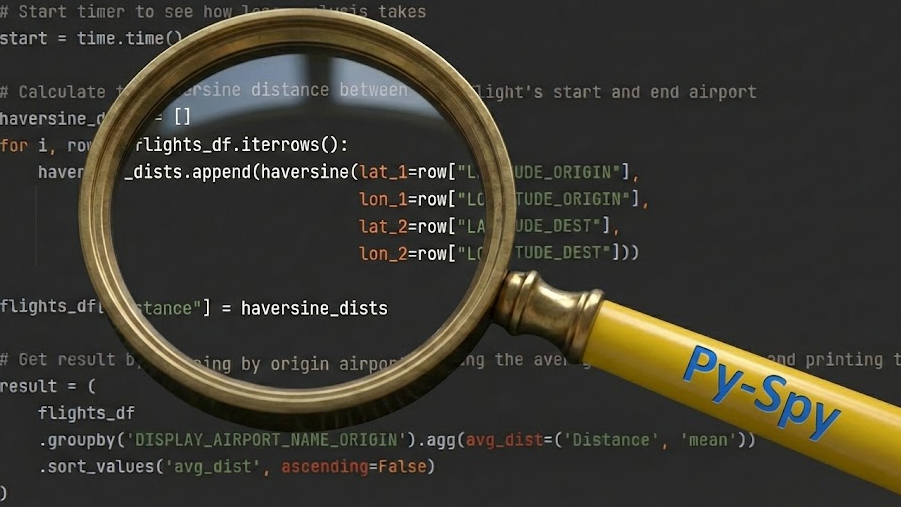
import pandas as pd
import math
import time
def haversine(lat_1, lon_1, lat_2, lon_2):
"""Calculate the Haversine Distance between two latitude and longitude factors"""
lat_1_rad = math.radians(lat_1)
lon_1_rad = math.radians(lon_1)
lat_2_rad = math.radians(lat_2)
lon_2_rad = math.radians(lon_2)
delta_lat = lat_2_rad - lat_1_rad
delta_lon = lon_2_rad - lon_1_rad
R = 6371 # Radius of the earth in km
return 2*R*math.asin(math.sqrt(math.sin(delta_lat/2)**2 + math.cos(lat_1_rad)*math.cos(lat_2_rad)*(math.sin(delta_lon/2))**2))
if __name__ == '__main__':
# Load in flight information to a dataframe
flight_data_file = r"./information/2025_flight_data.csv"
flights_df = pd.read_csv(flight_data_file)
# Begin timer to see how lengthy evaluation takes
begin = time.time()
# Calculate the haversine distance between every flight's begin and finish airport
haversine_dists = ()
for i, row in flights_df.iterrows():
haversine_dists.append(haversine(lat_1=row("LATITUDE_ORIGIN"),
lon_1=row("LONGITUDE_ORIGIN"),
lat_2=row("LATITUDE_DEST"),
lon_2=row("LONGITUDE_DEST")))
flights_df("Distance") = haversine_dists
# Get end result by grouping by origin airport, taking the common flight distance and printing the highest 5
end result = (
flights_df
.groupby('DISPLAY_AIRPORT_NAME_ORIGIN').agg(avg_dist=('Distance', 'imply'))
.sort_values('avg_dist', ascending=False)
)
print(end result.head(5))
# Finish timer and print evaluation time
finish = time.time()
print(f"Took {finish - begin} s")Das Ausführen dieses Codes liefert die folgende Ausgabe:
avg_dist
DISPLAY_AIRPORT_NAME_ORIGIN
Pago Pago Worldwide 4202.493567
Guam Worldwide 3142.363005
Luis Munoz Marin Worldwide 2386.141780
Ted Stevens Anchorage Worldwide 2246.530036
Daniel Okay Inouye Worldwide 2211.857407
Took 169.8935534954071 sDiese Ergebnisse sind sinnvoll, da sich die aufgeführten Flughäfen jeweils in Amerikanisch-Samoa, Guam, Puerto Rico, Alaska und Hawaii befinden. Dies sind alles Orte außerhalb der angrenzenden Vereinigten Staaten, an denen man mit langen durchschnittlichen Flugentfernungen rechnen muss.
Das Downside hierbei sind nicht die Ergebnisse – die gültig sind – sondern die Ausführungszeit: quick drei Minuten! Während drei Minuten für einen einmaligen Durchlauf akzeptabel sein könnten, werden sie während der Entwicklung zu einem Produktivitätskiller. Stellen Sie sich dies als Teil einer längeren Datenpipeline vor. Jedes Mal, wenn ein Parameter angepasst, ein Fehler behoben oder eine Zelle erneut ausgeführt wird, sind Sie gezwungen, untätig zu bleiben, während das Programm ausgeführt wird. Diese Reibung unterbricht Ihren Fluss und macht eine schnelle Analyse zu einer ganztägigen Angelegenheit.
Nun wollen wir sehen, wie py-spy kann uns helfen, genau zu diagnostizieren, welche Leitungen so lange dauern.
Was ist Py-Spy?
Um zu verstehen, was py-spy Es hilft, zu vergleichen, was es tut und welche Vorteile es mit sich bringt py-spy zum integrierten Python-Profiler cProfile.
cProfile: Das ist ein Tracing-Profilerdie bei jedem Funktionsaufruf ähnlich wie eine Stoppuhr funktioniert. Die Zeit zwischen jedem Funktionsaufruf und jeder Rückgabe wird gemessen und gemeldet. Dies ist zwar sehr genau, verursacht jedoch einen erheblichen Mehraufwand, da der Profiler ständig anhalten und Daten aufzeichnen muss, was das Skript erheblich verlangsamen kann.py-spy: Das ist ein Sampling-ProfilerEs funktioniert ähnlich wie eine Hochgeschwindigkeitskamera, die das gesamte Programm auf einmal betrachtet.py-spybefindet sich vollständig außerhalb des laufenden Python-Skripts und erstellt hochfrequente Schnappschüsse des Programmstatus. Es betrachtet den gesamten „Name Stack“, um genau zu sehen, welche Codezeile ausgeführt wird und welche Funktion sie aufgerufen hat, bis hin zur obersten Ebene.
Laufender Py-Spion
Um zu laufen py-spy auf einem Python-Skript, dem py-spy Die Bibliothek muss in der Python-Umgebung installiert werden.
pip set up py-spySobald die py-spy Wenn die Bibliothek installiert ist, kann unser Skript durch Ausführen des folgenden Befehls im Terminal profiliert werden:
py-spy file -o profile.svg -r 100 -- python fundamental.pyHier sehen Sie, was jeder Teil dieses Befehls tatsächlich bewirkt:
py-spy: Ruft das Instrument auf.file: Das sagtpy-spyum den „Aufzeichnungsmodus“ zu verwenden, der das Programm während der Ausführung kontinuierlich überwacht und die Daten speichert.-o profile.svg: Dies gibt den Namen und das Format der Ausgabedatei an und weist an, die Ergebnisse als SVG-Datei mit dem Namen auszugebenprofile.svg.-r 100: Dies gibt die Abtastrate an und legt sie auf 100 Mal professional Sekunde fest. Das bedeutet daspy-spyüberprüft 100 Mal professional Sekunde, was das Programm tut.--: Dies trennt diepy-spyBefehl aus dem Python-Skriptbefehl. Es erzähltpy-spydass alles, was auf dieses Flag folgt, der auszuführende Befehl und keine Argumente dafür istpy-spyselbst.python fundamental.py: Dies ist der Befehl zum Ausführen des Python-Skripts, mit dem ein Profil erstellt werden sollpy-spyin diesem Fall läuftfundamental.py.
Notiz: Wenn es unter Linux läuft, sudo Privilegien sind oft eine Voraussetzung für die Ausführung py-spyaus Sicherheitsgründen.
Nachdem dieser Befehl ausgeführt wurde, wird eine Ausgabedatei erstellt profile.svg wird angezeigt, was uns einen tieferen Einblick in die Teile des Codes ermöglicht, die am längsten dauern.
Py-Spy-Ausgabe

Ausgabe öffnen profile.svg verrät die Visualisierung, die py-spy hat erstellt, wie viel Zeit unser Programm in verschiedenen Teilen des Codes verbracht hat. Dies wird als a bezeichnet Eiszapfendiagramm (oder manchmal a Flammendiagramm wenn die y-Achse invertiert ist) und wird wie folgt interpretiert:
- Barren: Jeder farbige Balken stellt eine bestimmte Funktion dar, die während der Ausführung des Programms aufgerufen wurde.
- X-Achse (Bevölkerung): Die horizontale Achse stellt die Sammlung aller während der Profilierung entnommenen Proben dar. Sie sind so gruppiert, dass die Breite eines bestimmten Balkens den Anteil der Gesamtproben darstellt, die das Programm in der durch diesen Balken dargestellten Funktion hatte. Notiz: Das ist nicht eine Zeitleiste; Die Reihenfolge stellt nicht dar, wann die Funktion aufgerufen wurde, sondern nur die insgesamt aufgewendete Zeit.
- Y-Achse (Stapeltiefe): Die vertikale Achse stellt den Aufrufstapel dar. Die obere Leiste mit der Bezeichnung „Alle“ stellt das gesamte Programm dar, und die Balken darunter stellen Funktionen dar, die von „Alle“ aufgerufen werden. Dies wird rekursiv fortgesetzt, wobei jeder Balken in die Funktionen zerlegt wird, die während seiner Ausführung aufgerufen wurden. Die ganz untere Leiste zeigt die Funktion, die zum Zeitpunkt der Probenentnahme tatsächlich auf der CPU ausgeführt wurde.
Interaktion mit dem Diagramm
Während das Bild oben statisch ist, handelt es sich um das tatsächliche .svg Datei generiert von py-spy ist vollständig interaktiv. Wenn Sie es in einem Webbrowser öffnen, können Sie:
- Suchen (Strg+F): Markieren Sie bestimmte Funktionen, um zu sehen, wo sie im Stapel angezeigt werden.
- Zoom: Klicken Sie auf eine beliebige Leiste, um diese bestimmte Funktion und ihre untergeordneten Funktionen zu vergrößern und so komplexe Teile des Aufrufstapels zu isolieren.
- Schweben: Wenn Sie den Mauszeiger über eine beliebige Leiste bewegen, werden der spezifische Funktionsname, der Dateipfad, die Zeilennummer und der genaue Prozentsatz der verbrauchten Zeit angezeigt.
Die wichtigste Regel zum Lesen des Eiszapfendiagramms lautet einfach: Je breiter der Balken, desto häufiger ist die Funktion. Wenn sich eine Funktionsleiste über 50 % der Breite des Diagramms erstreckt, bedeutet dies, dass das Programm 50 % der gesamten Laufzeit mit der Ausführung dieser Funktion beschäftigt warfare.
Diagnose
Aus dem Eiszapfendiagramm oben können wir ersehen, dass der Balken die Pandas darstellt iterrows() Die Funktion ist spürbar umfangreich. Bewegen Sie den Mauszeiger über diese Leiste, wenn Sie das anzeigen profile.svg Datei zeigt, dass der wahre Anteil für diese Funktion warfare 68,36 %. Es wurden additionally über 2/3 der Laufzeit im verbracht iterrows() Funktion. Intuitiv macht dieser Engpass Sinn, da iterrows() erstellt für jede einzelne Zeile in der Schleife ein Pandas-Serienobjekt, was einen enormen Mehraufwand verursacht. Daraus ergibt sich ein klares Ziel, die Laufzeit des Skripts zu optimieren.
Optimierung des Skripts
Der klarste Weg zur Optimierung dieses Skripts basierend auf den Erkenntnissen py-spy ist, mit dem Gebrauch aufzuhören iterrows() um jede Zeile zu durchlaufen, um diesen Haversinus-Abstand zu berechnen. Stattdessen sollte es durch eine vektorisierte Berechnung mit NumPy ersetzt werden, die die Berechnung für jede Zeile mit nur einem Funktionsaufruf durchführt. Die vorzunehmenden Änderungen sind additionally:
- Schreiben Sie das um
haversine()Funktion, um vektorisierte und effiziente NumPy-Operationen auf C-Ebene zu verwenden, die die Übergabe ganzer Arrays statt jeweils eines Koordinatensatzes ermöglichen. - Ersetzen Sie die
iterrows()Schleife mit einem einzigen Aufruf dieser neu vektorisierten Schleifehaversine()Funktion.
import pandas as pd
import numpy as np
import time
def haversine(lat_1, lon_1, lat_2, lon_2):
"""Calculate the Haversine Distance between two latitude and longitude factors"""
lat_1_rad = np.radians(lat_1)
lon_1_rad = np.radians(lon_1)
lat_2_rad = np.radians(lat_2)
lon_2_rad = np.radians(lon_2)
delta_lat = lat_2_rad - lat_1_rad
delta_lon = lon_2_rad - lon_1_rad
R = 6371 # Radius of the earth in km
return 2*R*np.asin(np.sqrt(np.sin(delta_lat/2)**2 + np.cos(lat_1_rad)*np.cos(lat_2_rad)*(np.sin(delta_lon/2))**2))
if __name__ == '__main__':
# Load in flight information to a dataframe
flight_data_file = r"./information/2025_flight_data.csv"
flights_df = pd.read_csv(flight_data_file)
# Begin timer to see how lengthy evaluation takes
begin = time.time()
# Calculate the haversine distance between every flight's begin and finish airport
flights_df("Distance") = haversine(lat_1=flights_df("LATITUDE_ORIGIN"),
lon_1=flights_df("LONGITUDE_ORIGIN"),
lat_2=flights_df("LATITUDE_DEST"),
lon_2=flights_df("LONGITUDE_DEST"))
# Get end result by grouping by origin airport, taking the common flight distance and printing the highest 5
end result = (
flights_df
.groupby('DISPLAY_AIRPORT_NAME_ORIGIN').agg(avg_dist=('Distance', 'imply'))
.sort_values('avg_dist', ascending=False)
)
print(end result.head(5))
# Finish timer and print evaluation time
finish = time.time()
print(f"Took {finish - begin} s")Das Ausführen dieses Codes liefert die folgende Ausgabe:
avg_dist
DISPLAY_AIRPORT_NAME_ORIGIN
Pago Pago Worldwide 4202.493567
Guam Worldwide 3142.363005
Luis Munoz Marin Worldwide 2386.141780
Ted Stevens Anchorage Worldwide 2246.530036
Daniel Okay Inouye Worldwide 2211.857407
Took 0.5649983882904053 sDiese Ergebnisse sind identisch mit den Ergebnissen vor der Optimierung des Codes, aber anstatt quick drei Minuten für die Verarbeitung zu benötigen, es hat etwas mehr als eine halbe Sekunde gedauert!
Blick nach vorn
Wenn Sie dies aus der Zukunft (Ende 2026 oder später) lesen, prüfen Sie, ob Sie Python 3.15 oder neuer verwenden. Es wird erwartet, dass Python 3.15 einen nativen Sampling-Profiler in die Standardbibliothek einführt, der ähnliche Funktionen bietet wie py-spy ohne dass eine externe Set up erforderlich ist. Für alle, die Python 3.14 oder älter verwenden py-spy bleibt der Goldstandard.
In diesem Artikel wurde ein Instrument zur Bewältigung einer häufigen Frustration in der Datenwissenschaft untersucht – ein Skript, das wie vorgesehen funktioniert, aber ineffizient geschrieben ist und lange zur Ausführung benötigt. Es wurde ein Beispielskript bereitgestellt, um herauszufinden, welche US-Abflughäfen gemäß der Haversine-Entfernung die längste durchschnittliche Flugentfernung haben. Dieses Skript funktionierte wie erwartet, die Ausführung dauerte jedoch quick drei Minuten.
Mit der py-spy Mit dem Python-Profiler konnten wir herausfinden, dass die Ursache für die Ineffizienz in der Verwendung von lag iterrows() Funktion. Durch Ersetzen iterrows() Mit einer effizienteren vektorisierten Berechnung der Haversine-Distanz wurde die Laufzeit von drei Minuten auf etwas mehr als eine halbe Sekunde optimiert.
Siehe meine GitHub-Repository für den Code aus diesem Artikel, einschließlich der Vorverarbeitung der Rohdaten von BTS.
Vielen Dank fürs Lesen!
Datenquellen
Die Daten des Bureau of Transportation Statistics (BTS) sind ein Werk der US-Bundesregierung und unter gemeinfrei 17 USC § 105. Die Nutzung, Weitergabe und Anpassung ist ohne Urheberrechtsbeschränkung kostenlos.