
Vor ein paar Tagen veröffentlichte eine Gruppe von Forschern bei Google ein PDF, das nicht nur die KI veränderte: Es hat Milliarden von Greenback vom Aktienmarkt vernichtet.
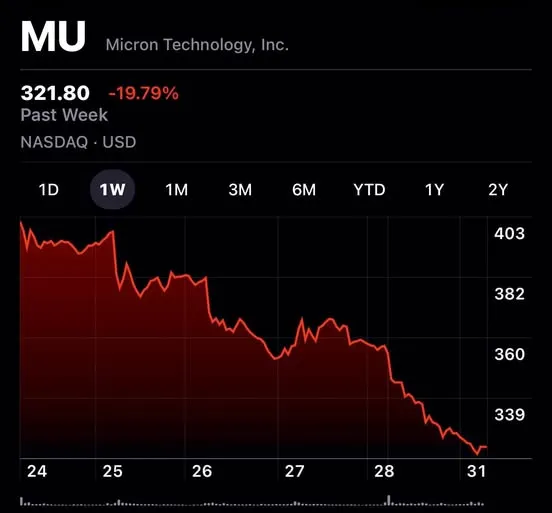
Wenn Sie sich die Diagramme angesehen haben Mikron (MU) oder Western Digital Letzte Woche hast du ein Meer von gesehen Rot. Warum? Denn eine neue Technologie rief TurboQuant hat gerade bewiesen, dass wir möglicherweise nicht annähernd so viel {Hardware} benötigen, um riesige KI-Modelle auszuführen, wie wir dachten.
Aber machen Sie sich keine Sorgen wegen der komplexen Mathematik. Hier ist die einfache Aufschlüsselung von Googles neuester Schlüsselwert-Cache-Optimierungstechnik TurboQuant.
Wir stellen eine Reihe fortschrittlicher, theoretisch fundierter Quantisierungsalgorithmen vor, die eine huge Komprimierung für große Sprachmodelle und Vektorsuchmaschinen ermöglichen. – Offizielle Versionshinweise von Google
Die Speicherbeschränkung
Stellen Sie sich ein KI-Modell wie eine riesige Bibliothek vor. Normalerweise wird jedes „Buch“ (Datenpunkt) in hochauflösenden 4K-Particulars geschrieben. Dies nimmt enorm viel Platz im Regal ein (was Technikfreaks nennen). VRAM oder Erinnerung).
Je mehr KI mit Ihnen „spricht“, desto mehr Platz benötigt sie, um sich daran zu erinnern, was vor zehn Minuten passiert ist. Aus diesem Grund ist KI-{Hardware} so teuer. Unternehmen mögen Mikron Machen Sie ein Vermögen, weil KI-Modelle praktisch „Speicherfresser“ sind.
Die Sprache der KI: Vektoren
Um zu verstehen, warum diese Bücher so schwer sind, muss man sich die „Tinte“ ansehen, die in diesen Büchern verwendet wird. KI sieht weder Worte noch Bilder: Sie sieht Vektoren.
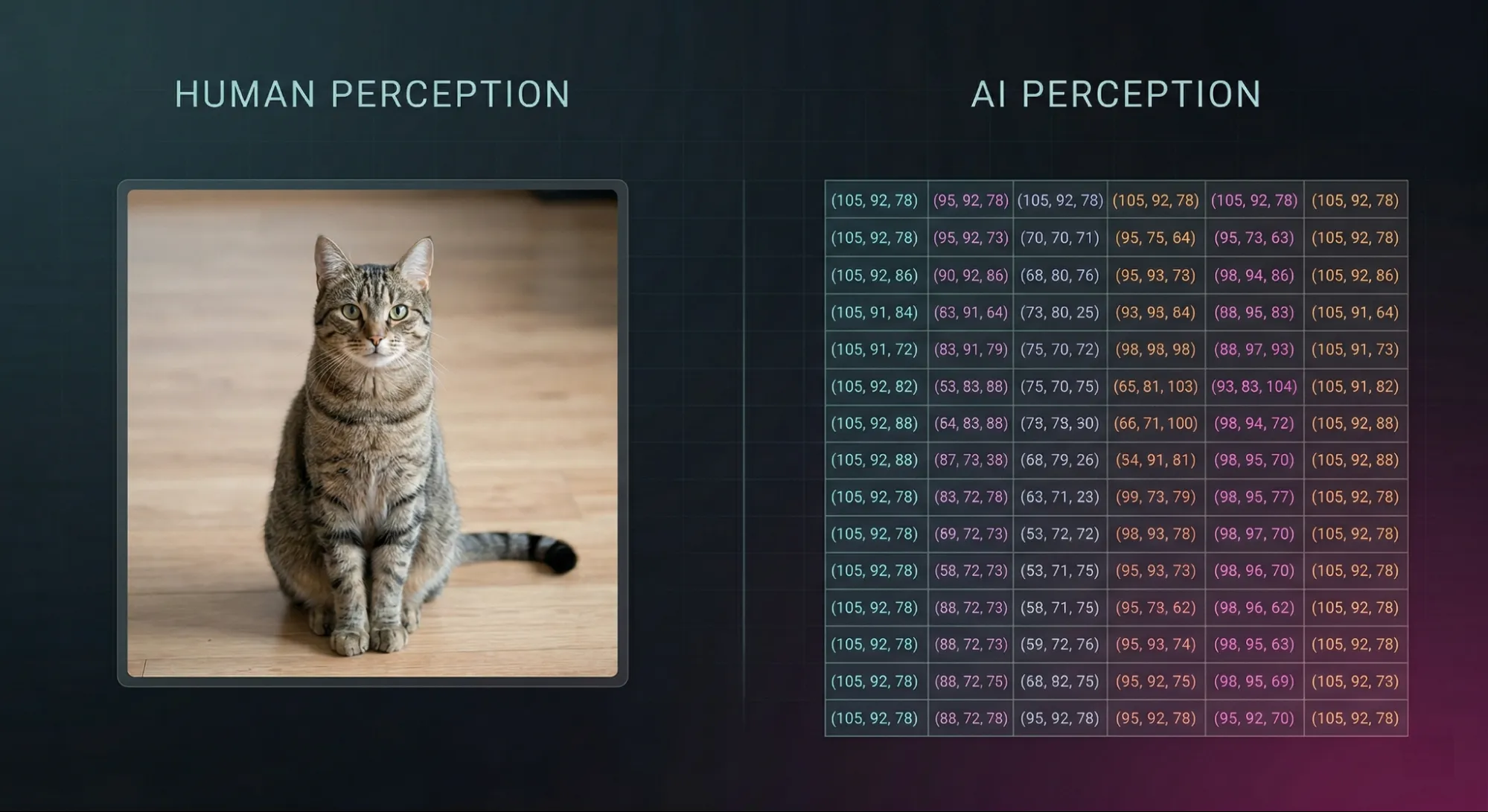
Ein Vektor ist im Wesentlichen ein Satz von Koordinaten, eine Folge präziser Zahlen wie 0,872632, die der KI genau sagen, wo sich eine Info auf einer riesigen, mehrdimensionalen Karte befindet.
- Einfache Vektoren könnte einen einzelnen Punkt in einem Diagramm beschreiben.
- Hochdimensionale Vektoren Erfassen Sie komplexe Bedeutungen, wie die spezifische „Stimmung“ eines Satzes oder die Merkmale eines menschlichen Gesichts.
Hochdimensionale Vektoren sind sehr effektiv, erfordern jedoch beim Erstellen viel Speicher Engpässe im Schlüsselwert-Cache. In Transformatormodellen speichert der KV-Cache die Schlüssel- und Wertvektoren früherer Token, sodass das Modell die Aufmerksamkeit nicht jedes Mal von Grund auf neu berechnen muss.
Die Lösung: Vektorquantisierung
Um das Aufblähen des Gedächtnisses zu bekämpfen, verwenden Ingenieure einen Schachzug namens Vektorquantisierung. Wenn die Koordinaten zu lang sind, „rasieren“ wir die Enden einfach ab, um Platz zu sparen.
Stellen Sie sich vor, Sie haben eine Liste n-dimensionaler Vektoren:
- 0,872632982
- 0,192934356
- 0,445821930
Das sind viele Daten, die gespeichert werden müssen. Um Platz zu sparen, „quantisieren“ wir sie, indem wir die Enden abschneiden:
- 0,872632982 → 0,87
- 0,192934356 → 0,19
- 0,445821930 → 0,44
* Bei der gezeigten Rundung handelt es sich um eine Skalierungsrundung. In der Praxis werden Vektoren gruppiert und einem kleineren Satz repräsentativer Werte zugeordnet, nicht nur einzeln gerundet.
Dies führt zu einer Verringerung der Koeffizientenpräzision bzw. zum Shaving. Dies kann mithilfe von Methoden wie Runden auf n Stellen, adaptiver Schwellenwertbildung, kalibrierter Vorhersageschwellenwertbildung und Least Vital Bit (LSB) erfolgen.
Dieser Optimierungsschritt hat zwei Vorteile:
- Erweiterte Vektorsuche: Es unterstützt große KI, indem es schnelle Ähnlichkeitssuchen ermöglicht und Suchmaschinen und Abrufsysteme erstellt deutlich Schneller.
- Nicht verstopft KV-Cache Engpässe: Durch die Reduzierung der Größe von Schlüssel-Wert-Paaren werden die Speicherkosten gesenkt und die Ähnlichkeitssuche im Cache beschleunigt, was für die Skalierung der Modellleistung von entscheidender Bedeutung ist.
Wenn die Vektorquantisierung fehlschlägt?
Dieser Prozess hat versteckte Kosten: Quantisierungskonstanten mit voller Genauigkeit (a Skala und a Nullpunkt) muss für jeden Block gespeichert werden. Dieser Speicher ist unerlässlich, damit die KI die Daten später „unshave“ oder dequantisieren kann. Dies fügt hinzu 1 oder 2 zusätzliche Bits professional Zahlwas bis zu 50 % Ihrer geplanten Ersparnisse verschlingen kann. Da jeder Block seine eigene Skalierung und seinen eigenen Offset benötigt, speichern Sie nicht nur Daten, sondern auch die Anweisungen zu deren Dekodierung.
Die Lösung reduziert den Speicher auf Kosten der Genauigkeit. TurboQuant ändert diesen Kompromiss.
TurboQuant: Komprimierung ohne Einschränkungen
TurboQuant von Google ist eine Komprimierungsmethode, die durch grundlegende Änderungen eine hohe Reduzierung der Modellgröße bei geringem Genauigkeitsverlust erreicht wie die KI den Vektorraum wahrnimmt. Anstatt nur Zahlen abzuschreiben und auf das Beste zu hoffen, nutzt es eine zweistufige mathematische Pipeline, um alle Daten perfekt in ein hocheffizientes Raster einzupassen.
Stufe 1: Die zufällige Rotation (PolarQuant)
Die Standardquantisierung schlägt fehl, weil reale Daten chaotisch und unvorhersehbar sind. Um die Genauigkeit zu gewährleisten, müssen Sie für jeden Datenblock „Skalen“- und „Nullpunkt“-Anweisungen speichern.
TurboQuant löst dieses Downside, indem es zunächst a anwendet zufällige Rotation (oder zufällige Vorkonditionierung) auf die Eingabevektoren. Diese Rotation zwingt die Daten in eine vorhersehbare, konzentrierte Verteilung (insbesondere Polarkoordinaten), unabhängig davon, wie die Originaldaten aussahen. Eine zufällige Rotation verteilt die Informationen gleichmäßig über die Dimensionen, glättet Spitzen und sorgt dafür, dass sich die Daten gleichmäßiger verhalten.
- Der Vorteil: Da die Verteilung jetzt mathematisch „flach“ und vorhersehbar ist, kann die KI jede Koordinate optimum runden, ohne diese zusätzlichen „Skalen- und Null“-Konstanten speichern zu müssen.
- Das Ergebnis: Sie umgehen den Normalisierungsschritt vollständig und erzielen enorme Speichereinsparungen ohne Overhead.
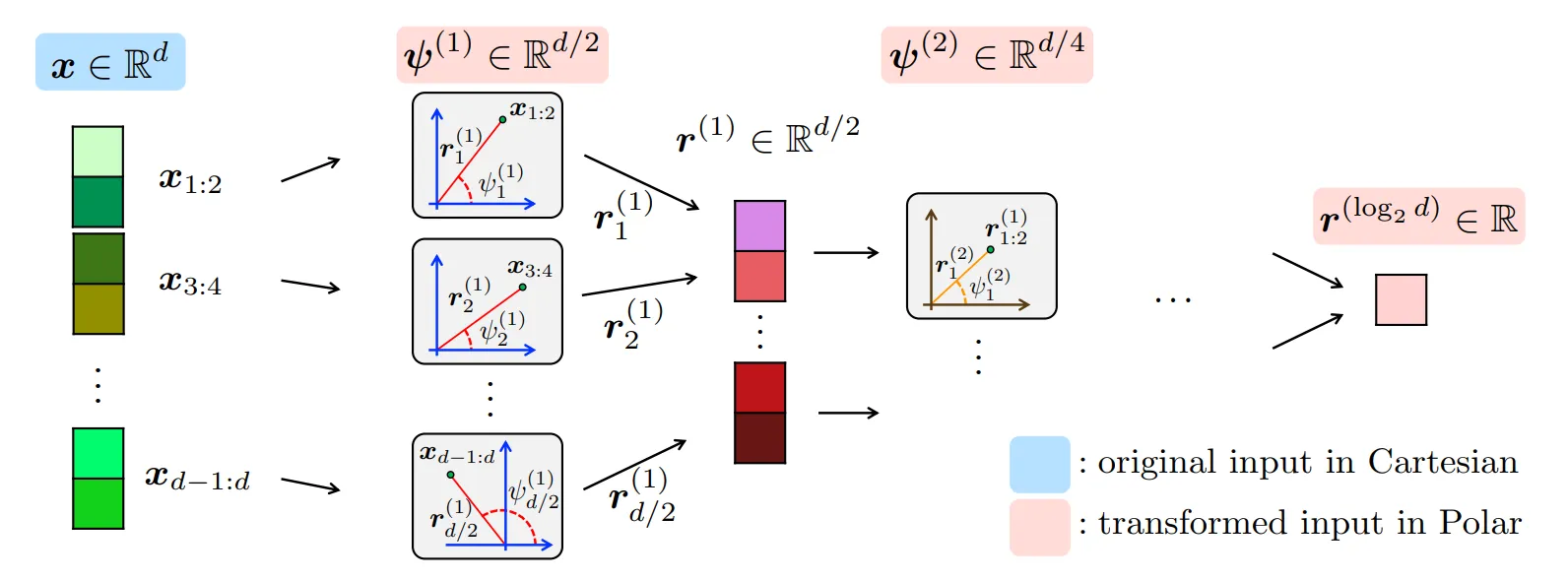
Weitere Informationen zur PolarQuant-Methode finden Sie unter: arXiv
Stufe 2: Der 1-Bit-„Relaxation“-Repair (quantisierte JL)
Auch bei perfekter Drehung führt einfaches Runden ein Voreingenommenheit. Winzige mathematische Fehler, die in eine Richtung tendieren. Mit der Zeit häufen sich diese Fehler, was dazu führt, dass die KI ihren „Gedankengang“ verliert oder halluziniert. TurboQuant behebt dieses Downside mit Quantisierter Johnson-Lindenstrauss (QJL).
- Der Relaxation: Es isoliert den „übrig gebliebenen“ Fehler (das Residuum), der während der ersten Rundungsstufe verloren ging.
- Das 1-Bit-Zeichen: Es quantisiert diesen Fehler auf ein einzelnes Bit (auch das Vorzeichenbit). +1 oder -1).
- Die Mathematik: Diese 1-Bit-Prüfung dient als „unvoreingenommener Schätzer“, was bedeutet, dass bei vielen Operationen die winzigen Richtungshinweise (1-Bit-Vorzeichen) die Verzerrung statistisch aufheben.
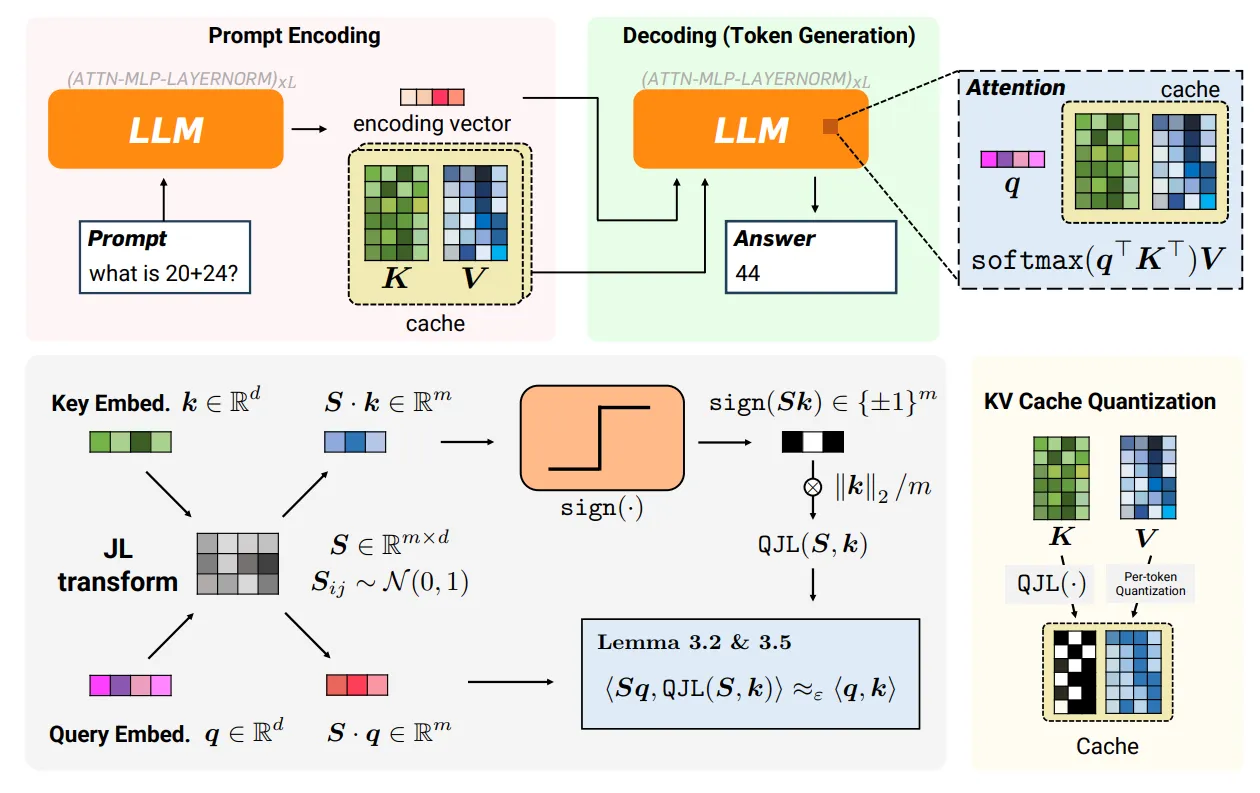
Weitere Informationen zur QJL-Methode finden Sie unter: arXiv
PolarQuant und QJL werden in TurboQuant verwendet, um Schlüsselwertengpässe zu reduzieren, ohne die Leistung des KI-Modells zu beeinträchtigen.
| Verfahren | Erinnerung | Genauigkeit | Overhead |
| Commonplace-KV-Cache | Hoch | Perfekt | Keiner |
| Quantisierung | Untere | Leichter Verlust | Hoch (Metadaten) |
| TurboQuant | Viel niedriger | Nahezu perfekt | Minimal |
Die Leistungsrealität
Durch die Abschaffung der Metadatensteuer und die Korrektur der Rundungsverzerrung liefert TurboQuant das „Beste aus beiden Welten“-Ergebnis für Hochgeschwindigkeits-KI-Systeme:
- Qualitätsneutralität: Beim Testen mit Modellen wie Lama-3.1TurboQuant erreichte exakt die gleiche Leistung wie das Full-Precision-Modell, während der Speicher um den Faktor komprimiert wurde 4x bis 5x.
- Sofortsuche: Bei der Suche nach dem nächsten Nachbarn übertrifft es vorhandene Techniken und reduziert gleichzeitig die „Indizierungszeit“ (die Zeit, die zum Vorbereiten der Daten benötigt wird). praktisch Null.
- Hardwarefreundlich: Der gesamte Algorithmus ist auf Vektorisierung ausgelegt und kann daher parallel auf modernen GPUs mit geringem Platzbedarf ausgeführt werden.
Die Realität: Jenseits der Forschungsarbeit
Die wahre Wirkung von TurboQuant wird nicht nur an Zitaten gemessen, sondern auch daran, wie es die Weltwirtschaft und die physische {Hardware} in unseren Taschen verändert.
1. Die „Reminiscence Wall“ durchbrechen
Die „Reminiscence Wall“ battle jahrelang die größte Bedrohung für den KI-Fortschritt. Als die Modelle wuchsen, benötigten sie eine enorme Menge an RAM und Speicher, was KI-{Hardware} unerschwinglich teuer machte und leistungsstarke Modelle in der Cloud festhielt.
Als TurboQuant vorgestellt wurde, änderte es diese Mathematik grundlegend:
- Der Halbleiterwandel: Die Ankündigung der TurboQuant-Optimierung löste Schockwellen in der Speicherbranche aus. KI kann plötzlich werden 6x speichereffizienterwird die hektische Nachfrage nach physischem RAM nachlassen.
- Von der Cloud zum Verbraucher: Durch die Verkleinerung des „digitalen Spickzettels“ der KI (der KV-Cache) auf nur 3 Bit professional Wert reduziert, hat TurboQuant den {Hardware}-Engpass effektiv „beseitigt“. Dies verlagerte hochentwickelte KI von riesigen Serverfarmen nach 16-GB-Verbrauchergeräte wie der Mac Mini, der die lokale und personal Ausführung leistungsstarker LLMs ermöglicht.
2. Ein neuer Commonplace für den globalen Maßstab
TurboQuant hat bewiesen, dass die Zukunft der KI nicht nur im Bauen liegt größer Bibliotheken, sondern darum, eine effizientere „Tinte“ zu erfinden.
- Die „unsichtbare“ Infrastruktur: Im Gegensatz zu früheren Forschungen, die eine komplexe Umschulung erforderten, wurde TurboQuant darauf ausgelegt Datenvergessen. Es könnte in jedes vorhandene Transformatormodell eingefügt werden (z Google Gemini), um Kosten und Energieverbrauch sofort zu senken.
- Demokratisierung des Geheimdienstes: Diese Effizienz bildete die Brücke für die Skalierung der KI auf die neuen Benutzer. In Cell-First-Märkten wurde der Traum eines voll funktionsfähigen KI-Assistenten auf dem Gerät in eine batteriefreundliche Realität verwandelt. Ihr nächstes Telefon könnte lokal KI auf GPT-Ebene ausführen!
Letztendlich markiert TurboQuant den Second, in dem die KI-Effizienz genauso wichtig wurde wie die reine Rechenleistung. Es handelt sich nicht mehr nur um eine „Wertungsliste“. Es ist das unsichtbare Gerüst, das es der nächsten Technology semantischer Suche und autonomer Agenten ermöglicht, auf globaler, menschlicher Ebene zu funktionieren.
TurboQuant: Zukunftsausblick
Jahrelang bedeutete die Skalierung der KI, das Downside mit mehr {Hardware} zu lösen: mehr GPUs, mehr Speicher, mehr Kosten. TurboQuant stellt diesen Glauben in Frage.
Anstatt sich nach außen auszudehnen, konzentriert es sich darauf, das, was wir bereits haben, intelligenter zu nutzen. Durch die Reduzierung der Speicherlast ohne große Einbußen bei der Leistung ändert sich unsere Einstellung zum Erstellen und Ausführen großer Modelle.
Häufig gestellte Fragen
A. TurboQuant ist eine KI-Speicheroptimierungstechnik, die die RAM-Nutzung durch Komprimieren von KV-Cache-Daten mit minimalen Auswirkungen auf die Leistung reduziert.
A. Es nutzt zufällige Rotation und effiziente Quantisierung, um Vektoren zu komprimieren, wodurch zusätzliche Metadaten eliminiert und der für KI-Modelle benötigte Speicher reduziert wird.
A: Nicht ganz, aber es senkt den Speicherbedarf erheblich, wodurch große Modelle effizienter und einfacher auf kleinerer {Hardware} ausgeführt werden können.
Ich bin auf die Überprüfung und Verfeinerung von KI-gestützter Forschung, technischer Dokumentation und Inhalten im Zusammenhang mit neuen KI-Technologien spezialisiert. Meine Erfahrung umfasst KI-Modelltraining, Datenanalyse und Informationsabruf und ermöglicht es mir, Inhalte zu erstellen, die sowohl technisch korrekt als auch zugänglich sind.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.