
In den letzten Jahren battle Immediate Engineering der heimliche Händedruck der KI-Welt. Die richtige Formulierung könnte ein Modell poetisch, lustig oder aufschlussreich klingen lassen; Der Falsche hat es flach und roboterhaft gemacht. Aber ein neues von Stanford geleitetes Papier argumentiert, dass der größte Teil dieser „Handlung“ etwas Tiefgründigeres kompensierte, eine versteckte Voreingenommenheit in der Artwork und Weise, wie wir diese Systeme trainierten.
Ihr Anspruch ist einfach: Die Fashions waren nie langweilig. Sie wurden darauf trainiert, sich so zu verhalten.
Und die vorgeschlagene Lösung heißt Verbalisierte Probenahmekönnte nicht nur die Artwork und Weise ändern, wie wir Modelle auffordern; Es könnte unsere Denkweise über Ausrichtung und Kreativität in der KI neu definieren.
Das Kernproblem: Ausrichtung machte KI vorhersehbar
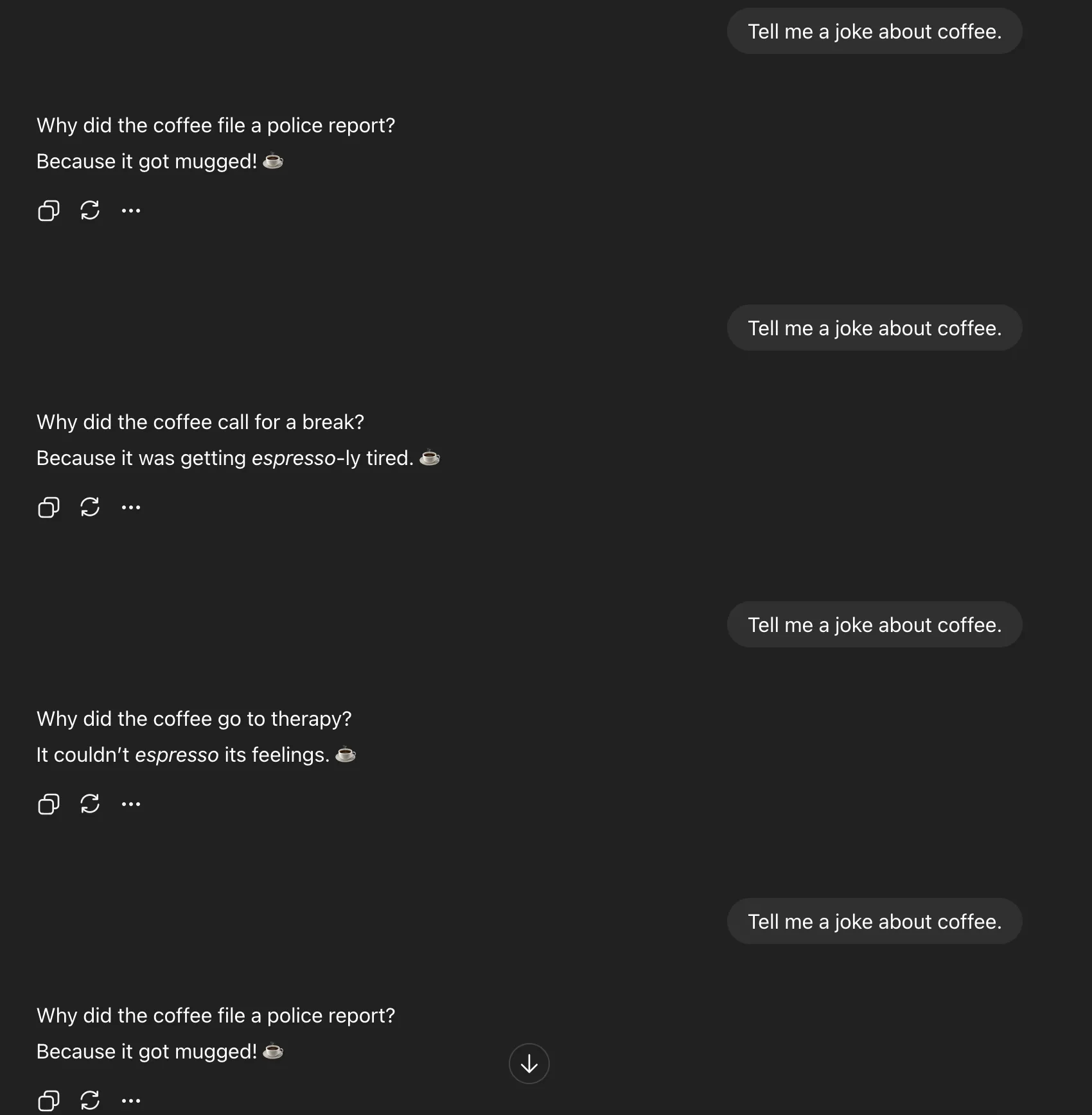
Um den Durchbruch zu verstehen, beginnen Sie mit einem einfachen Experiment. Bitten Sie ein KI-Modell um „c“. Machen Sie es fünfmal. Sie erhalten quick immer die gleiche Antwort:

Das ist keine Faulheit; es ist Moduszusammenbrucheine Einengung der Ausgabeverteilung des Modells nach dem Ausrichtungstraining. Anstatt alle gültigen Antworten zu untersuchen, die es hervorbringen könnte, orientiert sich das Modell an der sichersten und typischsten Antwort.
Das Stanford-Workforce hat dies darauf zurückgeführt Typizitätsfehler in den menschlichen Feedbackdaten, die beim Reinforcement Studying verwendet werden. Wenn Annotatoren Modellantworten beurteilen, bevorzugen sie stets Textual content, der ihnen bekannt vorkommt. Mit der Zeit lernen Belohnungsmodelle, die auf diese Präferenz trainiert werden, zu belohnen Normalität anstatt Neuheit.
Mathematisch gesehen fügt diese Verzerrung der Belohnungsfunktion ein „Typizitätsgewicht“ (α) hinzu und verstärkt so alles, was statistisch gesehen am durchschnittlichsten aussieht. Es ist ein langsamer Druck auf die Kreativität und der Grund dafür, dass die meisten abgestimmten Modelle gleich klingen.
Die Wendung: Die Kreativität ging nie verloren
Hier ist der Clou: Die Vielfalt ist nicht verschwunden. Es ist begraben.
Wenn Sie nach einer einzigen Antwort fragen, zwingen Sie das Modell, die wahrscheinlichste Vervollständigung auszuwählen. Aber wenn Sie es darum bitten Verbalisieren Sie mehrere Antworten zusammen mit ihren Wahrscheinlichkeitenöffnet es plötzlich seine interne Verbreitung, die Bandbreite der Ideen, die es tatsächlich „kennt“.
Das ist Verbalisierte Probenahme (VS) in Aktion.
Anstatt:
Erzähl mir einen Witz über Kaffee
Sie fragen:
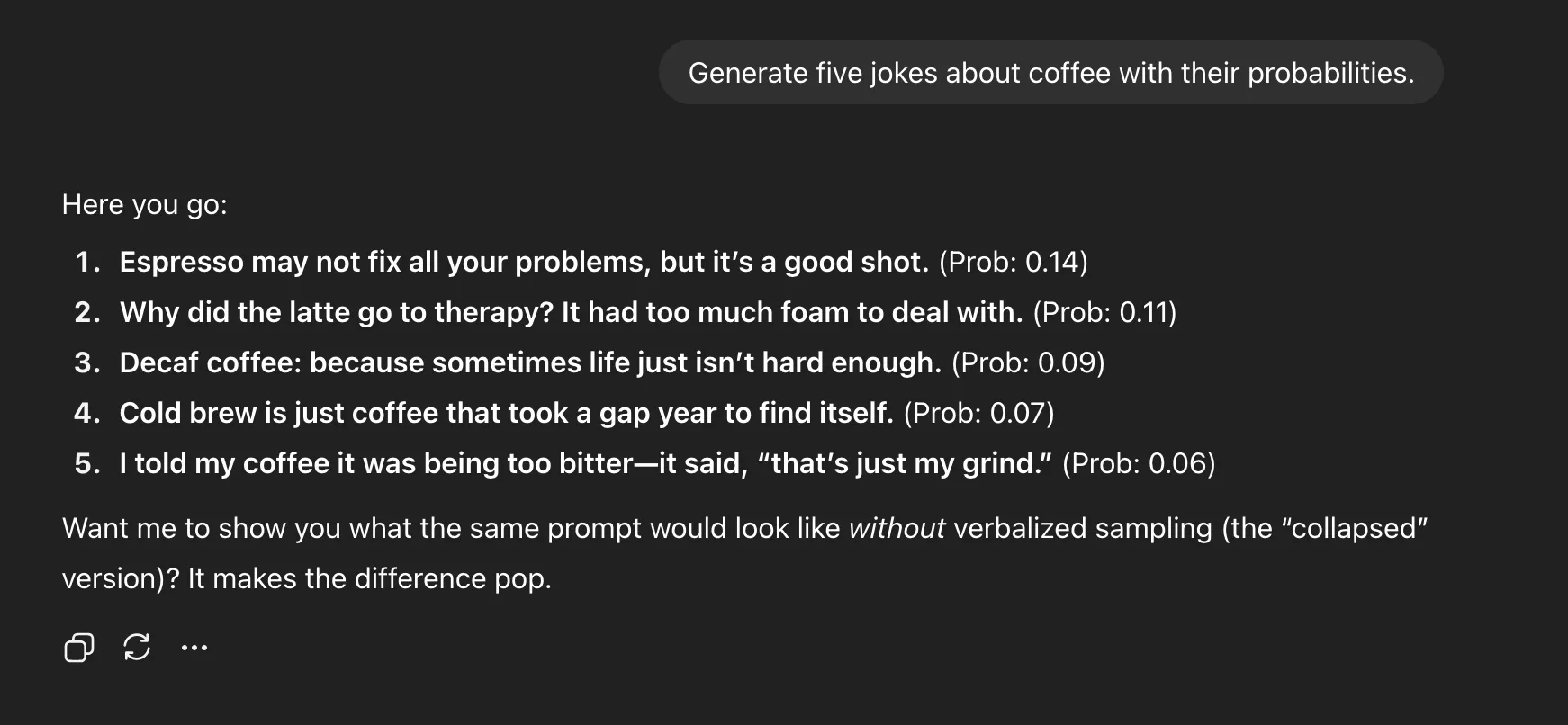
Ermitteln Sie fünf Witze zum Thema Kaffee mit ihren Wahrscheinlichkeiten
Diese kleine Änderung erschließt die Vielfalt, die durch das Ausrichtungstraining komprimiert wurde. Sie trainieren das Modell nicht neu, ändern die Temperatur oder hacken die Probenparameter. Sie geben lediglich eine andere Aufforderung – Sie fordern das Modell auf, seine Unsicherheit zu zeigen, anstatt sie zu verbergen.
Die Kaffeeaufforderung: Beweis in Aktion
Um dies zu demonstrieren, führten die Forscher die gleiche Kaffeewitz-Eingabeaufforderung durch, wobei sie sowohl traditionelle Eingabeaufforderungen als auch verbalisierte Stichproben verwendeten.
Direkte Aufforderung
Verbalisierte Probenahme
Warum es funktioniert
Während der Generierung tastet ein Sprachmodell intern Token aus einer Wahrscheinlichkeitsverteilung ab, wir sehen jedoch normalerweise nur die erste Wahl. Wenn Sie es auffordern, mehrere Kandidaten mit angehängten Wahrscheinlichkeiten auszugeben, lassen Sie es explizit über seine eigene Unsicherheit nachdenken.
Diese „Selbstverbalisierung“ legt die zugrunde liegende Vielfalt des Modells offen. Anstatt auf einen einzigen Modus mit hoher Wahrscheinlichkeit zu reduzieren, werden Ihnen mehrere believable Modi angezeigt.
In der Praxis bedeutet das, dass „Erzähl mir einen Witz“ zu einem Überfall-Wortspiel führt, während „Generiere fünf Witze mit Wahrscheinlichkeiten“ Espresso-Wortspiele, Therapiewitze, Chilly-Brew-Zeilen und mehr hervorbringt. Es geht nicht nur um Vielfalt, sondern um Interpretierbarkeit. Sie können sehen, was das Modell ist denkt könnte funktionieren.
Die Daten und die Gewinne
Über mehrere Benchmarks, kreatives Schreiben, Dialogsimulation und offene Qualitätssicherung hinweg waren die Ergebnisse konsistent:
- 1,6- bis 2,1-fache Steigerung der Vielfalt bei kreativen Schreibaufgaben
- 66,8 % Wiederherstellung der Diversität vor der Ausrichtung
- Kein Rückgang der sachlichen Richtigkeit oder Sicherheit (Ablehnungsraten über 97 %)
Größere Modelle profitierten noch mehr. Systeme der GPT-4-Klasse zeigten im Vergleich zu kleineren Systemen eine doppelt so hohe Diversitätsverbesserung, was darauf hindeutet, dass große Modelle über eine tiefe latente Kreativität verfügen, die darauf wartet, genutzt zu werden.
Die Voreingenommenheit dahinter
Um zu bestätigen, dass Typizitätsverzerrungen tatsächlich den Moduskollaps vorantreiben, analysierten die Forscher quick siebentausend Antwortpaare aus dem HelpSteer-Datensatz. Menschliche Annotatoren bevorzugten etwa 17–19 % häufiger „typische“ Antworten, selbst wenn beide gleichermaßen richtig waren.
Sie modellierten dies als:
r(x, y) = r_true(x, y) + α log π_ref(y | x)
Dieser α-Time period ist das Gewicht der Typizitätsverzerrung. Mit zunehmendem α wird die Verteilung des Modells schärfer und verschiebt es in Richtung Mitte. Mit der Zeit werden die Reaktionen dadurch sicherer, vorhersehbarer und sich wiederholender.
Was bedeutet das für Immediate Engineering??
Ist Immediate Engineering additionally tot? Nicht ganz. Aber es entwickelt sich weiter.
Verbalized Sampling macht eine durchdachte Aufforderung nicht überflüssig – es ändert, wie geschickte Aufforderung aussieht. Bei dem neuen Spiel geht es nicht darum, ein Modell zur Kreativität zu verleiten; es geht darum Entwerfen von Meta-Eingabeaufforderungen das seinen vollen Wahrscheinlichkeitsraum offenlegt.
Sie können es sogar als „Kreativitätsrad“ betrachten. Legen Sie einen Wahrscheinlichkeitsschwellenwert fest, um zu steuern, wie wild oder sicher die Antworten sein sollen. Senken Sie es für mehr Überraschung, heben Sie es für Stabilität an.
Die wahren Implikationen
Bei der größten Veränderung geht es hier nicht um Witze oder Geschichten. Es geht darum, die Ausrichtung selbst neu zu definieren.
Seit Jahren sind wir davon überzeugt, dass die Ausrichtung Modelle sicherer, aber langweiliger macht. Diese Forschung legt etwas anderes nahe: Die Ausrichtung hat sie geschaffen zu höflich, nicht gebrochen. Indem wir anders anregen, können wir unsere Kreativität zurückgewinnen, ohne die Modellgewichte zu berühren.
Das hat Konsequenzen, die weit über kreatives Schreiben hinausgehen – von realistischeren sozialen Simulationen bis hin zu umfangreicheren synthetischen Daten für das Modelltraining. Es deutet auf eine neue Artwork von KI-System hin: eines, das seine eigene Ungewissheit analysieren und mehrere believable Antworten anbieten kann, anstatt so zu tun, als gäbe es nur eine.
Die Vorbehalte
Nicht jeder kauft den Hype ab. Kritiker weisen darauf hin, dass dies bei einigen Modellen der Fall sein könnte halluzinieren Wahrscheinlichkeitswerte statt die wahren Wahrscheinlichkeiten widerzuspiegeln. Andere argumentieren, dass dies die zugrunde liegende menschliche Voreingenommenheit nicht behebt, sondern lediglich umgeht.
Und während die Ergebnisse in kontrollierten Exams überzeugend aussehen, bringt der reale Einsatz Kompromisse in Bezug auf Kosten, Latenz und Interpretierbarkeit mit sich. Wie es ein Forscher trocken auf X ausdrückte: „Wenn es perfekt funktionieren würde, würde OpenAI es bereits tun.“
Dennoch fällt es schwer, die Eleganz nicht zu bewundern. Keine Umschulung, keine neuen Daten, nur eine überarbeitete Anleitung:
Generieren Sie fünf Antworten mit ihren Wahrscheinlichkeiten.
Abschluss
Die Lehre aus Stanfords Arbeit ist größer als jede einzelne Technik. Die von uns gebauten Modelle waren nie einfallslos; Sie waren übermäßig ausgerichtet und darauf trainiert, die Vielfalt zu unterdrücken, die sie mächtig machte.
Verbalized Sampling schreibt sie nicht neu; es gibt ihnen einfach die Schlüssel zurück.
Wenn Pretraining eine riesige interne Bibliothek aufgebaut hat, hat die Ausrichtung die meisten Türen verschlossen. Mit VS fangen wir an, danach zu fragen, alle fünf Versionen der Wahrheit zu sehen.
Immediate Engineering ist nicht tot. Es wird endlich eine Wissenschaft.
Häufig gestellte Fragen
A. Verbalized Sampling ist eine Eingabeaufforderungsmethode, die KI-Modelle auffordert, mehrere Antworten mit ihren Wahrscheinlichkeiten zu generieren und so ihre interne Diversität ohne Umschulung oder Parameteränderungen offenzulegen.
A. Wegen Typizitätsfehler In menschlichen Feedbackdaten lernen Modelle, sichere, vertraute Reaktionen zu bevorzugen, was zum Zusammenbruch des Modus und zum Verlust der kreativen Vielfalt führt.
A. Nein. Es definiert es neu. Die neue Fähigkeit besteht darin, Meta-Eingabeaufforderungen zu erstellen, die Verteilungen offenlegen und die Kreativität steuern, anstatt einzelne Formulierungen zu verfeinern.
Ich bin auf die Überprüfung und Verfeinerung von KI-gestützter Forschung, technischer Dokumentation und Inhalten im Zusammenhang mit neuen KI-Technologien spezialisiert. Meine Erfahrung umfasst KI-Modelltraining, Datenanalyse und Informationsabruf und ermöglicht es mir, Inhalte zu erstellen, die sowohl technisch korrekt als auch zugänglich sind.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.