
Einführung
In Sprachmodellen, bei denen das Streben nach Effizienz und Präzision im Vordergrund steht, Lama 3.1 Storm 8BBoote kaufen erweist sich als bemerkenswerte Leistung. Diese fein abgestimmte Model von Metas Llama 3.1 8B Instruct stellt einen großen Fortschritt bei der Verbesserung der Konversations- und Funktionsaufruffunktionen innerhalb der 8B-Parametermodellklasse dar. Der Weg zu diesem Fortschritt wurzelt in einem sorgfältigen Ansatz, der sich auf die Datenkuratierung konzentriert, bei der hochwertige Trainingsbeispiele sorgfältig ausgewählt wurden, um das Potenzial des Modells zu maximieren.
Der Feinabstimmungsprozess endete hier nicht; er wurde durch gezielte Feinabstimmung auf Spektrumbasis fortgesetzt und gipfelte in einer strategischen Modellzusammenführung. In diesem Artikel werden die innovativen Techniken beschrieben, mit denen Llama 3.1 Storm 8B seine Vorgänger übertraf und einen neuen Maßstab für kleine Sprachmodelle setzte.

Was ist Llama-3.1-Storm-8B?
Llama-3.1-Storm-8B baut auf den Stärken von Llama-3.1-8B-Instruct auf und verbessert die Konversations- und Funktionsaufruffunktionen innerhalb der 8B-Parametermodellklasse. Dieses Improve weist in mehreren Benchmarks bemerkenswerte Verbesserungen auf, darunter Anweisungsbefolgung, wissensbasierte Qualitätssicherung, Argumentation, Reduzierung von Halluzinationen und Funktionsaufruf. Diese Fortschritte kommen KI-Entwicklern und -Enthusiasten zugute, die mit begrenzten Rechenressourcen arbeiten.
Im Vergleich zu den jüngsten Hermes-3-Llama-3.1-8B 3D-ModellLlama-3.1-Storm-8B übertrifft 7 von 9 Benchmarks. Hermes-3 führt nur im MuSR-Benchmark und beide Modelle schneiden im BBH-Benchmark ähnlich ab.
Llama 3.1 Storm 8B Stärken
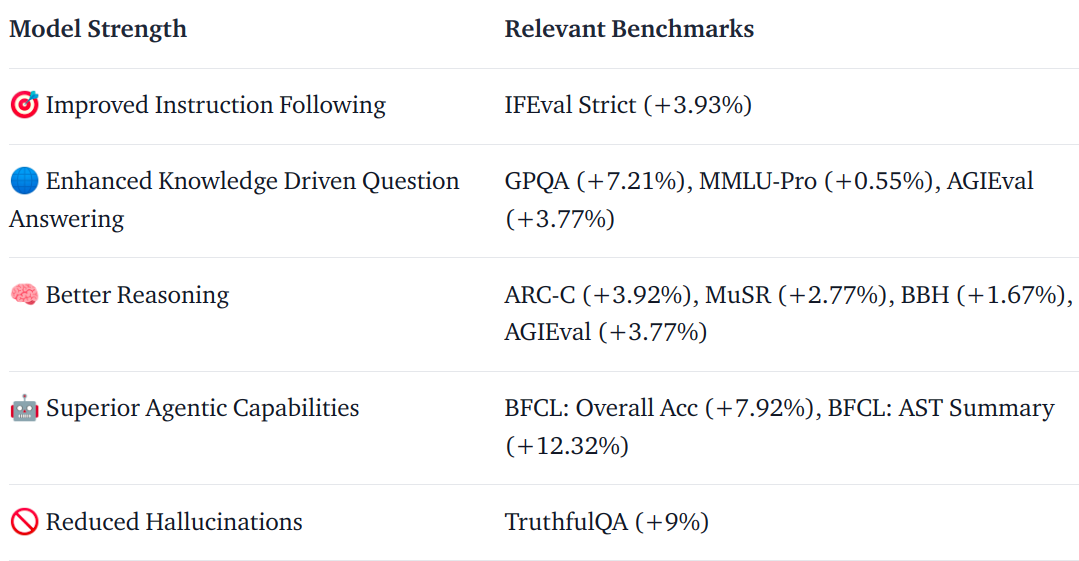
Das obige Bild stellt Verbesserungen (absolute Gewinne) gegenüber dem Llama 3.1 8B Instruct dar.
Llama 3.1 Storm 8B Modelle
Hier sind die Llama 3.1 Storm 8B-Modelle:
- Lama 3.1 Storm 8BBoote kaufen: Dies ist das primäre feinabgestimmte Modell.
- Llama 3.1 Storm 8B FP8 Dynamisch: Das Skript quantisiert die Gewichte und Aktivierungen von Llama-3.1-Storm-8B auf den FP8-Datentyp, was zu einem Modell führt, das für vLLM-Inferenz bereit ist. Durch die Reduzierung der Anzahl der Bits professional Parameter von 16 auf 8 spart diese Optimierung etwa 50 % des GPU-Speicherbedarfs und des Speicherplatzes.
Die Gewichte und Aktivierungen der linearen Operatoren sind die einzigen quantisierten Elemente in Transformatorblöcken. Die FP8-Darstellungen dieser quantisierten Gewichte und Aktivierungen werden mithilfe einer einzigen linearen Skalierungstechnik abgebildet, die als symmetrische Professional-Tensor-Quantisierung bekannt ist. 512 UltraChat-Sequenzen werden mithilfe des LLM Compressor quantisiert.
- Llama 3.1 Storm 8B GGUF: Dies ist die GGUF-quantisierte Model von Llama-3.1-Storm-8B zur Verwendung mit llama.cpp. GGUF ist ein Dateiformat zum Speichern von Modellen für die Inferenz mit GGML und auf GGML basierenden Executoren. GGUF ist ein Binärformat, das für das schnelle Laden und Speichern von Modellen und für einfaches Lesen konzipiert ist. Modelle werden traditionell mit PyTorch oder einem anderen Framework entwickelt und dann zur Verwendung in GGML in GGUF konvertiert. Es ist ein Nachfolgedateiformat von GGML, GGMF und GGJT und wurde so konzipiert, dass es eindeutig ist, da es alle zum Laden eines Modells erforderlichen Informationen enthält. Es ist außerdem so konzipiert, dass es erweiterbar ist, sodass Modellen neue Informationen hinzugefügt werden können, ohne die Kompatibilität zu beeinträchtigen.
Lesen Sie auch: Meta Llama 3.1: Neuestes Open-Supply-KI-Modell übernimmt GPT-4o mini
Der verfolgte Ansatz
Der Leistungsvergleich zeigt, dass Llama 3.1 Storm 8B Meta AI deutlich übertrifft. Lama 3.1 8B Anweisung Und Hermes 3 Llama 3.1 8B Modelle über verschiedene Benchmarks hinweg.
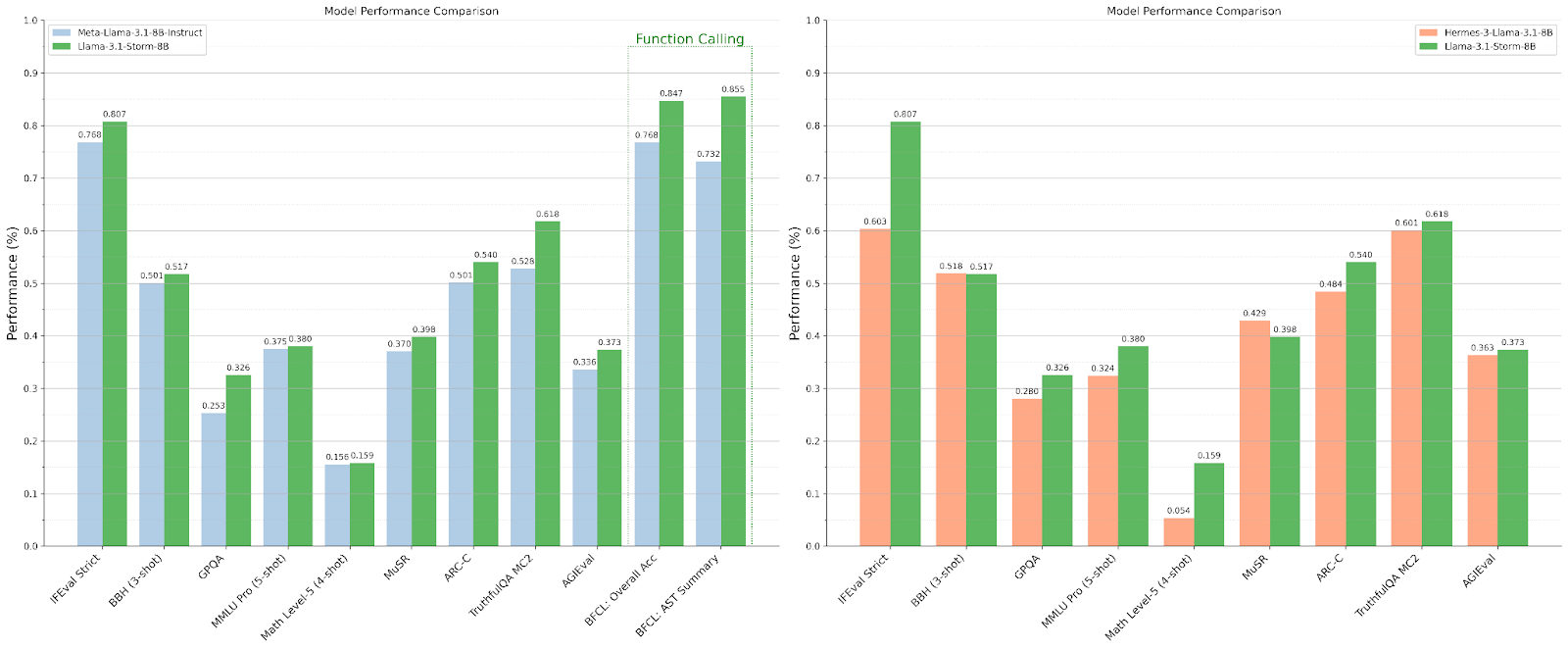
Ihr Ansatz besteht aus drei Hauptschritten:
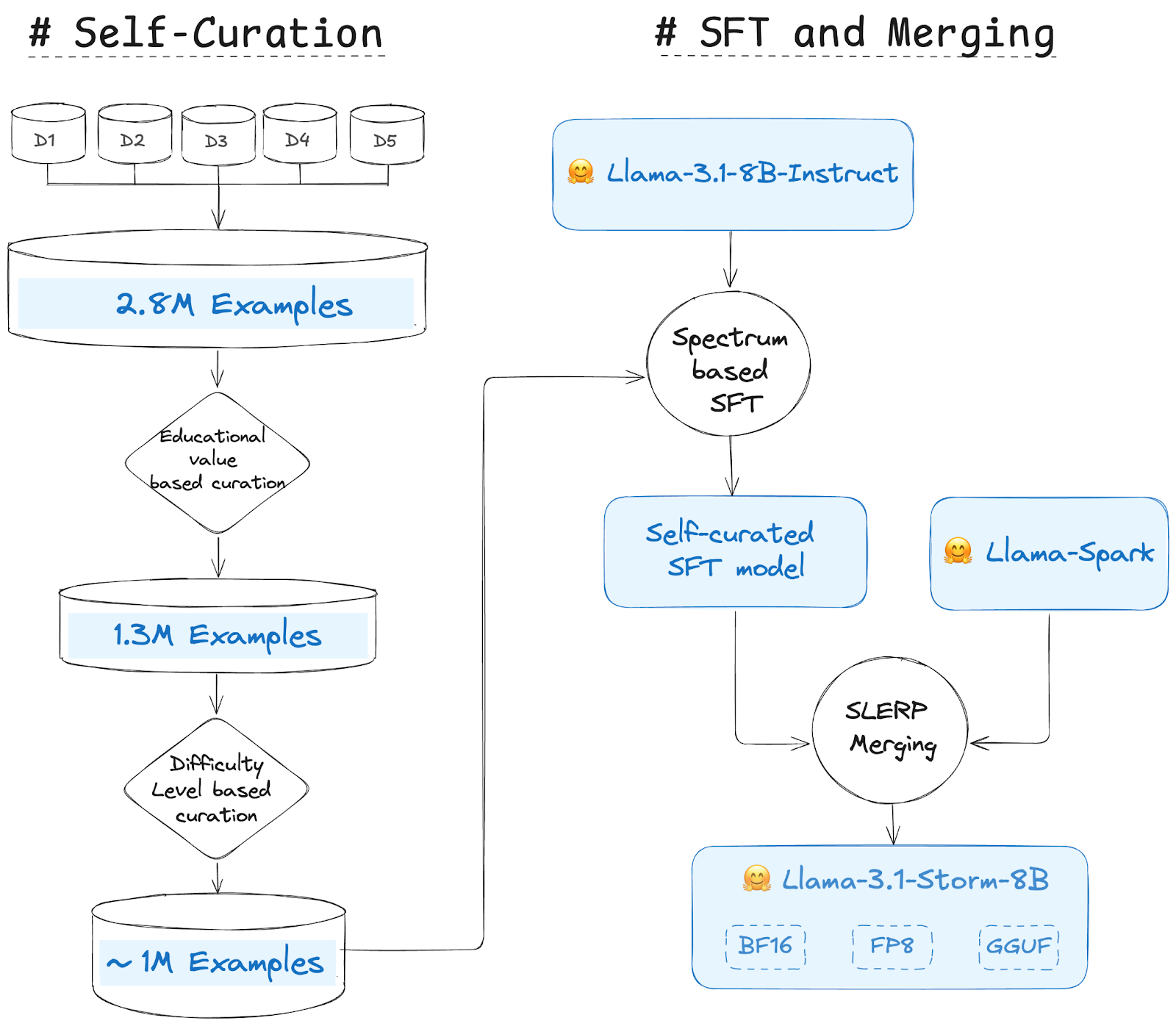
Selbstkuratierung
Die für Llama 3.1 Storm 8B verwendeten Quelldatensätze sind diese 5 Open-Supply-Datensätze (Das-Buch, Agentendaten, Magpie-Llama-3.1-Professional-300K-gefiltert, openhermes_200k_unfilteredLlama-3-Magpie-PO-100K-SML). Die kombinierten Datensätze enthalten insgesamt ca. 2,8 Millionen Beispiele. Jedem Beispiel in der Datenkuratierung wird ein oder mehrere Werte zugewiesen, und Auswahlentscheidungen werden dann abhängig von den Werten getroffen, die jeder Probe zugewiesen werden. Um solche Werte zuzuweisen, werden normalerweise LLM- oder maschinelle Lernmodelle verwendet. Bei Verwendung von LLM gibt es zahlreiche Ansätze, um einem Beispiel einen Wert zuzuweisen. Bildungswert und Schwierigkeitsgrad sind zwei der am häufigsten verwendeten Metriken zur Bewertung der Beispiele.
Der Wert oder die Aussagekraft des Beispiels (Anweisung + Antwort) wird durch seinen Bildungswert und der Schwierigkeitsgrad durch seinen Schwierigkeitsgrad bestimmt. Der Bildungswert liegt zwischen 1 und 5, wobei 1 am wenigsten lehrreich und 5 am lehrreichsten ist. Es gibt 3 Schwierigkeitsstufen – Einfach, Mittel und Schwer. Das Ziel besteht darin, SLM im Rahmen der Selbstkuratierung zu verbessern. Daher haben wir uns darauf konzentriert, dasselbe Modell anzuwenden – Verwenden Sie Llama-3.1-8B-Instruct anstelle von Llama-3.1-70B-Instruct, Llama-3.1-405B-Instruct und anderen größeren LLMs.
Schritte zur Selbstkuratierung:
- Schritt 1: Bildung Wertbasierte Kuration – Sie verwendeten Llama 3.1 Instruct 8B, um allen Beispielen (~2,8 Mio.) einen Bildungswert (1-5) zuzuweisen. Dann wählten sie die Beispiele mit einem Wert über 3 aus. Sie folgten dem Ansatz des FineWeb-Edu-Datensatz. Durch diesen Schritt wurde die Gesamtzahl der Beispiele von 2,8 Mio. auf 1,3 Mio. reduziert..
- Schritt 2: Kuratierung basierend auf Schwierigkeitsgraden – Wir folgen einem ähnlichen Ansatz und verwenden Llama 3.1. Weisen Sie 8B an, 1,3 Millionen Beispielen aus dem vorherigen Schritt einen Schwierigkeitsgrad (Einfach, Mittel und Schwer) zuzuweisen. Nach einigen Experimenten wählten sie Beispiele mit mittlerem und schwerem Schwierigkeitsgrad aus. Diese Strategie ähnelt der Datenbereinigung, die im Abschnitt „Datenbereinigung“ beschrieben wird. Technischer Bericht zu Llama-3.1. Es gab ca. 650.000 bzw. 325.000 Beispiele für den mittleren bzw. schweren Schwierigkeitsgrad.
Der endgültige kuratierte Datensatz enthielt ca. 975.000 Beispiele. Anschließend wurden 960.000 bzw. 15.000 für Coaching und Validierung aufgeteilt.
Gezielte Feinabstimmung des überwachten Unterrichts
Das Self Curation-Modell, das auf dem Llama-3.1-8B-Instruct-Modell mit ~960.000 Beispielen über 4 Epochen feinabgestimmt wurde, verwendet Spectrum, eine Methode, die das LLM-Coaching beschleunigt, indem sie Schichtmodule selektiv anhand ihres Sign-Rausch-Verhältnisses (SNR) anvisiert und den Relaxation einfriert. Spectrum kombiniert effektiv die vollständige Feinabstimmungsleistung mit reduzierter GPU-Speichernutzung, indem es Schichten mit hohem SNR priorisiert und 50 % der Schichten mit niedrigem SNR einfriert. Vergleiche mit Methoden wie QLoRA zeigen die überlegene Modellqualität und VRAM-Effizienz von Spectrum in verteilten Umgebungen.
Modellzusammenführung
Da die Modellzusammenführung zu einigen hochmodernen Modellen geführt hat, haben sie beschlossen, das selbst kuratierte, fein abgestimmte Modell mit dem Llama Spark-Modell zusammenzuführen, das ein Derivat von Llama 3.1 8B Instruct ist. Sie verwendeten die SLERP-Methode, um die beiden Modelle zusammenzuführen, und erstellten so ein gemischtes Modell, das durch sanfte Interpolation die Essenz beider Eltern erfasst. Die sphärische lineare Interpolation (SLERP) gewährleistet eine konstante Änderungsrate unter Beibehaltung der geometrischen Eigenschaften des sphärischen Raums, sodass das resultierende Modell wichtige Merkmale beider Elternmodelle beibehalten kann. Wir können die Benchmarks sehen, bei denen das selbstkuratierte SFT-Modell im Durchschnitt besser abschneidet als das Llama-Spark-Modell. Das zusammengeführte Modell schneidet jedoch sogar besser ab als jedes der beiden Modelle.
Auswirkungen der Selbstkuratierung und Modellzusammenführung
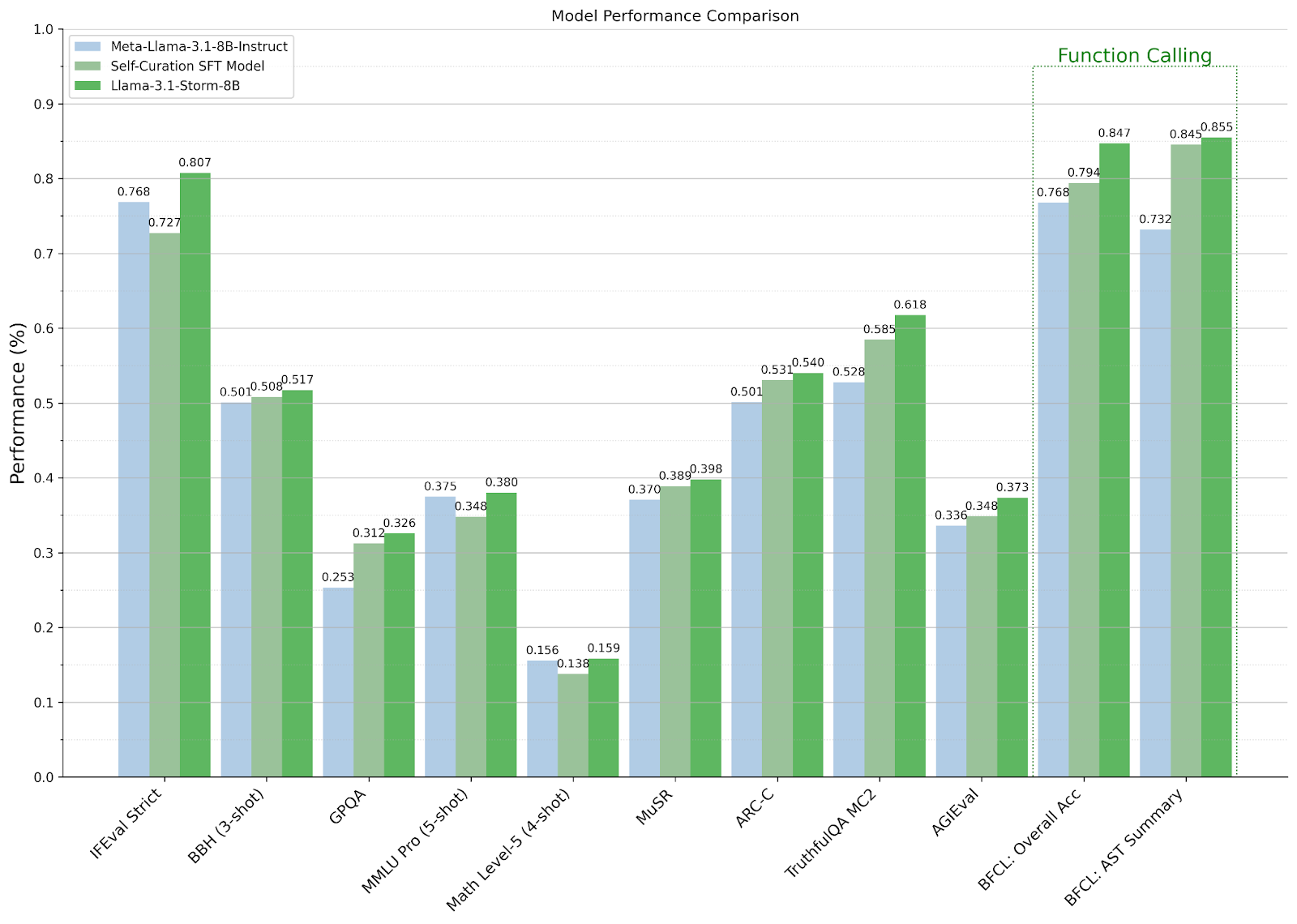
Wie die obige Abbildung zeigt, übertrifft die auf Selbstkuration basierende SFT-Strategie Llama-3.1-8B-Instruct bei 7 von 10 Benchmarks, was die Bedeutung der Auswahl qualitativ hochwertiger Beispiele unterstreicht. Diese Ergebnisse legen auch nahe, dass die Wahl des richtigen kombinierten Modells die Leistung bei den bewerteten Benchmarks noch weiter verbessern kann.
So verwenden Sie das Modell Llama 3.1 Storm 8B
Wir werden die Transformer-Bibliothek von Hugging Face verwenden, um das Llama 3.1 Storm 8B-Modell zu verwenden. Standardmäßig laden Transformer das Modell in bfloat16, dem Typ, der bei der Feinabstimmung verwendet wird. Es wird empfohlen, diesen Typ zu verwenden.
Methode 1: Transformers Pipeline verwenden
1. Platz Schritt: Set up der benötigten Bibliotheken
!pip set up --upgrade "transformers>=4.43.2" torch==2.3.1 speed up flash-attn==2.6.32. Schritt: Laden Sie das Llama 3.1 Storm 8B-Modell
import transformers
import torch
model_id = "akjindal53244/Llama-3.1-Storm-8B"
pipeline = transformers.pipeline(
"text-generation",
mannequin=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)3. Schritt: Erstellen einer Hilfsmethode zur Erstellung des Modell-Inputs
def prepare_conversation(user_prompt):
# Llama-3.1-Storm-8B chat template
dialog = (
{"position": "system", "content material": "You're a useful assistant."},
{"position": "person", "content material": user_prompt}
)
return dialog4. Schritt: Ausgabe erhalten
# Consumer question
user_prompt = "What's the capital of Spain?"
dialog = prepare_conversation(user_prompt)
outputs = pipeline(dialog, max_new_tokens=128, do_sample=True, temperature=0.01, top_k=100, top_p=0.95)
response = outputs(0)('generated_text')(-1)('content material')
print(f"Llama-3.1-Storm-8B Output: {response}")
Methode 2: Verwenden der APIs „Mannequin“, „Tokenizer“ und „mannequin.generate“
1. Platz Schritt: Llama 3.1 Storm 8B-Modell und Tokenizer laden
import torch
from transformers import AutoTokenizer, LlamaForCausalLM
model_id = 'akjindal53244/Llama-3.1-Storm-8B'
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
mannequin = LlamaForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
load_in_8bit=False,
load_in_4bit=False,
use_flash_attention_2=False # Colab Free T4 GPU is an outdated era GPU and doesn't assist FlashAttention. Allow if utilizing Ampere GPUs or newer corresponding to RTX3090, RTX4090, A100, and so forth.
)2. Schritt: Llama-3.1-Storm-8B Chat-Vorlage anwenden
def format_prompt(user_query):
template = """<|begin_of_text|><|start_header_id|>system<|end_header_id|>nnYou are a useful assistant.<|eot_id|><|start_header_id|>person<|end_header_id|>nn{}<|eot_id|><|start_header_id|>assistant<|end_header_id|>nn"""
return template.format(user_query)3. Platz Schritt: Holen Sie sich die Ausgabe vom Modell
# Construct last enter immediate after making use of chat-template
immediate = format_prompt("What's the capital of France?")
input_ids = tokenizer(immediate, return_tensors="pt").input_ids.to("cuda")
generated_ids = mannequin.generate(input_ids, max_new_tokens=128, temperature=0.01, do_sample=True, eos_token_id=tokenizer.eos_token_id)
response = tokenizer.decode(generated_ids(0)(input_ids.form(-1):), skip_special_tokens=True)
print(f"Llama-3.1-Storm-8B Output: {response}")
Abschluss
Llama 3.1 Storm 8B stellt einen bedeutenden Fortschritt bei der Entwicklung effizienter und leistungsstarker Sprachmodelle dar. Es zeigt, dass kleinere Modelle durch modern Trainings- und Zusammenführungstechniken eine beeindruckende Leistung erzielen können, was neue Möglichkeiten für die KI-Forschung und Anwendungsentwicklung eröffnet. Da sich das Feld weiterentwickelt, erwarten wir weitere Verfeinerungen und Anwendungen dieser Techniken, die möglicherweise den Zugang zu erweiterten KI-Funktionen demokratisieren.
Tauchen Sie mit GenAI Pinnacle in die Zukunft der KI ein. Stärken Sie Ihre Projekte mit modernsten Funktionen, vom Coaching maßgeschneiderter Modelle bis hin zur Bewältigung realer Herausforderungen wie der PII-Maskierung. Entdecken Sie.
Häufig gestellte Fragen
Antwort: Llama 3.1 Storm 8B ist ein verbessertes kleines Sprachmodell (SLM) mit 8 Milliarden Parametern, das auf dem Llama 3.1 8B Instruct-Modell von Meta AI basiert und Selbstkuratierung, gezielte Feinabstimmung und Modellzusammenführungstechniken verwendet.
Antwort: Es übertrifft sowohl Meta’s Llama 3.1 8B Instruct als auch Hermes-3-Llama-3.1-8B in verschiedenen Benchmarks und zeigt erhebliche Verbesserungen in Bereichen wie Befolgen von Anweisungen, wissensbasierte Qualitätssicherung, Argumentation und Funktionsaufruf.
Antwort: Das Modell wurde in einem dreistufigen Prozess erstellt: Selbstkuratierung der Trainingsdaten, gezielte Feinabstimmung mit der Spectrum-Methode und Modellzusammenführung mit Llama-Spark unter Verwendung der SLERP-Technik.
Antwort: Entwickler können das Modell mithilfe beliebter Bibliotheken wie Transformers und vLLM problemlos in ihre Projekte integrieren. Es ist in mehreren Formaten (BF16, FP8, GGUF) verfügbar und kann für verschiedene Aufgaben verwendet werden, darunter Konversations-KI und Funktionsaufrufe.