
Zhipu AI hat offiziell GLM-4,5V und ein Open-Sourcing-VLM (VLM) der nächsten Era veröffentlicht, das den Zustand der offenen multimodalen KI erheblich vorantreibt. Basierend auf der 106-Milliarden-Parameter-GLM-4,5-Air-Architektur von ZHIPHU-mit 12 Milliarden aktiven Parametern über eine Mischung aus Experten (MOE), liefert GGLM-4,5V eine starke Leistung der realen Welt und unübertroffene Vielseitigkeit über visuelle und Textinhalte hinweg.
Schlüsselmerkmale und Designinnovationen
1. umfassende visuelle Argumentation
- Bildrealisierung: GLM-4,5V erreicht ein fortgeschrittenes Szenenverständnis, eine Mehrzeitanalyse und die räumliche Erkennung. Es kann detaillierte Beziehungen in komplexen Szenen interpretieren (z. B. Unterscheidung von Produktfehlern, Analyse geografischer Hinweise oder Abschluss des Kontextes aus mehreren Bildern gleichzeitig).
- Videoverständnis: Es verarbeitet lange Movies, führt automatische Segmentierung durch und erkennt nuancierte Ereignisse dank eines 3D -Faltungs -Imaginative and prescient -Encoders. Dies ermöglicht Anwendungen wie Storyboarding, Sportanalytics, Überwachungsprüfung und Vorlesung.
- Räumliche Argumentation: Die integrierte 3D-Rotationspositionskodierung (3D-Rope) gibt dem Modell eine robuste Wahrnehmung dreidimensionaler räumlicher Beziehungen, die für die Interpretation visueller Szenen und die Erde visuelle Elemente von entscheidender Bedeutung sind.
2. Aufgaben fortgeschrittener GUI und Agent
- Bildschirmlesung und Symbolerkennung: Das Modell zeichnet sich aus, um Desktop-/App -Schnittstellen zu lesen, Schaltflächen und Symbole zu lokalisieren und die Automatisierung zu unterstützen – Wesentlichkeit für RPA (Roboterprozessautomatisierung) und Zugänglichkeitstools.
- Desktop -Betriebsunterstützung: Durch ein detailliertes visuelles Verständnis kann GLM-4,5V GUI-Vorgänge planen und beschreiben, wodurch Benutzer beim Navigieren von Software program oder beim Durchführen komplexer Workflows unterstützt werden.
3. Komplexes Diagramm und Dokumenten Parsing
- Diagrammverständnis: GLM-4,5V kann Diagramme, Infografiken und wissenschaftliche Diagramme in PDFs oder PowerPoint-Dateien analysieren und zusammenfassende Schlussfolgerungen und strukturierte Daten auch aus dichten, langen Dokumenten extrahieren.
- Lange Dokumentinterpretation: Mit Unterstützung von bis zu 64.000 Token multimodaler Kontext kann es erweiterte, bildreiche Dokumente (wie Forschungsarbeiten, Verträge oder Compliance-Berichte) analysieren und zusammenfassen, was es superb für Enterprise Intelligence und Wissensförderung macht.
4. Erdung und visuelle Lokalisierung
- Präzise Erdung: Das Modell kann visuelle Elemente-wie Objekte, Begrenzungsboxen oder spezifische UI-Elemente-genau lokalisieren und beschreiben-weltweit und semantischen Kontext, nicht nur Hinweise auf Pixelebene. Dies ermöglicht eine detaillierte Analyse für Qualitätskontrolle, AR -Anwendungen und Bildanmerkungen.
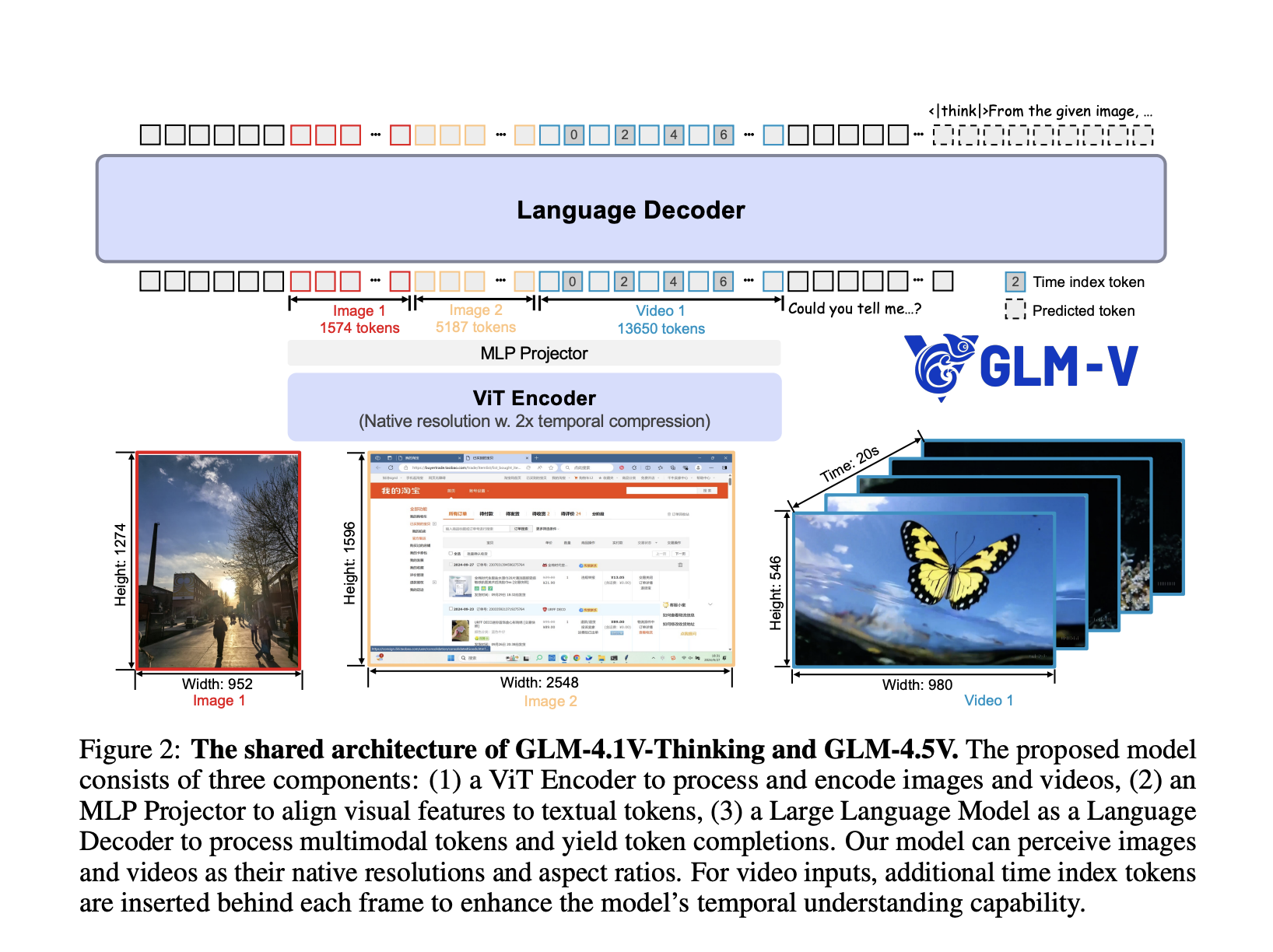
Architektonische Höhepunkte
- Hybrid-Imaginative and prescient-sprachliche Pipeline: Das System integriert einen leistungsstarken visuellen Encoder, einen MLP -Adapter und einen Sprachdecoder, der eine nahtlose Verschmelzung von visuellen und textuellen Informationen ermöglicht. Statische Bilder, Movies, GUIs, Diagramme und Dokumente werden als erstklassige Eingaben behandelt.
- Expertenmischung (MOE) Effizienz: Während die Gesamtparameter von 106B in der Lage ist, aktiviert das MOE -Design nur 12B professional Inferenz und sorgt für einen hohen Durchsatz und erschwinglichen Einsatz, ohne die Genauigkeit zu beeinträchtigen.
- 3D -Faltung für Video & Bilder: Videoeingaben werden unter Verwendung von zeitlicher Downsampling und 3D-Faltung verarbeitet, um die Analyse hochauflösender Movies und nativen Seitenverhältnisse zu ermöglichen und gleichzeitig die Effizienz beizubehalten.
- Adaptive Kontextlänge: Unterstützt bis zu 64K-Token und ermöglicht eine robuste Handhabung von Multi-Picture-Eingaben, verketteten Dokumenten und langwierigen Dialogen in einem Cross.
- Modern Vorab- und RL: Das Trainingsregime kombiniert large multimodale Vorabbau, beaufsichtigte Feinabstimmung und Verstärkungslernen mit Lehrplanabtastung (RLCS) Für langkettige Argumentation Meisterschaft und reale Aufgabe Robustheit.
„Denkmodus“ für einstellbare Argumentationstiefe
Eine herausragende Funktion ist der „Denkmodus“ -Wechsel:
- Denkmodus eingeschaltet: Priorisiert tief, schrittweise Argumentation, geeignet für komplexe Aufgaben (z. B. logischer Abzug, mehrstufiges Diagramm oder Dokumentenanalyse).
- Denkmodus aus: Liefert schnellere, direkte Antworten für Routine -Lookups oder einfache Q & A. Der Benutzer kann die Überlegungstiefe des Modells mit Schluss steuern und die Geschwindigkeit gegen Interpretierbarkeit und Strenge ausbalancieren.
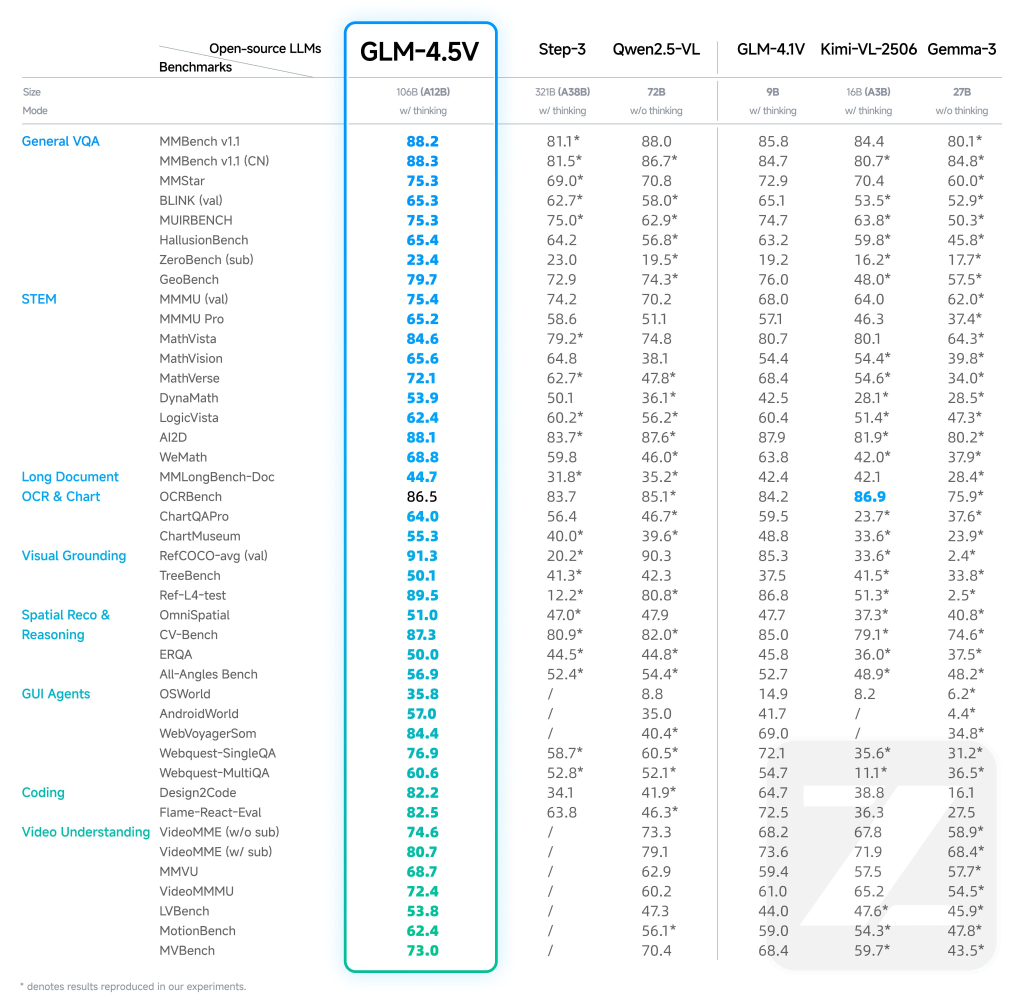
Benchmark-Leistung und reale Auswirkungen
- Hochmoderne Ergebnisse: GLM-4,5V erreicht SOTA über 41–42 öffentliche multimodale Benchmarks, einschließlich MMBench, AI2D, MMSTAR, Mathvista und mehr, übertreffen sowohl offenes als auch einige Premium-proprietäre Modelle in Kategorien wie STEM-QA, Chart-Verständnis, GUI-Betrieb und Videoverständnis.
- Praktische Bereitstellungen: Unternehmen und Forscher berichten über transformative Ergebnisse bei der Erkennung von Defekten, der automatisierten Berichtsanalyse, der Erstellung digitaler Assistenten und der Zugänglichkeitstechnologie mit GLM-4,5 V.
- Demokratisierung der multimodalen KI: Open Sourcing Im Rahmen der MIT-Lizenz wird das Modell den Zugriff auf modernste multimodale Argumentation erreicht, die zuvor von exklusiven proprietären APIs abgebildet wurde.
Beispiel Anwendungsfälle
| Besonderheit | Beispiel Verwendung | Beschreibung |
|---|---|---|
| Bildrealisierung | Defekterkennung, Inhalts Moderation | Szenenverständnis, Zusammenfassung mehrerer Picture |
| Videoanalyse | Überwachung, Inhaltserstellung | Lange Videosegmentierung, Ereigniserkennung |
| GUI -Aufgaben | Zugänglichkeit, Automatisierung, QA | Bildschirm/UI -Lesen, Symbolort, Betriebsvorschlag |
| Chart -Parsen | Finanzen, Forschungsberichte | Visuelle Analytik, Datenextraktion aus komplexen Diagrammen |
| Dokument an Parsen | Gesetz, Versicherung, Wissenschaft | Analysieren und fassen Sie lange illustrierte Dokumente zusammen |
| Erdung | AR, Einzelhandel, Robotik | Zielobjektlokalisierung, räumliche Referenzierung |
Zusammenfassung
GLM-4,5V von Zhipu AI ist ein Flaggschiff Open-Supply Imaginative and prescient-Sprach-Modell, das neue Leistungsstandards und Usability-Requirements für multimodales Denken festlegt. Mit seiner leistungsstarken Architektur, der Kontextlänge, dem Echtzeit-Denkmodus und dem breiten Fähigkeitsspektrum definiert GLM-4,5V das, was für Unternehmen, Forscher und Entwickler, die an der Schnittstelle von Imaginative and prescient und Sprache arbeiten, möglich definiert.
Schauen Sie sich das an PapierAnwesend Modell auf dem Umarmungsgesicht Und Github -Seite hier. Fühlen Sie sich frei, unsere zu überprüfen Github -Seite für Tutorials, Codes und Notizbücher. Fühlen Sie sich auch frei, uns zu folgen Twitter Und vergessen Sie nicht, sich unserer anzuschließen 100k+ ml Subreddit und abonnieren Unser E-newsletter.
Asif Razzaq ist der CEO von Marktechpost Media Inc. Sein jüngstes Bestreben ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch die ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die von einem breiten Publikum technisch intestine und leicht verständlich sind. Die Plattform verfügt über über 2 Millionen monatliche Ansichten und veranschaulicht ihre Beliebtheit des Publikums.