
Bild von Autor | Chatgpt
Der Datenqualität Engpass, den jeder Datenwissenschaftler kennt
Sie haben gerade einen neuen Datensatz erhalten. Bevor Sie in die Analyse eintauchen, müssen Sie verstehen, womit Sie arbeiten: Wie viele fehlende Werte? Welche Spalten sind problematisch? Was ist die Gesamtpunktzahl der Datenqualität?
Die meisten Datenwissenschaftler verbringen 15 bis 30 Minuten damit, jeden neuen Datensatz manuell zu untersuchen-und laden sie in Pandas, laufend .data()Anwesend .describe()Und .isnull().sum()dann erstellen Sie Visualisierungen, um fehlende Datenmuster zu verstehen. Diese Routine wird mühsam, wenn Sie täglich mehrere Datensätze bewerten.
Was wäre, wenn Sie eine CSV -URL einfügen und einen professionellen Datenqualitätsbericht in weniger als 30 Sekunden erhalten könnten? Kein Python -Umgebungsaufbau, keine manuelle Codierung, kein Umschalten zwischen den Werkzeugen.
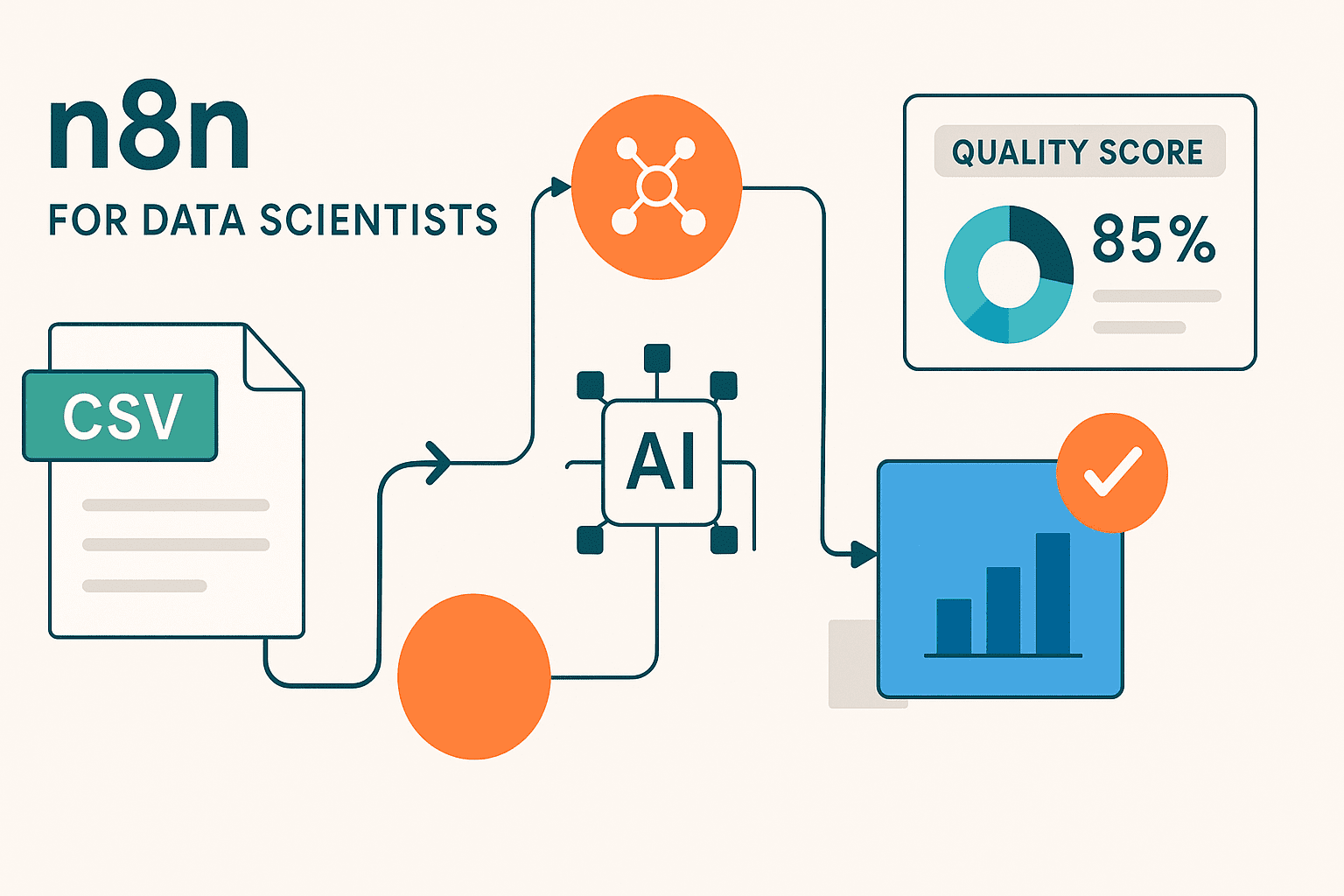
Die Lösung: ein 4-Knoten-N8N-Workflow
n8n (ausgesprochen „n-acht-n“) ist eine Open-Supply-Workflow-Automatisierungsplattform, die verschiedene Dienste, APIs und Instruments über eine visuelle Drag & Drop-Schnittstelle verbindet. Während die meisten Menschen Workflow -Automatisierung mit Geschäftsprozessen wie E -Mail -Advertising oder Kundensupport in Verbindung bringen, kann N8N auch die Automatisierung von Datenwissenschaftsaufgaben unterstützen, die traditionell benutzerdefinierte Skripts erfordern.
Im Gegensatz zum Schreiben von Standalone -Python -Skripten sind N8N -Workflows visuell, wiederverwendbar und leicht zu ändern. Sie können Datenquellen anschließen, Transformationen ausführen, Analysen ausführen und Ergebnisse liefern – alle, ohne zwischen verschiedenen Instruments oder Umgebungen zu wechseln. Jeder Workflow besteht aus „Knoten“, die unterschiedliche Aktionen darstellen, die miteinander verbunden sind, um eine automatisierte Pipeline zu erstellen.
Unser automatisierter Datenqualitätsanalysator besteht aus vier verbundenen Knoten:

- Manueller Auslöser – Startet den Workflow, wenn Sie auf „Ausführen“ klicken.
- HTTP -Anfrage – Holen Sie sich jede CSV -Datei aus einer URL
- Codeknoten – Analysiert die Daten und generiert Qualitätskennzahlen
- HTML -Knoten – Erstellt einen schönen, professionellen Bericht
Erstellen des Workflows: Schritt-für-Schritt-Implementierung
Voraussetzungen
- N8N -Konto (kostenlose 14 -tägige Testversion bei n8n.io)
- Unsere vorgefertigte Workflow-Vorlage (JSON -Datei zur Verfügung gestellt)
- Jeder CSV -Datensatz, der über öffentliche URL zugänglich ist (wir werden Testbeispiele angeben)
Schritt 1: Importieren Sie die Workflow -Vorlage
Anstatt von Grund auf neu zu bauen, werden wir eine vorkonfigurierte Vorlage verwenden, die alle Analyselogik enthält:
- Laden Sie die herunter Workflow -Datei
- Öffnen n8n und klicken Sie auf „aus der Datei importieren“
- Wählen Sie die heruntergeladene JSON -Datei aus – Alle vier Knoten werden automatisch angezeigt
- Speichern Sie den Workflow mit Ihrem bevorzugten Namen
Der importierte Workflow enthält vier angeschlossene Knoten mit allen bereits konfigurierten komplexen Parsen- und Analysecode.
Schritt 2: Verstehen Sie Ihren Workflow
Gehen wir durch das, was jeder Knoten tut:
Manueller Triggerknoten: Startet die Analyse, wenn Sie auf „Workflow ausführen“ klicken. Perfekt für On-Demand-Datenqualitätsprüfungen.
HTTP -Anforderungsknoten: Ruft CSV -Daten aus jeder öffentlichen URL ab. Vorkonfiguriert, um die meisten Normal-CSV-Formate zu verarbeiten und die für die Analyse erforderlichen Rohtextdaten zurückzugeben.
Codeknoten: Die Analyse -Engine, die eine robuste CSV -Parsing -Logik enthält, um häufige Variationen bei der Nutzung des Trennzeichens, den zitierten Feldern und fehlenden Wertformaten zu verarbeiten. Es automatisch:
- Parsen CSV -Daten mit intelligenter Felderkennung
- Identifiziert fehlende Werte in mehreren Formaten (Null, leer, „n/a“ usw.)
- Berechnet Qualitätswerte und Schweregradbewertungen
- Generiert spezifische, umsetzbare Empfehlungen
HTML -Knoten: Verwandelt die Analyseergebnisse in einen schönen, professionellen Bericht mit farbencodierten Qualitätswerten und sauberer Formatierung.
Schritt 3: Anpassen für Ihre Daten
So analysieren Sie Ihren eigenen Datensatz:
- Klicken Sie auf den HTTP -Anforderungsknoten
- Ersetzen Sie die URL Mit Ihrer CSV -Datensatz -URL:
- Aktuell:
https://uncooked.githubusercontent.com/fivethirtyeight/information/grasp/college-majors/recent-grads.csv - Ihre Daten:
https://your-domain.com/your-dataset.csv
- Aktuell:
- Speichern Sie den Workflow

Das conflict’s! Die Analyselogik passt sich automatisch an verschiedene CSV -Strukturen, Spaltennamen und Datentypen an.
Schritt 4: Ergebnisse ausführen und anzeigen
- Klicken Sie auf „Workflow ausführen“ in der oberen Symbolleiste
- Beobachten Sie den Vorgang des Knotens – Jedes zeigt ein grünes Checkmark, wenn es vollständig ist
- Klicken Sie auf den HTML -Knoten und wählen Sie die Registerkarte „HTML“, um Ihren Bericht anzuzeigen
- Kopieren Sie den Bericht Oder machen Sie Screenshots, um sie mit Ihrem Group zu teilen
Der gesamte Vorgang dauert weniger als 30 Sekunden, sobald Ihr Workflow eingerichtet ist.
Die Ergebnisse verstehen
Die farbcodierte Qualitätsbewertung bietet Ihnen eine sofortige Bewertung Ihres Datensatzes:
- 95-100%: Perfekte (oder nahezu perfekte) Datenqualität, bereit für die sofortige Analyse
- 85-94%: Hervorragende Qualität mit minimaler Reinigung erforderlich
- 75-84%: Gute Qualität, eine Vorverarbeitung erforderlich
- 60-74%: Faire Qualität, mittelschwere Reinigung benötigt
- Unter 60%: Schlechte Qualität, bedeutende Datenarbeiten erforderlich
Hinweis: Diese Implementierung verwendet ein einfaches Bewertungssystem für fehlende Daten. Erweiterte Qualitätsmetriken wie Datenkonsistenz, Ausreißerkennung oder Schema -Validierung könnten zukünftigen Versionen hinzugefügt werden.
So sieht der Abschlussbericht aus:


Unsere Beispielanalyse zeigt einen Qualitätswert von 99,42% – was darauf hinweist, dass der Datensatz weitgehend vollständig und mit minimaler Vorverarbeitung analysiert ist.
Datensatzübersicht:
- 173 Gesamtzahl der Aufzeichnungen: Eine kleine, aber ausreichende Stichprobengröße supreme für eine schnelle explorative Analyse
- 21 Gesamtspalten: Eine überschaubare Anzahl von Funktionen, die fokussierte Erkenntnisse ermöglichen
- 4 Spalten mit fehlenden Daten: Einige ausgewählte Felder enthalten Lücken
- 17 Komplette Spalten: Die Mehrheit der Felder ist vollständig besiedelt
Testen mit verschiedenen Datensätzen
Um zu sehen, wie der Workflow unterschiedliche Datenqualitätsmuster umgeht, probieren Sie diese Beispieldatensätze aus:
- Iris -Datensatz (
https://uncooked.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/information/iris.csv) zeigt normalerweise eine perfekte Punktzahl (100%) ohne fehlende Werte. - Titanic -Datensatz (
https://uncooked.githubusercontent.com/datasciencedojo/datasets/grasp/titanic.csv) zeigt eine realistischere Punktzahl von 67,6% aufgrund strategischer fehlender Daten in Spalten wie Alter und Kabine. - Ihre eigenen Daten: Laden Sie in GitHub RAW hoch oder verwenden Sie eine öffentliche CSV -URL
Basierend auf Ihrer Qualitätsbewertung können Sie die nächsten Schritte ermitteln: Über 95% können Sie direkt mit explorativen Datenanalysen fortfahren. 85-94% deuten auf eine minimale Reinigung identifizierter problematischer Spalten hin. 75-84% weisen auf average Vorprozesarbeiten hin, die erforderlich sind. 60-74% erfordert die Planung von Reinigungsstrategien, und unter den unteren. Der Workflow passt sich automatisch an jede CSV -Struktur an, sodass Sie mehrere Datensätze schnell bewerten und Ihre Datenvorbereitungsbemühungen priorisieren können.
Nächste Schritte
1. E -Mail -Integration
Fügen Sie a hinzu E -Mail senden Knoten, um Berichte automatisch an Stakeholder zu liefern, indem sie nach dem HTML -Knoten verbinden. Dies verwandelt Ihren Workflow in ein Verteilungssystem, in dem Qualitätsberichte automatisch an Projektmanager, Dateningenieure oder Purchasers gesendet werden, wenn Sie einen neuen Datensatz analysieren. Sie können die E -Mail -Vorlage so anpassen, dass Government -Zusammenfassungen oder spezifische Empfehlungen auf der Grundlage der Qualitätsbewertung enthalten sind.
2. Geplante Analyse
Ersetzen Sie den manuellen Abzug durch a Planenauslöser So analysieren Sie die Datensätze in regelmäßigen Abständen automatisch, um Datenquellen zu überwachen, die häufig aktualisiert werden. Richten Sie die täglichen, wöchentlichen oder monatlichen Schecks auf Ihren wichtigsten Datensätzen ein, um die Qualitätsverschlechterung frühzeitig zu fangen. Dieser proaktive Ansatz hilft Ihnen, Datenpipeline -Probleme zu identifizieren, bevor sie sich auf die Downstream -Analyse oder die Modellleistung auswirken.
3.. Mehrere Datensatzanalyse
Ändern Sie den Workflow, um eine Liste von CSV -URLs zu akzeptieren, und generieren Sie gleichzeitig einen vergleichenden Qualitätsbericht über mehrere Datensätze hinweg. Dieser Stapelverarbeitungsansatz ist von unschätzbarem Wert bei der Bewertung von Datenquellen für ein neues Projekt oder die Durchführung regelmäßiger Audits im gesamten Datenbestand Ihres Unternehmens. Sie können zusammenfassende Dashboards erstellen, die Datensätze nach Qualitätsbewertung bewerten, um zu priorisieren, welche Datenquellen sofort beachtet werden müssen, im Vergleich zu den für die Analyse bereitgestellten.
4. Verschiedene Dateiformate
Erweitern Sie den Workflow, um andere Datenformate über CSV hinaus zu verarbeiten, indem Sie die Parsenlogik im Codeknoten ändern. Passen Sie für JSON -Dateien die Datenextraktion an, um verschachtelte Strukturen und Arrays zu verarbeiten, während Excel -Dateien durch Hinzufügen eines Vorverarbeitungsschritts zum Konvertieren von XLSX in das CSV -Format verarbeitet werden können. Durch die Unterstützung mehrerer Formate ist Ihr Qualitätsanalysator zu einem universellen Device für jede Datenquelle in Ihrem Unternehmen, unabhängig davon, wie die Daten gespeichert oder geliefert werden.
Abschluss
Dieser N8N -Workflow zeigt, wie die visuelle Automatisierung die Routine -Datenwissenschaftsaufgaben rationalisieren und gleichzeitig die technische Tiefe beibehält, die Datenwissenschaftler benötigen. Durch die Nutzung Ihres vorhandenen Codierungshintergrunds können Sie die JavaScript -Analyselogik anpassen, die HTML -Berichtsvorlagen erweitern und in Ihre bevorzugte Dateninfrastruktur integrieren – alles innerhalb einer intuitiven visuellen Schnittstelle.
Das modulare Design des Workflows macht es für Datenwissenschaftler besonders wertvoll, die sowohl die technischen Anforderungen als auch den geschäftlichen Kontext der Datenqualitätsbewertung verstehen. Im Gegensatz zu starre No-Code-Instruments können Sie mit N8N die zugrunde liegende Analyselogik ändern und gleichzeitig visuelle Klarheit bereitstellen, die Workflows leicht zu teilen, zu debuggen und zu warten. Sie können mit dieser Grundlage beginnen und nach und nach hoch entwickelte Funktionen wie statistische Anomalie -Erkennung, maßgeschneiderte Qualitätsmetriken oder Integration in Ihre vorhandene MLOPS -Pipeline hinzufügen.
Am wichtigsten ist, dass dieser Ansatz die Lücke zwischen Datenwissenschaftskompetenz und organisatorischer Zugänglichkeit verbindet. Ihre technischen Kollegen können den Code ändern, während nichttechnische Stakeholder Workflows ausführen und die Ergebnisse sofort interpretieren können. Diese Kombination aus technischer Raffinesse und benutzerfreundlicher Ausführung macht N8N supreme für Datenwissenschaftler, die ihre Auswirkungen über die individuelle Analyse hinaus skalieren möchten.
Vinod wurde in Indien geboren und ist in Japan aufgewachsen. Er bringt eine globale Perspektive in die Bildung von Datenwissenschaft und maschinellem Lernen. Er überbrückt die Lücke zwischen aufstrebenden KI -Technologien und der praktischen Umsetzung für Berufstätige. Vinod konzentriert sich darauf, zugängliche Lernwege für komplexe Themen wie Agenten -KI, Leistungsoptimierung und KI -Engineering zu erstellen. Er konzentriert sich auf praktische Implementierungen für maschinelles Lernen und Mentoring der nächsten Technology von Datenfachleuten durch Stay -Sitzungen und personalisierte Anleitung.