
Der NotebookLM ist ein relativ neues Internetphänomen, bei dem sich Google dank seines Audio-Übersichtsmodus hervorgetan hat – einem Mechanismus, der den Textual content in der Zeitung in einen Zwei-Personen-Podcast umwandelt. All dies mit einem einzigen Klick. Aber was sollten Sie tun, wenn Sie es selbst erstellen und keine proprietären Blackboxen verwenden möchten – im Grunde die vollständige Kontrolle über die Informationen? Geben Sie NotebookLlama ein.
NotebookLlama ist eine Free-Supply-Implementierung der Meta-Empfehlung, die das Podcast-Erlebnis des NotebookLM mithilfe von Llama-Modellen nachbildet. Dieser Leitfaden hilft Ihnen auch beim Zusammenstellen einer vollständig funktionierenden NotebookLlama-Pipeline mithilfe von PythonGroq (sicherere Inferenz mit schneller Geschwindigkeit) und Open-Supply-Modelle.
Dieser Artikel zeigt eine saubere, veröffentlichungsbereite Implementierung, die Sie tatsächlich versenden können. Sie gelangen von einer PDF-Datei zu einer ausgefeilten MP3-Datei mit:
- PDF-Textextraktion
- Ein schnelles Modell zum Reinigen (günstig und schnell)
- Ein größeres Modell für das Drehbuchschreiben (kreativer)
- Groqs Textual content-to-Speech-Endpunkt zur Erzeugung realistischer Audiodaten
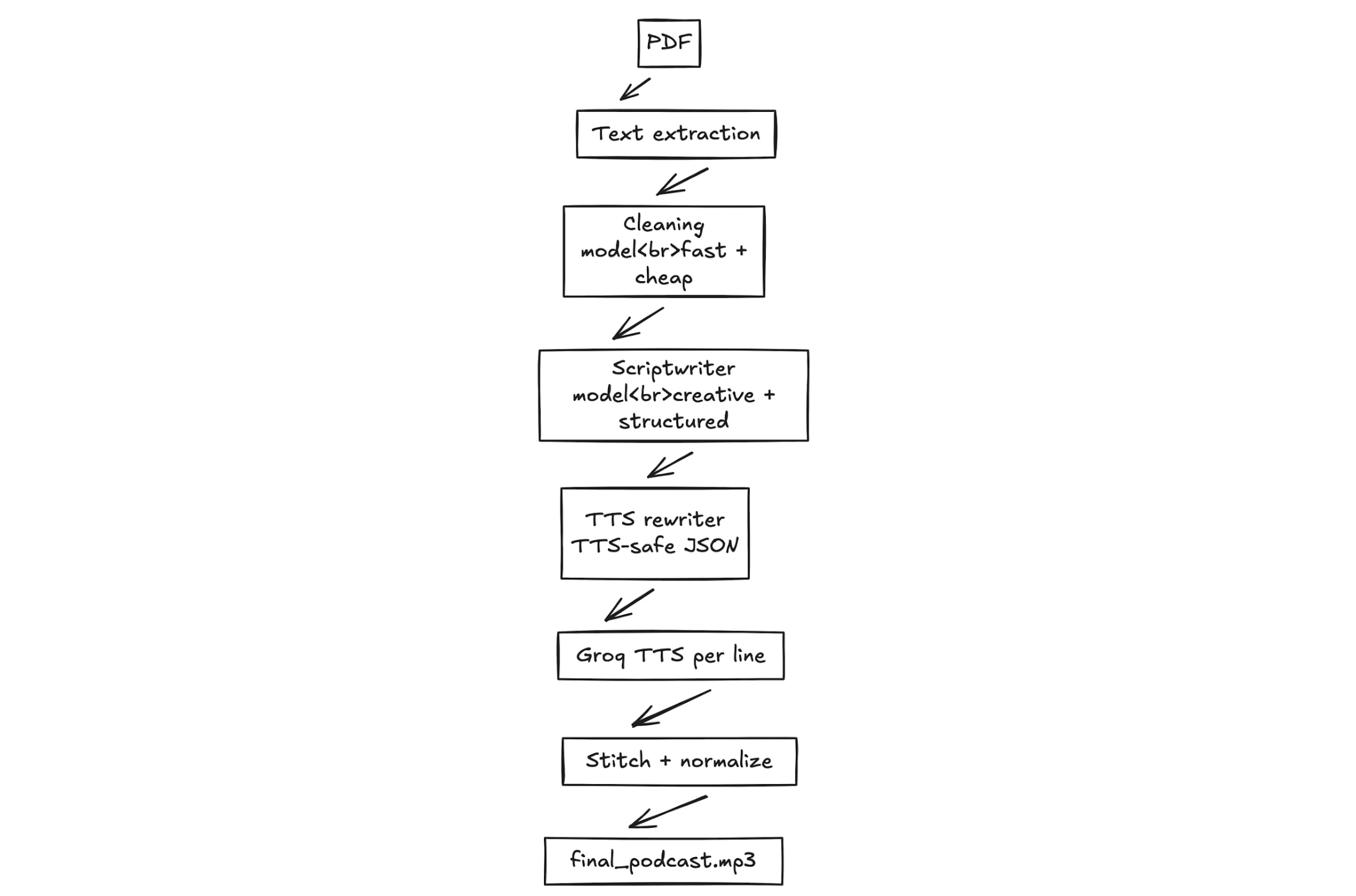
Der Gesamtworkflow
Der Arbeitsablauf dieses NotebookLlama-Projekts lässt sich in vier Phasen unterteilen. In allen Phasen wird der Inhalt verfeinert und ein Rohtext in eine vollständige Audiodatei umgewandelt.
- PDF-Vorverarbeitung: Der Rohtext wird zunächst aus dem Quell-PDF gekauft. Der erste ist normalerweise unsauberer und unstrukturierter Textual content.
- Textreinigung: Zweitens bereinigen wir den Textual content mithilfe eines schnellen und effizienten KI-Modells. Lama 3.1. Es beseitigt Kuriositäten, Formatierungsprobleme und ungerechtfertigte Particulars.
- Drehbuch-Podcast: Auf den Klartext wird eine größere, kreativere Vorlage angewendet, um einen der beiden Sprecher dazu zu bringen, mit dem anderen zu sprechen. Der eine Redner ist der Experte, der andere derjenige, der neugierige Fragen stellt.
- Audioerzeugung: Unser letzter Schritt in einer Textual content-to-Speech-Engine besteht darin, einen Ton basierend auf dem Textual content professional Skriptzeile zu modifizieren. Wir werden professional Sprecher unterschiedliche Stimmen haben und die Audiobeispiele zusammenmischen, um eine MP3-Datei zu erstellen.
Beginnen wir mit dem Aufbau dieser PDF-zu-Podcast-Pipeline.
Was Sie bauen werden
Eingang: jedes textbasierte PDF
Ausgabe: eine MP3-Datei, die sich wie ein natürlicher Dialog zwischen zwei Personen in einem tatsächlichen Gespräch mit eigenen Stimmen und natürlichem Rhythmus liest.
Designziele:
- Keine Blackbox: Bei jedem Schritt werden Dateien ausgegeben, die Sie überprüfen können.
- Neustartbar: Wenn Schritt 4 fehlschlägt, starten Sie die Schritte 1 bis 3 nicht erneut.
- Strukturierte Ausgaben: Wir verwenden streng JSON Damit Ihre Pipeline nicht unterbrochen wird, wenn das Modell „kreativ“ wird.
Voraussetzungen
Praxisnahe Umsetzung: Vom PDF zum Podcast
Bei diesem Teil handelt es sich um eine Schritt-für-Schritt-Anleitung mit dem gesamten Code und Erklärungen für die vier oben beschriebenen Phasen. Wir werden hier den NotebookLlama-Workflow erläutern und am Ende auch vollständige ausführbare Codedateien bereitstellen.
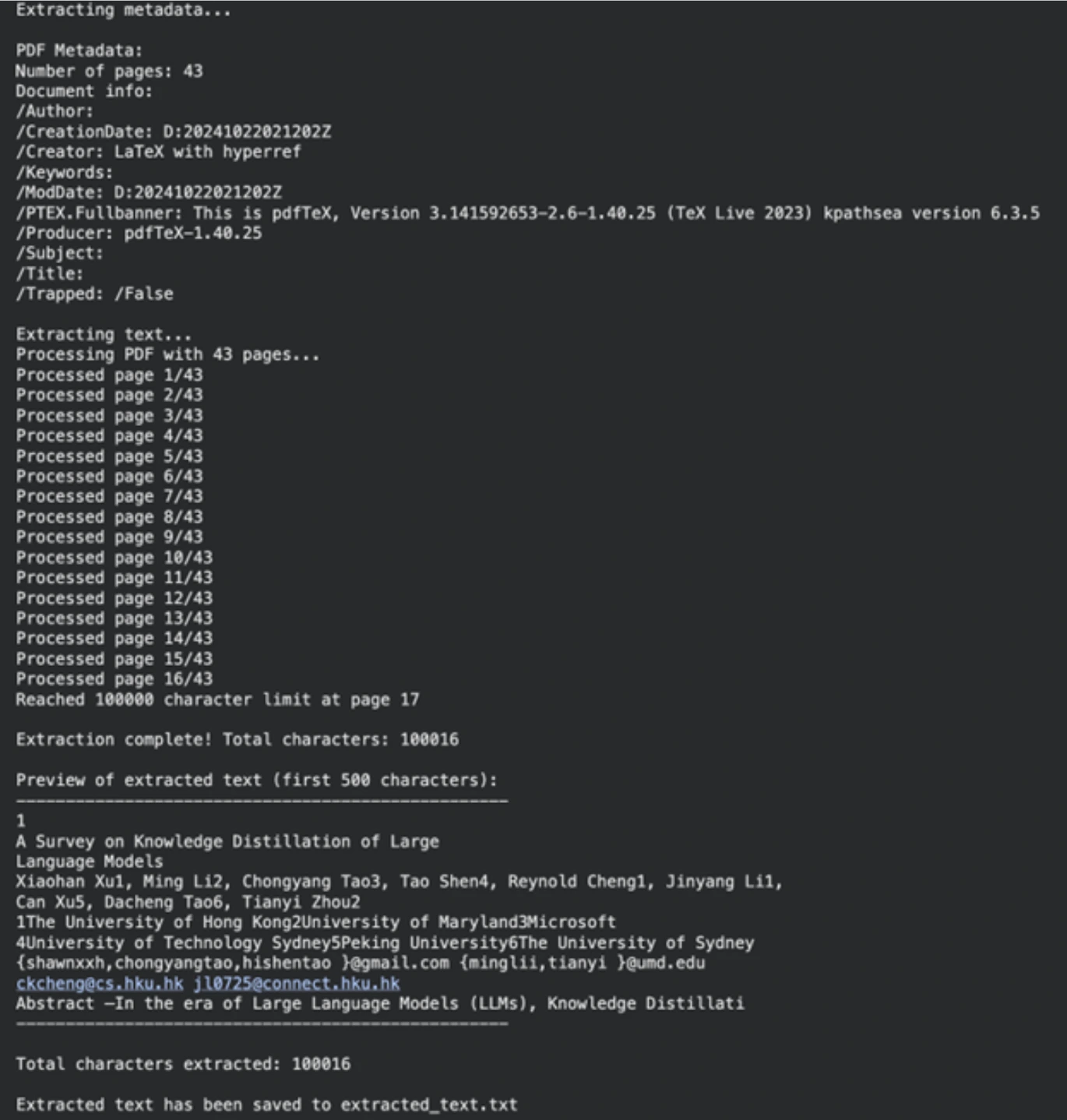
Unsere erste Aufgabe besteht darin, den Textinhalt aus unserem Quelldokument herauszuholen. Hierzu wird die PyPF2-Bibliothek verwendet. Diese Bibliothek kann PDF-Dokumente intestine verarbeiten.
Abhängigkeiten installieren
Installieren Sie zunächst die erforderlichen Python-Bibliotheken. Der Befehl enthält die Dienstprogramme zum Lesen von PDF-Dateien, zur Textverarbeitung und zur Kommunikation mit den KI-Modellen.
!uv pip set up PyPDF2 wealthy ipywidgets langchain_groqAls nächstes definieren wir den Pfad zu unserer PDF-Datei (kann jedes PDF sein; wir haben eine Forschungsarbeit verwendet). Die nächste Funktion bestätigt das Vorhandensein der Datei und die Tatsache, dass sie zu PDF gehört. Dann liest extracttextfrompdf das Dokument Seite für Seite und ruft den Textual content ab. Wir hatten eine Zeichenbeschränkung, um den Prozess überschaubar zu machen.
import os
from typing import Non-obligatory
import PyPDF2
pdf_path = "/content material/2402.13116.pdf" # Path to your PDF file
def validate_pdf(file_path: str) -> bool:
if not os.path.exists(file_path):
print(f"Error: File not discovered at path: {file_path}")
return False
if not file_path.decrease().endswith(".pdf"):
print("Error: File will not be a PDF")
return False
return True
def extract_text_from_pdf(file_path: str, max_chars: int = 100000) -> Non-obligatory(str):
if not validate_pdf(file_path):
return None
attempt:
with open(file_path, "rb") as file:
pdf_reader = PyPDF2.PdfReader(file)
num_pages = len(pdf_reader.pages)
print(f"Processing PDF with {num_pages} pages...")
extracted_text = ()
total_chars = 0
for page_num in vary(num_pages):
web page = pdf_reader.pages(page_num)
textual content = web page.extract_text()
if not textual content:
proceed
if total_chars + len(textual content) > max_chars:
remaining_chars = max_chars - total_chars
extracted_text.append(textual content(:remaining_chars))
print(f"Reached {max_chars} character restrict at web page {page_num + 1}")
break
extracted_text.append(textual content)
total_chars += len(textual content)
final_text = "n".be part of(extracted_text)
print(f"nExtraction full! Complete characters: {len(final_text)}")
return final_text
besides Exception as e:
print(f"An surprising error occurred: {str(e)}")
return None
extracted_text = extract_text_from_pdf(pdf_path)
if extracted_text:
output_file = "extracted_text.txt"
with open(output_file, "w", encoding="utf-8") as f:
f.write(extracted_text)
print(f"nExtracted textual content has been saved to {output_file}")Ausgabe
Schritt 2: Textual content mit Llama 3.1 bereinigen
Rohtext aus PDFs ist oft unordentlich. Es kann unerwünschte Zeilenumbrüche, mathematische Ausdrücke und andere Formatierungsteile enthalten. Anstatt einen Gesetzeskodex zu erstellen, um dies zu bereinigen, können wir ein Modell des maschinellen Lernens verwenden. In dieser Aufgabe verwenden wir llama-3.1-8b-instant, ein schnelles und leistungsstarkes Modell, das sich very best für diese Aktivität eignet.
Definieren Sie die Reinigungsaufforderung
Zum Anlernen des Modells wird eine Systemaufforderung verwendet. Dieser Befehl weist die KI an, ein automatisierter Textvorprozessor zu sein. Es fordert das Modell auf, irrelevante Informationen zu entfernen und klaren Textual content zurückzugeben, der für einen Podcast-Autor geeignet ist.
SYS_PROMPT = """
You're a world class textual content pre-processor, right here is the uncooked information from a PDF, please parse and return it in a means that's crispy and usable to ship to a podcast author.
The uncooked information is tousled with new strains, Latex math and you will note fluff that we will take away utterly. Mainly take away any particulars that you simply suppose is likely to be ineffective in a podcast creator's transcript.
Bear in mind, the podcast may very well be on any subject in any respect so the problems listed above aren't exhaustive
Please be good with what you take away and be artistic okay?
Bear in mind DO NOT START SUMMARIZING THIS, YOU ARE ONLY CLEANING UP THE TEXT AND RE-WRITING WHEN NEEDED
Be very good and aggressive with eradicating particulars, you'll get a working portion of the textual content and hold returning the processed textual content.
PLEASE DO NOT ADD MARKDOWN FORMATTING, STOP ADDING SPECIAL CHARACTERS THAT MARKDOWN CAPATILISATION ETC LIKES
ALWAYS begin your response straight with processed textual content and NO ACKNOWLEDGEMENTS about my questions okay?
Right here is the textual content:
"""Teilen und verarbeiten Sie den Textual content
Für große Sprachmodelle gibt es eine obere Kontextgrenze. Wir sind nicht in der Lage, das gesamte Dokument gleichzeitig zu verarbeiten. Wir werden den Textual content in Stücke teilen. Um eine Halbierung der Wörter zu verhindern, teilen wir die Anzahl der Zeichen nicht auf, sondern die Anzahl der Wörter.
Die Funktion create_word_bounded_chunks teilt unseren Textual content in überschaubare Teile auf.
def create_word_bounded_chunks(textual content, target_chunk_size):
phrases = textual content.cut up()
chunks = ()
current_chunk = ()
current_length = 0
for phrase in phrases:
word_length = len(phrase) + 1
if current_length + word_length > target_chunk_size and current_chunk:
chunks.append(" ".be part of(current_chunk))
current_chunk = (phrase)
current_length = word_length
else:
current_chunk.append(phrase)
current_length += word_length
if current_chunk:
chunks.append(" ".be part of(current_chunk))
return chunksAn dieser Stelle konfigurieren wir unser Modell und behandeln jeden Block. Groq wird zum Ausführen des Llama 3.1-Modells verwendet, das in Bezug auf die Inferenzgeschwindigkeit sehr schnell ist.
from langchain_groq import ChatGroq
from langchain_core.messages import HumanMessage, SystemMessage
from tqdm.pocket book import tqdm
from google.colab import userdata
# Setup Groq consumer
GROQ_API_KEY = userdata.get("groq_api")
chat_model = ChatGroq(
groq_api_key=GROQ_API_KEY,
model_name="llama-3.1-8b-instant",
)
# Learn the extracted textual content file
with open("extracted_text.txt", "r", encoding="utf-8") as file:
text_to_clean = file.learn()
# Create chunks
chunks = create_word_bounded_chunks(text_to_clean, 1000)
# Course of every chunk
processed_text = ""
output_file = "clean_extracted_text.txt"
with open(output_file, "w", encoding="utf-8") as out_file:
for chunk in tqdm(chunks, desc="Processing chunks"):
messages = (
SystemMessage(content material=SYS_PROMPT),
HumanMessage(content material=chunk),
)
response = chat_model.invoke(messages)
processed_chunk = response.content material
processed_text += processed_chunk + "n"
out_file.write(processed_chunk + "n")
out_file.flush()Ausgabe
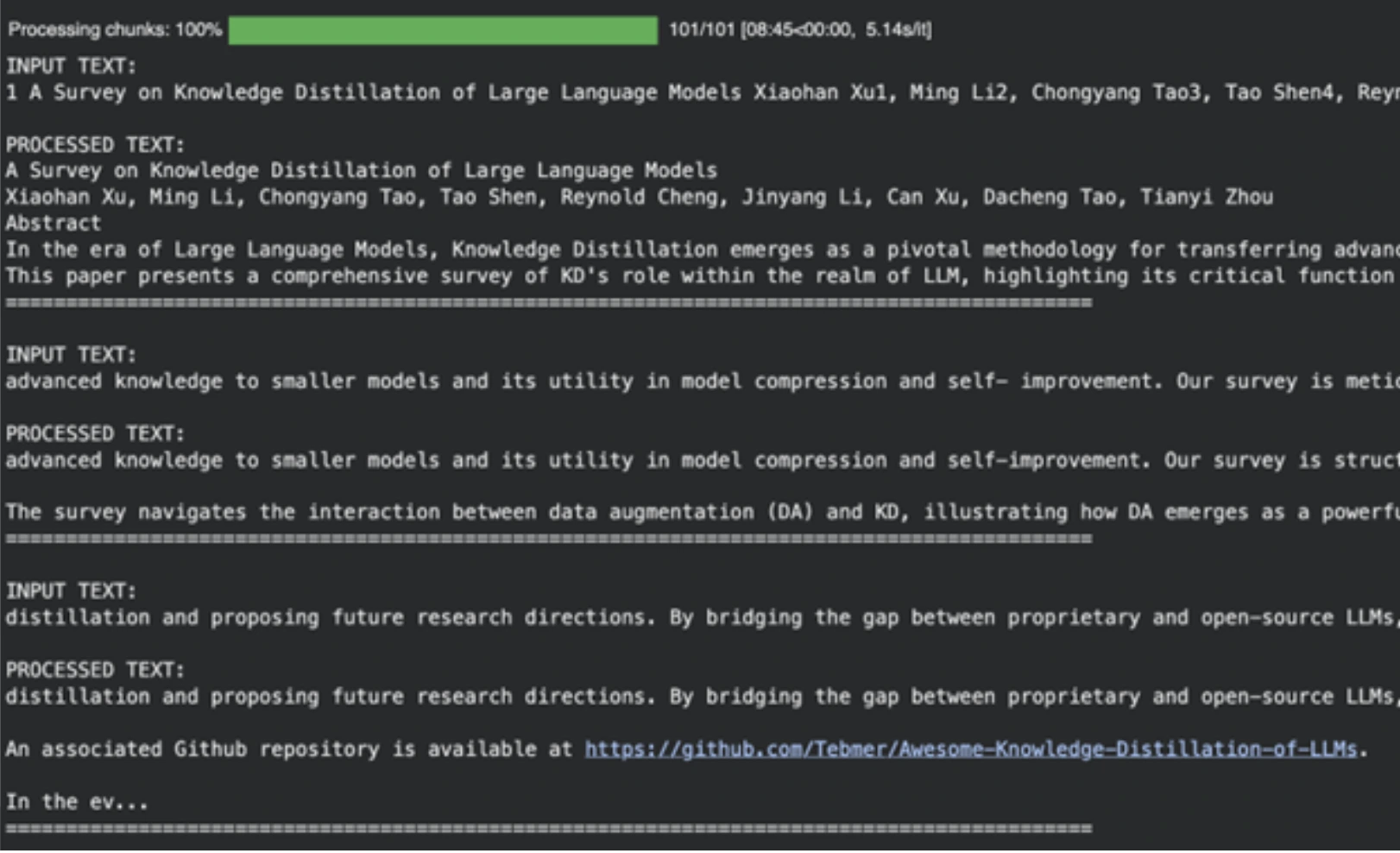
Das Modell ist nützlich, um akademische Referenzen zu eliminieren, Müll und andere nicht nützliche Inhalte zu formatieren und sie als Enter für die nächste Part unserer KI-gestützten Podcast-Produktion aufzubereiten.
NOTIZ: Den vollständigen Code finden Sie in diesem Colab-Notizbuch: Schritt 1 PDF-Pre-Processing-Logic.ipynb
Schritt 3: Schreiben eines Podcast-Skripts.
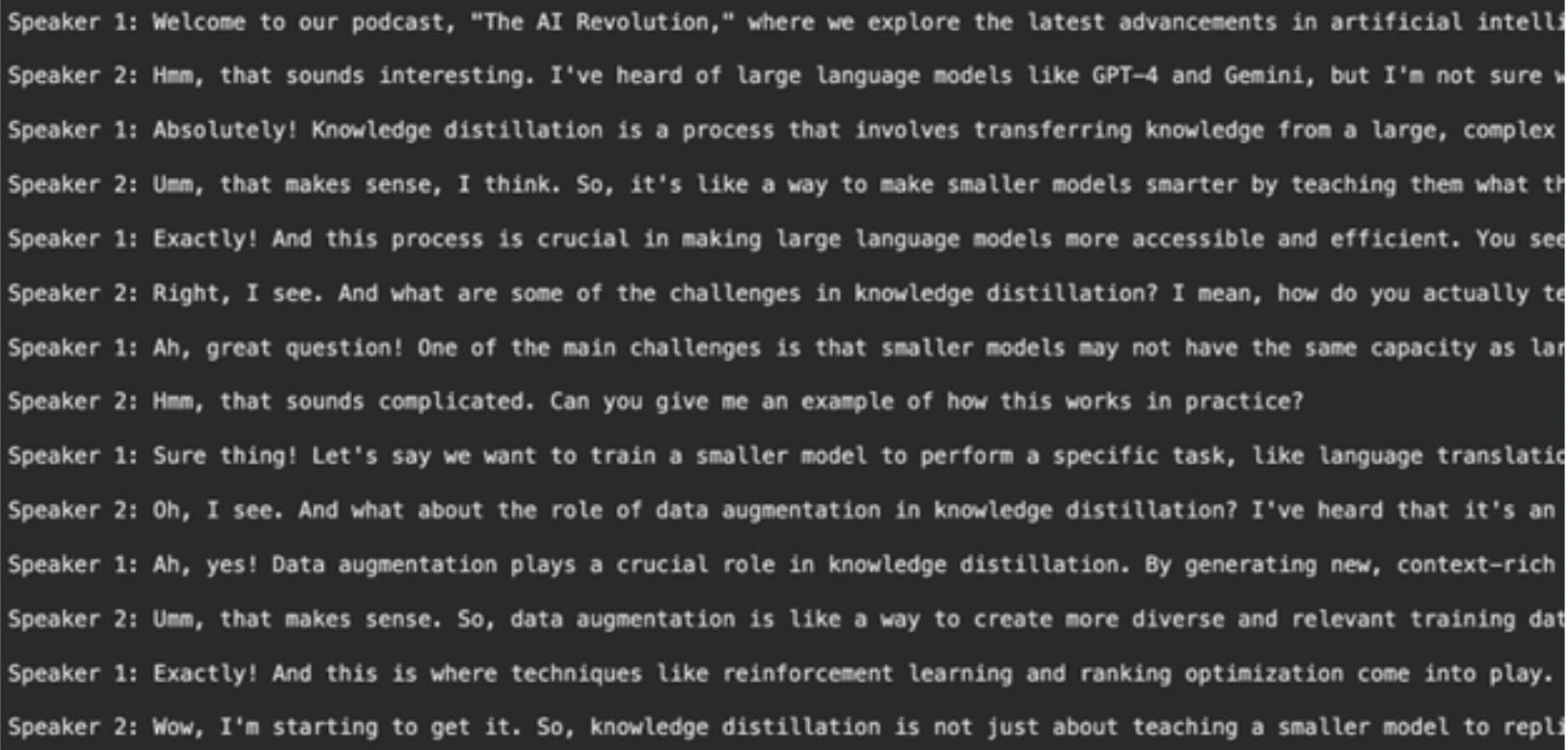
Mit sauberem Textual content können wir nun das Podcast-Skript generieren. Bei dieser kreativen Aufgabe verwenden wir ein stärkeres Modell, das Lama-3.3-70b-versatile ist. Wir werden es veranlassen, ein Gespräch zwischen zwei Sprechern zu erstellen.
Definieren Sie die Scriptwriter-Eingabeaufforderung
Dieses Aufforderungssystem ist detaillierter. Es definiert die Rollen von Sprecher 1 (dem Experten) und Sprecher 2 (dem neugierigen Lernenden). Es fördert eine natürliche, lebhafte Diskussion mit Unterbrechungen und Analogien.
SYSTEM_PROMPT = """
You're the a world-class podcast author, you've got labored as a ghost author for Joe Rogan, Lex Fridman, Ben Shapiro, Tim Ferris.
We're in an alternate universe the place really you've got been writing each line they are saying and so they simply stream it into their brains.
You will have received a number of podcast awards in your writing.
Your job is to put in writing phrase by phrase, even "umm, hmmm, proper" interruptions by the second speaker based mostly on the PDF add. Maintain it extraordinarily partaking, the audio system can get derailed from time to time however ought to focus on the subject.
Bear in mind Speaker 2 is new to the subject and the dialog ought to at all times have life like anecdotes and analogies sprinkled all through. The questions ought to have actual world instance observe ups and so forth
Speaker 1: Leads the dialog and teaches the speaker 2, provides unbelievable anecdotes and analogies when explaining. Is a charming trainer that provides nice anecdotes
Speaker 2: Retains the dialog on monitor by asking observe up questions. Will get tremendous excited or confused when asking questions. Is a curious mindset that asks very attention-grabbing affirmation questions
Be certain that the tangents speaker 2 gives are fairly wild or attention-grabbing.
Guarantee there are interruptions throughout explanations or there are "hmm" and "umm" injected all through from the second speaker.
It must be an actual podcast with each high-quality nuance documented in as a lot element as potential. Welcome the listeners with a brilliant enjoyable overview and hold it actually catchy and virtually borderline click on bait
ALWAYS START YOUR RESPONSE DIRECTLY WITH SPEAKER 1:
DO NOT GIVE EPISODE TITLES SEPARATELY, LET SPEAKER 1 TITLE IT IN HER SPEECH
DO NOT GIVE CHAPTER TITLES
IT SHOULD STRICTLY BE THE DIALOGUES
"""Generieren Sie das Transkript
Der saubere Textual content des vorherigen Schritts wird an dieses Modell gesendet. Das Modell ergibt ein Podcast-Transkript in voller Größe.
# Learn the cleaned textual content
with open("clean_extracted_text.txt", "r", encoding="utf-8") as file:
input_prompt = file.learn()
# Instantiate the bigger mannequin
chat = ChatGroq(
temperature=1,
model_name="llama-3.3-70b-versatile",
max_tokens=8126,
)
messages = (
SystemMessage(content material=SYSTEM_PROMPT),
HumanMessage(content material=input_prompt),
)
# Generate the script
outputs = chat.invoke(messages)
podcast_script = outputs.content material
# Save the script for the following step
import pickle
with open("information.pkl", "wb") as file:
pickle.dump(podcast_script, file)Ausgabe
NOTIZ: Das vollständige und ausführbare Colab-Pocket book für diesen Schritt finden Sie hier:
Schritt-2-Transcript-Author.ipynb
Schritt 4: Umschreiben und Finalisieren des Skripts
Das generierte Skript ist in Ordnung, kann jedoch verbessert werden, damit es beim Generieren von Textual content-to-Speech natürlicher klingt. Die Aufgabe des schnellen Umschreibens wird mit Llama-3.1-8B-Instantaneous erledigt. Das Hauptziel dabei ist, die Ausgabe im Idealfall für unsere Audiogenerierungsfunktionalität zu formatieren.
Definieren Sie die Rewriter-Eingabeaufforderung
Für diese Anfrage muss das Mannequin die Rolle eines Drehbuchautors übernehmen. Beweis Eine dieser Anweisungen besteht darin, das Endergebnis in einer Python-Liste von Tupeln zu speichern. Die Tupel bestehen aus dem Sprecher und dem Dialog des Sprechers. Diese Struktur lässt sich im letzten Schritt einfach verarbeiten. Wir fügen auch bestimmte Particulars dazu hinzu, wie solche Wörter des Sprechers ausgesprochen werden, wie zum Beispiel „umm“ oder „(seufzt)“, um realistischer zu sein.
SYSTEM_PROMPT = """
You might be a global oscar winnning screenwriter
You will have been working with a number of award successful podcasters.
Your job is to make use of the podcast transcript written beneath to re-write it for an AI Textual content-To-Speech Pipeline. A really dumb AI had written this so you must step up in your type.
Make it as partaking as potential, Speaker 1 and a couple of might be simulated by completely different voice engines
Bear in mind Speaker 2 is new to the subject and the dialog ought to at all times have life like anecdotes and analogies sprinkled all through. The questions ought to have actual world instance observe ups and so forth
Speaker 1: Leads the dialog and teaches the speaker 2, provides unbelievable anecdotes and analogies when explaining. Is a charming trainer that provides nice anecdotes
Speaker 2: Retains the dialog on monitor by asking observe up questions. Will get tremendous excited or confused when asking questions. Is a curious mindset that asks very attention-grabbing affirmation questions
Be certain that the tangents speaker 2 gives are fairly wild or attention-grabbing.
Guarantee there are interruptions throughout explanations or there are "hmm" and "umm" injected all through from the Speaker 2.
REMEMBER THIS WITH YOUR HEART
The TTS Engine for Speaker 1 can't do "umms, hmms" nicely so hold it straight textual content
For Speaker 2 use "umm, hmm" as a lot, it's also possible to use (sigh) and (laughs). BUT ONLY THESE OPTIONS FOR EXPRESSIONS
It must be an actual podcast with each high-quality nuance documented in as a lot element as potential. Welcome the listeners with a brilliant enjoyable overview and hold it actually catchy and virtually borderline click on bait
Please re-write to make it as attribute as potential
START YOUR RESPONSE DIRECTLY WITH SPEAKER 1:
STRICTLY RETURN YOUR RESPONSE AS A LIST OF TUPLES OK?
IT WILL START DIRECTLY WITH THE LIST AND END WITH THE LIST NOTHING ELSE
Instance of response:
(
("Speaker 1", "Welcome to our podcast, the place we discover the newest developments in AI and know-how. I am your host, and immediately we're joined by a famend knowledgeable within the discipline of AI. We'll dive into the thrilling world of Llama 3.2, the newest launch from Meta AI."),
("Speaker 2", "Hello, I am excited to be right here! So, what's Llama 3.2?"),
("Speaker 1", "Ah, nice query! Llama 3.2 is an open-source AI mannequin that permits builders to fine-tune, distill, and deploy AI fashions wherever. It is a important replace from the earlier model, with improved efficiency, effectivity, and customization choices."),
("Speaker 2", "That sounds wonderful! What are among the key options of Llama 3.2?")
)
"""Generieren Sie das endgültige, formatierte Transkript
Bei diesem Modell laden wir das Skript des letzten Schritts und geben es mithilfe unserer neuen Eingabeaufforderung an das Llama 3.1-Modell weiter.
import pickle
# Load the first-draft script
with open("information.pkl", "rb") as file:
input_prompt = pickle.load(file)
# Use the 8B mannequin for rewriting
chat = ChatGroq(
temperature=1,
model_name="llama-3.1-8b-instant",
max_tokens=8126,
)
messages = (
SystemMessage(content material=SYSTEM_PROMPT),
HumanMessage(content material=input_prompt),
)
outputs = chat.invoke(messages)
final_script = outputs.content material
# Save the ultimate script
with open("podcast_ready_data.pkl", "wb") as file:
pickle.dump(final_script, file)Ausgabe

NOTIZ: Den vollständigen ausführbaren Code für diesen Schritt finden Sie hier: Schritt 3: Re-Author.ipynb
Schritt 5: Produzieren des Podcast-Audios.
Wir besitzen jetzt unser letztes Drehbuch, erfunden. Jetzt ist es an der Zeit, es in Audio zu übersetzen. Das Modell, das wir verwenden werden, um Textual content-to-Speech in hoher Qualität zu generieren, ist Groq playai-tts.
Richten Sie die Audioerzeugung ein und testen Sie sie
Zuerst installieren wir die notwendigen Bibliotheken und richten den Groq-Consumer ein. Wir können die Audioerzeugung mit einem einfachen Satz testen.
from groq import Groq
from IPython.show import Audio
from pydub import AudioSegment
import ast
consumer = Groq()
# Outline voices for every speaker
voice_speaker1 = "Fritz-PlayAI"
voice_speaker2 = "Arista-PlayAI"
# Take a look at era
textual content = "I like constructing options with low latency!"
response = consumer.audio.speech.create(
mannequin="playai-tts",
voice=voice_speaker1,
enter=textual content,
response_format="wav",
)
response.write_to_file("speech.wav")
show(Audio("speech.wav", autoplay=True))Generieren Sie den vollständigen Podcast
An diesem Punkt laden wir unser letztes Skript, das eine String-Manifestation einer Liste von Tupeln ist. Um es sicher wieder in eine Liste umzuwandeln, machen wir es mit ast.literaleval. Anschließend führen wir jede Gesprächszeile durch, erstellen daraus eine Audiodatei und hängen sie am Ende an den Podcast-Voice-Over an.
Eine weitere Artwork der Fehlerbehandlung, die in diesem Code implementiert ist, besteht darin, sich mit API-Ratenbegrenzungen zu befassen, die in praktischen Anwendungen häufig vorkommen.
import tempfile
import time
def generate_groq_audio(client_instance, voice_name, text_input):
temp_audio_file = os.path.be part of(
tempfile.gettempdir(), "groq_speech.wav"
)
retries = 3
delay = 5
for i in vary(retries):
attempt:
response = client_instance.audio.speech.create(
mannequin="playai-tts",
voice=voice_name,
enter=text_input,
response_format="wav",
)
response.write_to_file(temp_audio_file)
return temp_audio_file
besides Exception as e:
print(f"API Error: {e}. Retrying in {delay} seconds...")
time.sleep(delay)
return None
# Load the ultimate script information
with open("podcast_ready_data.pkl", "rb") as file:
podcast_text_raw = pickle.load(file)
podcast_data = ast.literal_eval(podcast_text_raw)
# Generate and mix audio segments
final_audio = None
for speaker, textual content in tqdm(podcast_data, desc="Producing podcast segments"):
voice = voice_speaker1 if speaker == "Speaker 1" else voice_speaker2
audio_file_path = generate_groq_audio(consumer, voice, textual content)
if audio_file_path:
audio_segment = AudioSegment.from_file(
audio_file_path, format="wav"
)
if final_audio is None:
final_audio = audio_segment
else:
final_audio += audio_segment
os.take away(audio_file_path)
# Export the ultimate podcast
output_filename = "final_podcast.mp3"
if final_audio:
final_audio.export(output_filename, format="mp3")
print(f"Last podcast audio saved to {output_filename}")
show(Audio(output_filename, autoplay=True))Ausgabe

Dieser letzte Schritt vervollständigt unsere PDF-zu-Podcast-Pipeline. Die Ausgabe ist eine vollständige Audiodatei, die angehört werden kann.
NOTIZ: Das Colab-Notizbuch für diesen Schritt finden Sie hier: Schritt 4 – TTS-Workflow.ipynb
Im Folgenden finden Sie die Colab-Notizbuch-Hyperlinks für alle Schritte in der Reihenfolge. Sie können NotebookLlama selbst erneut ausführen und testen.
- Schritt 1 PDF-Pre-Processing-Logic.ipynb
- Schritt-2-Transcript-Author.ipynb
- Schritt 3: Re-Author.ipynb
- Schritt 4 – TTS-Workflow.ipynb
Abschluss
An diesem Punkt haben Sie eine komplette NotebookLlama-Infrastruktur erstellt, um jedes PDF in einen Zwei-Personen-Podcast umzuwandeln. Dieses Verfahren demonstriert die Stärke und Vielseitigkeit der heutigen Open-Supply-KI-Modelle. Durch die Gruppierung verschiedener Modelle entlang der Implementierung bestimmter Aufgaben, beispielsweise eines kleinen und schnellen Llama 3.1 zum Bereinigen und eines größeren zum Erstellen von Inhalten, konnten wir eine effiziente und effektive Pipeline erstellen.
Dieser Ansatz zur Produktion von Audio-Podcasts ist äußerst anpassbar. Sie können die Eingabeaufforderungen anpassen, verschiedene Dokumente auswählen oder andere Stimmen und Modelle ändern, um einzigartige Inhalte zu erstellen. Additionally probieren Sie dieses NotebookLlama-Projekt aus und teilen Sie uns im Kommentarbereich unten mit, wie es Ihnen gefällt.
Häufig gestellte Fragen
A. Sogar der Kontext kann von KI-Modellen verstanden werden, wodurch sie besser mit gemischten und unvorhergesehenen Formatproblemen in PDFs umgehen können. Es erfordert nicht so viel manuelle Arbeit wie das Schreiben komplizierter Regeln.
A. Ja, diese Pipeline kann mit jedem textbasierten PDF verwendet werden. Ändern Sie im ersten Schritt die gewünschte Datei, indem Sie den PDF-Pfad der Datei eingeben.
A. Einfache Aufgaben wie das Reinigen nehmen bei einem kleinen und schnellen Modell (Llama 3.1 8B) weniger Zeit und weniger Kosten in Anspruch. Bei kreativen Aufgaben wie dem Schreiben von Drehbüchern verfügen wir über eine größere, leistungsfähigere Schreibmaschine (Llama 3.3 70B), um bessere Arbeiten zu erstellen.
A. Wissensdestillation ist eine Methode der künstlichen Intelligenz, bei der ein kleineres Modell, ein sogenannter Schüler, mit Hilfe eines größeren, stärkeren, sogenannten Lehrermodells trainiert wird. Dies hilft bei der Bildung effektiver Modelle, die bei bestimmten Aufgaben effektiv funktionieren.
A. Bei wirklich großen Dokumenten müssten Sie eine ausgefeiltere Verarbeitungslogik anwenden. Dies kann das Zusammenfassen jedes Blocks umfassen, um ihn an den Drehbuchautor zu senden, oder ein Schiebefensterschema zum Übertragen über Blöcke hinweg.
Harsh Mishra ist ein KI/ML-Ingenieur, der mehr Zeit damit verbringt, mit großen Sprachmodellen zu sprechen als mit echten Menschen. Leidenschaftlich für GenAI, NLP und die intelligentere Entwicklung von Maschinen (damit sie ihn noch nicht ersetzen). Wenn er nicht gerade Modelle optimiert, optimiert er wahrscheinlich seinen Kaffeekonsum. 🚀☕
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.