
Haben Sie sich jemals gefragt, wie Ihr Telefon Sprachbefehle versteht oder das perfekte Wort vorschlägt, auch ohne Internetverbindung? Wir sind mitten in einer großen KI-Verschiebung: von der Cloud-basierten Verarbeitung bis hin zu On-System-Intelligenz. Hier geht es nicht nur um Geschwindigkeit. Es geht auch um Privatsphäre und Zugänglichkeit. Im Zentrum dieser Verschiebung steht das Einbettungsgecken, das neue offene Einbettungsmodell von Google. Es ist kompakt, schnell und entwickelt, um große Datenmengen direkt auf Ihrem Gerät zu verarbeiten.
In diesem Weblog werden wir untersuchen, was Emettdinggeemma ist, wie wichtig es ist, wie sie es verwenden können, und welche Anwendungen es mit Strom versorgt. Lass uns eintauchen!
Was genau ist ein „Einbettungsmodell“?
Bevor wir uns mit den Particulars befassen, lasst uns ein Kernkonzept aufschlüsseln. Wenn wir einen Pc unterrichten, um die Sprache zu verstehen, können wir ihn nicht nur um Wörter ernähren, da Pc nur Zahlen verarbeiten. Hier kommt ein Einbettungsmodell ins Spiel. Es funktioniert wie ein Übersetzer und konvertiert Textual content in eine Reihe von Zahlen (a Vektor) Das erfasst Sinn und Kontext.
Betrachten Sie es als einen Fingerabdruck für Textual content. Je mehr Texten ähnlich sind, desto näher sind ihre Fingerabdrücke in einem mehrdimensionalen Raum. Diese einfache Ideen führt Anwendungen wie semantische Suche (Finden von Bedeutung und nicht nur Schlüsselwörter) und Chatbots, die die relevantesten Antworten abrufen.
Verständnis des Emettdinggeemma
Additionally, was macht aus Einbettungge besonders? Es geht darum, mehr mit weniger zu tun. Das von Google Deepmind erstellte Modell hat gerade 308 Millionen Parameter. Das magazine riesig klingen, aber in der KI -Welt gilt es als leicht. Diese kompakte Größe ist ihre Stärke, sodass sie direkt auf einem Smartphone, einem Laptop computer oder sogar einem kleinen Sensor ausgeführt werden kann, ohne sich auf eine Rechenzentrumsverbindung zu verlassen.
Diese Fähigkeit zu arbeiten On-System ist mehr als nur eine nette Funktion. Es ist eine echte Paradigmenverschiebung.
Schlüsselmerkmale
- Unerreichte Privatsphäre: Ihre Daten bleiben auf Ihrem Gerät. Das Modell verarbeitet alles lokal, sodass Sie sich keine Sorgen über Ihre privaten Fragen oder persönlichen Daten machen müssen, die an die Cloud gesendet werden.
- Offline -Funktionalität: Kein Web? Kein Drawback. Anwendungen, die mit Emettdinggeemma erstellt wurden, können komplexe Aufgaben wie die Suche durch Ihre Notizen oder die Organisation Ihrer Fotos ausführen, auch wenn Sie vollständig offline sind.
- Unglaubliche Geschwindigkeit: Ohne Latenz, die Daten auf einen Server hin und her senden, ist die Antwortzeit sofort.
Und hier ist der coole Teil: Trotz seiner kompakten Größe liefert EmbedingGemma eine modernste Leistung.
- Es verfügt über das höchste Rang für ein offenes mehrsprachiges Texteinbettungsmodell unter 500 m auf dem massiven Textbettverbindungs -Benchmark (MTEB).
- Seine Leistung ist vergleichbar mit oder überschreitet die von Modellen quick doppelt so groß wie sie.
- Dies ist auf sein hocheffizientes Design zurückzuführen, das mit einer Quantisierung mit weniger als 200 MB RAM ausgeführt werden kann und eine Latenz mit geringer Inferenz von Sub-15 ms auf EDGETPU für 256 Eingangs-Token bietet, wodurch es für Echtzeit-Anwendungen geeignet ist.
Lesen Sie auch: Wie wähle ich die richtige Einbettung für Ihr Lappenmodell aus?
Wie ist das Einbettunggeemma entworfen?
Eines der herausragenden Merkmale von EmbedingGemma ist die Repräsentation von Matryoshka Repräsentation (MRL). Dies gibt Entwicklern die Flexibilität, die Ausgangsabmessungen des Modells anhand ihrer Anforderungen anzupassen. Das vollständige Modell erzeugt einen detaillierten 768-dimensionalen Vektor für maximale Qualität, kann jedoch auf 512, 256 oder sogar 128 Dimensionen mit geringer Genauigkeitsverlust reduziert werden. Diese Anpassungsfähigkeit ist besonders für Geräte für ressourcenbezogene Geräte wertvoll und ermöglicht eine schnellere Ähnlichkeitssuche und niedrigere Speicheranforderungen.
Jetzt, da wir verstehen, was Emettdinggeemma mächtig macht, sehen wir es in Aktion.
Einbettung Gemma: Handson
Lassen Sie uns einen Lappen unter Verwendung von Gemma und Langgraph erstellen.
Set 1: Laden Sie den Datensatz herunter
!gdown 1u8ImzhGW2wgIib16Z_wYIaka7sYI_TGKSchritt 2: Laden und Vorverarbeitung der Daten
from pathlib import Path
import json
from langchain.docstore.doc import Doc
# ---- Configure dataset path (replace if wanted) ----
DATA_PATH = Path("./rag_demo_docs052025.jsonl") # similar file title as earlier pocket book
if not DATA_PATH.exists():
increase FileNotFoundError(
f"Anticipated dataset at {DATA_PATH}. "
"Please place the JSONL file right here or replace DATA_PATH."
)
# Load JSONL
raw_docs = ()
with DATA_PATH.open("r", encoding="utf-8") as f:
for line in f:
raw_docs.append(json.masses(line))
# Convert to Doc objects with metadata
paperwork = ()
for i, d in enumerate(raw_docs):
sect = d.get("sectioned_report", {})
textual content = (
f"Difficulty:n{sect.get('Difficulty','')}nn"
f"Impression:n{sect.get('Impression','')}nn"
f"Root Trigger:n{sect.get('Root Trigger','')}nn"
f"Advice:n{sect.get('Advice','')}"
)
paperwork.append(Doc(page_content=textual content))
print(paperwork(0).page_content)
Schritt 3: Erstellen Sie einen Vektor DB
Verwenden Sie die vorverarbeiteten Daten und einbetten Sie Gemma ein, um einen Vektor -DB zu erstellen:
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
persist_dir = "./reports_db"
assortment = "reports_db"
embedder = HuggingFaceEmbeddings(model_name="google/embeddinggemma-300m")
# Construct or rebuild the vector retailer
vectordb = Chroma.from_documents(
paperwork=paperwork,
embedding=embedder,
collection_name=assortment,
collection_metadata={"hnsw:house": "cosine"},
persist_directory=persist_dir
)Schritt 4: Erstellen Sie einen Hybrid -Retriever (Semantic + BM25 Key phrase Retriever)
# Reopen deal with (demonstrates persistence)
vectordb = Chroma(
embedding_function=embedder,
collection_name=assortment,
persist_directory=persist_dir,
)
vectordb._collection.depend()
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain.retrievers import ContextualCompressionRetriever
# Base semantic retriever (cosine sim + threshold)
semantic = vectordb.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"ok": 5, "score_threshold": 0.2},
)
# BM25 key phrase retriever
bm25 = BM25Retriever.from_documents(paperwork)
bm25.ok = 3
# Ensemble (hybrid)
hybrid_retriever = EnsembleRetriever(
retrievers=(bm25, semantic),
weights=(0.6, 0.4),
ok=5
)
# Fast check
hybrid_retriever.invoke("What are the key points in finance approval workflows?")(:3)
Schritt 5: Knoten erstellen
Erstellen wir nun zwei Knoten – einen zum Abrufen und die andere für die Era:
Definieren von Langgraph State
from typing import Listing, TypedDict, Annotated
from langgraph.graph import StateGraph, START, END
from langchain.docstore.doc import Doc as LCDocument
# We maintain overwrite semantics for all keys (no reducers wanted for appends right here).
class RAGState(TypedDict):
query: str
retrieved_docs: Listing(LCDocument)
reply: strKnoten 1: Abruf
def retrieve_node(state: RAGState) -> RAGState:
question = state("query")
docs = hybrid_retriever.invoke(question) # returns listing(Doc)
return {"retrieved_docs": docs}Knoten 2: Era
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
PROMPT = ChatPromptTemplate.from_template(
"""You might be an assistant for Analyzing inner experiences for Operational Insights.
Use the next items of retrieved context to reply the query.
If you do not know the reply or there is no such thing as a related context, simply say that you do not know.
give a well-structured and to the purpose reply utilizing the context info.
Query:
{query}
Context:
{context}
"""
)
def _format_docs(docs: Listing(LCDocument)) -> str:
return "nn".be part of(d.page_content for d in docs) if docs else ""
def generate_node(state: RAGState) -> RAGState:
query = state("query")
docs = state.get("retrieved_docs", ())
context = _format_docs(docs)
immediate = PROMPT.format(query=query, context=context)
resp = llm.invoke(immediate)
return {"reply": resp.content material}
Construct the Graph and Edges
builder = StateGraph(RAGState)
builder.add_node("retrieve", retrieve_node)
builder.add_node("generate", generate_node)
builder.add_edge(START, "retrieve")
builder.add_edge("retrieve", "generate")
builder.add_edge("generate", END)
graph = builder.compile()
from IPython.show import Picture, show, display_markdown
show(Picture(graph.get_graph().draw_mermaid_png()))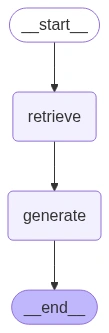
Schritt 6: Führen Sie das Modell aus
Lassen Sie uns nun einige Beispiele für den Lappen machen, den wir gebaut haben:
example_q = "What are the key points in finance approval workflows?"
final_state = graph.invoke({"query": example_q})
display_markdown(final_state("reply"), uncooked=True)
example_q = "What brought on bill SLA breaches within the final quarter?"
final_state = graph.invoke({"query": example_q})
display_markdown(final_state("reply"), uncooked=True)
example_q = "How did AutoFlow Perception enhance SLA adherence?"
final_state = graph.invoke({"query": example_q})
display_markdown(final_state("reply"), uncooked=True)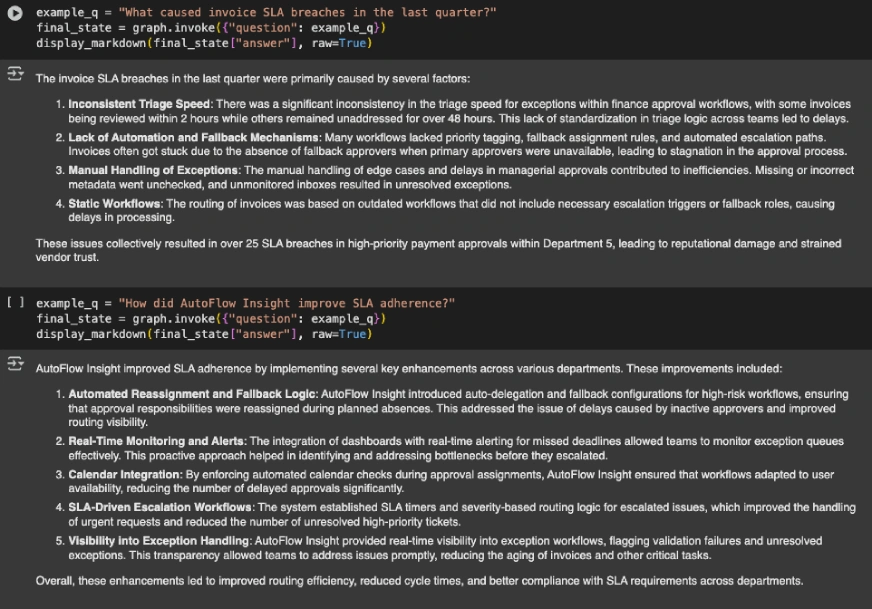
Schauen Sie sich das gesamte Notizbuch an Hier.
Einbetten von Gemma: Leistungsbenchmarks
Jetzt, da wir ein Emettdinggeemma in Aktion gesehen haben, lassen Sie uns schnell sehen, wie es sich gegen seine Kollegen entwickelt. Die folgende Tabelle unterteilt die Unterschiede zwischen allen Prime -Einbettungsmodellen:
- Einbettunggeemma erzielt einen mittleren MTEB -Rating von 61,15, der die meisten Modelle ähnlicher und sogar größerer Größe eindeutig besiegt.
- Das Modell zeichnet sich im Abruf hervor, Klassifizierung mit soliden Clustering.
- Es schlägt größere Modelle wie mehrsprachige E5-Giant (560 m) und BGE-M3 (568 m).
- Das einzige Modell, das seine Punktzahlen schlägt, ist Qwen-Embedding-0,6B, das quick doppelt so groß ist.
Lesen Sie auch: 14 leistungsstarke Techniken, die die Entwicklung der Einbettung definieren
Einbetten von Gemma gegen OpenAi -Einbettungsmodelle
Ein wichtiger Vergleich ist zwischen Einbettungsgemma und OpenAIs Einbettungsmodellen. OpenAI-Einbettungen sind für kleine Projekte im Allgemeinen kostengünstiger, aber für größere, skalierbare Anwendungen hat das Einbettunggeemma den Vorteil. Ein weiterer wichtiger Unterschied ist die Kontextgröße: OpenAI -Einbettungsdings unterstützen bis zu 8K -Token, während die Emettdinggeemma derzeit bis zu 2K -Token unterstützt.
Anwendungen der Einbettungge
Die wahre Kraft des Einbettungsgeckens liegt in der Vielzahl von Anwendungen, die es ermöglicht. Durch die Generierung hochwertiger Texteinbettungen direkt auf dem Gerät führt es eine neue Era von Datenschutz-zentrierten und effizienten KI-Erlebnissen.
Hier sind einige Schlüsselanwendungen:
- LAPPEN: Wie bereits erwähnt, kann Emettdinggeemma verwendet werden, um eine robuste Lappenpipeline zu erstellen, die vollständig offline funktioniert. Sie können einen persönlichen KI -Assistenten erstellen, der Ihre Dokumente durchsuchen und präzise, geerdete Antworten geben kann. Dies ist besonders nützlich, um Chatbots zu erstellen, die Fragen basierend auf einer bestimmten privaten Wissensbasis beantworten können.
- Semantische Suche und Informationsabruf: Anstatt nur nach Schlüsselwörtern zu suchen, können Sie Suchfunktionen erstellen, die die Bedeutung der Abfrage eines Benutzers verstehen. Dies eignet sich perfekt für die Suche nach großen Dokumentbibliotheken, Ihren persönlichen Notizen oder der Wissensbasis eines Unternehmens, um sicherzustellen, dass Sie schnell und genau die relevantesten Informationen finden.
- Klassifizierung und Clustering: Einbettungsgemma kann verwendet werden, um Anwendungen für das Gerät für Aufgaben wie Klassifizierung von Texten (z. B. Stimmungsanalyse, SPAM-Erkennung) oder sie in Gruppen zu gruppieren, basierend auf ihren Ähnlichkeiten (z. B. Organisation von Dokumenten, Marktforschung).
- Semantische Ähnlichkeits- und Empfehlungssysteme: Die Fähigkeit des Modells, die Ähnlichkeit zwischen Texten zu messen, ist eine Kernkomponente von Empfehlungsmotoren. Zum Beispiel kann es einem Benutzer, der auf seinem Leseverlauf basierend auf dem Leserhistorium, neue Artikel oder Produkte empfehlen und gleichzeitig ihre Daten privat halten.
- Code -Abruf & Faktenüberprüfung: Entwickler können ein Emettdinggeemma verwenden, um Instruments zu erstellen, mit denen relevante Codeblöcke basierend auf einer natürlichen Sprachabfrage abgerufen werden. Es kann auch in Fakten zur Überprüfung von Systemen verwendet werden, um Dokumente abzurufen, die eine Erklärung unterstützen oder widerlegen, wodurch die Zuverlässigkeit von Informationen verbessert wird.
Abschluss
Google hat nicht nur ein Modell gestartet. Sie haben ein Toolkit veröffentlicht. Einbettinggeemma integriert sich in Frameworks wie Satztransformers, Lama.cpp und Langchain, was es den Entwicklern erleichtert, leistungsstarke Anwendungen aufzubauen. Die Zukunft ist lokal. Einbettunggeemma ermöglicht die Privatsphäre, die erste, effiziente und schnelle KI, die direkt auf Geräten ausgeführt wird. Es demokratisiert Zugang und legt leistungsstarke Werkzeuge in die Hände von Milliarden.
Anu Madan ist ein Experte für Unterrichtsdesign, Inhaltsschreiben und B2B -Advertising and marketing mit einem Expertise, komplexe Ideen in wirkungsvolle Erzählungen zu verwandeln. Mit ihrem Fokus auf generative KI erstellt sie aufschlussreiche, progressive Inhalte, die ein sinnvolles Engagement erziehen, inspiriert und fördert.
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.