
Seit Google Nano Banana fallen gelassen hat, hat das Web nicht mehr mit A-generierten Bearbeitungen aufgehört. Vom 3D -Figur -Development bis hin zu Retro Bollywood Saree -Transformationen tauchen jeden Tag neue Stile auf, und die Leute können nicht genug davon bekommen. Als ich zum ersten Mal in die Konfiguration des Modells ausgegraben wurde, warfare ich von seiner Präzision betroffen: der Artwork und Weise, wie es Bilder kombiniert, die Beleuchtung entspricht und natürliche Ausgänge erzeugt. Dann hatte ich eine Idee – warum nicht diese Macht einsetzen, um eine lustige Nano -Banana -App zu erstellen? In diesem Weblog werde ich Sie durch das Erstellen von Selfie mit einem Promi, einer AI -App, mit der Sie mit Ihrem Lieblingsschauspieler, Musiker oder öffentlichen Figur ein realistisches Foto erstellen können. Ich werde das Nano -Bananenmodell von Google als Engine verwenden, es mit Gradio für eine einfache Weboberfläche kombinieren und es auf umarmenden Gesichtsräumen bereitstellen, damit jeder es ausprobieren kann.
Wenn Sie nicht wissen, was Nano Banane ist, lesen Sie diese Blogs:
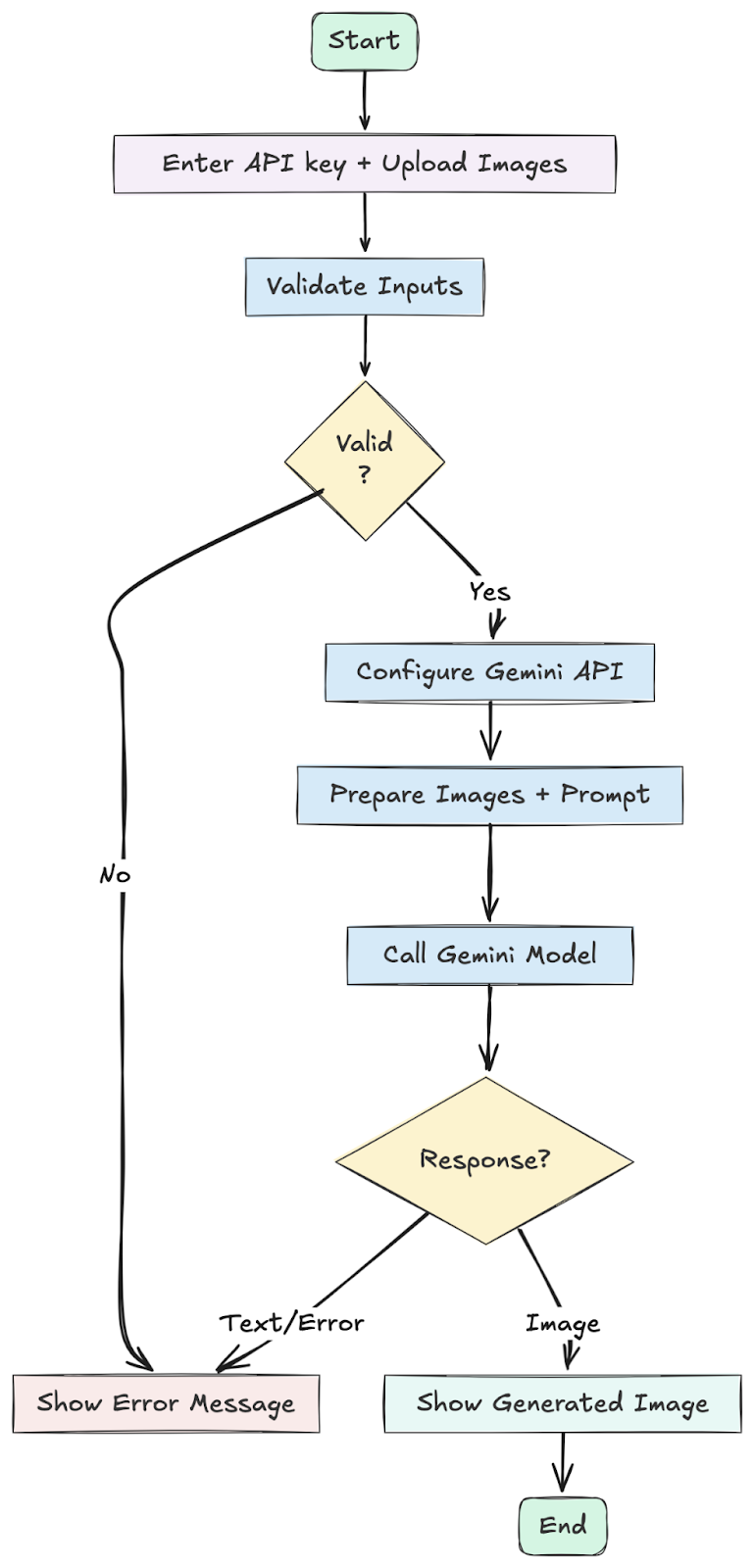
Projektübersicht
Das Ziel dieses Projekts ist es, eine einfache, aber lustige AI -Bild -App namens Seleber mit einem Promi zu erstellen. Die App ermöglicht einem Benutzer:
- Laden Sie ihr eigenes Foto hoch.
- Laden Sie ein Foto ihrer Lieblingsstars hoch.
- Erzeugen Sie ein realistisches zusammengesetztes Bild, in dem beide zusammen erscheinen, als ob sie in derselben Szene fotografiert werden.
Um dies zu erreichen, verwendet das Projekt:
- Googles Nano Banane (Gemini 2.5 Flash Picture) Als KI -Modell, das Bildmischung, Beleuchtungsanpassungen und Hintergrunderzeugung durchführt.
- Gradio als Framework zum Erstellen einer benutzerfreundlichen Weboberfläche, in der Benutzer Fotos hochladen und Ergebnisse anzeigen können.
- Umarme Gesichtsräume als Internet hosting -Plattform kostenlos, öffentliche Bereitstellung, damit jeder auf die App zugreifen und testen kann.
Das Endergebnis ist ein mitgeteilbares Foto, das natürlich, konsistent und ansprechend aussieht. Da es durch Personalisierung betrieben wird (Sie plus Ihre gewählte Berühmtheit), werden die Inhalte viral werden: Menschen genießen es, sich in kreativen neuen Kontexten zu sehen.
Lassen Sie uns unsere Nano -Banana -App bauen:
Schritt 1: Richten Sie Ihr Projekt ein
Erstellen Sie zunächst einen neuen Ordner für Ihr Projekt. Erstellen Sie in diesem Ordner eine Datei namens Anforderungen.txt und fügen Sie die von uns benötigten Bibliotheken hinzu.
Anforderungen.txt
gradio
google-generativeai
pillowInstallieren Sie diese Abhängigkeiten, indem Sie diesen Befehl in Ihrem Terminal ausführen:
pip set up -r necessities.txtUnser App.Py -Skript magazine lang erscheinen, aber es ist in logischen Abschnitten organisiert, die alles von Sprechen mit der KI bis zur Erstellung der Benutzeroberfläche verarbeiten. Lass uns durchgehen.
Schritt 2: Importe und erste Einrichtung
Ganz oben in der Datei importieren wir alle notwendigen Bibliotheken und definieren einige Konstanten:
import os
import io
import time
import base64
from PIL import Picture
import gradio as gr
import google.generativeai as genai
from google.api_core.exceptions import ResourceExhausted, InvalidArgument, GoogleAPICallError
APP_TITLE = "Take a Image with Your Favorite Celeb!"
MODEL_NAME = "fashions/gemini-2.5-flash-image-preview"- Standardbibliotheken: Wir importieren OS, IO, Time und Base64 für grundlegende Vorgänge wie die Handhabung von Dateien, Datenströmen und Verzögerungen. PIL (Kissen) ist für die Bildverarbeitung von entscheidender Bedeutung.
- Kernkomponenten: Gradio dient zum Erstellen der Internet -Benutzeroberfläche und Google.generATiveAI ist die offizielle Google -Bibliothek für die Interaktion mit dem Gemini -Modell.
- Konstanten: Wir definieren app_title und model_name oben. Dies erleichtert einfach, den Titel der App zu ändern oder die Modellversion später zu aktualisieren, ohne den Code zu durchsuchen.
Schritt 3: Helferfunktionen für eine robuste API -Interaktion
Diese Gruppe von Funktionen macht unsere Anwendung zuverlässig. Sie behandeln die komplexen API -Antworten und potenziellen Netzwerkprobleme anmutig:
# Helper features
def _iter_parts(resp):
if hasattr(resp, "components") and resp.components:
for p in resp.components:
yield p
if hasattr(resp, "candidates") and resp.candidates:
for c in resp.candidates:
content material = getattr(c, "content material", None)
if content material and getattr(content material, "components", None):
for p in content material.components:
yield p
def _find_first_image_part(resp):
for p in _iter_parts(resp):
inline = getattr(p, "inline_data", None)
if inline and getattr(inline, "information", None):
mime = getattr(inline, "mime_type", "") or ""
if mime.startswith("picture/"):
return p
return None
def _collect_text(resp, restrict=2):
msgs = ()
for p in _iter_parts(resp):
if hasattr(p, "textual content") and isinstance(p.textual content, str) and p.textual content.strip():
msgs.append(p.textual content.strip())
if len(msgs) >= restrict:
break
return msgs
def _format_candidate_reasons(resp):
infos = ()
cands = getattr(resp, "candidates", None)
if not cands:
return ""
for i, c in enumerate(cands):
fr = getattr(c, "finish_reason", None)
if fr:
infos.append(f"candidate({i}).finish_reason={fr}")
security = getattr(c, "safety_ratings", None) or getattr(c, "safetyRatings", None)
if security:
infos.append(f"candidate({i}).safety_ratings={security}")
return "n".be part of(infos)
def _preprocess_image(pil_img, max_side=512):
# Smaller enter to scale back token/depend price
pil_img = pil_img.convert("RGB")
w, h = pil_img.dimension
m = max(w, h)
if m <= max_side:
return pil_img
scale = max_side / float(m)
nw, nh = int(w * scale), int(h * scale)
return pil_img.resize((nw, nh), Picture.LANCZOS)
def _call_with_backoff(mannequin, contents, max_retries=3):
"""
Retries on 429 / quota exceeded errors with exponential backoff.
"""
last_exc = None
for try in vary(max_retries + 1):
strive:
return mannequin.generate_content(contents)
besides ResourceExhausted as e:
last_exc = e
if try == max_retries:
increase
sleep_time = 2 ** try
print(f"(DEBUG) ResourceExhausted / quota error. Retry after {sleep_time} seconds.")
time.sleep(sleep_time)
besides GoogleAPICallError as e:
err_str = str(e)
if "429" in err_str or "quota" in err_str.decrease():
last_exc = e
if try == max_retries:
increase
sleep_time = 2 ** try
print(f"(DEBUG) Quota or rate-limit error. Retry after {sleep_time} seconds.")
time.sleep(sleep_time)
else:
increase
# if we exit loop with out return
if last_exc:
increase last_exc
else:
increase RuntimeError("Unreachable in backoff logic")- Antwort Parsers (_iter_parts, _find_first_image_part, _collect_text, _format_candidate_reasons): Die Gemini -API kann eine komplexe Reaktion mit mehreren Teilen zurückgeben. Diese Funktionen suchen sicher durch die Antwort, um die wichtigen Bits zu finden: die generierten Bilddaten, alle Textnachrichten oder Fehler/Sicherheitsinformationen.
- _PREPROCESS_IMAGE: Um API -Kosten zu sparen und die Erzeugung zu beschleunigen, nimmt diese Funktion die hochgeladenen Bilder und die Größe, wenn sie zu groß sind. Es behält das Seitenverhältnis bei und stellt sicher, dass die längste Seite nicht mehr als 512 Pixel beträgt.
- _call_with_backoff: Dies ist eine kritische Funktion für die Zuverlässigkeit. Wenn die Google -API besetzt ist und uns auffordert, zu verlangsamen (ein „Quoten überschritten“ -Fehler), wartet diese Funktion automatisch auf einen Second und versucht dann erneut. Es erhöht die Wartezeit mit jedem fehlgeschlagenen Versuch und verhindert, dass die App abstürzt.
Schritt 4: Logik der Hauptgeneration
Dies ist das Herzstück unserer Anwendung. Die Funktion generate_image_with_celeb orchestriert den gesamten Vorgang, von der Validierung der Benutzereingabe auf die Rückgabe des endgültigen Bildes.
# Fundamental operate
def generate_image_with_celeb(api_key, user_image, celeb_image, progress=gr.Progress()):
if not api_key:
return None, "🔐 Authentication Error: Please present your Google AI API key."
if user_image is None or celeb_image is None:
return None, "📥 Please add each your photograph and the celeb photograph."
progress(0.05, desc="Configuring API...")
strive:
genai.configure(api_key=api_key)
besides Exception as e:
return None, f"❌ API key configuration failed: {e}"
# Examine mannequin visibility
strive:
fashions = (getattr(m, "identify", "") for m in genai.list_models())
besides Exception as e:
# Probably SDK model not supporting list_models
fashions = ()
print(f"(DEBUG) list_models failed: {e}")
if MODEL_NAME not in fashions:
return None, (
f"🚫 Mannequin `{MODEL_NAME}` not out there underneath this API key. "
"Please guarantee your mission is enabled for picture preview mannequin and billing is energetic."
)
progress(0.15, desc="Getting ready photographs...")
strive:
user_pil = Picture.fromarray(user_image)
celeb_pil = Picture.fromarray(celeb_image)
user_pil = _preprocess_image(user_pil, max_side=512)
celeb_pil = _preprocess_image(celeb_pil, max_side=512)
besides Exception as e:
return None, f"❌ Did not course of photographs: {e}"
immediate = (
"Analyze these two photographs. Your process is to create a single, new, photorealistic picture the place the individual from the primary picture "
"is standing subsequent to the celeb from the second picture."
"Key necessities for the output picture:"
"1. **Seamless Integration:** Each people should appear like they're in the identical bodily house."
"2. **Automated Background:** Generate an appropriate and natural-looking background (e.g., a crimson carpet occasion, an off-the-cuff avenue, a studio)."
"3. **Constant Lighting:** The lighting, shadows, and shade tones on each people have to be completely matched and according to the generated background."
"4. **Pure Poses:** The poses and interactions ought to seem pure and plausible."
"5. **Excessive-High quality Output:** The ultimate picture must be high-resolution and freed from apparent digital artifacts."
)
contents = (user_pil, celeb_pil, immediate)
progress(0.35, desc="Sending request...")
response = None
strive:
mannequin = genai.GenerativeModel(MODEL_NAME)
response = _call_with_backoff(mannequin, contents, max_retries=4)
besides Exception as e:
err = str(e)
if "429" in err or "quota" in err.decrease():
return None, (
"❌ You’ve exceeded your quota for picture preview mannequin. "
"Anticipate quota reset or improve billing / permissions."
)
return None, f"❌ API name failed: {err}"
progress(0.65, desc="Parsing response...")
if not response:
return None, "❌ No response from mannequin."
img_part = _find_first_image_part(response)
if img_part:
strive:
mime = getattr(img_part.inline_data, "mime_type", "") or "picture/unknown"
data_b64 = img_part.inline_data.information
image_bytes = base64.b64decode(data_b64)
img = Picture.open(io.BytesIO(image_bytes))
progress(0.95, desc="Rendering...")
return img, f"✅ Picture generated ({mime})."
besides Exception as e:
particulars = _format_candidate_reasons(response)
return None, f"❌ Picture information discovered however didn't decode: {e}nn{particulars}"
# No picture half → get textual content
texts = _collect_text(response, restrict=2)
causes = _format_candidate_reasons(response)
steering = (
"nTo get picture output you want entry to the preview picture mannequin "
"and enough free-tier quota or a billed mission."
)
txt_msg = texts(0) if texts else "No textual content message."
debug = f"n(Debug data) {causes}" if causes else ""
return None, f"⚠️ Mannequin returned textual content: {txt_msg}{steering}{debug}"- Eingabevalidierung: Es prüft zunächst, ob der Benutzer einen API -Schlüssel und beide Bilder bereitgestellt hat. Wenn nicht, gibt es sofort eine Fehlermeldung zurück.
- API -Konfiguration: Es verwendet die Funktion genai.configure (), um die Verbindung mit der persönlichen API -Style des Benutzers an Googles Server einzurichten.
- Bildvorbereitung: Es konvertiert die Bilder, die über Gradio hochgeladen wurden, in ein Format, das die API versteht (PIL -Bilder) und verwendet unseren Helfer _Proprocess_image, um sie zu ändern.
- Eingabeaufforderung und API -Anruf: Es erstellt die endgültige Eingabeaufforderung und kombiniert die beiden Bilder und unsere Textanweisungen. Anschließend werden das Gemini -Modell mit unserer zuverlässigen Funktion _call_with_backoff aufgerufen.
- Antworthandhabung: Nach einer Antwort verwendet es unsere Helferfunktionen, um die Bilddaten zu finden. Wenn ein Bild gefunden wird, decodiert es es und gibt es an die Benutzeroberfläche zurück. Wenn nicht, findet es Textnachrichten und gibt diese stattdessen zurück, sodass der Benutzer weiß, was passiert ist.
Schritt 5: Erstellen Sie die Benutzeroberfläche mit Gradio
Der letzte Abschnitt des Codes verwendet Gradio, um die interaktive Webseite zu erstellen:
# Gradio UI
custom_css = """
.gradio-container { border-radius: 20px !vital; box-shadow: 0 4px 20px rgba(0,0,0,0.05); }
#title { text-align: middle; font-family: 'Helvetica Neue', sans-serif; font-weight: 700; font-size: 2.0rem; }
#subtitle { text-align: middle; font-size: 1.0rem; margin-bottom: 1.0rem; }
.gr-button { font-weight: 600 !vital; border-radius: 8px !vital; padding: 12px 10px !vital; }
#output_header { text-align: middle; font-weight: daring; font-size: 1.2rem; }
footer { show: none !vital; }
"""
with gr.Blocks(theme=gr.themes.Comfortable(), css=custom_css) as demo:
gr.Markdown(f"# {APP_TITLE}", elem_id="title")
gr.Markdown(
"Makes use of Google Gemini 2.5 Flash Picture Preview mannequin. Present your API key from a billed mission with entry.",
elem_id="subtitle"
)
with gr.Accordion("Step 1: Enter Your Google AI API Key", open=True):
api_key_box = gr.Textbox(
label="API Key",
placeholder="Paste your Google AI API key right here...",
kind="password",
data="Guarantee the secret is from a mission with billing and picture preview entry.",
interactive=True
)
with gr.Row(variant="panel"):
user_image = gr.Picture(kind="numpy", label="Add your image", peak=350)
celeb_image = gr.Picture(kind="numpy", label="Add celeb image", peak=350)
generate_btn = gr.Button("Generate Picture", variant="major")
gr.Markdown("### Output", elem_id="output_header")
output_image = gr.Picture(label="Generated Picture", peak=500, interactive=False)
output_text = gr.Markdown(label="Standing / Message")
generate_btn.click on(
fn=generate_image_with_celeb,
inputs=(api_key_box, user_image, celeb_image),
outputs=(output_image, output_text)
)
if __name__ == "__main__":
if not os.path.exists("./examples"):
os.makedirs("./examples")
demo.launch(debug=True)- Structure (Gr.Blocks): Wir verwenden Gr.Blocks, um ein benutzerdefiniertes Structure zu erstellen. Wir geben auch unsere Custom_CSS -String über, um die Komponenten zu stylen.
- Komponenten: Jedes Factor auf der Seite – wie der Titel (Gr.Markdown), das Feld API -Schlüssel (Gr.TextBox) und die Bild -Add -Felder (Gr.Picture) – wird als Gradio -Komponente erstellt.
- Anordnung: Komponenten wie die beiden Bild-Add-Boxen werden in einem Gr.Row platziert, um nebeneinander zu erscheinen. Das API -Schlüsselfeld befindet sich in einem zusammenklappbaren Gr.Accordion.
- Style und Ausgänge: Wir definieren die Schaltfläche „Generate“ (Gr.Button) und die Komponenten, in denen die Ergebnisse angezeigt werden (output_image und output_text).
- Occasion -Dealing with (.click on ()): Dies ist die Magie, die die Benutzeroberfläche mit unserer Python -Logik verbindet. Diese Zeile sagt Gradio: „Wenn generate_btn geklickt wird, führen Sie die Funktion generate_image_with_celeb aus. Nehmen Sie die Werte aus api_key_box, user_image und celeb_image als Eingänge und platzieren Sie die Ergebnisse in Output_image und output_text.“
GO LIVE: Einfache Gradio App -Bereitstellung auf dem Umarmungsgesicht
Einer der besten Teile dieses Projekts ist, wie einfach die Gradio App -Bereitstellung ist. Wir werden umarmende Gesichtsräume verwenden, eine kostenlose Plattform zum Internet hosting von maschinellem Lerndemos.
- Erstellen Sie ein umarmendes Gesichtskonto: Wenn Sie keine haben, melden Sie sich an suggingface.co.
- Erstellen Sie einen neuen Raum: Klicken Sie in Ihrem Profil auf „Neuer Speicherplatz“.
- Raumname: Geben Sie ihm einen einzigartigen Namen (z. B. Promi-Selfie-Generator).
- Lizenz: Wählen Sie eine Lizenz (z. B. MIT).
- Wählen Sie den House SDK aus: Wählen Gradio.
- {Hardware}: Die kostenlose Possibility „CPU Primary“ ist ausreichend.
- Klicken Sie auf „Speicherplatz erstellen“.
- Laden Sie Ihre Dateien hoch:
- Navigieren Sie in Ihrem neuen Speicherplatz auf die Registerkarte „Dateien und Versionen“.
- Klicken Sie auf „Datei hinzufügen“ und dann „Dateien hochladen“.
- Wählen Sie Ihre App.py und Anforderungen.txt -Dateien aus und laden Sie sie hoch.
Das warfare’s! Durch das Umarmungsflächen werden die erforderlichen Bibliotheken automatisch installiert und Ihre Anwendung gestartet. In wenigen Augenblicken wird Ihre App für jeden auf der Welt reside sein. Da für die App jeder Benutzer seine eigene API-Schlüssel eingeben muss, müssen Sie sich keine Sorgen um die Verwaltung von serverseitigen Geheimnissen machen.
Klicken Sie hier, um das Selfie mit einer Promi -App zu überprüfen!
Eingang:
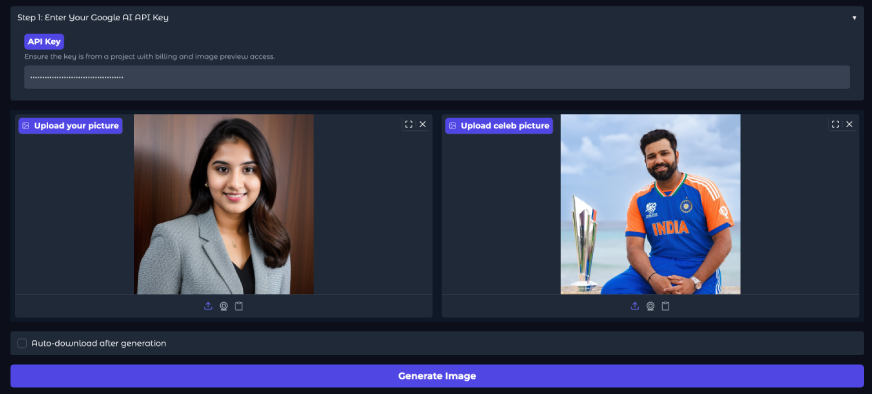
Ausgabe:

Sie müssen Ihren Gemini -API -Schlüssel bereitstellen, Ihr Foto hochladen und ein Promi -Bild hinzufügen. Sobald Sie auf Generieren klicken, verarbeitet und liefert die App Ihre Ausgabe in wenigen Augenblicken. Die Ergebnisse sehen natürlich und realistisch aus, mit einer starken Konsistenz zwischen beiden Bildern.
Probieren Sie es mit Ihrem eigenen Foto und Ihrer Lieblingsberühmtheit mit Ihrem API -Schlüssel aus!
Abschluss
Sie haben jetzt eine vollständige Blaupause, um Ihre eigene virale AI -Bild -App zu erstellen. Wir haben untersucht, wie Googles Nano Bananamodel (Gemini 2.5 Flash Picture) hochrealistische, konsistente Ausgänge erzeugen kann und wie einfach es ist, sich in Frameworks wie Gradio und umarmende Gesichtsräume zu integrieren. Das Beste daran ist, dass Sie die Eingabeaufforderung anpassen, die Schnittstelle optimieren oder die Idee sogar in völlig neue Apps erweitern können. Mit nur wenigen Schritten können Sie dieses Projekt von der Konzept bis zur Realität nehmen und etwas wirklich gemeinsam genutzbares schaffen.
Welche Nano -Banana -App bauen Sie? Lassen Sie mich im Kommentarbereich unten wissen!
Häufig gestellte Fragen
A. Es ist der interne Codename für Googles Gemini 2.5 Flash Picture, ein leistungsstarkes KI -Modell, das Inhalte sowohl aus Bildern als auch aus Textual content verstehen und generieren kann.
A. Die App selbst ist frei zu verwenden, erfordert jedoch einen Google AI -API -Schlüssel. Google bietet eine kostenlose Stufe mit Nutzungsgrenzen, wonach Sie möglicherweise eine Abrechnung einrichten müssen.
A. Dieser Ansatz ermöglicht es jedem, die App zu verwenden, ohne dass der Entwickler für jede Bildgenerierung Kosten entspricht, was es nachhaltig macht, öffentlich zu hosten.
A. Ja, umarmende Gesichtsräume bieten eine kostenlose Stufe mit Neighborhood -{Hardware} (CPU oder Restricted GPU -Zugriff), die für die meisten Gradio -Demos perfekt ist.
A. Dies ist ein Optimierungsschritt. Kleinere Bilder werden schneller verarbeitet und konsumieren weniger Ressourcen, was die API -Kosten senken und die Erzeugungszeit verkürzen kann.
Harsh Mishra ist ein KI/ML -Ingenieur, der mehr Zeit damit verbringt, mit großen Sprachmodellen zu sprechen als mit tatsächlichen Menschen. Leidenschaft über Genai, NLP und Maschinen schlauer (damit sie ihn noch nicht ersetzen). Wenn er Fashions nicht optimiert, optimiert er wahrscheinlich seine Kaffeeaufnahme. 🚀☕
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.