
Giant Language Fashions (LLMs) sind das Herzstück von Agentic-Systemen und RAG-Systemen. Und das Bauen mit LLMs ist spannend, bis die Größe sie teuer macht. Es gibt immer einen Kompromiss zwischen Kosten und Qualität, aber in diesem Artikel werden wir meiner Meinung nach die 10 besten Möglichkeiten untersuchen, wie man die Kosten für die LLM-Nutzung senken und sich gleichzeitig auf die Aufrechterhaltung der Qualität des Techniques konzentrieren kann. Beachten Sie auch, dass ich für die Inferenz die OpenAI-API verwende, die Techniken jedoch auch auf andere Modellanbieter angewendet werden könnten. Lassen Sie uns additionally ohne weitere Umschweife die Kostengleichung verstehen und Wege zur LLM-Kostenoptimierung finden.
Voraussetzung: Verständnis der Kostengleichung
Bevor wir beginnen, sollten wir uns besser mit Kosten, Token und Kontextfenster vertraut machen:
- Token: Dies sind die kleinen Einheiten des Textes. Aus praktischen Gründen können Sie davon ausgehen, dass 1.000 Token ungefähr 750 Wörtern entsprechen.
- Immediate-Tokens: Dies sind die Eingabetokens, die wir an das Modell senden. Sie sind im Allgemeinen günstiger.
- Abschlusstoken: Dies sind die vom Modell generierten Token. Sie sind oft 3-4 mal teurer als Enter-Tokens.
- Kontextfenster: Dies ist wie ein Kurzzeitgedächtnis (es kann die alten Ein- und Ausgänge umfassen). Wenn Sie diese Grenze überschreiten, lässt das Modell die früheren Teile des Gesprächs aus. Wenn Sie im Kontextfenster 10 vorherige Nachrichten senden, zählen diese als Eingabe-Tokens für die aktuelle Anfrage und erhöhen die Kosten.
- Gesamtkosten: (Eingabe-Tokens x Kosten professional Eingabe-Token) + (Ausgabe-Tokens x Kosten professional Ausgabe-Token)
Notiz: Für OpenAI können Sie das Abrechnungs-Dashboard verwenden, um die Kosten zu verfolgen: https://platform.openai.com/settings/group/billing/overview
Um zu erfahren, wie Sie die OpenAI-API erhalten, lesen Sie Das Artikel.
1. Leiten Sie Anfragen an das richtige Modell weiter
Nicht für jede Aufgabe ist das beste Modell auf dem neuesten Stand der Technik erforderlich. Sie können mit einem günstigeren Modell experimentieren oder versuchen, mit einem günstigeren Modell eine Eingabeaufforderung in wenigen Schritten zu verwenden, um ein größeres Modell zu reproduzieren.
Konfigurieren Sie den API-Schlüssel
from google.colab import userdata
import os
os.environ('OPENAI_API_KEY')=userdata.get('OPENAI_API_KEY') Definieren Sie die Funktionen
from openai import OpenAI
shopper = OpenAI()
SYSTEM_PROMPT = "You're a concise, useful assistant. You reply in 25-30 phrases"
def generate_examples(questions, n=3):
examples = ()
for q in questions(:n):
response = shopper.chat.completions.create(
mannequin="gpt-5.1",
messages=({"position": "system", "content material": SYSTEM_PROMPT},
{"position": "person", "content material": q})
)
examples.append({"q": q, "a": response.decisions(0).message.content material})
return examplesDiese Funktion verwendet den größeren GPT-5.1 und beantwortet die Frage in 25-30 Wörtern.
# Instance utilization
questions = (
"What's overfitting?",
"What's a confusion matrix?",
"What's gradient descent?"
)
few_shot = generate_examples(questions, n=3)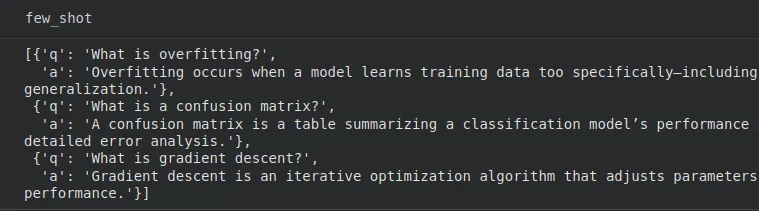
Großartig, wir haben unsere Frage-Antwort-Paare bekommen.
def build_prompt(examples, query):
immediate = ""
for ex in examples:
immediate += f"Q: {ex('q')}nA: {ex('a')}nn"
return immediate + f"Q: {query}nA:"
def ask_small_model(examples, query):
immediate = build_prompt(examples, query)
response = shopper.chat.completions.create(
mannequin="gpt-5-nano",
messages=({"position": "system", "content material": SYSTEM_PROMPT},
{"position": "person", "content material": immediate})
)
return response.decisions(0).message.content materialHier haben wir eine Funktion, die das kleinere „gpt-5-nano“ verwendet, und eine andere Funktion, die die Eingabeaufforderung mithilfe der Frage-Antwort-Paare für das Modell erstellt.
reply = ask_small_model(few_shot, "Clarify regularization in ML.")
print(reply)Lassen Sie uns eine Frage an das Modell weiterleiten.
Ausgabe:
Regularization provides a penalty to the loss for mannequin complexity to scale back overfitting. Frequent kinds embody L1 (lasso) selling sparsity and L2 (ridge) shrinking weights; elastic internet blends.
Großartig! Wir haben ein viel günstigeres Modell (gpt-5-nano) verwendet, um unsere Ausgabe zu erhalten, aber wir können das billigere Modell sicherlich nicht für jede Aufgabe verwenden.
2. Verwenden Sie Modelle entsprechend der Aufgabe
Die Idee dabei ist, ein kleineres Modell für Routineaufgaben zu verwenden und die größeren Modelle nur für komplexe Überlegungen. Wie machen wir das? Hier definieren wir einen Klassifikator, der „einfach“ oder „komplex“ zurückgibt und leiten die Abfragen entsprechend weiter. Dies hilft uns, Kosten bei den Routinekosten zu sparen.
Beispiel:
from openai import OpenAI
shopper = OpenAI()
def get_complexity(query):
immediate = f"Fee the complexity of the query from 1 to 10 for an LLM to reply. Present solely the quantity.nQuestion: {query}"
res = shopper.chat.completions.create(
mannequin="gpt-5.1",
messages=({"position": "person", "content material": immediate}),
)
return int(res.decisions(0).message.content material.strip())
print(get_complexity("Clarify convolutional neural networks"))Ausgabe:
4
Unser Klassifikator sagt additionally, dass die Komplexität 4 ist. Machen Sie sich keine Sorgen über den zusätzlichen LLM-Aufruf, da dieser nur eine einzige Zahl generiert. Diese Komplexitätszahl kann zum Weiterleiten der Aufgaben verwendet werden, wie zum Beispiel: Komplexität < 7 Dann zu einem kleineren Modell weiterleiten, andernfalls zu einem größeren Modell.
3. Verwenden von Immediate Caching
Wenn das LLM-System umfangreiche Systemanweisungen oder viele Beispiele mit wenigen Schüssen über viele Aufrufe hinweg verwendet, stellen Sie sicher, dass Sie diese an der richtigen Stelle platzieren Begin Ihrer Nachricht.
Hier ein paar wichtige Punkte:
- Stellen Sie sicher, dass das Präfix bei allen Anforderungen genau identisch ist (einschließlich aller Zeichen, einschließlich Leerzeichen).
- Laut OpenAI profitieren die unterstützten Modelle automatisch von Caching, die Eingabeaufforderung muss jedoch länger als 1.024 Token sein.
- Anfragen, die Immediate Caching verwenden, haben eine
cached_tokensWert als Teil der Antwort.
4. Verwenden Sie die Batch-API für Aufgaben, die warten können
Viele Aufgaben erfordern keine sofortigen Antworten. Hier können wir den asynchronen Batch-Endpunkt für die Inferenz verwenden. Indem Sie eine Datei mit Anfragen einreichen und OpenAI bis zu 24 Stunden Zeit für deren Bearbeitung geben, werden die Token-Kosten im Vergleich zu den üblichen OpenAI-API-Aufrufen um 50 % gesenkt.
5. Trimmen Sie die Ausgänge mit den Parametern max_tokens und Stops
Was wir hier versuchen, ist, die Generierung von unkontrollierten Token zu stoppen. Nehmen wir an, Sie benötigen eine Zusammenfassung mit 75 Wörtern oder ein bestimmtes JSON-Objekt. Lassen Sie nicht zu, dass das Modell weiterhin unnötigen Textual content generiert. Stattdessen können wir die Parameter verwenden:
Beispiel:
from openai import OpenAI
shopper = OpenAI()
response = shopper.chat.completions.create(
mannequin="gpt-5.1",
messages=(
{
"position": "system",
"content material": "You're a knowledge extractor. Output solely uncooked JSON."
}
),
max_tokens=100,
cease=("nn", "}")
)Wir haben max_tokens auf 100 gesetzt, da es ungefähr 75 Wörter sind.
6. Nutzen Sie RAG
Anstatt das Kontextfenster zu überfluten, können wir Retrieval-Augmented Era verwenden. Dies hilft dabei, die Wissensdatenbank in Einbettungen umzuwandeln und diese in einer Vektordatenbank zu speichern. Wenn ein Benutzer eine Anfrage stellt, befindet sich nicht der gesamte Kontext im Kontextfenster, sondern die abgerufenen oberen paar relevanten Textabschnitte werden als Kontext übergeben.
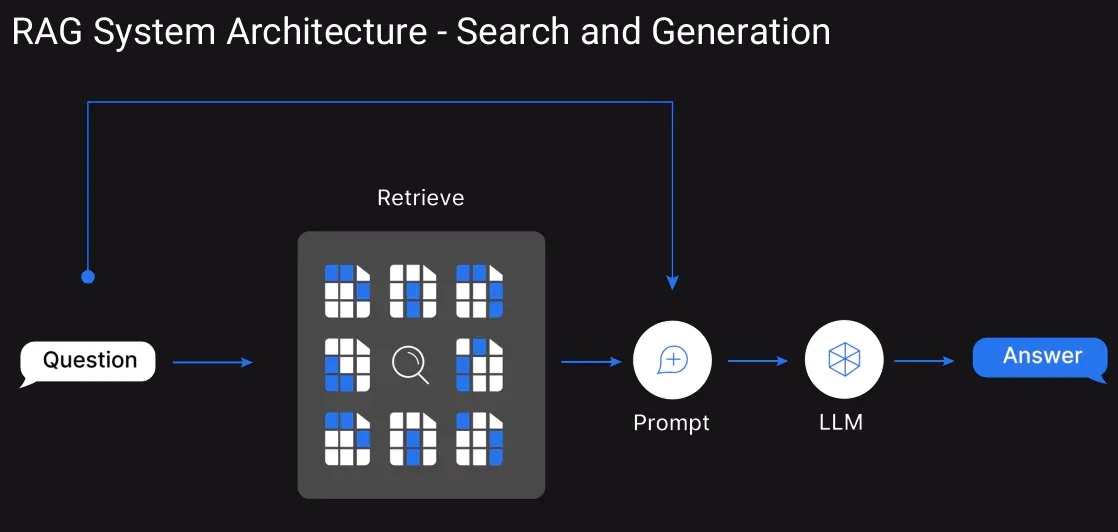
7. Verwalten Sie immer den Gesprächsverlauf
Hier liegt unser Fokus auf dem Konversationsverlauf, in dem wir die älteren Ein- und Ausgaben weitergeben. Anstatt die Konversationen iterativ hinzuzufügen, können wir einen „Schiebefenster“-Ansatz implementieren.
Hier löschen wir die ältesten Nachrichten, sobald der Kontext zu lang wird (legen Sie einen Schwellenwert fest) oder fassen frühere Nachrichten in einer einzigen Systemnachricht zusammen, bevor wir fortfahren. Stellen Sie sicher, dass das aktive Kontextfenster nicht zu lang ist, da es für lang laufende Sitzungen von entscheidender Bedeutung ist.
Funktion zur Zusammenfassung
from openai import OpenAI
shopper = OpenAI()
SYSTEM_PROMPT = "You're a concise assistant. Summarize the chat historical past in 30-40 phrases."
def summarize_chat(history_text):
response = shopper.chat.completions.create(
mannequin="gpt-5.1",
messages=(
{"position": "system", "content material": SYSTEM_PROMPT},
{"position": "person", "content material": history_text}
)
)
return response.decisions(0).message.content materialSchlussfolgerung
chat_history = """
Person: Hello, I am attempting to know how embeddings work.
Assistant: Embeddings flip textual content into numeric vectors.
Person: Can I take advantage of them for similarity search?
Assistant: Sure, that’s a standard use case.
Person: Good, present me easy code.
Assistant: Certain, this is a brief instance...
"""
abstract = summarize_chat(chat_history)Der Benutzer hat gefragt, was Einbettungen sind. Der Assistent erklärte, dass sie Textual content in numerische Vektoren umwandeln. Der Benutzer fragte dann nach der Verwendung von Einbettungen für die Ähnlichkeitssuche. Der Assistent bestätigte dies und stellte ein kurzes Beispielcode-Snippet zur Verfügung, das die grundlegende Ähnlichkeitssuche demonstriert.
Wir haben jetzt eine Zusammenfassung, die zum Kontextfenster des Modells hinzugefügt werden kann, wenn die Eingabetokens über einem definierten Schwellenwert liegen.
8. Improve auf effiziente Modellmodi
OpenAI veröffentlicht häufig optimierte Versionen seiner Modelle. Suchen Sie immer nach neueren „Mini“- oder „Nano“-Varianten der neuesten Modelle. Diese sind speziell auf Effizienz ausgelegt und bieten oft eine ähnliche Leistung für bestimmte Aufgaben zu einem Bruchteil der Kosten.
9. Strukturierte Ausgaben erzwingen (JSON)
Wenn Sie Daten extrahieren oder formatieren müssen. Durch die Definition eines strikten Schemas wird das Modell gezwungen, die unnötigen Token herauszuschneiden und nur die genauen angeforderten Datenfelder zurückzugeben. Dichtere Antworten bedeuten weniger generierte Token auf Ihrer Rechnung.
Importe und Strukturdefinition
from openai import OpenAI
import json
shopper = OpenAI()
immediate = """
You're an extraction engine. Output ONLY legitimate JSON.
No explanations. No pure language. No additional keys.
Extract these fields:
- title (string)
- date (string, format: YYYY-MM-DD)
- entities (array of strings)
Textual content:
"On 2025-12-05, OpenAI launched Structured Outputs, permitting builders to implement strict JSON schemas. This improved reliability was welcomed by many engineers."
Return JSON on this actual format:
{
"title": "",
"date": "",
"entities": ()
}
"""Schlussfolgerung
response = shopper.chat.completions.create(
mannequin="gpt-5.1",
messages=({"position": "person", "content material": immediate})
)
knowledge = response.decisions(0).message.content material
json_data = json.masses(knowledge)
print(json_data)Ausgabe:
{'title': 'OpenAI Introduces Structured Outputs', 'date': '2025-12-05', 'entities': ('OpenAI', 'Structured Outputs', 'JSON', 'builders', 'engineers')}
Wie wir sehen können, wird nur das erforderliche Wörterbuch mit den erforderlichen Particulars zurückgegeben. Außerdem ist die Ausgabe übersichtlich als Schlüssel-Wert-Paare strukturiert.
10. Cache-Abfragen
Im Gegensatz zu unserer früheren Idee des Cachings ist dies ganz anders. Wenn die Benutzer häufig genau dieselben Fragen stellen, speichern Sie die Antwort des LLM in Ihrer eigenen Datenbank. Überprüfen Sie diese Datenbank, bevor Sie die API aufrufen. Diese zwischengespeicherte Antwort ist für den Benutzer schneller und praktisch kostenlos. Wenn Sie mit LangGraph für Agenten arbeiten, können Sie dies auch für das Caching auf Knotenebene untersuchen: Caching in LangGraph
Abschluss
Die Entwicklung mit LLMs ist leistungsstark, kann aber aufgrund ihrer Größe schnell teuer werden. Daher ist das Verständnis der Kostengleichung unerlässlich. Durch die Anwendung der richtigen Mischung aus Modellrouting, Caching, strukturierten Ausgaben, RAG und effizientem Kontextmanagement können wir die Inferenzkosten erheblich senken. Diese Techniken tragen dazu bei, die Qualität des Techniques aufrechtzuerhalten und gleichzeitig sicherzustellen, dass die gesamte LLM-Nutzung praktisch und kosteneffektiv bleibt. Vergessen Sie nicht, nach der Implementierung jeder Technik das Abrechnungs-Dashboard auf die Kosten zu überprüfen.
Häufig gestellte Fragen
A. Ein Token ist eine kleine Texteinheit, wobei etwa 1.000 Token etwa 750 Wörtern entsprechen.
A. Weil Ausgabe-Token (aus dem Modell) professional Token oft um ein Vielfaches teurer sind als Eingabe-Token (Immediate-Token).
A. Das Kontextfenster ist das Kurzzeitgedächtnis (vorherige Eingaben und Ausgaben), das an das Modell gesendet wird. Ein längerer Kontext erhöht die Token-Nutzung und damit die Kosten.
Leidenschaftlich für Technologie und Innovation, Absolvent des Vellore Institute of Expertise. Derzeit arbeite ich als Knowledge Science Trainee mit Schwerpunkt auf Knowledge Science. Großes Interesse an Deep Studying und generativer KI, begierig darauf, modernste Techniken zu erforschen, um komplexe Probleme zu lösen und wirkungsvolle Lösungen zu schaffen.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.