Bild vom Autor
# Einführung
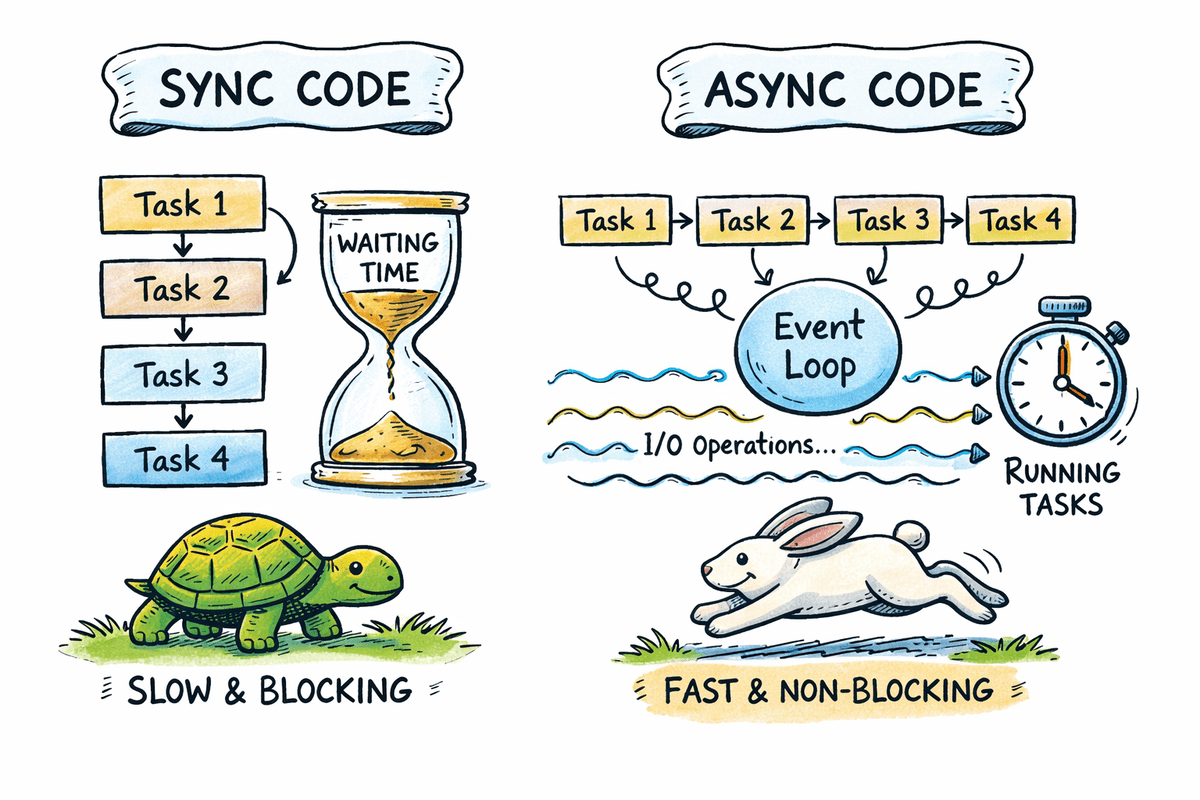
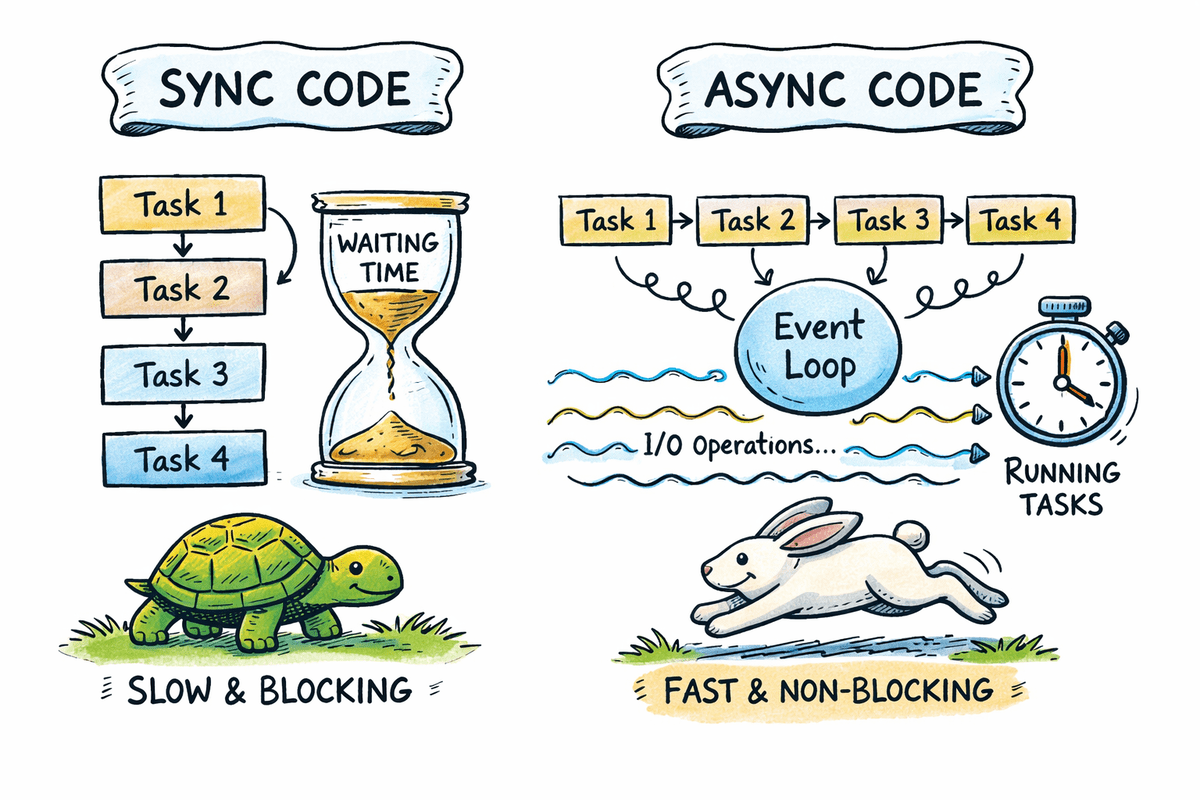
Die meisten Python-Anwendungen verbringen viel Zeit damit, auf APIs, Datenbanken, Dateisysteme und Netzwerkdienste zu warten. Durch die asynchrone Programmierung kann ein Programm anhalten, während es auf E/A-Vorgänge wartet, und weiterhin andere Aufgaben ausführen, anstatt sie zu blockieren.
In diesem Tutorial lernen Sie anhand anschaulicher Codebeispiele die Grundlagen der asynchronen Programmierung in Python kennen. Wir werden synchrone und asynchrone Ausführung vergleichen, erklären, wie die Ereignisschleife funktioniert, und asynchrone Muster auf reale Szenarien wie gleichzeitige API-Anfragen und Hintergrundaufgaben anwenden.
Am Ende dieses Leitfadens werden Sie verstehen, wann asynchrone Programmierung sinnvoll ist, wie Sie Async und Wait richtig verwenden und wie Sie skalierbaren und zuverlässigen asynchronen Python-Code schreiben.
# Definieren der asynchronen Programmierung in Python
Durch die asynchrone Programmierung kann ein Programm die Ausführung anhalten, während es auf den Abschluss eines Vorgangs wartet, und in der Zwischenzeit mit der Ausführung anderer Aufgaben fortfahren.
Zu den Kernbausteinen gehören:
async defzum Definieren von Coroutinenawaitfür nicht blockierende Wartezeiten- Die Ereignisschleife für die Aufgabenplanung
Notiz: Asynchrone Programmierung verbessert den Durchsatz, nicht die reine Rechengeschwindigkeit.
# Verstehen der asynchronen Ereignisschleife in Python
Die Ereignisschleife ist für die Verwaltung und Ausführung asynchroner Aufgaben verantwortlich.
Zu den Hauptaufgaben gehören:
- Verfolgen Sie angehaltene und bereite Aufgaben
- Umschalten der Ausführung, wenn Aufgaben auf E/A warten
- Koordinieren der Parallelität ohne Threads
Python verwendet die asyncio Bibliothek als standardmäßige asynchrone Laufzeit.
# Vergleich der sequentiellen und der asynchronen Ausführung in Python
In diesem Abschnitt wird gezeigt, wie das Blockieren von sequenziellem Code im Vergleich zur asynchronen gleichzeitigen Ausführung abschneidet und wie die Asynchronisierung die Gesamtwartezeit für E/A-gebundene Aufgaben reduziert.
// Untersuchen eines Beispiels für eine sequentielle Blockierung
Bei der sequentiellen Ausführung werden Aufgaben nacheinander ausgeführt. Wenn eine Aufgabe einen blockierenden Vorgang ausführt, wartet das gesamte Programm, bis dieser Vorgang abgeschlossen ist. Dieser Ansatz ist einfach, aber ineffizient für I/O-gebundene Workloads, bei denen das Warten die Ausführungszeit dominiert.
Diese Funktion simuliert eine blockierende Aufgabe. Der Aufruf an time.sleep Pausiert das gesamte Programm für die angegebene Anzahl von Sekunden.
import time
def download_file(title, seconds):
print(f"Beginning {title}")
time.sleep(seconds)
print(f"Completed {title}")Der Timer startet, bevor die Funktion aufgerufen wird, und stoppt, nachdem alle drei Aufrufe abgeschlossen sind. Jede Funktion wird erst ausgeführt, nachdem die vorherige beendet ist.
begin = time.perf_counter()
download_file("file-1", 2)
download_file("file-2", 2)
download_file("file-3", 2)
finish = time.perf_counter()
print(f"(TOTAL SYNC) took {finish - begin:.4f} seconds")Ausgabe:
file-1startet und blockiert das Programm für zwei Sekundenfile-2beginnt erst danachfile-1endetfile-3beginnt erst danachfile-2endet
Die Gesamtlaufzeit ist die Summe aller Verzögerungen, etwa sechs Sekunden.
Beginning file-1
Completed file-1
Beginning file-2
Completed file-2
Beginning file-3
Completed file-3
(TOTAL SYNC) took 6.0009 seconds// Untersuchen eines asynchronen gleichzeitigen Beispiels
Durch die asynchrone Ausführung können Aufgaben gleichzeitig ausgeführt werden. Wenn eine Aufgabe einen erwarteten E/A-Vorgang erreicht, wird sie angehalten und anderen Aufgaben ermöglicht, fortzufahren. Durch diese Wartezeitüberschneidung wird der Durchsatz deutlich verbessert.
Diese asynchrone Funktion definiert eine Coroutine. Der await asyncio.sleep Der Aufruf pausiert nur die aktuelle Aufgabe, nicht das gesamte Programm.
import asyncio
import time
async def download_file(title, seconds):
print(f"Beginning {title}")
await asyncio.sleep(seconds)
print(f"Completed {title}")asyncio.collect Plant alle drei Coroutinen so, dass sie gleichzeitig in der Ereignisschleife ausgeführt werden.
async def essential():
begin = time.perf_counter()
await asyncio.collect(
download_file("file-1", 2),
download_file("file-2", 2),
download_file("file-3", 2),
)
finish = time.perf_counter()
print(f"(TOTAL ASYNC) took {finish - begin:.4f} seconds")Dadurch wird die Ereignisschleife gestartet und das asynchrone Programm ausgeführt.
Ausgabe:
- Alle drei Aufgaben beginnen quick gleichzeitig
- Jede Aufgabe wartet unabhängig voneinander zwei Sekunden
- Während eine Aufgabe wartet, werden andere weiterhin ausgeführt
- Die Gesamtlaufzeit liegt nahe bei der längsten Einzelverzögerung, etwa zwei Sekunden
Beginning file-1
Beginning file-2
Beginning file-3
Completed file-1
Completed file-2
Completed file-3
(TOTAL ASYNC) took 2.0005 seconds# Erkunden, wie Await im Python-Async-Code funktioniert
Der await Das Schlüsselwort teilt Python mit, dass eine Coroutine anhalten und die Ausführung anderer Aufgaben zulassen kann.
Falsche Verwendung:
async def job():
asyncio.sleep(1)Richtige Verwendung:
async def job():
await asyncio.sleep(1)Nicht verwendbar await verhindert Parallelität und kann Laufzeitwarnungen verursachen.
# Ausführen mehrerer asynchroner Aufgaben mit asyncio.collect
asyncio.collect Ermöglicht die gleichzeitige Ausführung mehrerer Coroutinen und sammelt ihre Ergebnisse, sobald alle Aufgaben abgeschlossen sind. Es wird häufig verwendet, wenn mehrere unabhängige asynchrone Vorgänge parallel ausgeführt werden können.
Der job Coroutine simuliert eine asynchrone Aufgabe. Es gibt eine Startmeldung aus, wartet eine Sekunde in einem nicht blockierenden Ruhezustand, gibt dann eine Abschlussmeldung aus und gibt ein Ergebnis zurück.
import asyncio
import time
async def job(job_id, delay=1):
print(f"Job {job_id} began")
await asyncio.sleep(delay)
print(f"Job {job_id} completed")
return f"Accomplished job {job_id}"asyncio.collect Plant alle drei Jobs so, dass sie gleichzeitig in der Ereignisschleife ausgeführt werden. Jeder Job beginnt sofort mit der Ausführung, bis er einen erwarteten Vorgang erreicht.
async def essential():
begin = time.perf_counter()
outcomes = await asyncio.collect(
job(1),
job(2),
job(3),
)
finish = time.perf_counter()
print("nResults:", outcomes)
print(f"(TOTAL WALL TIME) {finish - begin:.4f} seconds")
asyncio.run(essential())Ausgabe:
- Alle drei Jobs beginnen quick gleichzeitig
- Jeder Job wartet unabhängig eine Sekunde
- Während ein Job wartet, laufen andere weiter
- Die Ergebnisse werden in derselben Reihenfolge zurückgegeben, an die die Aufgaben übergeben wurden
asyncio.collect - Die Gesamtausführungszeit liegt bei etwa einer Sekunde, nicht bei drei
Job 1 began
Job 2 began
Job 3 began
Job 1 completed
Job 2 completed
Job 3 completed
Outcomes: ('Accomplished job 1', 'Accomplished job 2', 'Accomplished job 3')
(TOTAL WALL TIME) 1.0013 secondsDieses Muster ist grundlegend für gleichzeitige Netzwerkanforderungen, Datenbankabfragen und andere E/A-gebundene Vorgänge.
# Gleichzeitige HTTP-Anfragen stellen
Asynchrone HTTP-Anfragen sind ein häufiger Anwendungsfall in der Praxis, bei dem die asynchrone Programmierung unmittelbare Vorteile bietet. Wenn mehrere APIs nacheinander aufgerufen werden, entspricht die Gesamtausführungszeit der Summe aller Antwortverzögerungen. Async ermöglicht die gleichzeitige Ausführung dieser Anforderungen.
Diese Liste enthält drei URLs, die ihre Antworten absichtlich um eine, zwei und drei Sekunden verzögern.
import asyncio
import time
import urllib.request
import json
URLS = (
"https://httpbin.org/delay/1",
"https://httpbin.org/delay/2",
"https://httpbin.org/delay/3",
)Diese Funktion führt eine blockierende HTTP-Anfrage mithilfe der Standardbibliothek aus. Es kann nicht direkt abgewartet werden.
def fetch_sync(url):
"""Blocking HTTP request utilizing customary library"""
with urllib.request.urlopen(url) as response:
return json.hundreds(response.learn().decode())Der fetch Coroutine misst die Ausführungszeit und protokolliert den Begin einer Anfrage. Die blockierende HTTP-Anfrage wird mit an einen Hintergrundthread ausgelagert asyncio.to_thread. Dadurch wird verhindert, dass die Ereignisschleife blockiert.
async def fetch(url):
begin = time.perf_counter()
print(f"Fetching {url}")
# Run blocking IO in a thread
information = await asyncio.to_thread(fetch_sync, url)
elapsed = time.perf_counter() - begin
print(f"Completed {url} in {elapsed:.2f} seconds")
return informationAlle Anfragen werden gleichzeitig geplant asyncio.collect.
async def essential():
begin = time.perf_counter()
outcomes = await asyncio.collect(
*(fetch(url) for url in URLS)
)
whole = time.perf_counter() - begin
print(f"nFetched {len(outcomes)} responses")
print(f"(TOTAL WALL TIME) {whole:.2f} seconds")
asyncio.run(essential())Ausgabe:
- Alle drei HTTP-Anfragen starten quick sofort
- Jede Anfrage wird nach ihrer eigenen Verzögerung abgeschlossen
- Die längste Anfrage bestimmt die Gesamtwandzeit
- Die Gesamtlaufzeit beträgt etwa dreieinhalb Sekunden, nicht die Summe aller Verzögerungen
Fetching https://httpbin.org/delay/1
Fetching https://httpbin.org/delay/2
Fetching https://httpbin.org/delay/3
Completed https://httpbin.org/delay/1 in 1.26 seconds
Completed https://httpbin.org/delay/2 in 2.20 seconds
Completed https://httpbin.org/delay/3 in 3.52 seconds
Fetched 3 responses
(TOTAL WALL TIME) 3.52 secondsDieser Ansatz verbessert die Leistung beim Aufruf mehrerer APIs erheblich und ist ein häufiges Muster in modernen asynchronen Python-Diensten.
# Implementieren von Fehlerbehandlungsmustern in asynchronen Python-Anwendungen
Robuste asynchrone Anwendungen müssen Fehler ordnungsgemäß verarbeiten. In gleichzeitigen Systemen sollte eine einzelne fehlgeschlagene Aufgabe nicht dazu führen, dass der gesamte Workflow fehlschlägt. Eine ordnungsgemäße Fehlerbehandlung stellt sicher, dass erfolgreiche Aufgaben abgeschlossen werden, während Fehler sauber gemeldet werden.
Diese Liste enthält zwei erfolgreiche Endpunkte und einen Endpunkt, der einen HTTP-404-Fehler zurückgibt.
import asyncio
import urllib.request
import json
import socket
URLS = (
"https://httpbin.org/delay/1",
"https://httpbin.org/delay/2",
"https://httpbin.org/standing/404",
)Diese Funktion führt eine blockierende HTTP-Anfrage mit Zeitüberschreitung aus. Es kann zu Ausnahmen wie Zeitüberschreitungen oder HTTP-Fehlern kommen.
def fetch_sync(url, timeout):
with urllib.request.urlopen(url, timeout=timeout) as response:
return json.hundreds(response.learn().decode())Diese Funktion umschließt eine blockierende HTTP-Anfrage in einer sicheren asynchronen Schnittstelle. Der Blockierungsvorgang wird in einem Hintergrundthread ausgeführt asyncio.to_threadwodurch verhindert wird, dass die Ereignisschleife während der Verarbeitung der Anforderung blockiert.
Häufige Fehlerfälle wie Zeitüberschreitungen und HTTP-Fehler werden abgefangen und in strukturierte Antworten umgewandelt. Dadurch wird sichergestellt, dass Fehler vorhersehbar behandelt werden und dass eine einzelne fehlgeschlagene Anforderung nicht die Ausführung anderer gleichzeitiger Aufgaben unterbricht.
async def safe_fetch(url, timeout=5):
attempt:
return await asyncio.to_thread(fetch_sync, url, timeout)
besides socket.timeout:
return {"url": url, "error": "timeout"}
besides urllib.error.HTTPError as e:
return {"url": url, "error": "http_error", "standing": e.code}
besides Exception as e:
return {"url": url, "error": "unexpected_error", "message": str(e)}Alle Anfragen werden gleichzeitig mit ausgeführt asyncio.collect.
async def essential():
outcomes = await asyncio.collect(
*(safe_fetch(url) for url in URLS)
)
for lead to outcomes:
print(consequence)
asyncio.run(essential())Ausgabe:
- Die ersten beiden Anfragen werden erfolgreich abgeschlossen und geben geparste JSON-Daten zurück
- Die dritte Anfrage gibt einen strukturierten Fehler zurück, anstatt eine Ausnahme auszulösen
- Alle Ergebnisse werden zusammen zurückgegeben, ohne den Arbeitsablauf zu unterbrechen
{'args': {}, 'information': '', 'recordsdata': {}, 'type': {}, 'headers': {'Settle for-Encoding': 'id', 'Host': 'httpbin.org', 'Person-Agent': 'Python-urllib/3.11', 'X-Amzn-Hint-Id': 'Root=1-6966269f-1cd7fc7821bc6bc469e9ba64'}, 'origin': '3.85.143.193', 'url': 'https://httpbin.org/delay/1'}
{'args': {}, 'information': '', 'recordsdata': {}, 'type': {}, 'headers': {'Settle for-Encoding': 'id', 'Host': 'httpbin.org', 'Person-Agent': 'Python-urllib/3.11', 'X-Amzn-Hint-Id': 'Root=1-6966269f-5f59c151487be7094b2b0b3c'}, 'origin': '3.85.143.193', 'url': 'https://httpbin.org/delay/2'}
{'url': 'https://httpbin.org/standing/404', 'error': 'http_error', 'standing': 404}Dieses Muster stellt sicher, dass eine einzelne fehlgeschlagene Anfrage nicht den gesamten asynchronen Vorgang unterbricht und ist für produktionsbereite asynchrone Anwendungen unerlässlich.
# Verwenden der asynchronen Programmierung in Jupyter Notebooks
Jupyter-Notebooks führen bereits eine aktive Ereignisschleife aus. Aus diesem Grund, asyncio.run kann nicht innerhalb einer Pocket book-Zelle verwendet werden, da versucht wird, eine neue Ereignisschleife zu starten, während eine bereits ausgeführt wird.
Diese asynchrone Funktion simuliert eine einfache, nicht blockierende Aufgabe asyncio.sleep.
import asyncio
async def essential():
await asyncio.sleep(1)
print("Async job accomplished")Falsche Verwendung in Notebooks:
Richtige Verwendung in Notebooks:
Das Verständnis dieser Unterscheidung stellt sicher, dass asynchroner Code in Jupyter-Notebooks korrekt ausgeführt wird, und verhindert häufige Laufzeitfehler beim Experimentieren mit asynchronem Python.
# Steuern der Parallelität mit asynchronen Semaphoren
Externe APIs und Dienste erzwingen oft Ratenbegrenzungen, was die gleichzeitige Ausführung zu vieler Anfragen unsicher macht. Mit asynchronen Semaphoren können Sie steuern, wie viele Aufgaben gleichzeitig ausgeführt werden, und gleichzeitig von der asynchronen Ausführung profitieren.
Das Semaphor wird mit einem Restrict von zwei initialisiert, was bedeutet, dass nur zwei Aufgaben gleichzeitig den geschützten Bereich betreten können.
import asyncio
import time
semaphore = asyncio.Semaphore(2) # enable solely 2 duties at a timeDie Aufgabenfunktion stellt eine asynchrone Arbeitseinheit dar. Jede Aufgabe muss das Semaphor vor der Ausführung abrufen und wartet, wenn das Restrict erreicht ist, bis ein Steckplatz verfügbar wird.
Sobald sich die Aufgabe im Semaphor befindet, zeichnet sie ihre Startzeit auf, gibt eine Startnachricht aus und wartet auf einen nicht blockierenden Ruhezustand von zwei Sekunden, um einen E/A-gebundenen Vorgang zu simulieren. Nach Abschluss des Ruhezustands berechnet die Aufgabe ihre Ausführungszeit, gibt eine Abschlussmeldung aus und gibt das Semaphor frei.
async def job(task_id):
async with semaphore:
begin = time.perf_counter()
print(f"Job {task_id} began")
await asyncio.sleep(2)
elapsed = time.perf_counter() - begin
print(f"Job {task_id} completed in {elapsed:.2f} seconds")Der essential Die Funktion plant die gleichzeitige Ausführung von vier Aufgaben asyncio.collectaber das Semaphor stellt sicher, dass sie in zwei Wellen von zwei Aufgaben ausgeführt werden.
Endlich, asyncio.run startet die Ereignisschleife und führt das Programm aus, was zu einer Gesamtausführungszeit von etwa vier Sekunden führt.
async def essential():
begin = time.perf_counter()
await asyncio.collect(
job(1),
job(2),
job(3),
job(4),
)
whole = time.perf_counter() - begin
print(f"n(TOTAL WALL TIME) {whole:.2f} seconds")
asyncio.run(essential())Ausgabe:
- Aufgrund des Semaphor-Limits beginnen die Aufgaben 1 und 2 zuerst
- Die Aufgaben 3 und 4 warten, bis ein Slot frei wird
- Aufgaben werden in zwei Wellen ausgeführt, die jeweils zwei Sekunden dauern
- Die gesamte Wandzeit beträgt etwa vier Sekunden
Job 1 began
Job 2 began
Job 1 completed in 2.00 seconds
Job 2 completed in 2.00 seconds
Job 3 began
Job 4 began
Job 3 completed in 2.00 seconds
Job 4 completed in 2.00 seconds
(TOTAL WALL TIME) 4.00 secondsSemaphoren bieten eine effektive Möglichkeit, Parallelitätsbeschränkungen durchzusetzen und die Systemstabilität in asynchronen Produktionsanwendungen zu schützen.
# Abschließende Bemerkungen
Asynchrone Programmierung ist keine universelle Lösung. Es ist nicht für CPU-intensive Arbeitslasten wie maschinelles Lerntraining, Bildverarbeitung oder numerische Simulationen geeignet. Seine Stärke liegt in der Abwicklung von I/O-gebundenen Vorgängen, bei denen die Wartezeit die Ausführung dominiert.
Bei richtiger Anwendung verbessert die asynchrone Programmierung den Durchsatz, indem sie es Aufgaben ermöglicht, Fortschritte zu machen, während andere warten. Richtige Verwendung von await ist für die Parallelität unerlässlich, und asynchrone Muster sind besonders effektiv in API-gesteuerten und servicebasierten Systemen.
In Produktionsumgebungen sind die Kontrolle der Parallelität und die explizite Behandlung von Fehlern von entscheidender Bedeutung für die Erstellung zuverlässiger und skalierbarer asynchroner Python-Anwendungen.
Abid Ali Awan (@1abidaliawan) ist ein zertifizierter Datenwissenschaftler, der gerne Modelle für maschinelles Lernen erstellt. Derzeit konzentriert er sich auf die Erstellung von Inhalten und das Schreiben technischer Blogs zu maschinellem Lernen und Datenwissenschaftstechnologien. Abid verfügt über einen Grasp-Abschluss in Technologiemanagement und einen Bachelor-Abschluss in Telekommunikationstechnik. Seine Imaginative and prescient ist es, ein KI-Produkt mithilfe eines graphischen neuronalen Netzwerks für Schüler mit psychischen Erkrankungen zu entwickeln.