Für ML -Praktiker ist die natürliche Erwartung, dass ein neues ML -Modell, das vielversprechende Ergebnisse offline zeigt, auch in der Produktion erfolgreich sein wird. Aber oft ist das nicht der Fall. ML -Modelle, die die Testdaten übertreffen, können für echte Produktionsbenutzer unterdurchschnittlich sein. Diese Diskrepanz zwischen Offline- und On-line -Metriken ist häufig eine große Herausforderung für das maschinelle Lernen angewandt.
In diesem Artikel werden wir untersuchen, was sowohl On-line- als auch Offline -Metriken wirklich messen, warum sie sich unterscheiden und wie ML -Groups Modelle erstellen können, die sowohl on-line als auch offline intestine abschneiden können.
Der Komfort von Offline -Metriken
Die Offline -Modellbewertung ist der erste Kontrollpunkt für jedes Modell in der Bereitstellung. Die Trainingsdaten werden normalerweise in Zugsätze und Validierungs-/Testsätze unterteilt, und die Bewertungsergebnisse werden auf letzterem berechnet. Die für die Bewertung verwendeten Metriken können je nach Modelltyp variieren: a Einstufung Modell verwendet normalerweise Präzision, RückrufAUC usw., a Empfehlungssystem Verwendet NDCG, Karte, während ein Prognosemodell RMSE, MAE, MAPE usw. verwendet.
Die Offline -Bewertung ermöglicht eine schnelle Iteration, da Sie mehrere Modellbewertungen professional Tag ausführen, ihre Ergebnisse vergleichen und ein schnelles Suggestions erhalten können. Aber sie haben Grenzen. Die Bewertungsergebnisse hängen stark von dem von Ihnen ausgewählten Datensatz ab. Wenn der Datensatz keinen Produktionsverkehr darstellt, können Sie ein falsches Vertrauensgefühl erhalten. Die Offline -Bewertung ignoriert auch On-line -Faktoren wie Latenz, Backend -Einschränkungen und dynamisches Benutzerverhalten.
Die Realitätsprüfung von On-line -Metriken
Im Gegensatz dazu werden On-line -Metriken in einer Dwell -Produktionsumgebung über A/B -Checks oder Dwell -Überwachung gemessen. Diese Metriken sind diejenigen, die für das Geschäft von Bedeutung sind. Für Empfehlungssysteme können es Trichterraten wie Click on-Via-Fee (CTR) und Conversion Fee (CVR) oder Retention sein. Für ein Prognosemodell kann es Kosteneinsparungen, eine Verringerung der Ereignisse außerhalb des Bestehens usw. bringen.
Die offensichtliche Herausforderung bei On-line -Experimenten besteht darin, dass sie teuer sind. Jeder A/B -Check verbraucht den Versuchsverkehr, der zu einem anderen Experiment hätte gehen können. Die Ergebnisse dauern Tage, manchmal sogar Wochen, um zu stabilisieren. Darüber hinaus können On-line -Signale manchmal laut sein, dh von Saisonalität, Feiertagen, die mehr Datenwissenschaftsbandbreite bedeuten können, um den wahren Effekt des Modells zu isolieren.
| Metrischer Typ | Vor- & Nachteile |
| Offline -Metriken, z. B. AUC, Genauigkeit, RMSE, MAPE |
Profis: Schnell, wiederholbar und billig Nachteile: Spiegelt die reale Welt nicht wider |
| On-line -Kennzahlen, z. B. CTR, Aufbewahrung, Einnahmen |
Profis: Wahre geschäftliche Auswirkungen, die die reale Welt widerspiegeln Nachteile: Teuer, langsam und laut (betroffen durch externe Faktoren) |
Die On-line-Offline-Trennung
Warum stolpern Modelle, die offline leuchten, on-line? Erstens ist das Benutzerverhalten sehr dynamisch und Modelle, die in der Vergangenheit geschult sind, können möglicherweise nicht mit den aktuellen Benutzeranforderungen Schritt halten. Ein einfaches Beispiel hierfür ist ein im Winter geschultes Empfehlungssystem, das möglicherweise nicht die richtigen Empfehlungen für den Sommer geben kann, da sich die Benutzerpräferenzen geändert haben. Zweitens spielen Suggestions-Loops eine entscheidende Rolle in der On-line-Offline-Diskrepanz. Das Experimentieren mit einem Modell in der Produktion verändert das, was Benutzer sehen, was wiederum ihr Verhalten verändert, was sich auf die von Ihnen gesammelten Daten auswirkt. Diese rekursive Schleife existiert bei Offline -Checks nicht.
Offline -Metriken gelten als Proxies für On-line -Metriken. Aber oft stimmen sie nicht mit realen Zielen zusammen. Zum Beispiel minimiert Root Imply Squared Fehler (RMSE) den Gesamtfehler, kann jedoch nicht excessive Peaks und Trogs erfassen, die bei der Planung der Lieferketten vielmehr wichtig sind. Zweitens können App -Latenz und andere Faktoren auch die Benutzererfahrung beeinflussen, was sich wiederum auf Geschäftsmetriken auswirken würde.
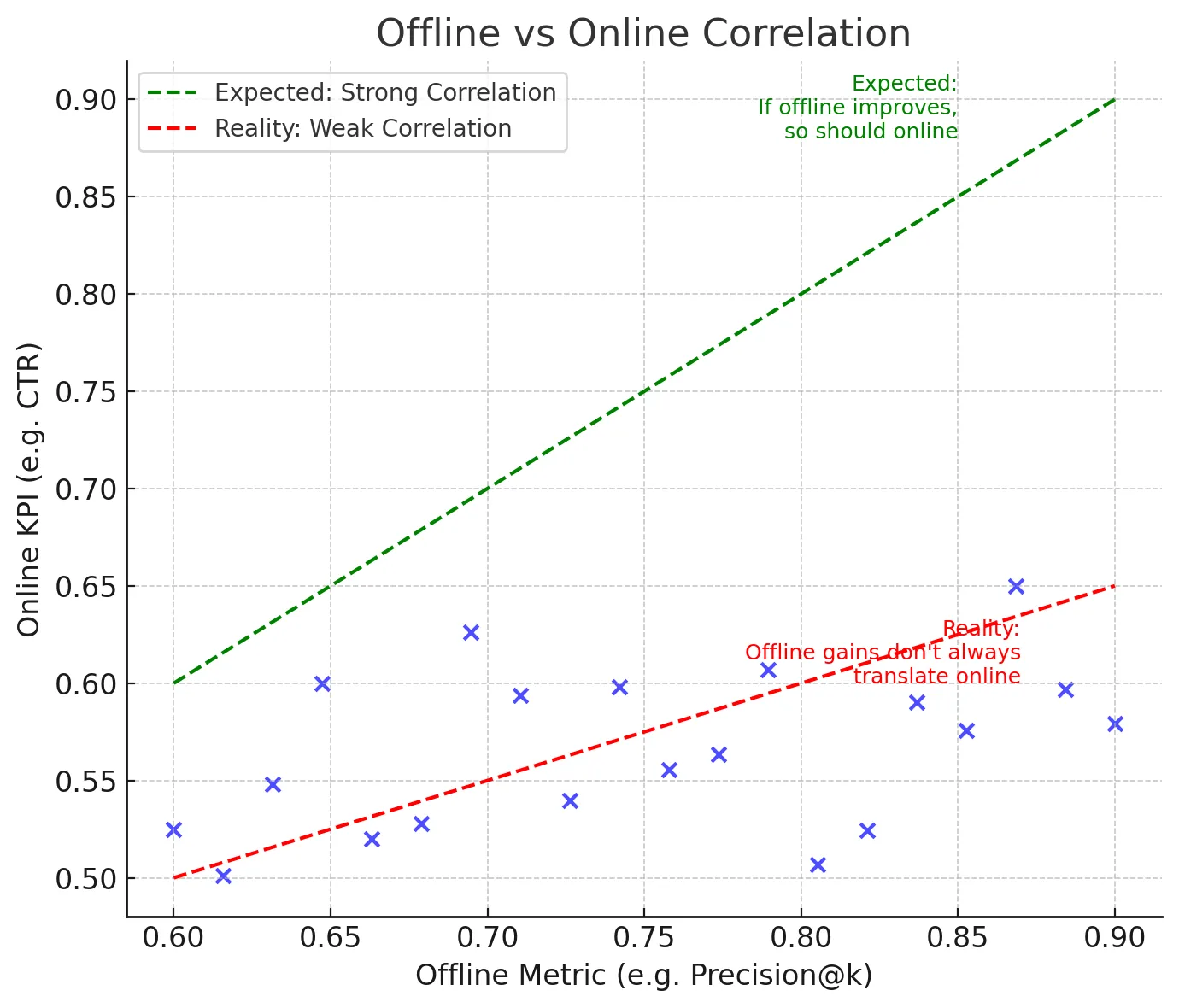
Die Lücke überbrücken
Die gute Nachricht ist, dass es Möglichkeiten gibt, das Downside der On-line-Offline-Diskrepanz zu verringern.
- Wählen Sie bessere Stellvertreter: Wählen Sie mehrere Proxy -Metriken aus, die die Geschäftsergebnisse annähern, anstatt eine Metrik zu überlegen. Beispielsweise kann ein Empfehlungssystem Präzision@ok mit anderen Faktoren wie Vielfalt kombinieren. Ein Prognosemodell könnte die Reduzierung der Förderung und andere Geschäftsmetriken neben RMSE bewerten.
- Studienkorrelationen: Mit früheren Experimenten können wir analysieren, welche Offline -Metriken mit erfolgreichen On-line -Ergebnissen korrelierten. Einige Offline -Kennzahlen werden durchweg besser sein als andere, wenn sie den On-line -Erfolg vorhersagen. Das Dokumentieren dieser Erkenntnisse und die Verwendung dieser Metriken hilft dem gesamten Group, zu wissen, auf welche Offline -Metriken sie sich verlassen können.
- Simulation von Interaktionen: Es gibt einige Methoden in Empfehlungssystemen, wie Bandit -Simulatoren, die die historischen Protokolle der Benutzer wiederholen und schätzen, was passiert wäre, wenn ein anderes Rating gezeigt worden wäre. Eine kontrafaktische Bewertung kann auch dazu beitragen, das On-line -Verhalten mithilfe von Offline -Daten zu nähern. Methoden wie diese können dazu beitragen, die On-line-Offline-Lücke einzugrenzen.
- Überwachen Sie nach der Bereitstellung: Trotz erfolgreicher A/B -Checks driftet die Modelle, wenn sich das Benutzerverhalten weiterentwickelt (wie das obige Winter- und Sommerbeispiel). Daher wird es immer bevorzugt, sowohl Eingabedaten als auch KPIs auszugeben, um sicherzustellen, dass die Diskrepanz nicht stillschweigend wieder geöffnet wird.
Praktisches Beispiel
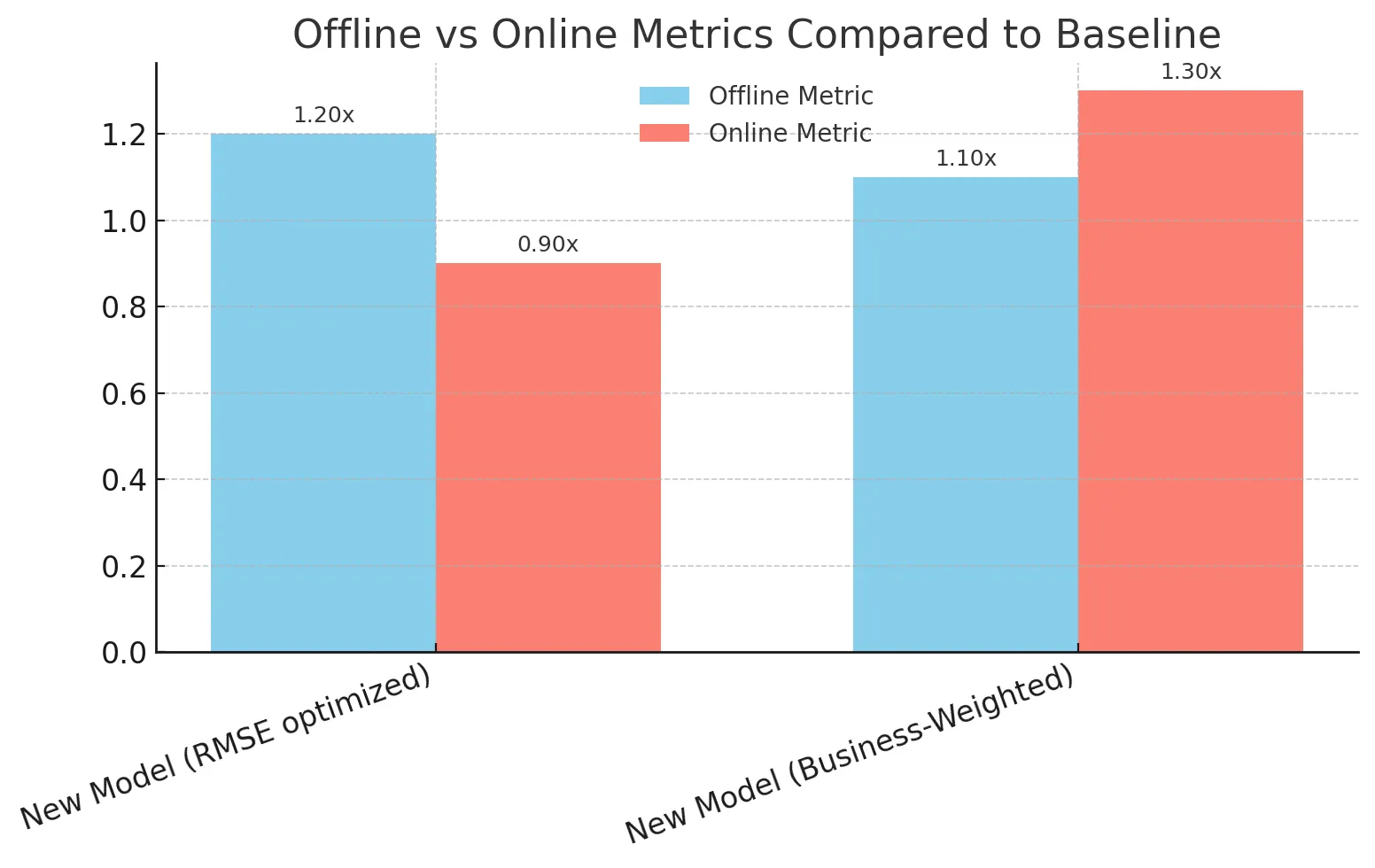
Betrachten Sie ein Einzelhändler, der ein neues Nachfrageprognosemodell einsetzt. Das Modell zeigte großartige vielversprechende Ergebnisse offline (in RMSE und MAPE), was das Group sehr aufgeregt machte. Bei on-line getestet wurde das Unternehmen jedoch nur minimale Verbesserungen und in einigen Metriken sahen die Dinge sogar schlechter aus als die Basislinie.
Das Downside struggle die Fehlausrichtung der Proxy. Bei der Planung der Lieferkette führt die Unterpressung der Nachfrage nach einem Trendprodukt zu verlorenen Umsätzen, während die überbearbeitete Nachfrage nach einem langsam bewegenden Produkt zu einem Verschwendung von Inventar führt. Die Offline-Metrik-RMSE behandelte beide gleich, aber die realen Kosten waren nicht symmetrisch.
Das Group entschied sich, seinen Bewertungsrahmen neu zu definieren. Anstatt sich nur auf RMSE zu verlassen, definierten sie eine maßgefertigte geschäftsgewichtige Metrik, die die Unterpressung stärker für Trendprodukte bestraft und explizit nachverfolgt wurde. Mit dieser Änderung lieferte die nächste Modell -Iteration sowohl starke Offline -Ergebnisse als auch On-line -Umsatzgewinne.
Gedanken schließen
Offline -Metriken sind wie die Proben einer Tanzpraxis: Sie können schnell lernen, Ideen testen und in einer kleinen, kontrollierten Umgebung scheitern. On-line -Metriken sind wie diese tatsächliche Tanzperformance: Sie messen die tatsächlichen Reaktionen des Publikums und ob Ihre Änderungen einen echten Geschäftswert bieten. Keiner allein ist genug.
Die eigentliche Herausforderung besteht darin, die besten Offline -Bewertungsrahmen und Metriken zu finden, die den On-line -Erfolg vorhersagen können. Wenn es intestine gemacht wird, können Groups schneller experimentieren und innovieren, verschwendete A/B -Checks minimieren und besser bauen Ml Systeme, die sowohl offline als auch on-line intestine durchführen.
Häufig gestellte Fragen
A. Da Offline-Metriken dynamisches Benutzerverhalten, Suggestions-Schleifen, Latenz und reale Kosten nicht erfassen, die On-line-Metriken messen.
A. Sie sind schnell, billig und wiederholbar, was während der Entwicklung eine schnelle Iteration ermöglicht.
A. Sie spiegeln echte geschäftliche Auswirkungen wie CTR, Aufbewahrung oder Einnahmen in Dwell -Umgebungen wider.
A. Durch Auswahl besserer Proxy -Metriken, Studienkorrelationen, Simulation von Interaktionen und Überwachungsmodellen nach der Bereitstellung.
A. Ja, Groups können geschäftsgewichtete Metriken entwerfen, die Fehler unterschiedlich bestrafen, um die Kosten der realen Welt zu widerspiegeln.
Madhura Raut ist eine Hauptdatenwissenschaftlerin am Arbeitstag, wo sie das Design von großflächigen maschinellen Lernsystemen für die Prognose der Arbeitsbedarf leitet. Sie ist die führende Erfinderin bei zwei US -Patenten im Zusammenhang mit fortschrittlichen Zeitreihenstechniken, und ihr ML -Produkt wurde von Personalrecutive als Prime -HR -Produkt des Jahres anerkannt. Madhura struggle ein Hauptredner auf vielen renommierten Datenwissenschaftskonferenzen, darunter KDD 2025, und struggle Richter und Mentor für mehrere Cosecrunch -Hackathons.
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.