
Was wäre, wenn Sie für 100 US-Greenback eine funktionierende ChatGPT-ähnliche KI entwickeln könnten? Der neue Nanochat von Andrej Karpathy sagt Ihnen genau das! Das am 13. Oktober 2025 gestartete Nanochat-Projekt von Karpathy ist ein Open-Supply-LLM, das in etwa 8.000 PyTorch-Zeilen codiert ist. Es bietet Ihnen eine unkomplizierte Roadmap, wie Sie ein Sprachmodell von Grund auf trainieren und in wenigen Stunden Ihre eigene personal KI erstellen können. In diesem Artikel sprechen wir über den neu veröffentlichten Nanochat und wie man ihn Schritt für Schritt richtig für das Coaching einrichtet.
Was ist Nanochat?
Das Nanochat-Repository bietet eine Full-Stack-Pipeline zum Trainieren eines minimalen ChatGPT-Klons. Es kümmert sich um alles von der Tokenisierung bis zur Finish-Net-Benutzeroberfläche. Dieses System ist ein Nachfolger des bisherigen nanoGPT. Es führt wichtige Funktionen wie Supervised High-quality-Tuning (SFT), Reinforcement Studying (RL) und verbesserte Inferenz ein.
Hauptmerkmale
Das Projekt besteht aus einer Reihe wichtiger Komponenten. Es enthält einen neuen, von Rust entwickelten Tokenizer für hohe Leistung. Die Trainingspipeline nutzt Qualitätsdaten wie FineWeb-EDU für das Vortraining. Es nutzt auch spezielle Daten wie SmolTalk und GSM8K für die Feinabstimmung nach dem Coaching. Aus Sicherheitsgründen kann das Modell Code in einer Python-Sandbox ausführen.
Das Projekt passt intestine zu Ihrem Finances. Das grundlegende „Speedrun“-Modell kostet etwa 100 US-Greenback und trainiert vier Stunden lang. Sie können auch ein robusteres Modell für etwa 1.000 US-Greenback und etwa 42 Stunden Schulung entwickeln.
Leistung
Die Leistung steigt mit der Trainingszeit.
- 4 Stunden: Der Schnelldurchlauf bietet Ihnen ein einfaches Konversationsmodell. Es kann einfache Gedichte verfassen oder Konzepte wie die Rayleigh-Streuung beschreiben.
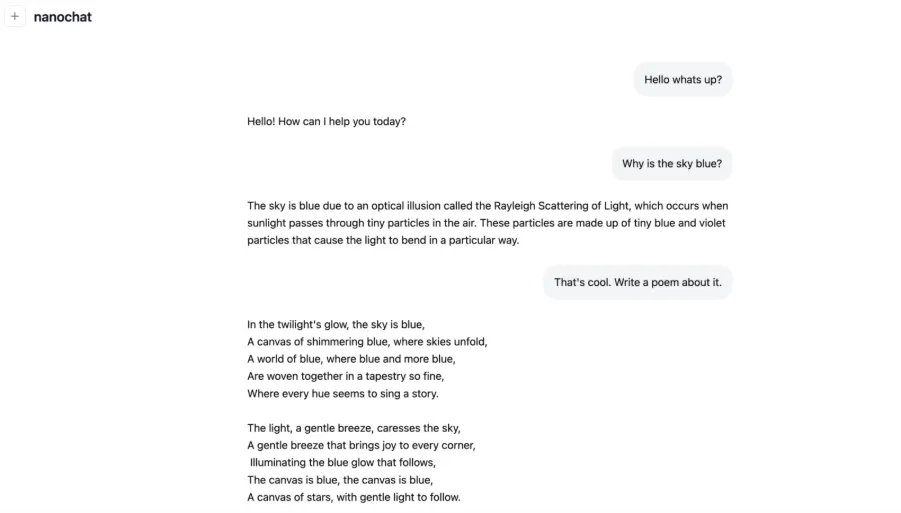
Einige der zusammenfassenden Messwerte wurden durch den 100-Greenback-Speedrun über 4 Stunden ermittelt.
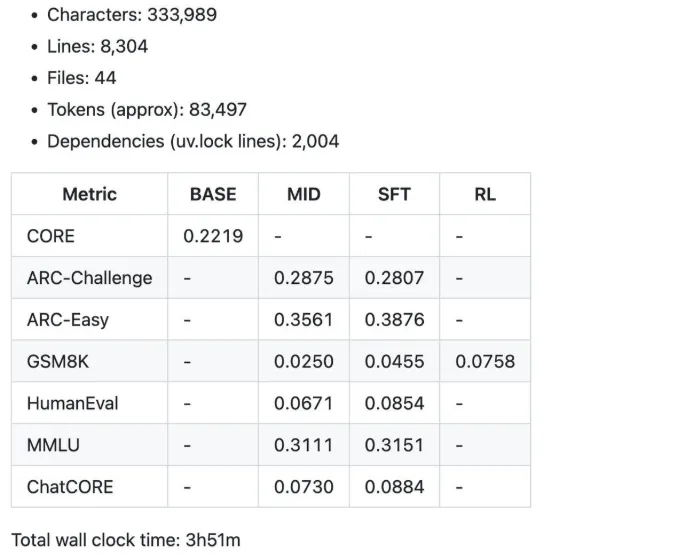
- 12 Stunden: Das Modell beginnt, GPT-2 beim CORE-Benchmark zu übertreffen.
- 24 Stunden: Es erzielt ordentliche Werte, z. B. 40 % bei MMLU und 70 % bei ARC-Simple.
Das primäre Bildungsziel des Nanochat-Projekts besteht darin, eine einfache, hackbare Foundation bereitzustellen. Dies macht es zu einer großartigen Ressource für Studenten, Forscher und KI-Hobbyisten.
Voraussetzungen und Einrichtung
Bevor Sie beginnen, müssen Sie Ihre {Hardware} und Software program vorbereiten. Mit den richtigen Werkzeugen ist das ganz einfach.
Hardwareanforderungen
Das Projekt lässt sich am besten mit einem 8xH100-GPU-Knoten bewältigen. Diese sind bei Anbietern wie Lambda GPU Cloud für etwa 24 US-Greenback professional Stunde erhältlich. Sie können auch eine einzelne GPU mit Gradientenakkumulation verwenden. Dies ist eine langsamere Methode, aber achtmal langsamer.
Software program
Sie benötigen neben PyTorch eine Normal-Python-Umgebung. Das Projekt stützt sich auf die UV Paketmanager zur Verwaltung von Abhängigkeiten. Außerdem muss Git installiert sein, um das Repository zu klonen. Als optionale Choice können Sie Gewichtungen und Gewichtungen zur Protokollierung Ihrer Trainingsläufe hinzufügen.
Erste Schritte
Das Klonen des offiziellen Repositorys steht an erster Stelle:
git clone (e-mail protected):karpathy/nanochat.git Zweitens wechseln Sie in das Projektverzeichnis, additionally nanochat, und installieren Sie die Abhängigkeiten.
cd nanochat Erstellen Sie abschließend Ihre Cloud-GPU-Instanz und verbinden Sie sie mit ihr, um mit dem Coaching zu beginnen.
Leitfaden zum Trainieren Ihres eigenen ChatGPT-Klons
Im Folgenden finden Sie eine Schritt-für-Schritt-Anleitung zum Trainieren Ihres allerersten Modells. Wenn Sie diese Schritte genau beachten, erhalten Sie ein funktionierendes LLM. Die offizielle Komplettlösung im Repository enthält weitere Informationen.
Schritt 1: Umgebungsvorbereitung
Starten Sie zunächst Ihren 8xH100-Knoten. Sobald Sie fertig sind, installieren Sie den UV-Paketmanager mit dem mitgelieferten Skript. Es ist sinnvoll, Dinge mit langer Laufzeit in einer Bildschirmsitzung zu haben. Dadurch läuft das Coaching auch dann weiter, wenn Sie die Verbindung trennen.
# set up uv (if not already put in)
command -v uv &> /dev/null || curl -LsSf https://astral.sh/uv/set up.sh | sh
# create a .venv native digital setting (if it does not exist)
( -d ".venv" ) || uv venv
# set up the repo dependencies
uv sync
# activate venv in order that `python` makes use of the mission's venv as a substitute of system python
supply .venv/bin/activate Schritt 2: Daten- und Tokenizer-Einrichtung
Zuerst müssen wir Rust/Cargo installieren, damit wir unseren benutzerdefinierten Rust-Tokenizer kompilieren können.
# Set up Rust / Cargo
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- -y
supply "$HOME/.cargo/env"
# Construct the rustbpe Tokenizer
uv run maturin develop --release --manifest-path rustbpe/Cargo.toml Bei den Vortrainingsdaten handelt es sich lediglich um den Textual content vieler Webseiten, und für diesen Teil verwenden wir den FineWeb-EDU Datensatz. Karpathy empfiehlt jedoch die Verwendung der folgenden Model.
https://huggingface.co/datasets/karpathy/fineweb-edu-100b-shuffle
python -m nanochat.dataset -n 240 Nach dem Herunterladen trainieren Sie den Rust-Tokenizer auf einem großen Textkorpus. Das Skript sorgt dafür, dass dieser Schritt schnell geht. Es sollte auf ein Komprimierungsverhältnis von etwa 4,8 zu 1 komprimiert werden.
python -m scripts.tok_train --max_chars=2000000000
python -m scripts.tok_eval Schritt 3: Vortraining
Jetzt müssen Sie das Evaluierungsdatenpaket herunterladen. Hier befinden sich die Testdatensätze für die Leistung des Modells.
curl -L -o eval_bundle.zip https://karpathy-public.s3.us-west-2.amazonaws.com/eval_bundle.zip
unzip -q eval_bundle.zip
rm eval_bundle.zip
mv eval_bundle "$HOME/.cache/nanochat" Auch Setup wandb um während des Trainings schöne Handlungsstränge zu sehen. UV bereits installiert wandb Für uns oben, aber Sie müssen noch ein Konto einrichten und sich anmelden mit:
wandb login Jetzt können Sie das Haupt-Vortrainingsskript starten. Führen Sie es mit dem Befehl „torchrun“ aus, um alle acht GPUs zu nutzen. Der Prozess trainiert das Modell anhand einfacher Sprachmuster aus dem FineWeb-EDU-Korpus. Der Speedrun dieser Etappe dauert etwa zwei bis drei Stunden. Dies ist ein wesentlicher Teil des Prozesses zum Trainieren eines Sprachmodells.
torchrun --standalone --nproc_per_node=8 -m scripts.base_train -- --depth=20 Wir initiieren das Coaching auf 8 GPUs mithilfe des Skripts scripts/base_train.py. Das Modell ist ein 20-Schicht-Transformator. Jede GPU verarbeitet 32 Sequenzen von 2048 Token professional Vorwärts- und Rückwärtsdurchlauf, was insgesamt 32 × 2048 = 524.288 (≈0,5 Millionen) verarbeitete Token professional Optimierungsschritt ergibt.
Wenn Weights & Biases (wandb) konfiguriert ist, können Sie das Flag –run=speedrun hinzufügen, um einen Laufnamen zuzuweisen und die Protokollierung zu aktivieren.
Wenn das Coaching beginnt, sehen Sie eine Ausgabe ähnlich der folgenden (hier aus Gründen der Übersichtlichkeit vereinfacht):
Schritt 4: Midtraining und SFT
Nach dem Vortraining fahren Sie mit dem Mitteltraining fort. Midtraining wendet das an SmolTalk Datensatz, um dem Modell mehr Konversationsleistung zu verleihen. Anschließend führen Sie eine überwachte Feinabstimmung (SFT) für Daten wie GSM8K durch. Dies hilft dem Modell dabei, zu lernen, Anweisungen auszuführen und Probleme zu lösen.
Wir können das mittlere Coaching wie folgt beginnen: Dieser Lauf dauert nur etwa 8 Minuten, viel kürzer als vor dem Coaching mit ca. 3 Stunden.
torchrun --standalone --nproc_per_node=8 -m scripts.mid_train Nach der Trainingsmitte kommt das Feinabstimmung Bühne. Diese Part beinhaltet eine weitere Runde der Feinabstimmung der Konversationsdaten, wobei der Schwerpunkt jedoch darauf liegt, nur die qualitativ hochwertigsten und am besten kuratierten Beispiele auszuwählen. In dieser Part werden auch sicherheitsorientierte Anpassungen vorgenommen, beispielsweise das Coaching des Modells hinsichtlich angemessener Ablehnungsverhalten bei sensiblen oder eingeschränkten Abfragen. Dies dauert wiederum nur etwa 7 Minuten.
torchrun --standalone --nproc_per_node=8 -m scripts.chat_sft Schritt 5: Optionaler RL
Das Open-Supply-LLM von Nanochat bietet auch vorläufige Unterstützung für verstärktes Lernen. Sie können eine Technik namens GRPO für den GSM8K-Datensatz ausführen. Dies ist ein optionaler Vorgang und kann eine weitere Stunde dauern. Überprüfen Sie, ob Karpathy sagte, dass die RL-Unterstützung noch in den Kinderschuhen steckt.
torchrun --standalone --nproc_per_node=8 -m scripts.chat_rl Schritt 6: Inferenz und Benutzeroberfläche
Nachdem das Coaching abgeschlossen ist, können Sie nun das Inferenzskript ausführen. Dadurch können Sie über eine Net-Benutzeroberfläche oder eine Befehlszeilenschnittstelle mit Ihrem Modell kommunizieren. Versuchen Sie es mit einigen Beispielen wie „Warum ist der Himmel blau?“ um deine Schöpfung zu erleben.
python -m scripts.chat_cli (for Command line window) ODER
python -m scripts.chat_web. (for Net UI) Das chat_web-Skript bedient die Engine mithilfe von FastAPI. Stellen Sie sicher, dass Sie korrekt darauf zugreifen, z. B. verwenden Sie bei Lambda die öffentliche IP des Knotens, auf dem Sie sich befinden, gefolgt vom Port, additionally zum Beispiel http://209.20.xxx.xxx:8000/ usw.
Schritt 7: Überprüfen Sie die Ergebnisse
Testen Sie es nun mit der Weboberfläche über den Hyperlink, auf dem der Nanochat gehostet wird.
Schauen Sie sich zum Schluss die an bericht.md im Repository. Es verfügt über einige wichtige Kennzahlen für Ihr Modell, wie z. B. den CORE-Rating und die GSM8K-Genauigkeit. Der Foundation-Speedrun kostet etwa 92,40 $ und erfordert etwas weniger als vier Stunden Arbeit.
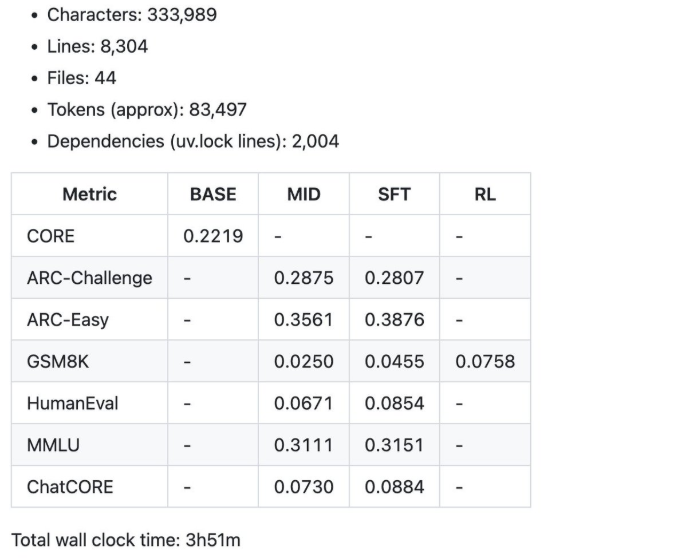
Hinweis: Ich habe den Code und die Schritte von Andrej Karapathys Nano-Chat GitHub übernommen. Die vollständige Dokumentation finden Sie hier Hier. Was ich oben vorgestellt habe, ist eine einfachere und kürzere Model.
Anpassen und Skalieren
Der Speedrun ist ein hervorragender Ausgangspunkt. Von diesem Punkt an können Sie das Modell weiter anpassen. Dies ist einer der bedeutendsten Vorteile der Nanochat-Veröffentlichung von Karpathy.
Tuning-Optionen
Sie können die Tiefe des Modells anpassen, um die Leistung zu verbessern. Mit dem --depth=26 Nehmen wir an, Sie betreten einen stärkeren 300-Greenback-Bereich. Sie können auch versuchen, andere Datensätze zu verwenden oder Trainingshyperparameter zu ändern.
Skalierung
Das Repository gibt einen Wert von 1.000 $ an. Dies erfordert einen verlängerten Trainingslauf von ca. 41,6 Stunden. Es ergibt ein Modell mit verbesserter Kohärenz und höheren Benchmark-Ergebnissen. Wenn Sie mit VRAM-Einschränkungen konfrontiert sind, versuchen Sie, diese zu senken --device_batch_size Einstellung.
Personalisierungsherausforderungen
Andere können das Modell anhand personenbezogener Daten verfeinern. Karpathy rät davon ab, da dies zu „Slop“ führen kann. Eine bessere Möglichkeit, personenbezogene Daten zu nutzen, ist Retrieval-Augmented Era (RAG) über Instruments wie NotebookLM.
Abschluss
Das Nanochat-Projekt ermöglicht sowohl Forschern als auch Anfängern. Es bietet eine kostengünstige und einfache Möglichkeit, ein starkes Open-Supply-LLM zu trainieren. Mit einem begrenzten Finances und einem offenen Wochenende können Sie von der Einrichtung bis zur Bereitstellung gehen. Verwenden Sie dieses Tutorial, um Ihr eigenes ChatGPT zu trainieren, das Nanochat-Repository auszuprobieren und am Group-Discussion board teilzunehmen, um zu helfen. Hier beginnt Ihr Abenteuer, ein Sprachmodell zu trainieren.
Häufig gestellte Fragen
A. Nanochat ist eine Open-Supply-PyTorch-Initiative von Andrej Karpathy. Es bietet eine Finish-to-Finish-Pipeline, um ein LLM im ChatGPT-Stil kostengünstig von Grund auf zu trainieren.
A. Das Trainieren eines Basismodells kostet etwa 100 US-Greenback und dauert vier Stunden. Leistungsstärkere Modelle können mit Budgets von 300 bis 1.000 US-Greenback und längerer Trainingsdauer trainiert werden.
A. Die empfohlene Konfiguration ist ein 8xH100-GPU-Knoten, den Sie von Cloud-Anbietern leasen können. Es ist möglich, eine einzelne GPU zu verwenden, diese ist jedoch wesentlich langsamer.
Harsh Mishra ist ein KI/ML-Ingenieur, der mehr Zeit damit verbringt, mit großen Sprachmodellen zu sprechen als mit echten Menschen. Leidenschaftlich für GenAI, NLP und die intelligentere Entwicklung von Maschinen (damit sie ihn noch nicht ersetzen). Wenn er nicht gerade Modelle optimiert, optimiert er wahrscheinlich seinen Kaffeekonsum. 🚀☕
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.