Google hat gerade seinen neuen agentenbasierten Webbrowser von Google DeepMind vorgestellt, der auf Gemini 2.5 Professional basiert. Basierend auf der Gemini-API kann es Net- und App-Schnittstellen „sehen“ und mit ihnen interagieren: Klicken, Tippen und Scrollen wie ein Mensch. Dieses neue KI-Webautomatisierungsmodell schließt die Lücke zwischen Verstehen und Handeln. In diesem Artikel werden wir die wichtigsten Funktionen von Gemini Laptop Use, seine Fähigkeiten und die Integration in Ihr System untersuchen Agentische KI-Workflows.
Was ist Gemini 2.5 Computernutzung?
Gemini 2.5 Laptop Use ist ein KI-Assistent, der einen Browser mithilfe natürlicher Sprache steuern kann. Sie beschreiben ein Ziel und es führt die Schritte aus, die zu seiner Verwirklichung erforderlich sind. Basierend auf dem neuen computer_use-Instrument in der Gemini-API analysiert es Screenshots einer Webseite oder App und generiert dann Aktionen wie „Klicken“, „Eingeben“ oder „Scrollen“. Ein Consumer wie Playwright führt diese Aktionen aus und gibt den nächsten Bildschirm zurück, bis die Aufgabe erledigt ist.
Das Modell interpretiert Schaltflächen, Textfelder und andere Elemente der Benutzeroberfläche, um zu entscheiden, wie es vorgehen soll. Im Rahmen Gemini 2.5 Professionalverfügt es über ein starkes visuelles Denken, das es ihm ermöglicht, komplexe Aufgaben auf dem Bildschirm mit minimalem menschlichen Aufwand zu erledigen. Derzeit konzentriert es sich auf Browserumgebungen und steuert keine Desktop-Apps außerhalb des Browsers.
Schlüsselfunktionen
- Automatisieren Sie die Dateneingabe und das Ausfüllen von Formularen auf Web sites. Der Agent wird in der Lage sein, Felder zu finden, Textual content einzugeben und ggf. Formulare einzureichen.
- Führen Sie Exams von Webanwendungen und Benutzerflüssen durch, indem Sie auf Seiten klicken, Ereignisse auslösen und sicherstellen, dass Elemente korrekt angezeigt werden.
- Führen Sie Recherchen auf mehreren Web sites durch. Es kann beispielsweise Informationen zu Produkten, Preisen oder Bewertungen auf mehreren E-Commerce-Seiten sammeln und die Ergebnisse zusammenfassen.
Wie greife ich auf die Computernutzung von Gemini 2.5 zu?
Die experimentellen Funktionen von Gemini 2.5 Laptop Use sind jetzt für jeden Entwickler zum Spielen öffentlich verfügbar. Entwickler müssen sich lediglich über für die Gemini-API anmelden AI Studio oder Vertex AI und fordern Sie dann Zugriff auf das Computernutzungsmodell an. Google stellt Dokumentation, ausführbare Codebeispiele und Referenzimplementierungen bereit, die Sie ausprobieren können. Die Gemini-API-Dokumente bieten beispielsweise ein Beispiel für die vierstufige Agentenschleife, komplett mit Beispielen in Python unter Verwendung von Google Cloud GenAI SDK und Dramatiker.
Sie würden hierfür entweder eine Browser-Automatisierungsumgebung wie Playwright einrichten und die folgenden Schritte ausführen:
- Melden Sie sich über AI Studio oder Vertex AI für die Gemini-API an.
- Fordern Sie Zugriff auf das Computernutzungsmodell an.
- Sehen Sie sich die Dokumentation von Google, ausführbare Codebeispiele und Referenzimplementierungen an.
Als Beispiel gibt es ein Beispiel für eine Agentenschleife, bei der vier Schritte in Python verwendet werden, die von Google mit dem GenAI SDK und Playwright bereitgestellt werden, um den Browser zu automatisieren.
Lesen Sie auch: Wie kann ich auf die Gemini-API zugreifen und sie verwenden?
Einrichten der Umgebung
Hier ist das allgemeine Beispiel dafür, wie das Setup mit Ihrem Code aussieht:
Erstkonfiguration und Gemini-Consumer
# Load setting variables
from dotenv import load_dotenv
load_dotenv()
# Initialize Gemini API consumer
from google import genai
consumer = genai.Consumer()
# Set display screen dimensions (really useful by Google)
SCREEN_WIDTH = 1440
SCREEN_HEIGHT = 900 Wir beginnen mit der Einrichtung der Umgebungsvariablen, dem Laden der API-Anmeldeinformationen und der Initialisierung des Gemini-Shoppers. Die von Google empfohlenen Bildschirmabmessungen werden definiert und später verwendet, um normalisierte Koordinaten in die tatsächlichen Pixelwerte umzuwandeln, die für Aktionen in der Benutzeroberfläche erforderlich sind.
Browser-Automatisierung mit Playwright
Als Nächstes richtet der Code Playwright für die Browser-Automatisierung ein:
from playwright.sync_api import sync_playwright
playwright = sync_playwright().begin()
browser = playwright.chromium.launch(
headless=False,
args=(
'--disable-blink-features=AutomationControlled',
'--disable-dev-shm-usage',
'--no-sandbox',
)
)
context = browser.new_context(
viewport={"width": SCREEN_WIDTH, "peak": SCREEN_HEIGHT},
user_agent="Mozilla/5.0 (Home windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/131.0.0.0 Safari/537.36",
)
web page = context.new_page() Definieren der Aufgaben- und Modellkonfiguration
Hier starten wir einen Chromium-Browser und nutzen die Anti-Erkennungs-Flags, um zu verhindern, dass Webseiten die Automatisierung erkennen. Dann definieren wir ein realistisches Ansichtsfenster und einen Benutzeragenten, um einen normalen Benutzer zu emulieren und eine neue Seite zu erstellen, um zu navigieren und die Interaktion zu automatisieren.
Nachdem der Browser eingerichtet und einsatzbereit ist, wird das Modell mit dem Ziel des Benutzers und dem ersten Screenshot versehen:
from google.genai.varieties import Content material, Half
USER_PROMPT = "Go to BBC Information and discover at the moment's prime expertise headlines"
initial_screenshot = web page.screenshot(kind="png")
contents = (
Content material(position="person", elements=(
Half(textual content=USER_PROMPT),
Half.from_bytes(information=initial_screenshot, mime_type="picture/png")
))
) USER_PROMPT definiert, welche Aufgabe in natürlicher Sprache der Agent ausführen wird. Es erfasst einen ersten Screenshot des Standing der Browserseite, der dann zusammen mit der Eingabeaufforderung an das Modell gesendet wird. Sie werden mit dem Content material-Objekt gekapselt, das später auch an das Gemini-Modell übergeben wird.
Schließlich wird die Agentenschleife ausgeführt, indem sie den Standing an das Modell sendet und die von ihm zurückgegebenen Aktionen ausführt:
Das Instrument computer_use fordert das Modell auf, Funktionsaufrufe zu erstellen, die dann in der Browserumgebung ausgeführt werden. think_config enthält die Zwischenschritte der Argumentation, um dem Benutzer Transparenz zu bieten, was für die spätere Fehlerbehebung oder das Verständnis des Entscheidungsprozesses des Agenten nützlich sein kann.
from google.genai.varieties import varieties
config = varieties.GenerateContentConfig(
instruments=(varieties.Instrument(
computer_use=varieties.ComputerUse(
setting=varieties.Surroundings.ENVIRONMENT_BROWSER
)
)),
thinking_config=varieties.ThinkingConfig(include_thoughts=True),
)Wie funktioniert es?
Gemini 2.5 Laptop Use läuft als Closed-Loop-Agent. Sie geben ihm ein Ziel und einen Screenshot vor, er sagt die nächste Aktion voraus, führt sie über den Consumer aus und überprüft dann den aktualisierten Bildschirm, um zu entscheiden, was als nächstes zu tun ist. Diese Rückkopplungsschleife ermöglicht es Zwillingen, ähnlich wie ein Mensch, der in einem Browser navigiert, zu sehen, zu denken und zu handeln. Der gesamte Prozess wird von der angetrieben computer_use Instrument in der Gemini-API.
Die Kern-Suggestions-Schleife
Der Agent arbeitet in einem kontinuierlichen Zyklus, bis die Aufgabe abgeschlossen ist:
- Eingabeziel und Screenshot: Das Modell erhält die Anweisung des Benutzers (z. B. „High-Tech-Schlagzeilen finden“) und den Screenshot des aktuellen Standing des Browsers.
- Generieren Sie Aktionen: Das Modell schlägt einen oder mehrere Funktionsaufrufe vor, die UI-Aktionen mit dem computer_use-Instrument entsprechen.
- Aktionen ausführen: Das Consumer-Programm führt diese Funktionsaufrufe im Browser aus.
- Erfassen Sie Suggestions: Ein neuer Screenshot und eine neue URL werden erfasst und an das Modell zurückgesendet.
Was das Modell in jeder Iteration sieht
Bei jeder Iteration erhält das Modell drei Schlüsselinformationen:
- Benutzeranfrage: Das Ziel oder die Anweisung in natürlicher Sprache (Beispiel: „Finden Sie die High-Schlagzeilen“)
- Aktueller Screenshot: Ein Bild Ihres Browser- oder App-Fensters und seines aktuellen Standing
- Aktionsgeschichte: Eine Aufzeichnung der bisher ergriffenen Maßnahmen (für den Kontext)
Das Modell analysiert den Screenshot und das Ziel des Benutzers und generiert dann einen oder mehrere Funktionsaufrufe– jeweils eine UI-Aktion darstellend. Zum Beispiel:
{"identify": "click_at", "args": {"x": 400, "y": 600}}Dies würde den Agenten anweisen, auf diese Koordinaten zu klicken.
Aktionen im Browser ausführen
Das Consumer-Programm (unter Verwendung der Maus- und Tastatur-APIs von Playwright) führt diese Aktionen im Browser aus. Hier ist ein Beispiel, wie Funktionsaufrufe ausgeführt werden:
def execute_function_calls(candidate, web page, screen_width, screen_height):
for half in candidate.content material.elements:
if half.function_call:
fname = half.function_call.identify
args = half.function_call.args
if fname == "click_at":
actual_x = int(args("x") / 1000 * screen_width)
actual_y = int(args("y") / 1000 * screen_height)
web page.mouse.click on(actual_x, actual_y)
elif fname == "type_text_at":
actual_x = int(args("x") / 1000 * screen_width)
actual_y = int(args("y") / 1000 * screen_height)
web page.mouse.click on(actual_x, actual_y)
web page.keyboard.kind(args("textual content"))
# ...different supported actions...Die Funktion analysiert die FunctionCall vom Modell zurückgegebenen Einträge und führt jede Aktion im Browser aus. Es wandelt normalisierte Koordinaten (0–1000) basierend auf der Bildschirmgröße in tatsächliche Pixelwerte um.
Erfassen von Suggestions für den nächsten Zyklus
Nach der Ausführung von Aktionen erfasst das System den neuen Zustand und sendet ihn an das Modell zurück:
def get_function_responses(web page, outcomes):
screenshot_bytes = web page.screenshot(kind="png")
current_url = web page.url
function_responses = ()
for identify, consequence, extra_fields in outcomes:
response_data = {"url": current_url}
response_data.replace(consequence)
response_data.replace(extra_fields)
function_responses.append(
varieties.FunctionResponse(
identify=identify,
response=response_data,
elements=(varieties.FunctionResponsePart(
inline_data=varieties.FunctionResponseBlob(
mime_type="picture/png",
information=screenshot_bytes
)
))
)
)
return function_responsesDer neue Standing des Browsers wird eingepackt FunctionResponse Objekte, anhand derer das Modell darüber nachdenkt, was als nächstes zu tun ist. Die Schleife wird fortgesetzt, bis das Modell keine Funktionsaufrufe mehr zurückgibt oder bis die Aufgabe abgeschlossen ist.
Lesen Sie auch: High 7 Laptop Use Brokers
Schritte der Agentenschleife
Nach dem Laden des Instruments computer_use folgt eine typische Agentenschleife diesen Schritten:
- Senden Sie eine Anfrage an das Modell: Fügen Sie das Ziel des Benutzers und einen Screenshot des aktuellen Browserstatus in den API-Aufruf ein
- Modellantwort erhalten: Das Modell gibt eine Antwort zurück, die Textual content und/oder einen oder mehrere FunctionCall-Einträge enthält.
- Führen Sie die Aktionen aus: Der Clientcode analysiert jeden Funktionsaufruf und führt die Aktion im Browser aus.
- Suggestions erfassen und senden: Nach der Ausführung erstellt der Consumer einen neuen Screenshot und notiert die aktuelle URL. Diese werden in eine FunctionResponse verpackt und als nächste Benutzernachricht an das Modell zurückgesendet. Dadurch wird dem Modell das Ergebnis seiner Aktion mitgeteilt, sodass es den nächsten Schritt planen kann.
Dieser Vorgang läuft automatisch in einer Schleife ab. Wenn das Modell keine neuen Funktionsaufrufe mehr generiert, signalisiert es, dass die Aufgabe abgeschlossen ist. An diesem Punkt wird die endgültige Textausgabe zurückgegeben, beispielsweise eine Zusammenfassung der erreichten Ergebnisse. In den meisten Fällen durchläuft der Agent mehrere Zyklen, bevor er entweder das Ziel erreicht oder das festgelegte Zuglimit erreicht.
Weitere unterstützte Aktionen
Das Computernutzungstool von Gemini verfügt über Dutzende integrierter UI-Aktionen. Das Basisset umfasst Aktionen, die für webbasierte Anwendungen typisch sind, darunter:
- open_web_browser: Initialisiert den Browser, bevor die Agentenschleife beginnt (normalerweise vom Consumer verarbeitet).
- click_at: Klickt auf eine bestimmte (x, y)-Koordinate auf der Seite.
- type_text_at: Klicken Sie auf eine Stelle und geben Sie eine bestimmte Zeichenfolge ein. Drücken Sie optionally available die Eingabetaste.
- navigieren: Öffnet eine neue URL im Browser.
- go_back / go_forward: Geht im Browserverlauf vorwärts oder rückwärts.
- hover_at: Bewegt die Maus an einen bestimmten Punkt, um Hover-Effekte auszulösen.
- scroll_document / scroll_at: Scrollt die gesamte Seite oder einen bestimmten Abschnitt.
- Schlüsselkombination: Simuliert das Drücken von Tastaturkürzeln.
- wait_5_seconds: Hält die Ausführung an, nützlich zum Warten auf Animationen oder Seitenladevorgänge.
- Drag_and_Drop: Klicken Sie auf ein Aspect und ziehen Sie es an eine andere Place auf der Seite.
In der Dokumentation von Google wird erwähnt, dass die Beispielimplementierung die drei häufigsten Aktionen umfasst: open_web_browser, click_at und type_text_at. Sie können dies erweitern, indem Sie weitere benötigte Aktionen hinzufügen oder solche ausschließen, die für Ihren Workflow nicht related sind.
Leistung und Benchmarks
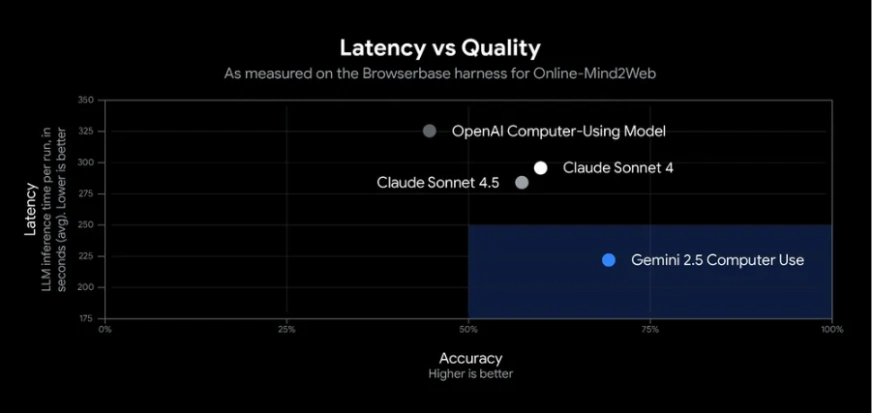
Gemini 2.5 Laptop Use bietet eine starke Leistung bei UI-Steuerungsaufgaben. In Googles Exams erreichte es eine Genauigkeit von über 70 % mit einer Latenz von etwa 225 ms und übertraf damit andere Modelle bei Net- und mobilen Benchmarks wie dem Durchsuchen von Web sites und dem Abschließen von App-Workflows.
In der Praxis kann der Agent Aufgaben wie das Ausfüllen von Formularen und das Abrufen von Daten zuverlässig erledigen. Unabhängige Benchmarks stufen es als das genaueste und schnellste öffentliche KI-Modell für die einfache Browserautomatisierung ein. Seine starke Leistung beruht auf der visuellen Argumentation von Gemini 2.5 Professional und einer optimierten API-Pipeline. Da es sich noch in der Vorschau befindet, sollten Sie seine Aktionen überwachen, da gelegentlich Fehler auftreten können.
Lesen Sie auch:
Abschluss
Die Gemini 2.5-Computernutzung ist eine bedeutende Entwicklung in der KI-gestützten Automatisierung, die es Agenten ermöglicht, effektiv und effizient mit realen Schnittstellen zu interagieren. Damit können Entwickler Aufgaben wie Webbrowsing, Dateneingabe oder Datenextraktion mit großer Genauigkeit und Geschwindigkeit automatisieren.
Im öffentlich zugänglichen Zustand können wir Entwicklern eine Möglichkeit bieten, sicher mit den Funktionen von Gemini 2.5 Laptop Use zu experimentieren und es in ihre eigenen Arbeitsabläufe zu integrieren. Insgesamt stellt es einen flexiblen Rahmen dar, mit dem intelligente Assistenten der nächsten Era oder leistungsstarke Automatisierungsworkflows für eine Vielzahl von Anwendungen und Bereichen erstellt werden können.
Hallo! Ich bin Vipin, ein leidenschaftlicher Fanatic für Datenwissenschaft und maschinelles Lernen mit fundierten Kenntnissen in Datenanalyse, Algorithmen für maschinelles Lernen und Programmierung. Ich verfüge über praktische Erfahrung in der Modellerstellung, der Verwaltung unübersichtlicher Daten und der Lösung realer Probleme. Mein Ziel ist es, datengesteuerte Erkenntnisse anzuwenden, um praktische Lösungen zu schaffen, die zu Ergebnissen führen. Ich bin bestrebt, meine Fähigkeiten in einer kollaborativen Umgebung einzubringen und gleichzeitig weiterhin in den Bereichen Information Science, maschinelles Lernen und NLP zu lernen und mich weiterzuentwickeln.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.