
Daten sind für moderne Geschäftsentscheidungen von wesentlicher Bedeutung. Viele Mitarbeiter sind mit SQL jedoch nicht vertraut. Dies schafft einen Engpass zwischen Fragen und Antworten. Ein Textual content-zu-SQL-System löst dieses Drawback direkt. Es übersetzt einfache Fragen in Datenbankabfragen. Dieser Artikel zeigt, wie Sie einen SQL -Generator erstellen. Wir werden den Ideen des Textual content-to-SQL-Engineering-Groups von Pinterest folgen. Sie lernen, wie man natürliche Sprache in SQL umwandelt. Wir werden auch erweiterte Techniken wie RAG für die Tischauswahl verwenden.
Pinterests Ansatz verstehen
Pinterest wollte Daten für alle zugänglich machen. Ihre Mitarbeiter brauchten Einblicke aus riesige Datensätze. Die meisten von ihnen waren nicht Sql Experten. Diese Herausforderung führte zur Erstellung der Textual content-zu-SQL-Plattform von Pinterest. Ihre Reise bietet eine großartige Roadmap für den Bau ähnlicher Werkzeuge.
Die erste Model
Ihr erstes System conflict unkompliziert. Ein Benutzer würde eine Frage stellen und auch die Datenbanktabellen auflisten, die er für related hielt. Das System würde dann eine SQL -Abfrage erzeugen.
Schauen wir uns seine Architektur genauer an:
Der Benutzer stellt eine analytische Frage und wählt die zu verwendenden Tabellen aus.
- Die relevanten Tabellenschemata werden aus dem Tischmetadatengeschäft abgerufen.
- Die Frage, ausgewählter SQL-Dialekt und Tabellenschemata werden in eine Eingabeaufforderung von Textual content zu SQL zusammengestellt.
- Die Eingabeaufforderung wird in die LLM eingespeist.
- Eine Streaming -Antwort wird generiert und dem Benutzer angezeigt.
Dieser Ansatz funktionierte, hatte aber einen großen Fehler. Benutzer hatten oft keine Ahnung, welche Tabellen ihre Antworten enthielten.
Die zweite Model
Um dies zu lösen, baute ihr Workforce ein intelligentlicheres System auf. Es verwendete eine Technik genannt Abrufgeneration (RAG). Anstatt den Benutzer nach Tabellen zu fragen, hat das System ihn automatisch gefunden. Es durchsuchte eine Sammlung von Tabellenbeschreibungen, um die relevantesten für die Frage zu finden. Diese Verwendung von Lappen für die Tischauswahl machte das Device viel benutzerfreundlicher.
- Ein Offline -Job wird eingesetzt, um einen Vektorindex der Zusammenfassungen und historischen Abfragen von Tabellen gegen sie zu generieren.
- Angenommen, der Benutzer gibt keine Tabellen an. In diesem Fall wird ihre Frage in Einbettungen umgewandelt, und eine Ähnlichkeitssuche wird gegen den Vektorindex durchgeführt, um die Spitze zu schließen N geeignete Tische.
- Die Oberseite N Tabellen werden zusammen mit dem Tabellenschema und der analytischen Frage in eine Eingabeaufforderung nach zusammengestellt Llm So wählen Sie die Oberseite aus Ok Relevanteste Tabellen.
- Die Oberseite Ok Tabellen werden zur Validierung oder Änderung an den Benutzer zurückgegeben.
- Der Normal-Textual content-zu-SQL-Prozess wird mit den vom Benutzer bestätigten Tabellen wieder aufgenommen.
Wir werden diesen leistungsstarken zweistufigen Ansatz replizieren.
Unser Plan: Eine vereinfachte Replikation
Mit dieser Anleitung können Sie einen SQL -Generator in zwei Teilen erstellen. Zunächst werden wir die Kernmotor erstellen, die die natürliche Sprache in SQL umwandelt. Zweitens werden wir die intelligente Funktionenfindungsfunktion hinzufügen.
- Das Kernsystem: Wir werden eine Basiskette bauen. Es nimmt eine Frage und eine Liste von Tabellennamen an, um eine SQL -Abfrage zu erstellen.
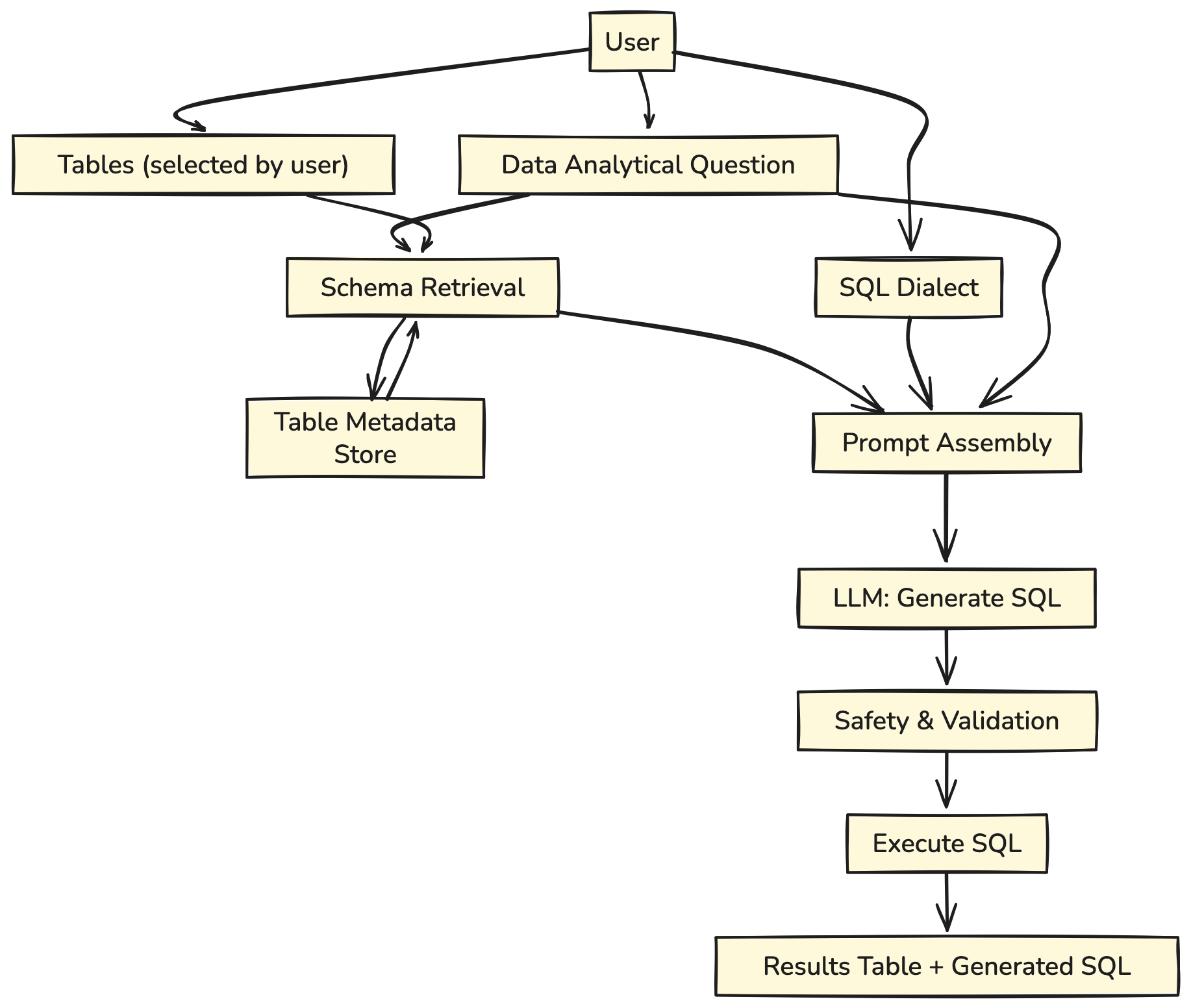
- Benutzereingabe: Bietet eine analytische Frage, ausgewählte Tabellen und einen SQL -Dialekt.
- Schema -Abruf: Das System holt relevante Tabellenschemata aus dem Metadatengeschäft.
- Schnellversammlung: Kombiniert Frage, Schemata und Dialekt in eine Eingabeaufforderung.
- LLM -Era: Das Modell gibt die SQL -Abfrage aus.
- Validierung und Ausführung: Die Abfrage wird auf Sicherheit überprüft, ausgeführt und die Ergebnisse werden zurückgegeben.
- Das Rag-verbesserte System: Wir werden einen Retriever hinzufügen. Diese Komponente schlägt automatisch die richtigen Tabellen für jede Frage vor.
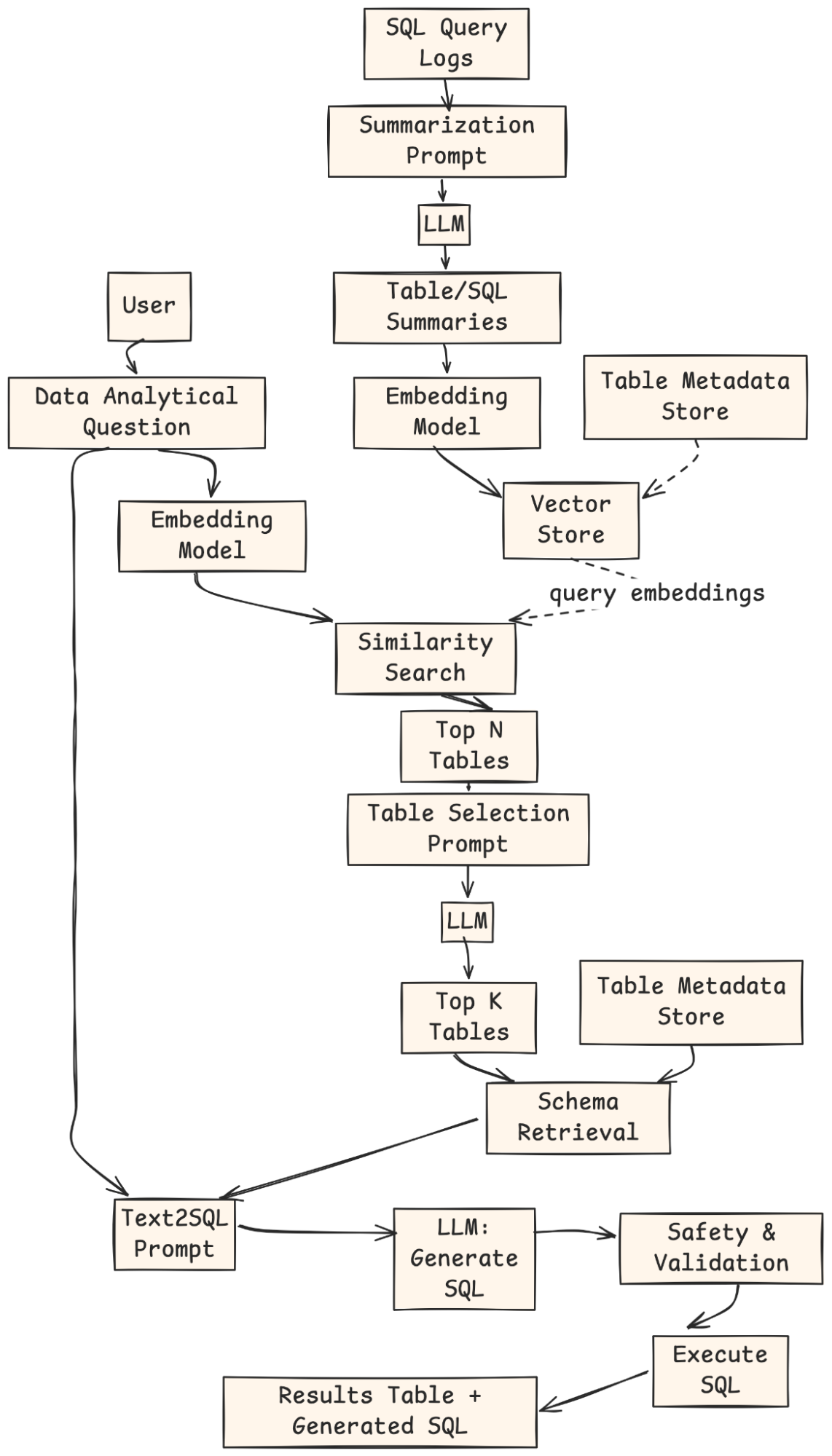
- Offline -Indexierung: SQL -Abfrageprotokolle werden durch ein LLM zusammengefasst, eingebettet und in einem Vektorindex mit Metadaten gespeichert.
- Benutzerabfrage: Der Benutzer stellt eine natürliche analytische Frage an.
- Abruf: Die Frage ist eingebettet, gegen den Vektor Retailer abgestimmt, und Prime-n-Kandidatentische werden zurückgegeben.
- Tischauswahl: Ein LLM rängt und wählt die am besten relevanten Tabellen aus.
- Schema -Abruf & Aufforderung: Das System holt Schemata für diese Tabellen ab und erstellt eine Eingabeaufforderung von Textual content zu SQL.
- SQL -Era: Ein LLM generiert die SQL -Abfrage.
- Validierung und Ausführung: Die Abfrage wird überprüft, ausgeführt und die Ergebnisse + SQL werden an den Benutzer zurückgegeben.
Wir werden verwenden PythonAnwesend Langchainund öffnen Sie dieses Textual content-zu-SQL-System. Eine SQLite-Datenbank in Reminiscence fungiert als Datenquelle.
Praktische Anleitung: Erstellen Sie einen eigenen SQL-Generator
Beginnen wir mit dem Aufbau unseres Techniques. Befolgen Sie diese Schritte, um einen funktionierenden Prototyp zu erstellen.
Schritt 1: Einrichten Ihrer Umgebung
Zunächst installieren wir die notwendigen Python -Bibliotheken. Langchain hilft uns, Komponenten zu verbinden. Langchain-Openai stellt die Verbindung zum LLM her. Faiss hilft dabei, unseren Retriever zu erstellen, und Pandas zeigt Daten intestine an.
!pip set up -qU langchain langchain-openai faiss-cpu pandas langchain_communityAls nächstes müssen Sie Ihren OpenAI -API -Schlüssel konfigurieren. Mit diesem Schlüssel kann unsere Anwendung die Modelle von OpenAI verwenden.
import os
from getpass import getpass
OPENAI_API_KEY = getpass("Enter your OpenAI API key: ")
os.environ("OPENAI_API_KEY") = OPENAI_API_KEYSchritt 2: Simulation der Datenbank
Ein Textual content-zu-SQL-System benötigt eine Datenbank zur Abfrage. Für diese Demo erstellen wir eine einfache SQLite-Datenbank in Reminiscence. Es enthält drei Tabellen: Benutzer, Stifte und Boards. Dieses Setup ahmt eine grundlegende Model der Datenstruktur von Pinterest nach.
import sqlite3
import pandas as pd
# Create a connection to an in-memory SQLite database
conn = sqlite3.join(':reminiscence:')
cursor = conn.cursor()
# Create tables
cursor.execute('''
CREATE TABLE customers (
user_id INTEGER PRIMARY KEY,
username TEXT NOT NULL,
join_date DATE NOT NULL,
nation TEXT
)
''')
cursor.execute('''
CREATE TABLE pins (
pin_id INTEGER PRIMARY KEY,
user_id INTEGER,
board_id INTEGER,
image_url TEXT,
description TEXT,
created_at DATETIME,
FOREIGN KEY(user_id) REFERENCES customers(user_id),
FOREIGN KEY(board_id) REFERENCES boards(board_id)
)
''')
cursor.execute('''
CREATE TABLE boards (
board_id INTEGER PRIMARY KEY,
user_id INTEGER,
board_name TEXT NOT NULL,
class TEXT,
FOREIGN KEY(user_id) REFERENCES customers(user_id)
)
''')
# Insert pattern information
cursor.execute("INSERT INTO customers (user_id, username, join_date, nation) VALUES (1, 'alice', '2023-01-15', 'USA')")
cursor.execute("INSERT INTO customers (user_id, username, join_date, nation) VALUES (2, 'bob', '2023-02-20', 'Canada')")
cursor.execute("INSERT INTO boards (board_id, user_id, board_name, class) VALUES (101, 1, 'DIY Crafts', 'DIY')")
cursor.execute("INSERT INTO boards (board_id, user_id, board_name, class) VALUES (102, 1, 'Journey Goals', 'Journey')")
cursor.execute("INSERT INTO pins (pin_id, user_id, board_id, description, created_at) VALUES (1001, 1, 101, 'Handmade birthday card', '2024-03-10 10:00:00')")
cursor.execute("INSERT INTO pins (pin_id, user_id, board_id, description, created_at) VALUES (1002, 2, 102, 'Eiffel Tower at evening', '2024-05-15 18:30:00')")
cursor.execute("INSERT INTO pins (pin_id, user_id, board_id, description, created_at) VALUES (1003, 1, 101, 'Knitted scarf sample', '2024-06-01 12:00:00')")
conn.commit()
print("Database created and populated efficiently.")Ausgabe:

Schritt 3: Erstellen Sie die Kernkette von Textual content-zu-SQL-Kette
Das Sprachmodell kann unsere Datenbank nicht direkt sehen. Es muss die Tischstrukturen oder Schemas kennen. Wir erstellen eine Funktion, um die zu erhalten CREATE TABLE Aussagen. Diese Informationen geben dem Modell über Spalten, Datentypen und Schlüssel mit.
def get_table_schemas(conn, table_names):
"""Fetches the CREATE TABLE assertion for an inventory of tables."""
schemas = ()
cursor = conn.cursor() # Get cursor from the handed connection
for table_name in table_names:
question = f"SELECT sql FROM sqlite_master WHERE sort="desk" AND title="{table_name}";"
cursor.execute(question)
consequence = cursor.fetchone()
if consequence:
schemas.append(consequence(0))
return "nn".be part of(schemas)
# Instance utilization
sample_schemas = get_table_schemas(conn, ('customers', 'pins'))
print(sample_schemas)Ausgabe:
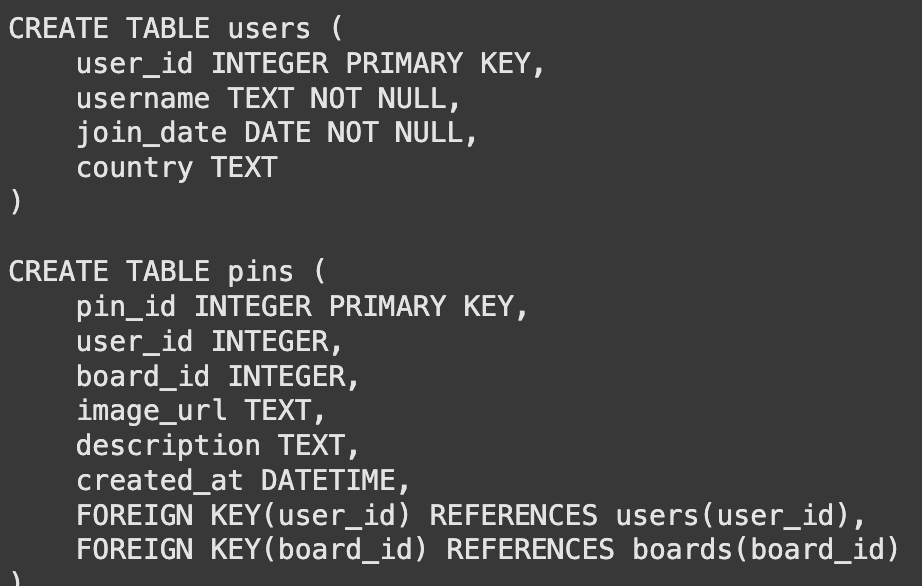
Mit der Schema -Funktion bauen wir unsere erste Kette auf. Eine schnelle Vorlage weist das Modell für seine Aufgabe an. Es kombiniert die Schemas und die Frage des Benutzers. Anschließend verbinden wir diese Eingabeaufforderung an das Modell.
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
import sqlite3 # Import sqlite3
template = """
You're a grasp SQL skilled. Primarily based on the offered desk schema and a consumer's query, write a syntactically appropriate SQLite SQL question.
Solely return the SQL question and nothing else.
Right here is the database schema:
{schema}
Right here is the consumer's query:
{query}
"""
immediate = ChatPromptTemplate.from_template(template)
llm = ChatOpenAI(mannequin="gpt-4.1-mini", temperature=0)
sql_chain = immediate | llm | StrOutputParser()
Let's take a look at our chain with a query the place we explicitly present the desk names.
user_question = "What number of pins has alice created?"
table_names_provided = ("customers", "pins")
# Retrieve the schema in the principle thread earlier than invoking the chain
schema = get_table_schemas(conn, table_names_provided)
# Go the schema on to the chain
generated_sql = sql_chain.invoke({"schema": schema, "table_names": table_names_provided, "query": user_question})
print("Person Query:", user_question)
print("Generated SQL:", generated_sql)
# Clear the generated SQL by eradicating markdown code block syntax
cleaned_sql = generated_sql.strip()
if cleaned_sql.startswith("```sql"):
cleaned_sql = cleaned_sql(len("```sql"):).strip()
if cleaned_sql.endswith("```"):
cleaned_sql = cleaned_sql(:-len("```")).strip()
print("Cleaned SQL:", cleaned_sql)
# Let's run the generated SQL to confirm it really works
attempt:
result_df = pd.read_sql_query(cleaned_sql, conn)
show(result_df)
besides Exception as e:
print(f"Error executing SQL question: {e}")Ausgabe:
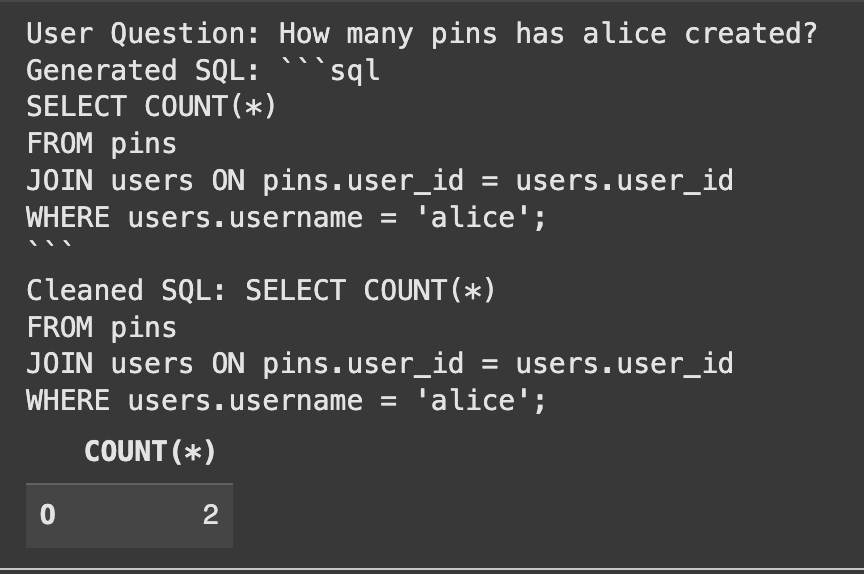
Das System hat die SQL korrekt erzeugt und die richtige Antwort gefunden.
Schritt 4: Verbesserung mit Lappen für die Tischauswahl
Unser Kernsystem funktioniert intestine, erfordert jedoch, dass Benutzer Tabellennamen kennen. Dies ist das genaue Drawback von Pinterests Textual content-zu-SQL-Workforce gelöst. Wir werden jetzt Lappen für die Tischauswahl implementieren. Wir beginnen mit der Übersicht über einfache, natürliche Sprachzusammenfassungen für jede Tabelle. Diese Zusammenfassungen erfassen die Bedeutung des Inhalts jeder Tabelle.
table_summaries = {
"customers": "Comprises details about particular person customers, together with their username, be part of date, and nation of origin.",
"pins": "Comprises information about particular person pins, linking to the consumer who created them and the board they belong to. Consists of descriptions and creation timestamps.",
"boards": "Shops details about user-created boards, together with the board's title, class, and the consumer who owns it."
}Als nächstes erstellen wir einen Vektor Retailer. Dieses Device wandelt unsere Zusammenfassungen in numerische Darstellungen (Einbettungen) um. Es ermöglicht uns, die relevantesten Tabellenzusammenfassungen für die Frage eines Benutzers durch eine Ähnlichkeitssuche zu finden.
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.schema import Doc
# Create LangChain Doc objects for every abstract
summary_docs = (
Doc(page_content=abstract, metadata={"table_name": table_name})
for table_name, abstract in table_summaries.gadgets()
)
embeddings = OpenAIEmbeddings()
vector_store = FAISS.from_documents(summary_docs, embeddings)
retriever = vector_store.as_retriever()
print("Vector retailer created efficiently.")Schritt 5: Kombinieren Sie alles zu einer Lappenkette
Wir erstellen jetzt die endgültige, intelligente Kette. Diese Kette automatisiert den gesamten Prozess. Es dauert eine Frage, verwendet den Retriever, um relevante Tabellen zu finden, ihre Schemata abzurufen und dann alles an unsere weitergibt sql_chain.
def get_table_names_from_docs(docs):
"""Extracts desk names from the metadata of retrieved paperwork."""
return (doc.metadata('table_name') for doc in docs)
# We'd like a option to get schema utilizing desk names and the connection throughout the chain
# Use the thread-safe perform that recreates the database for every name
def get_schema_for_rag(x):
table_names = get_table_names_from_docs(x('table_docs'))
# Name the thread-safe perform to get schemas
schema = get_table_schemas(conn, table_names)
return {"query": x('query'), "table_names": table_names, "schema": schema}
full_rag_chain = (
RunnablePassthrough.assign(
table_docs=lambda x: retriever.invoke(x('query'))
)
| RunnableLambda(get_schema_for_rag) # Use RunnableLambda to name the schema fetching perform
| sql_chain # Go the dictionary with query, table_names, and schema to sql_chain
)
Let's take a look at the whole system. We ask a query with out mentioning any tables. The system ought to deal with all the pieces.
user_question_no_tables = "Present me all of the boards created by customers from the USA."
# Go the consumer query inside a dictionary
final_sql = full_rag_chain.invoke({"query": user_question_no_tables})
print("Person Query:", user_question_no_tables)
print("Generated SQL:", final_sql)
# Clear the generated SQL by eradicating markdown code block syntax, being extra strong
cleaned_sql = final_sql.strip()
if cleaned_sql.startswith("```sql"):
cleaned_sql = cleaned_sql(len("```sql"):).strip()
if cleaned_sql.endswith("```"):
cleaned_sql = cleaned_sql(:-len("```")).strip()
# Additionally deal with instances the place there could be main/trailing newlines after cleansing
cleaned_sql = cleaned_sql.strip()
print("Cleaned SQL:", cleaned_sql)
# Confirm the generated SQL
attempt:
result_df = pd.read_sql_query(cleaned_sql, conn)
show(result_df)
besides Exception as e:
print(f"Error executing SQL question: {e}")Ausgabe:
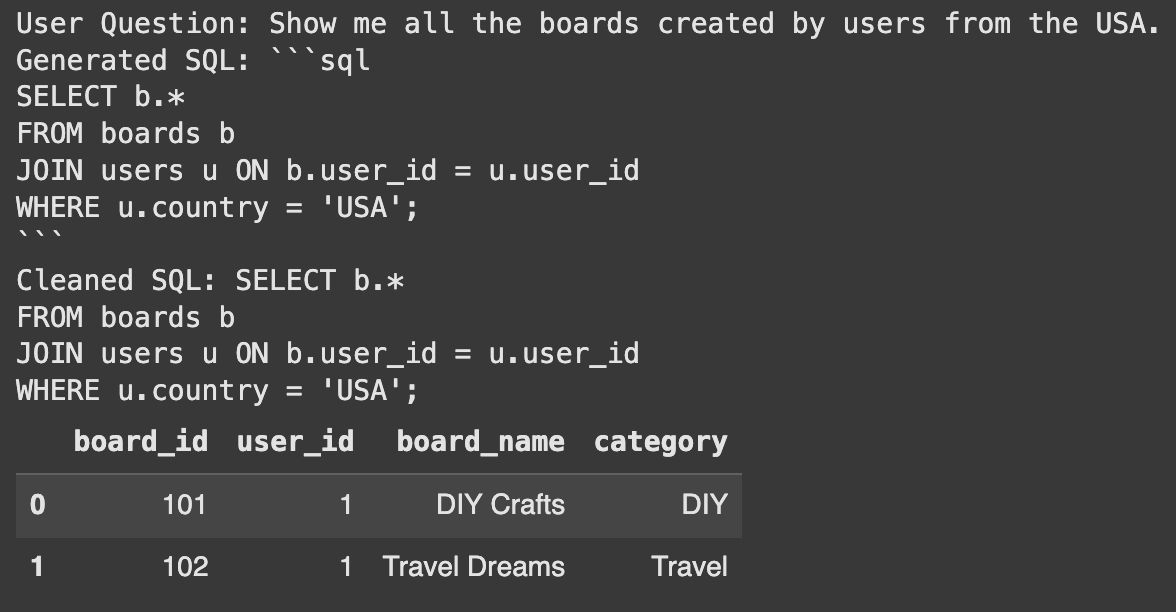
Erfolg! Das System identifizierte automatisch die Benutzer- und Board -Tabellen. Anschließend wurde die richtige Anfrage generiert, um die Frage zu beantworten. Dies zeigt die Kraft der Verwendung von Lappen für die Tabellenauswahl.
Abschluss
Wir haben erfolgreich einen Prototyp erstellt, der zeigt, wie ein SQL -Generator erstellt wird. Um dies in eine Produktionsumgebung zu bewegen, ist mehr Schritte erforderlich. Sie können den Tabellenübersichtsprozess automatisieren. Sie können auch historische Anfragen in den Vektor Retailer einbeziehen, um die Genauigkeit zu verbessern. Dies folgt dem Weg des Textual content-to-SQL-Groups von Pinterest. Diese Stiftung bietet einen klaren Weg zum Erstellen eines leistungsstarken Datenwerkzeugs.
Häufig gestellte Fragen
A. Textual content-to-SQL-System übersetzt Fragen, die in einfacher Sprache (wie Englisch) in SQL-Datenbankabfragen geschrieben wurden. Auf diese Weise können nicht-technische Benutzer Daten erhalten, ohne Code zu schreiben.
A. RAG hilft dem System, automatisch die relevantesten Datenbanktabellen für die Frage eines Benutzers zu finden. Dadurch wird die Notwendigkeit von Benutzern beseitigt, die Datenbankstruktur zu kennen.
A. Langchain ist ein Rahmen für die Entwicklung von Anwendungen, die von Sprachmodellen betrieben werden. Es hilft, verschiedene Komponenten wie Eingabeaufforderungen, Modelle und Wiederholungen in eine einzelne Kette zu verbinden.
Harsh Mishra ist ein KI/ML -Ingenieur, der mehr Zeit damit verbringt, mit großen Sprachmodellen zu sprechen als mit tatsächlichen Menschen. Leidenschaft über Genai, NLP und Maschinen schlauer (damit sie ihn noch nicht ersetzen). Wenn er Fashions nicht optimiert, optimiert er wahrscheinlich seine Kaffeeaufnahme. 🚀☕
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.