
Die Themenmodellierung deckt verborgene Themen in großen Dokumentensammlungen auf. Herkömmliche Methoden wie die latente Dirichlet-Zuordnung basieren auf der Worthäufigkeit und behandeln Textual content als Wortbeutel, dem oft der tiefere Kontext und die tiefere Bedeutung entgehen.
BERTopic geht einen anderen Weg und kombiniert Transformer-Einbettungen, Clustering und c-TF-IDF, um semantische Beziehungen zwischen Dokumenten zu erfassen. Es erzeugt aussagekräftigere, kontextbezogene Themen, die für Daten aus der realen Welt geeignet sind. In diesem Artikel erklären wir Ihnen Schritt für Schritt, wie BERTopic funktioniert und wie Sie es anwenden können.
Was ist BERTopic?
BERTopic ist ein modulares Framework zur Themenmodellierung, das die Themenerkennung als eine Pipeline unabhängiger, aber miteinander verbundener Schritte behandelt. Es integriert Deep Studying und klassische Techniken zur Verarbeitung natürlicher Sprache, um kohärente und interpretierbare Themen zu erstellen.
Die Kernidee besteht darin, Dokumente in semantische Einbettungen umzuwandeln, sie basierend auf ihrer Ähnlichkeit zu gruppieren und dann repräsentative Wörter für jeden Cluster zu extrahieren. Dieser Ansatz ermöglicht es BERTopic, sowohl Bedeutung als auch Struktur innerhalb von Textdaten zu erfassen.
Auf hoher Ebene verfolgt BERTopic diesen Prozess:

Jede Komponente dieser Pipeline kann geändert oder ersetzt werden, wodurch BERTopic für verschiedene Anwendungen äußerst flexibel ist.
Schlüsselkomponenten der BERTopic-Pipeline
1. Vorverarbeitung
Der erste Schritt besteht darin, Rohtextdaten aufzubereiten. Im Gegensatz zu herkömmlichen NLP-Pipelines erfordert BERTopic keine umfangreiche Vorverarbeitung. Eine minimale Reinigung, z. B. Kleinschreibung, Entfernen zusätzlicher Leerzeichen und Filtern sehr kurzer Dokumente, reicht normalerweise aus.
2. Einbettungen von Dokumenten
Jedes Dokument wird mithilfe transformatorbasierter Modelle wie SentenceTransformers in einen dichten Vektor umgewandelt. Dadurch kann das Modell semantische Beziehungen zwischen Dokumenten erfassen.
Mathematisch:
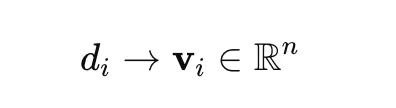
Wo dich ist ein Dokument und vich ist seine Vektordarstellung.
3. Dimensionsreduktion
Es ist schwierig, hochdimensionale Einbettungen effektiv zu gruppieren. BERTopic verwendet UMAP, um die Dimensionalität zu reduzieren und gleichzeitig die Struktur der Daten beizubehalten.
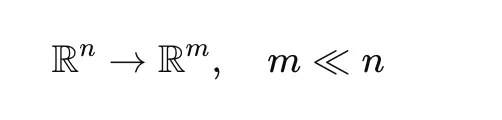
Dieser Schritt verbessert die Clustering-Leistung und die Recheneffizienz.
4. Clustering
Nach der Dimensionsreduzierung wird das Clustering mit HDBSCAN durchgeführt. Dieser Algorithmus gruppiert ähnliche Dokumente in Clustern und identifiziert Ausreißer.
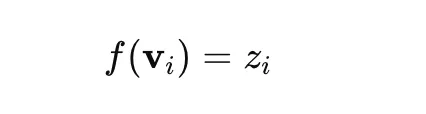
Wo zich ist die zugewiesene Themenbezeichnung. Dokumente mit der Bezeichnung −1 gelten als Ausreißer.
5. c-TF-IDF-Themendarstellung
Sobald Cluster gebildet sind, generiert BERTopic Themendarstellungen mithilfe von c-TF-IDF.
Begriffshäufigkeit:
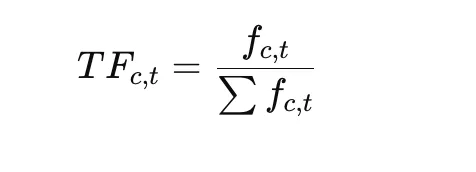
Inverse Klassenfrequenz:
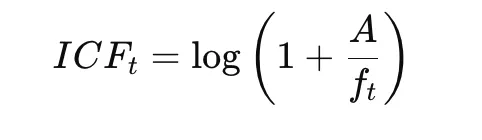
Endgültiges c-TF-IDF:
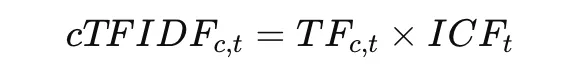
Diese Methode hebt Wörter hervor, die sich innerhalb eines Clusters unterscheiden, während gleichzeitig die Bedeutung gemeinsamer Wörter in Clustern verringert wird.
Praxisnahe Umsetzung
In diesem Abschnitt wird eine einfache Implementierung von BERTopic anhand eines sehr kleinen Datensatzes demonstriert. Das Ziel besteht hier nicht darin, ein Themenmodell im Produktionsmaßstab zu erstellen, sondern Schritt für Schritt zu verstehen, wie BERTopic funktioniert. In diesem Beispiel verarbeiten wir den Textual content vor, konfigurieren UMAP und HDBSCAN, trainieren das BERTopic-Modell und prüfen die generierten Themen.
Schritt 1: Bibliotheken importieren und den Datensatz vorbereiten
import re
import umap
import hdbscan
from bertopic import BERTopic
docs = (
"NASA launched a satellite tv for pc",
"Philosophy and faith are associated",
"House exploration is rising"
) In diesem ersten Schritt werden die benötigten Bibliotheken importiert. Das re-Modul wird für die grundlegende Textvorverarbeitung verwendet, während umap und hdbscan für die Dimensionsreduzierung und das Clustering verwendet werden. BERTopic ist die Hauptbibliothek, die diese Komponenten in einer Themenmodellierungspipeline kombiniert.
Außerdem wird eine kleine Liste mit Musterdokumenten erstellt. Diese Dokumente gehören zu verschiedenen Themen wie Raumfahrt und Philosophie, was sie nützlich macht, um zu veranschaulichen, wie BERTopic versucht, Texte in verschiedene Themen zu unterteilen.
Schritt 2: Den Textual content vorverarbeiten
def preprocess(textual content):
textual content = textual content.decrease()
textual content = re.sub(r"s+", " ", textual content)
return textual content.strip()
docs = (preprocess(doc) for doc in docs)Dieser Schritt führt eine grundlegende Textbereinigung durch. Jedes Dokument wird in Kleinbuchstaben umgewandelt, sodass Wörter wie „NASA“ und „nasa“ als dasselbe Token behandelt werden. Außerdem werden zusätzliche Leerzeichen entfernt, um die Formatierung zu standardisieren.
Die Vorverarbeitung ist wichtig, da sie das Rauschen in der Eingabe reduziert. Obwohl BERTopic Transformer-Einbettungen verwendet, die weniger von einer umfassenden Textbereinigung abhängig sind, verbessert eine einfache Normalisierung dennoch die Konsistenz und macht die Eingabe für die nachgelagerte Verarbeitung sauberer.
Schritt 3: UMAP konfigurieren
umap_model = umap.UMAP(
n_neighbors=2,
n_components=2,
min_dist=0.0,
metric="cosine",
random_state=42,
init="random"
)UMAP wird hier verwendet, um die Dimensionalität der Dokumenteinbettungen vor dem Clustering zu reduzieren. Da Einbettungen in der Regel hochdimensional sind, ist es oft schwierig, sie direkt zu gruppieren. UMAP hilft, indem es sie in einen niedrigerdimensionalen Raum projiziert und gleichzeitig ihre semantischen Beziehungen beibehält.
Der Parameter init=“random“ ist in diesem Beispiel besonders wichtig, da der Datensatz extrem klein ist. Bei nur drei Dokumenten schlägt die standardmäßige spektrale Initialisierung von UMAP möglicherweise fehl. Daher wird eine zufällige Initialisierung verwendet, um diesen Fehler zu vermeiden. Die Einstellungen n_neighbors=2 und n_components=2 werden passend zu diesem kleinen Datensatz gewählt.
Schritt 4: HDBSCAN konfigurieren
hdbscan_model = hdbscan.HDBSCAN(
min_cluster_size=2,
metric="euclidean",
cluster_selection_method="eom",
prediction_data=True
)HDBSCAN ist der von BERTopic verwendete Clustering-Algorithmus. Seine Aufgabe besteht darin, ähnliche Dokumente nach Dimensionsreduzierung zu gruppieren. Im Gegensatz zu Methoden wie Ok-Means erfordert HDBSCAN keine vorherige Angabe der Anzahl der Cluster.
Hier, min_cluster_size=2 bedeutet, dass zur Bildung eines Clusters mindestens zwei Dokumente erforderlich sind. Dies ist für ein so kleines Beispiel angemessen. Der vorhersage_data=Wahr Das Argument ermöglicht es dem Modell, Informationen zu behalten, die für spätere Schlussfolgerungen und Wahrscheinlichkeitsschätzungen nützlich sind.
Schritt 5: Erstellen Sie das BERTopic-Modell
topic_model = BERTopic(
umap_model=umap_model,
hdbscan_model=hdbscan_model,
calculate_probabilities=True,
verbose=True
) In diesem Schritt wird das BERTopic-Modell durch Übergabe der benutzerdefinierten UMAP- und HDBSCAN-Konfigurationen erstellt. Hier zeigt sich eine der Stärken von BERTopic: Es ist modular aufgebaut, sodass einzelne Komponenten je nach Datensatz und Anwendungsfall individuell angepasst werden können.
Die Choice „calcture_probabilities=True“ ermöglicht es dem Modell, Themenwahrscheinlichkeiten für jedes Dokument abzuschätzen. Die Choice verbose=True ist während des Experimentierens nützlich, da sie den Fortschritt und interne Verarbeitungsschritte anzeigt, während das Modell ausgeführt wird.
Schritt 6: Passen Sie das BERTopic-Modell an
matters, probs = topic_model.fit_transform(docs) Dies ist der Haupttrainingsschritt. BERTopic führt nun die komplette Pipeline intern aus:
- Es wandelt Dokumente in Einbettungen um
- Es reduziert die Einbettungsdimensionen mithilfe von UMAP
- Es gruppiert die reduzierten Einbettungen mithilfe von HDBSCAN
- Es extrahiert Themenwörter mithilfe von c-TF-IDF
Das Ergebnis wird in zwei Ausgaben gespeichert:
- Themen, das die zugewiesene Themenbezeichnung für jedes Dokument enthält
- probs, das die Wahrscheinlichkeitsverteilung oder Konfidenzwerte für die Zuweisungen enthält
Dies ist der Punkt, an dem die Rohdokumente in eine themenbasierte Struktur umgewandelt werden.
Schritt 7: Themenzuweisungen und Themeninformationen anzeigen
print("Matters:", matters)
print(topic_model.get_topic_info())
for topic_id in sorted(set(matters)):
if topic_id != -1:
print(f"nTopic {topic_id}:")
print(topic_model.get_topic(topic_id))
Dieser letzte Schritt wird verwendet, um die Ausgabe des Modells zu überprüfen.
print("Matters:", matters)Zeigt die jedem Dokument zugewiesene Themenbezeichnung an.get_topic_info()Zeigt eine Übersichtstabelle aller Themen an, einschließlich Themen-IDs und der Anzahl der Dokumente in jedem Thema.get_topic(topic_id)gibt die wichtigsten repräsentativen Wörter für ein bestimmtes Thema zurück.
Die Bedingung if topic_id != -1 schließt Ausreißer aus. In BERTopic bedeutet eine Themenbezeichnung von -1, dass das Dokument keinem Cluster sicher zugeordnet wurde. Dies ist ein normales Verhalten beim dichtebasierten Clustering und trägt dazu bei, nicht verwandte Dokumente in falsche Themen zu zwingen.
Vorteile von BERTopic
Hier sind die Hauptvorteile der Verwendung von BERTopic:
- Erfasst semantische Bedeutung mithilfe von Einbettungen
BERTopic verwendet transformatorbasierte Einbettungen, um den Textkontext und nicht nur die Worthäufigkeit zu verstehen. Dadurch können Dokumente mit ähnlicher Bedeutung gruppiert werden, auch wenn sie unterschiedliche Wörter verwenden. - Bestimmt automatisch die Anzahl der Themen
Mit HDBSCAN erfordert BERTopic keine vordefinierte Anzahl von Themen. Es erkennt die natürliche Struktur der Daten und macht sie für unbekannte oder sich entwickelnde Datensätze geeignet. - Behandelt Rauschen und Ausreißer effektiv
Dokumente, die nicht eindeutig zu einem Cluster gehören, werden als Ausreißer gekennzeichnet, anstatt in falsche Themen gezwungen zu werden. Dies verbessert die Gesamtqualität und Klarheit der Themen. - Erstellt interpretierbare Themendarstellungen
Mit c-TF-IDF extrahiert BERTopic Schlüsselwörter, die jedes Thema klar darstellen. Diese Wörter sind eindeutig und leicht verständlich, sodass die Interpretation einfach ist. - Hochmodular und anpassbar
Jeder Teil der Pipeline kann angepasst oder ersetzt werden, z. B. Einbettungen, Clustering oder Vektorisierung. Diese Flexibilität ermöglicht die Anpassung an verschiedene Datensätze und Anwendungsfälle.
Abschluss
BERTopic stellt einen bedeutenden Fortschritt in der Themenmodellierung dar, indem es semantische Einbettungen, Dimensionsreduktion, Clustering und klassenbasiertes TF-IDF kombiniert. Dieser hybride Ansatz ermöglicht die Erstellung bedeutungsvoller und interpretierbarer Themen, die besser mit dem menschlichen Verständnis übereinstimmen.
Anstatt sich ausschließlich auf die Worthäufigkeit zu verlassen, nutzt BERTopic die Struktur des semantischen Raums, um Muster in Textdaten zu identifizieren. Dank seines modularen Aufbaus ist es außerdem an eine Vielzahl von Anwendungen anpassbar, von der Analyse von Kundenfeedback bis hin zur Organisation von Forschungsdokumenten.
In der Praxis hängt die Wirksamkeit von BERTopic von der sorgfältigen Auswahl der Einbettungen, der Abstimmung der Clustering-Parameter und der sorgfältigen Auswertung der Ergebnisse ab. Bei richtiger Anwendung bietet es eine leistungsstarke und praktische Lösung für moderne Themenmodellierungsaufgaben.
Häufig gestellte Fragen
A. Es verwendet semantische Einbettungen anstelle der Worthäufigkeit, wodurch Kontext und Bedeutung effektiver erfasst werden können.
A. Es verwendet HDBSCAN-Clustering, das automatisch die natürliche Anzahl von Themen ohne vordefinierte Eingabe erkennt.
A. Aufgrund der eingebetteten Generierung ist es rechenintensiv, insbesondere bei großen Datensätzen.
Hallo, ich bin Janvi, ein leidenschaftlicher Information-Science-Fanatic, der derzeit bei Analytics Vidhya arbeitet. Meine Reise in die Welt der Daten begann mit einer tiefen Neugier, wie wir aus komplexen Datensätzen aussagekräftige Erkenntnisse gewinnen können.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.