
LLMs wie die von Google und OpenAI haben unglaubliche Fähigkeiten gezeigt. Aber ihre Kraft ist mit Kosten verbunden. Diese massiven Modelle sind langsam, teuer zu betreiben und auf alltäglichen Geräten schwer einzulegen. Hier kommen LLM -Komprimierungstechniken ins Spiel. Diese Methoden verkleinern die Modelle und machen sie ohne einen größeren Leistungsverlust schneller und zugänglicher. In diesem Leitfaden werden vier Schlüsseltechniken untersucht: Modellquantisierung, Modellbeschneidungsmethoden, Wissensdestillation in LLMs und Anpassung mit niedriger Rang (LORA) mit praktischen Codebeispielen.
Warum brauchen wir LLM -Komprimierung?
Bevor wir uns mit dem „Wie“ eintauchen, verstehen wir das „Warum“. Compressing LLMS bietet klare Vorteile, die sie für die reale Verwendung praktisch machen.
- Reduzierte Modellgröße: Kleinere Modelle erfordern weniger Speicher, sodass sie einfacher zu hosten und vertreiben.
- Schneller Inferenz: Ein kompaktes Modell kann schneller Antworten erzeugen. Dies verbessert die Benutzererfahrung in Anwendungen wie Chatbots.
- Niedrigere Kosten: Reduzierte Größe und schnellere Geschwindigkeit führen zu einem geringeren Bedarf an Speicher und Verarbeitungsleistung. Dies senkt die Cloud -Computing- und Energiekosten.
- Größere Zugänglichkeit: Durch die Komprimierung können leistungsstarke Modelle auf Geräten mit begrenzten Ressourcen wie Smartphones und Laptops ausgeführt werden.
Technik 1: Quantisierung – mehr mit weniger tun
Die Modellquantisierung ist eine der beliebtesten und effektivsten LLM -Kompressionstechniken. Es funktioniert, indem es die Genauigkeit der Zahlen (Gewichte) reduziert, aus denen das Modell besteht. Stellen Sie sich vor, Sie speichern ein hochauflösendes Foto als komprimiertes JPEG. Sie verlieren eine kleine Menge an Particulars, aber die Dateigröße schrumpft dramatisch. Die meisten Modelle werden unter Verwendung von 32-Bit-Gleitkomma-Zahlen (FP32) trainiert. Quantisierung wandelt diese in kleinere 8-Bit-Ganzzahlen (INT8) oder sogar 4-Bit-Ganzzahlen um.
Dieses Bild erklärt die Quantisierung visuell, wobei kontinuierliche, hochpräzise FP32-Werte (32-Bit-Gleitpunkte) auf einen begrenzten Satz diskreter Int4-Werte (4-Bit-Integer) mit niedrigerer Präzision (4-Bit-Ganzzahl) abgebildet werden. Im Wesentlichen zeigt es, wie eine breite Palette von Gleitpunktzahlen durch eine kleinere, feste Anzahl von Ganzzahlniveaus angenähert wird, um Speicher und Berechnung zu reduzieren, obwohl dies zu einem gewissen Präzisionsverlust führen kann.
Praktisch: 4-Bit-Quantisierung mit umarmtem Gesicht
Lassen Sie uns ein Modell mit den umarmenden Gesichtstransformatoren und der BitsandBytes -Bibliothek quantisieren. In diesem Beispiel wird angezeigt, wie ein Modell in 4-Bit-Präzision geladen wird, wodurch der Speicherausdruck erheblich reduziert wird.
Schritt 1: Bibliotheken installieren
Stellen Sie zunächst sicher, dass die erforderlichen Bibliotheken installiert sind.
!pip set up transformers torch speed up bitsandbytes -qSchritt 2: Laden und Vergleichen Sie Modelle
Wir werden ein Standardmodell und dann seine quantisierte Model laden, um den Unterschied zu erkennen.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# We use a smaller, well-known mannequin for this demonstration
model_id = "gpt2"
print(f"Loading tokenizer for mannequin: {model_id}")
tokenizer = AutoTokenizer.from_pretrained(model_id)
print("n-----------------------------------")
print("Loading authentic mannequin in FP32...")
# Load the unique mannequin in full precision (Float32)
model_fp32 = AutoModelForCausalLM.from_pretrained(model_id)
# Test the reminiscence footprint of the unique mannequin
print("nOriginal mannequin reminiscence footprint:")
# Calculate reminiscence footprint manually
mem_fp32 = sum(p.numel() * p.element_size() for p in model_fp32.parameters())
print(f"{mem_fp32 / 1024**2:.2f} MB")
print("n-----------------------------------")
print("Loading mannequin with 4-bit quantization...")
# Load the identical mannequin with 4-bit quantization enabled
model_4bit = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
device_map="auto" # Mechanically makes use of the GPU if obtainable
)
# Test the reminiscence footprint of the 4-bit mannequin
print("n4-bit quantized mannequin reminiscence footprint:")
# Calculate reminiscence footprint manually
mem_4bit = sum(p.numel() * p.element_size() for p in model_4bit.parameters())
print(f"{mem_4bit / 1024**2:.2f} MB")
print("nNotice the numerous discount in reminiscence utilization!")Ausgabe:
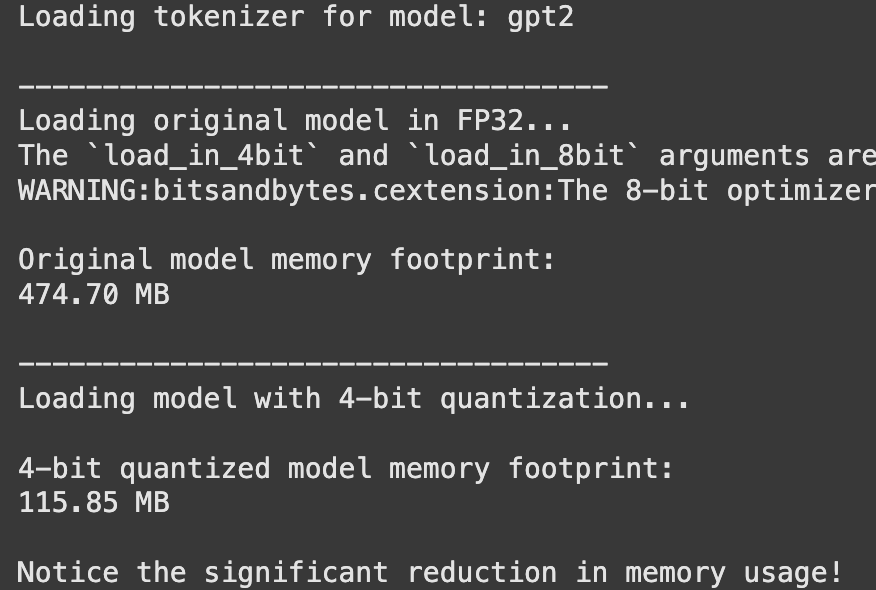
Sie werden eine signifikante Verringerung der Speicherverwendung des Modells bemerken, ohne dass sich die Qualität der Ausgabe für die meisten Aufgaben um quick nicht ändert.
Technik 2: Beschneiden – Abschneiden ungenutzter Verbindungen abschneiden
Modellschneidemethoden arbeiten, indem Teile des neuronalen Netzwerks entfernt werden, die am wenigsten zu seiner Ausgabe beitragen. Es ist wie eine Pflanze, um ein gesünderes Wachstum zu fördern. Sie können individuelle Gewichte (unstrukturiertes Beschneiden) oder ganze Gruppen von Neuronen (strukturiertes Beschneiden) entfernen. Während es leistungsfähig ist, kann das Beschneiden komplex sein, um korrekt zu implementieren.
Unstrukturiertes Beschneiden beseitigt beispielsweise individuelle Gewichte basierend auf ihrer Größe und erzeugt ein spärliches Modell. Dies macht das Modell zwar kleiner, aber es kann für {Hardware} schwierig sein, die spärliche Struktur zu nutzen. Strukturiertes Beschneiden entfernt ganze Blöcke wie Neuronen oder Schichten, die oft hardwarefreundlicher sind.
Das Bild zeigt verschiedene Strategien für das Beschneiden von Komponenten wie den Visionstransformator (VIT) und das große Sprachmodell (LLM) unter Verwendung von „Beschneidungsschichten“, um die Modellgröße zu verringern und die Effizienz zu verbessern. Insbesondere zeigt (a) das Beschneiden im visuellen Encoder, (b) konzentriert sich auf das Beschneiden innerhalb des LLM und (c) führt eine „anlehörige Komponente“ ein, um visuelle Token dynamisch auf der Grundlage von Textanweisungen zu verkürzen und die Effizienz für Aufgaben wie Videoverständnis zu verbessern.
Technik 3: Wissensdestillation-Der Ansatz der Schülerlehrer
Wissensdestillation in LLMs ist ein faszinierender Prozess. Ein großes, sehr genaues „Lehrer“ -Modell trainiert ein kleineres „Schüler“ -Modell. Der Schüler lernt, den Denkprozess des Lehrers (seine Ausgangswahrscheinlichkeiten) nachzuahmen, nicht nur die endgültige Antwort. Dies ermöglicht es dem kleineren Modell, die Leistung weit über das hinaus zu erzielen, indem sie allein die Daten trainieren.
Dieses Bild zeigt drei Wissensdestillationsmethoden im maschinellen Lernen: Offline, On-line und Selbstdestillation. Die Offline-Destillation verwendet einen vorgeborenen „Lehrer“, um einen „Schüler“ auszubilden, während die On-line-Destillation gleichzeitig und Selbstdarstellung ein einziges Modell beinhaltet, das sowohl als Lehrer als auch als Schüler fungiert (z. B. tiefere Schichten, die flachere Lehren lehren). Die orangefarbenen „Lehrer“ -Modelle sind vorgeschrieben, während die blauen „Schüler“ -Modelle (einschließlich der kombinierten „Lehrer/Schüler“ in der Selbstdestillation) „ausgebildet werden“.
Handwerbung: Konzeptionelle Destillation mit umarmtem Gesicht
Die Implementierung einer vollständigen Destillationspipeline ist beteiligt, aber die Kernidee kann durch die API der umarmenden Gesichtstrainer verstanden werden.
from transformers import TrainingArguments, Coach
# It is a conceptual instance for instance the method.
# To run this, you would wish:
# 1. An outlined 'teacher_model' (a big, pre-trained mannequin).
# 2. An outlined 'student_model' (a smaller mannequin to be skilled).
# 3. A 'your_dataset' object for coaching.
# Outline Coaching Arguments
training_args = TrainingArguments(
output_dir="./student_model_distilled",
num_train_epochs=1, # Instance worth
per_device_train_batch_size=8, # Instance worth
# ... different coaching arguments
)
# Create a customized Coach to change the loss perform
class DistillationTrainer(Coach):
def compute_loss(self, mannequin, inputs, return_outputs=False):
# That is the core of data distillation.
# The loss perform is a weighted common of two parts:
# a) The coed's commonplace loss on the info (e.g., Cross-Entropy).
# b) The distillation loss, which measures how effectively the coed's
# output distribution matches the instructor's.
# This half is conceptual and requires a full implementation.
print("Inside customized compute_loss - that is the place distillation logic would go.")
# For instance:
# student_outputs = mannequin(**inputs)
# student_loss = student_outputs.loss
# with torch.no_grad():
# teacher_outputs = teacher_model(**inputs)
# distillation_loss = some_kl_divergence_loss(student_outputs.logits, teacher_outputs.logits)
# combined_loss = 0.5 * student_loss + 0.5 * distillation_loss
# Returning a dummy loss to forestall errors on this conceptual instance
dummy_outputs = mannequin(**inputs)
return (dummy_outputs.loss, dummy_outputs) if return_outputs else dummy_outputs.loss
print("The DistillationTrainer class is outlined conceptually.")
print("A full implementation would require a instructor mannequin, scholar mannequin, and a dataset.")Dieser Prozess überträgt das „Wissen“ effektiv vom großen Modell auf das kleinere.
Technik 4: Anpassung mit niedriger Rang (LORA)-Effiziente Feinabstimmung
Während keine Methode zum Verkleinern eines Basismodells ist, ist die Anpassung der niedrigen Ranganpassung (LORA) eine Technik, um die zu komprimieren Änderungen während der Feinabstimmung gemacht. Anstatt alle Milliarden von Parametern in einem Modell umzusetzen, friert Lora das ursprüngliche Modell ein und injiziert winzige, trainierbare „Adapter“ -Schichten. Diese Adapter sind viel kleiner, wodurch der Feinabstimmungsvorgang schneller und das resultierende fein abgestimmte Modell viel speichereffizienter zum Speichern und Umschalten ist.
Dieses Diagramm erklärt LORA (Anpassung mit niedriger Rang) für eine effiziente Modellfeinabfindungsabstimmung: Während des Trainings wird eine kleine, trainierbare Anpassungsmatrix mit niedrigem Rang (BA) zu den gefrorenen vorbereiteten Gewichten (W) hinzugefügt. Nach dem Coaching wird diese niedrige Matrix mit den ursprünglichen Gewichten zusammengeführt, wodurch ein spezialisiertes Modell (W + BA) effektiv erstellt wird, ohne dass die Latenz oder den Speicherpreis beim Einsatz zu erhöhen. Dies reduziert die Rechenressourcen und Speicheranforderungen im Vergleich zur vollständigen Feinabstimmung erheblich.
Praktisch: Feinabstimmung mit Lora und Peft
Die umarmende Gesichtsbibliothek (parametereffiziente Feinabstimmung) erleichtert die Anwendung von Lora.
Schritt 1: Bibliotheken installieren
!pip set up peft -q Schritt 2: LORA anwenden und Parameterzahlen vergleichen
from peft import get_peft_model, LoraConfig, TaskType
from transformers import AutoModelForCausalLM
model_id = "gpt2"
mannequin = AutoModelForCausalLM.from_pretrained(model_id)
# Outline the LoRA configuration
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM, # Specify the duty kind
r=8, # Rank of the replace matrices. Decrease rank means fewer parameters.
lora_alpha=32, # A scaling issue for the realized weights.
lora_dropout=0.1, # Dropout chance for LoRA layers.
target_modules=("c_attn") # Apply LoRA to the eye layers of GPT-2.
)
# Wrap the bottom mannequin with the LoRA adapters
lora_model = get_peft_model(mannequin, lora_config)
print("--- Unique Mannequin ---")
# Get the whole variety of parameters for the unique mannequin
total_params = sum(p.numel() for p in mannequin.parameters())
print(f"Whole parameters: {total_params:,}")
print("n--- LoRA Tailored Mannequin ---")
# The PeftModel object has the print_trainable_parameters methodology
lora_model.print_trainable_parameters()
print("nNote how LoRA reduces trainable parameters by over 99%!")
print("This makes fine-tuning far more environment friendly.")Ausgabe:
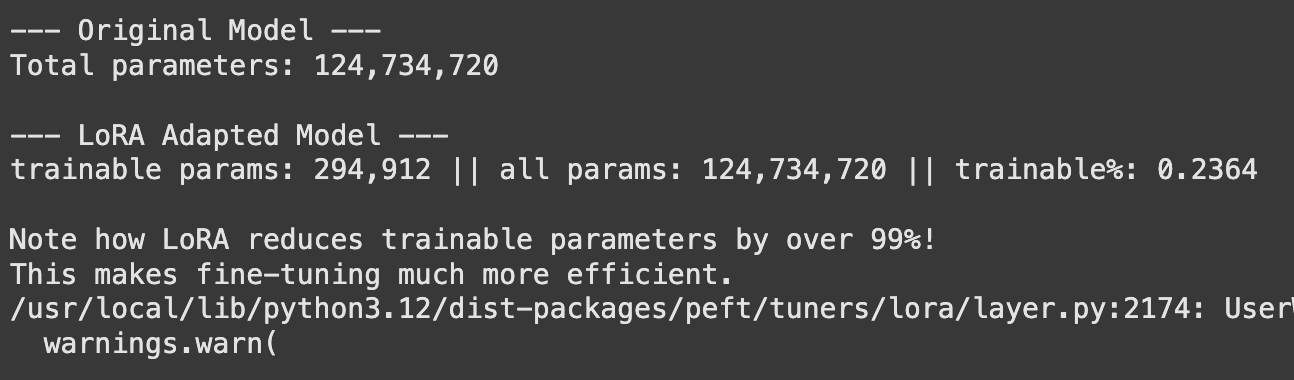
Der Ausgang zeigt eine dramatische Reduzierung (oft über 99%) in der Anzahl der Parameter, die trainiert und gespeichert werden müssen. Dies ermöglicht es, viele verschiedene Versionen eines Modells für verschiedene Aufgaben zu optimieren und zu verwalten, ohne riesige Modelldateien für jeden einzelnen zu speichern.
Das vollständige Colab -Notizbuch finden Sie hier: Colab
Abschluss
Großsprachige Modelle sind hier, um zu bleiben, aber ihre huge Größe stellt eine echte Herausforderung dar. LLM -Komprimierungstechniken sind der Schlüssel, um ihr Potenzial für einen größeren Anwendungsbereich freizuschalten. Unabhängig davon, ob es sich um den einfachen Ansatz der Modellquantisierung, die chirurgische Präzision von Modellbeschneidungsmethoden, die clevere Mentorschaft der Wissensdestillation in LLMs oder die Effizienz der Anpassung mit niedriger Rang (LORA) machen diese Methoden KI praktischer. Die richtige Technik hängt von Ihren spezifischen Bedürfnissen ab, aber das Kombinieren kann häufig zu den besten Ergebnissen führen.
Häufig gestellte Fragen
A. Modellquantisierung, insbesondere die Quantisierung nach dem Coaching (PTQ), ist im Allgemeinen am einfachsten. Bibliotheken wie BitsandBytes ermöglichen es Ihnen, ein quantisiertes Modell mit einer einzelnen Codezeile zu laden.
A. Es kann die Genauigkeit geringfügig verringern, aber für viele Anwendungen ist der Verlust minimal und oft unbemerkt. Techniken wie das quantisierungsbewusste Coaching (QAT) können dazu beitragen, die Genauigkeit noch weiter zu bewahren.
A. Ja, und es wird oft empfohlen. Ein häufiger und effektiver Workflow besteht darin, zuerst ein Modell zu beschneiden, dann das Ergebnis zu quantisieren und Wissensdestillation zu nutzen, um eine verlorene Leistung zu optimieren und wiederzugewinnen.
A. Beschneiden entfernt ganze Verbindungen (Gewichte) aus dem Modell, wodurch es sparsamer wird. Quantisierung reduziert die numerische Präzision aller Gewichte, ohne die Architektur des Modells zu ändern.
A. Lora verkleinert das ursprüngliche Basismodell nicht. Stattdessen komprimiert es das Anpassung oder Feinabstimmungsprozess, mit dem Sie leichte, aufgabenspezifische Modellversionen erstellen können, die viel kleiner als das Unique sind.
Harsh Mishra ist ein KI/ML -Ingenieur, der mehr Zeit damit verbringt, mit großen Sprachmodellen zu sprechen als mit tatsächlichen Menschen. Leidenschaft über Genai, NLP und Maschinen schlauer (damit sie ihn noch nicht ersetzen). Wenn er Fashions nicht optimiert, optimiert er wahrscheinlich seine Kaffeeaufnahme. 🚀☕
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.