
Der neueste Satz von Open-Supply-Modelle aus GOOGle sind da, die Gemma 4-Familie ist angekommen. Open-Supply-Modelle erfreuen sich aufgrund von Datenschutzbedenken und ihrer Flexibilität bei der einfachen Feinabstimmung in letzter Zeit großer Beliebtheit. Jetzt haben wir vier vielseitige Open-Supply-Modelle in der Gemma 4-Familie, die auf dem Papier sehr vielversprechend erscheinen. Lassen Sie uns additionally ohne weitere Umschweife entschlüsseln und sehen, worum es bei dem Hype geht.
Die Gemma-Familie
Gemma ist eine Familie von leichten, offenen, großen Sprachmodellen, die von Google entwickelt wurden. Es basiert auf der gleichen Forschung und Technologie, die auch bei Google zum Einsatz kommt Zwillinge Modelle, die jedoch zugänglicher und effizienter gestaltet sind.
Was das wirklich bedeutet, ist: Gemma-Modelle sind für den Betrieb in praktischeren Umgebungen wie Laptops, Verbraucher-GPUs und sogar mobilen Geräten gedacht.
Es gibt sie in beiden Varianten:
- Basisversionen (zur Feinabstimmung und Anpassung)
- Auf Anweisungen abgestimmte (IT) Versionen (bereit für Chat und allgemeine Nutzung)
Das sind additionally die Modelle, die unter das Dach fallen Gemma 4 Familie:
- Gemma 4 E2B: Mit ~2B effektiven Parametern handelt es sich um ein multimodales Modell, das für Edge-Geräte wie Smartphones optimiert ist.
- Gemma 4 E4B: Ähnlich dem E2B-Modell, verfügt dieses jedoch über ~4B effektive Parameter.
- Gemma 4 26B A4B: Es handelt sich um eine 26B-Parameter-Mischung aus Expertenmodellen, die während der Inferenz nur 3,8B Parameter (~4B aktive Parameter) aktiviert. Quantisierte Versionen dieses Modells können auf Shopper-GPUs ausgeführt werden.
- Gemma 4 31B: Es handelt sich um ein dichtes Modell mit 31B-Parametern, es ist das leistungsstärkste Modell in dieser Reihe und eignet sich sehr intestine für Feinabstimmungszwecke.
Die Modelle E2B und E4B verfügen über ein Kontextfenster von 128 KB, während die größeren Modelle 26B und 31B über ein Kontextfenster von 256 KB verfügen.
Notiz: Alle Modelle sind sowohl als Basismodell als auch als „IT“-Modell (auf Anleitung abgestimmt) erhältlich.
Nachfolgend finden Sie die Benchmark-Ergebnisse für die Gemma 4-Modelle:
Hauptmerkmale von Gemma 4
- Codegenerierung: Für die Codegenerierung können die Gemma 4-Modelle verwendet werden, auch die LiveCodeBench-Benchmark-Ergebnisse sehen intestine aus.
- Agentensysteme: Die Gemma 4-Modelle können lokal in Agenten-Workflows verwendet oder selbst gehostet und in produktionstaugliche Systeme integriert werden.
- Mehrsprachige Systeme: Diese Modelle sind auf über 140 Sprachen trainiert und können zur Unterstützung verschiedener Sprachen oder Übersetzungszwecke verwendet werden.
- Erweiterte Agenten: Diese Modelle weisen im Vergleich zu den Vorgängern eine deutliche Verbesserung in Mathematik und Argumentation auf. Sie können bei Agenten eingesetzt werden, die eine mehrstufige Planung und Denkweise erfordern.
- Multimodalität: Diese Modelle können von Natur aus Bilder, Movies und Audio verarbeiten. Sie können für Aufgaben wie OCR und Spracherkennung eingesetzt werden.
Wie greife ich über Hugging Face auf Gemma 4 zu?
Gemma 4 wird unter der Apache 2.0-Lizenz veröffentlicht. Sie können frei mit den Modellen bauen und die Modelle in jeder Umgebung bereitstellen. Auf diese Modelle kann mit Hugging Face, Ollama und Kaggle zugegriffen werden. Lassen Sie uns versuchen, das zu testen.Gemma 4 26B A4B ITDurch die Inferenzanbieter auf Hugging Face können wir uns so ein besseres Bild von den Fähigkeiten des Modells machen.
Voraussetzung
Token „Umarmendes Gesicht“:
- Gehe zu https://huggingface.co/settings/tokens
- Erstellen Sie ein neues Token, konfigurieren Sie es mit dem Namen und aktivieren Sie die folgenden Kontrollkästchen, bevor Sie das Token erstellen.
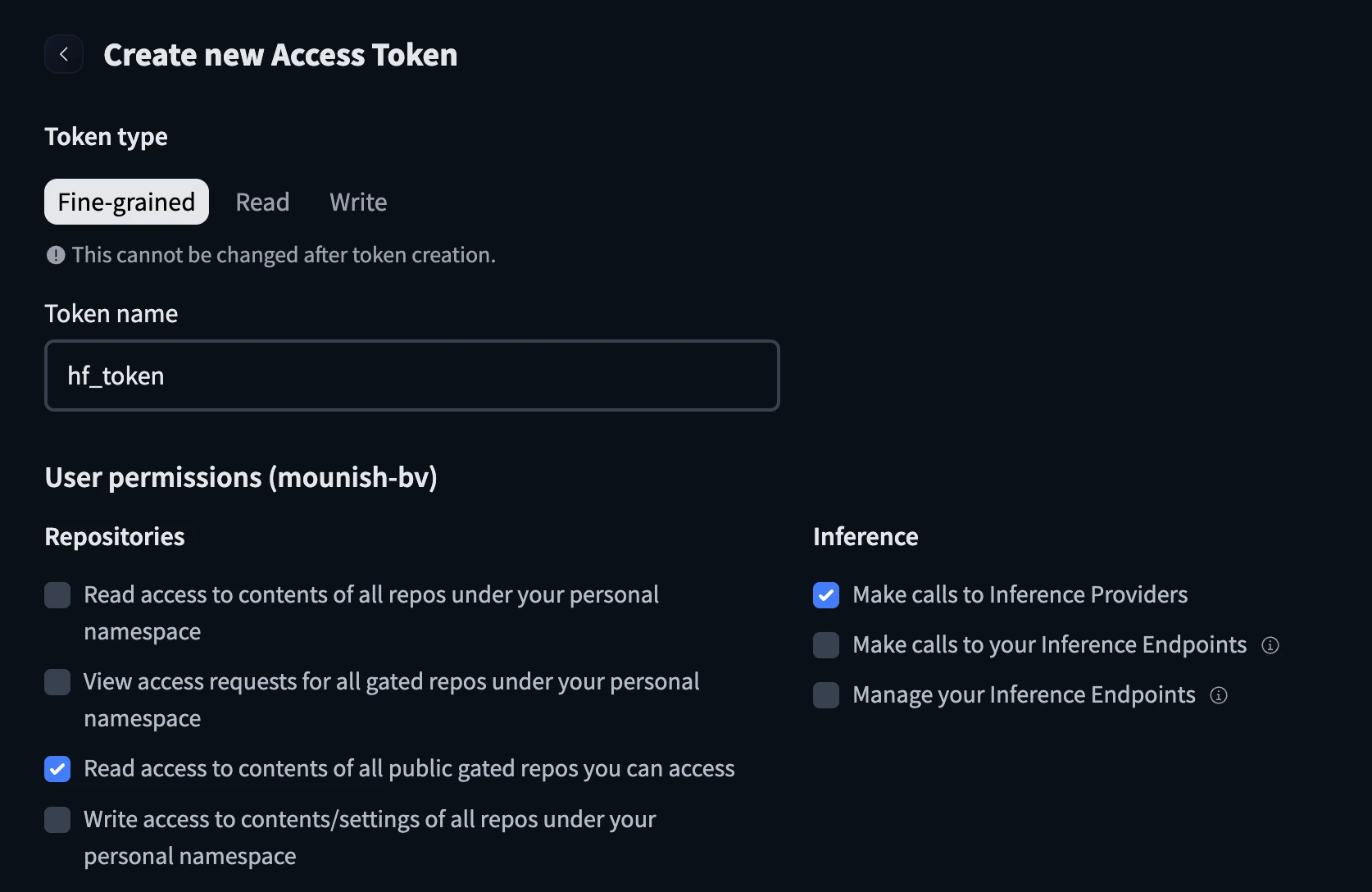
- Halten Sie den Umarmungsgesichts-Token bereit.
Python-Code
Ich verwende Google Colab für die Demo. Sie können gerne verwenden, was Ihnen gefällt.
from getpass import getpass
hf_key = getpass("Enter Your Hugging Face Token: ")Fügen Sie das Image „Umarmendes Gesicht“ ein, wenn Sie dazu aufgefordert werden:

Versuchen wir, ein Frontend für eine E-Commerce-Web site zu erstellen und sehen, wie das Modell funktioniert.
immediate="""Generate a contemporary, visually interesting frontend for an e-commerce web site utilizing solely HTML and inline CSS (no exterior CSS or JavaScript).
The web page ought to embrace a responsive format, navigation bar, hero banner, product grid, class part, product playing cards with photographs/costs/buttons, and a footer.
Use a clear trendy design, good spacing, and laptop-friendly format.
"""Anfrage an den Inferenzanbieter senden:
import os
from huggingface_hub import InferenceClient
consumer = InferenceClient(
api_key=hf_key,
)
completion = consumer.chat.completions.create(
mannequin="google/gemma-4-26B-A4B-it:novita",
messages=(
{
"function": "consumer",
"content material": (
{
"kind": "textual content",
"textual content": immediate,
},
),
}
),
)
print(completion.decisions(0).message)
Nachdem ich den Code kopiert und den HTML-Code erstellt habe, habe ich folgendes Ergebnis erhalten:
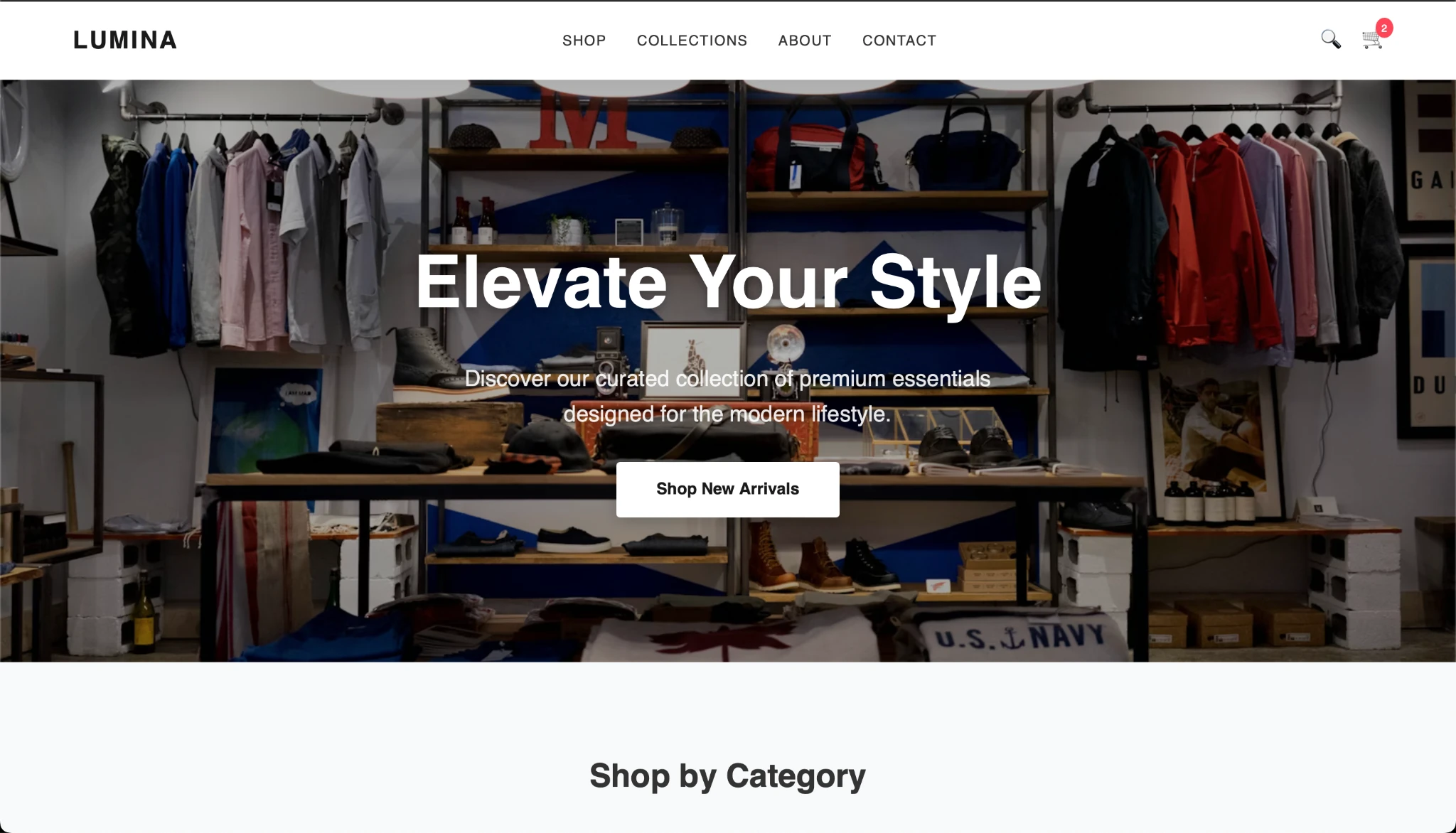
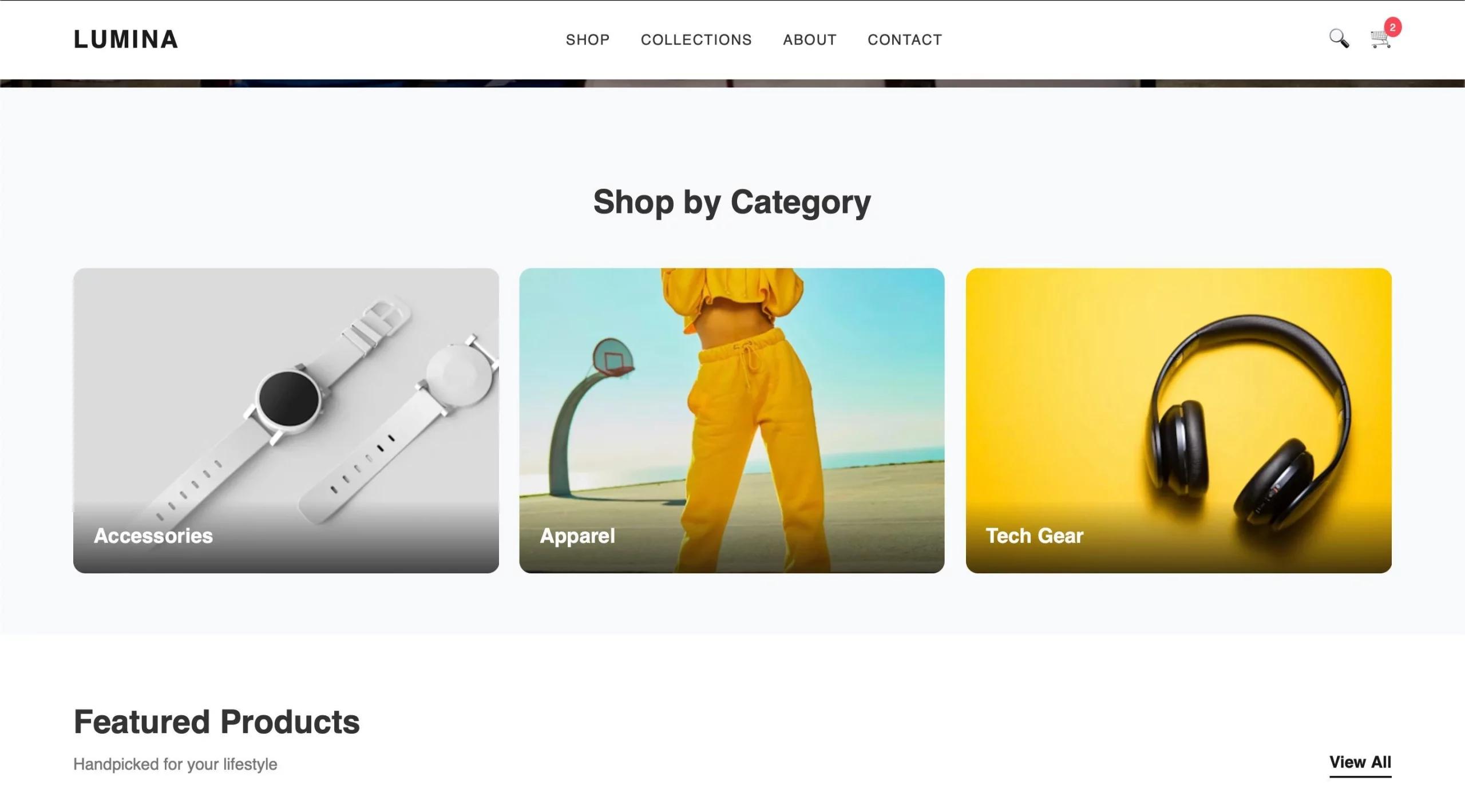
Die Ausgabe sieht intestine aus und das Gemma-Modell scheint eine gute Leistung zu erbringen. Was denken Sie?
Abschluss
Die Gemma 4-Familie sieht nicht nur auf dem Papier vielversprechend aus, sondern auch im Ergebnis. Mit vielseitigen Fähigkeiten und den verschiedenen Modellen, die für unterschiedliche Bedürfnisse gebaut wurden, haben die Gemma 4-Modelle so viele Dinge richtig gemacht. Auch mit Open-Supply KI Aufgrund der zunehmenden Beliebtheit sollten wir die Möglichkeit haben, die Modelle auszuprobieren, zu testen und zu finden, die unseren Anforderungen besser entsprechen. Außerdem wird es interessant sein zu sehen, wie Geräte wie Mobiltelefone, Raspberry Pi usw. in Zukunft von den sich entwickelnden speichereffizienten Modellen profitieren.
Häufig gestellte Fragen
A. E2B bedeutet 2,3B effektive Parameter. Während die Gesamtparameter einschließlich Einbettungen etwa 5,1 Milliarden erreichen.
A: Große Einbettungstabellen werden hauptsächlich für Suchvorgänge verwendet, sodass sie die Gesamtparameter erhöhen, jedoch nicht die effektive Rechengröße des Modells.
A. Mischung aus Experten Aktiviert nur eine kleine Teilmenge spezialisierter Expertennetzwerke professional Token und verbessert so die Effizienz bei gleichzeitiger Beibehaltung einer hohen Modellkapazität. Die Gemma 4 26B ist ein MoE-Modell.
Leidenschaftlich für Technologie und Innovation, Absolvent des Vellore Institute of Expertise. Derzeit arbeite ich als Information Science Trainee mit Schwerpunkt auf Information Science. Großes Interesse an Deep Studying und generativer KI, begierig darauf, modernste Techniken zu erforschen, um komplexe Probleme zu lösen und wirkungsvolle Lösungen zu schaffen.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.