
Bild von Autor | Ideogramm
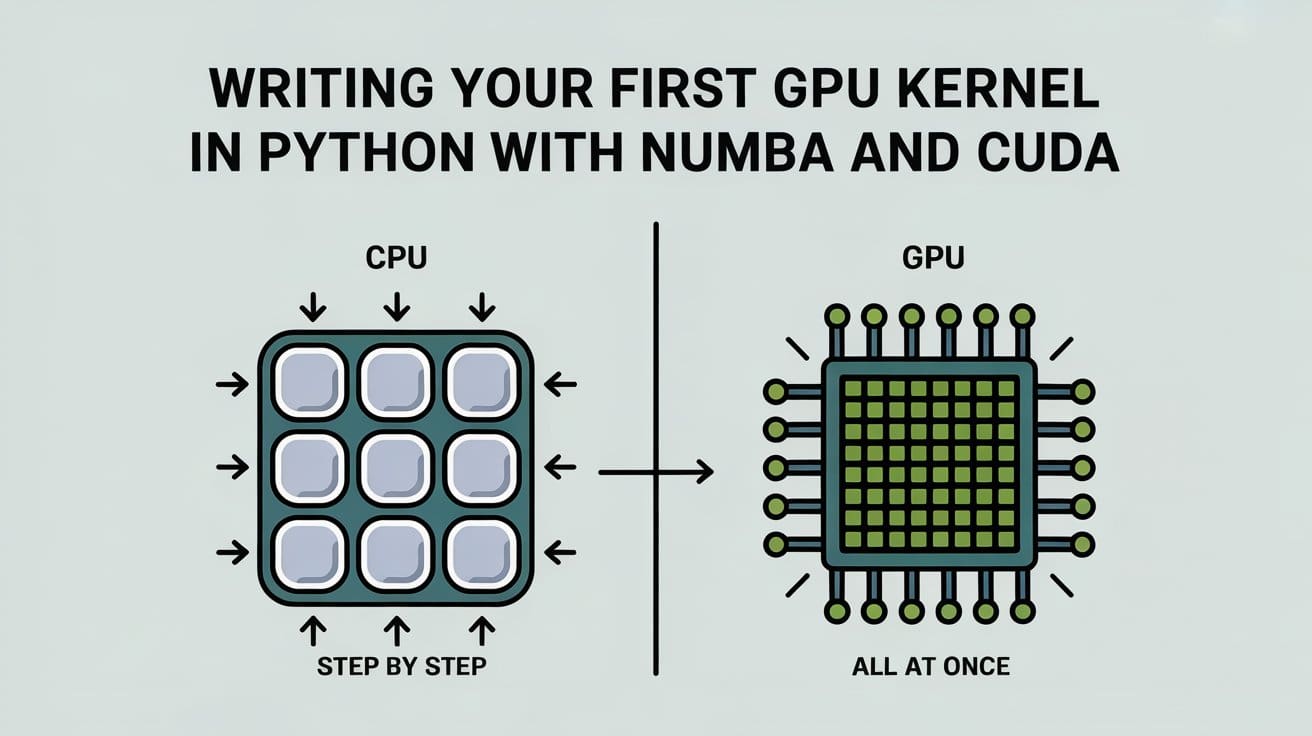
GPUs eignen sich hervorragend für Aufgaben, bei denen Sie den gleichen Betrieb über verschiedene Datenstücke hinweg ausführen müssen. Dies ist als die bekannt Einzelanweisung, mehrere Daten (SIMD) Ansatz. Im Gegensatz zu CPUs, die nur wenige leistungsstarke Kerne haben, haben GPUs Tausende kleinerer, die diese sich wiederholten Operationen auf einmal ausführen können. Sie sehen dieses Muster im maschinellen Lernen viel, beispielsweise beim Hinzufügen oder Multiplizieren großer Vektoren, da jede Berechnung unabhängig ist. Dies ist das ideale Szenario für die Verwendung von GPUs, um die Aufgaben parallelität zu beschleunigen.
Nvidia erstellt CUDA als eine Möglichkeit für Entwickler, Programme zu schreiben, die auf der GPU anstelle der CPU ausgeführt werden. Es basiert auf C und ermöglicht es Ihnen, spezielle Funktionen mit dem Namen Kernel zu schreiben, die viele Operationen gleichzeitig ausführen können. Das Downside ist, dass das Schreiben von CUDA in C oder C ++ nicht gerade anfängerfreundlich ist. Sie müssen sich mit Dingen wie Schaltspeicherzuweisung, Thread -Koordination und dem Verständnis der Funktionsweise der GPU auf einer niedrigen Ebene befassen. Dies kann überwältigend sein, insbesondere wenn Sie es gewohnt sind, Code in Python zu schreiben.
Hier Numba kann Ihnen helfen. Es ermöglicht das Schreiben von Cuda-Kerneln mit Python mit der Compiler-Infrastruktur von LLVM (Digital Machine), um Ihren Python-Code direkt zu CUDA-kompatiblen Kerneln zu kompilieren. Mit Simply-in-Time (JIT) -Kompilation können Sie Ihre Funktionen mit einem Dekorateur kommentieren und Numba alles andere für Sie behandelt.
In diesem Artikel werden wir ein gemeinsames Beispiel für die Addition des Vektors verwenden und einfachen CPU -Code in einen Cuda -Kernel mit Numba konvertieren. Die Addition der Vektor ist ein ideales Beispiel für die Parallelität, da die Zugabe über einen einzelnen Index unabhängig von anderen Indizes ist. Dies ist das perfekte SIMD -Szenario, sodass alle Indizes gleichzeitig hinzugefügt werden können, um die Vektor -Addition in einem Vorgang zu vervollständigen.
Beachten Sie, dass Sie eine CUDA -GPU benötigen, um diesem Artikel zu folgen. Sie können verwenden Colabs Kostenlose T4 -GPU oder eine lokale GPU mit NVIDIA -Toolkit und NVCC installiert.
# Einrichten der Umgebung und Set up von Numba
Numba ist als Python -Paket erhältlich und Sie können es mit PIP installieren. Darüber hinaus werden wir verwenden Numpy Für Vektoroperationen. Richten Sie die Python -Umgebung mit den folgenden Befehlen ein:
python3 -m venv venv
supply venv/bin/activate
pip set up numba-cuda numpy# Vektoraddition auf der CPU
Nehmen wir ein einfaches Beispiel für die Addition von Vektor. Für zwei gegebene Vektoren fügen wir die entsprechenden Werte aus jedem Index hinzu, um den Endwert zu erhalten. Wir werden Numpy verwenden, um zufällige Float32 -Vektoren zu erzeugen und die endgültige Ausgabe mit A for Loop zu generieren.
import numpy as np
N = 10_000_000 # 10 million components
a = np.random.rand(N).astype(np.float32)
b = np.random.rand(N).astype(np.float32)
c = np.zeros_like(a) # Output array
def vector_add_cpu(a, b, c):
"""Add two vectors on CPU"""
for i in vary(len(a)):
c(i) = a(i) + b(i)Hier ist eine Aufschlüsselung des Codes:
- Initialisieren Sie jeweils zwei Vektoren mit 10 Millionen zufälligen Gleitkomma-Zahlen
- Wir erstellen auch einen leeren Vektor
cdas Ergebnis speichern - Der
vector_add_cpuFunktion schaltet einfach jeden Index durch und fügt die Elemente ausaUndbdas Ergebnis speichernc
Dies ist a Serienbetrieb; Jede Zugabe erfolgt nacheinander. Dies funktioniert zwar einwandfrei, ist jedoch nicht der effizienteste Ansatz, insbesondere für große Datensätze. Da jede Ergänzung unabhängig von den anderen ist, ist dies ein perfekter Kandidat für die parallele Ausführung bei einer GPU.
Im nächsten Abschnitt sehen Sie, wie Sie dieselbe Operation für die GPU mit Numba konvertieren. Durch die Verteilung der einzelnen Elemente über Tausende von GPU-Threads können wir die Aufgabe erheblich schneller erledigen.
# Vektor Addition auf der GPU mit Numba
Sie werden nun Numba verwenden, um eine Python -Funktion zu definieren, die auf CUDA ausgeführt werden kann, und sie innerhalb von Python ausführen kann. Wir führen den gleichen Vektor -Addition -Betrieb durch, aber jetzt kann es für jeden Index des Numpy -Arrays parallel ausgeführt werden, was zu einer schnelleren Ausführung führt.
Hier ist der Code zum Schreiben des Kernels:
from numba import config
# Required for newer CUDA variations to allow linking instruments.
# Prevents CUDA toolkit and NVCC model mismatches.
config.CUDA_ENABLE_PYNVJITLINK = 1
from numba import cuda, float32
@cuda.jit
def vector_add_gpu(a, b, c):
"""Add two vectors utilizing CUDA kernel"""
# Thread ID within the present block
tx = cuda.threadIdx.x
# Block ID within the grid
bx = cuda.blockIdx.x
# Block width (variety of threads per block)
bw = cuda.blockDim.x
# Calculate the distinctive thread place
place = tx + bx * bw
# Be certain that we do not exit of bounds
if place < len(a):
c(place) = a(place) + b(place)
def gpu_add(a, b, c):
# Outline the grid and block dimensions
threads_per_block = 256
blocks_per_grid = (N + threads_per_block - 1) // threads_per_block
# Copy knowledge to the machine
d_a = cuda.to_device(a)
d_b = cuda.to_device(b)
d_c = cuda.to_device(c)
# Launch the kernel
vector_add_gpu(blocks_per_grid, threads_per_block)(d_a, d_b, d_c)
# Copy the consequence again to the host
d_c.copy_to_host(c)
def time_gpu():
c_gpu = np.zeros_like(a)
gpu_add(a, b, c_gpu)
return c_gpuLassen Sie uns aufschlüsseln, was oben passiert.
// Verständnis der GPU -Funktion
Der @cuda.jit Der Dekorateur fordert Numba auf, die folgende Funktion als Cuda -Kernel zu behandeln. Eine spezielle Funktion, die parallel über viele Threads der GPU ausgeführt wird. Zur Laufzeit kompiliert Numba diese Funktion mit CUDA-kompatiblen Code und verarbeitet die C-API-Transpilation für Sie.
@cuda.jit
def vector_add_gpu(a, b, c):
...Diese Funktion wird gleichzeitig auf Tausenden von Threads ausgeführt. Wir brauchen jedoch eine Möglichkeit, herauszufinden, an welchem Teil der Daten jeder Thread funktionieren sollte. Das tun die nächsten Zeilen:
txist die ID des Threads in seinem Blockbxist die ID des Blocks im Netzbwist wie viele Fäden in einem Block sind
Wir kombinieren diese mit Berechnen Sie eine einzigartige Placewas jedem Thread mitteilt, welches Component der Arrays es hinzufügen sollte. Beachten Sie, dass die Threads und Blöcke möglicherweise nicht immer einen gültigen Index liefern, da sie in Befugnissen von 2. wirken. Dies kann zu ungültigen Indizes führen, wenn die Vektorlänge nicht der zugrunde liegenden Architektur entspricht. Daher fügen wir eine Schutzbedingung hinzu, um den Index zu validieren, bevor wir die Vektor -Addition durchführen. Dies verhindert, dass beim Zugriff auf das Array einen außergewöhnlichen Laufzeitfehler ist.
Sobald wir die einzigartige Place kennen, können wir die Werte jetzt genau wie für die CPU -Implementierung hinzufügen. Die folgende Zeile entspricht der CPU -Implementierung:
c(place) = a(place) + b(place)// Begin des Kernels
Der gpu_add Funktion stellt Dinge auf:
- Es definiert, wie viele Themen und Blöcke verwendet werden sollen. Sie können mit unterschiedlichen Werten der Block- und Fadengrößen experimentieren und die entsprechenden Werte im GPU -Kernel drucken. Dies kann Ihnen helfen, zu verstehen, wie die zugrunde liegende GPU -Indexierung funktioniert.
- Es kopiert die Eingangsarrays (
aAnwesendbUndc) vom CPU -Speicher zum GPU -Speicher, sodass die Vektoren im GPU -RAM zugänglich sind. - Es führt den GPU -Kernel mit
vector_add_gpu(blocks_per_grid, threads_per_block). - Schließlich kopiert es das Ergebnis von der GPU zurück in die
cArray, damit wir auf die Werte der CPU zugreifen können.
# Vergleich der Implementierungen und der potenziellen Beschleunigung
Jetzt, da wir sowohl die CPU- als auch die GPU -Versionen von Vektorabzug haben, ist es Zeit zu sehen, wie sie sich vergleichen. Es ist wichtig, die Ergebnisse und den Ausführungsschub zu überprüfen, den wir mit CUDA -Parallelität erhalten können.
import timeit
c_cpu = time_cpu()
c_gpu = time_gpu()
print("Outcomes match:", np.allclose(c_cpu, c_gpu))
cpu_time = timeit.timeit("time_cpu()", globals=globals(), quantity=3) / 3
print(f"CPU implementation: {cpu_time:.6f} seconds")
gpu_time = timeit.timeit("time_gpu()", globals=globals(), quantity=3) / 3
print(f"GPU implementation: {gpu_time:.6f} seconds")
speedup = cpu_time / gpu_time
print(f"GPU speedup: {speedup:.2f}x")Zunächst führen wir beide Implementierungen aus und überprüfen, ob ihre Ergebnisse übereinstimmen. Dies ist wichtig, um sicherzustellen, dass unser GPU -Code korrekt funktioniert und die Ausgabe mit den CPUs übereinstimmt.
Als nächstes verwenden wir Pythons integriert timeit Modul, um zu messen, wie lange jede Model dauert. Wir führen jede Funktion ein paar Mal aus und nehmen den Durchschnitt, um ein zuverlässiges Timing zu erhalten. Schließlich berechnen wir, wie oft schneller die GPU -Model mit der CPU verglichen wird. Sie sollten einen großen Unterschied sehen, da die GPU viele Operationen gleichzeitig ausführen kann, während die CPU sie jeweils in einer Schleife umgeht.
Hier ist die erwartete Ausgabe der T4 -GPU von NVIDIA auf Colab. Beachten Sie, dass sich die genaue Beschleunigung basierend auf CUDA -Versionen und der zugrunde liegenden {Hardware} unterscheiden kann.
Outcomes match: True
CPU implementation: 4.033822 seconds
GPU implementation: 0.047736 seconds
GPU speedup: 84.50xDieser einfache Take a look at hilft, die Leistung der GPU -Beschleunigung zu demonstrieren und warum er für Aufgaben, die große Datenmengen und parallele Arbeiten beinhalten, so nützlich ist.
# Einpacken
Und das ist es. Sie haben jetzt Ihren ersten Cuda -Kernel mit Numba geschrieben, ohne tatsächlich einen C- oder CUDA -Code zu schreiben. Numba ermöglicht eine einfache Schnittstelle zur Verwendung der GPU durch Python und macht es für Python -Ingenieure viel einfacher, mit CUDA -Programmierung zu beginnen.
Sie können jetzt dieselbe Vorlage verwenden, um erweiterte CUDA -Algorithmen zu schreiben, die im maschinellen Lernen und im tiefen Lernen häufig vorkommen. Wenn Sie nach dem SIMD -Paradigma ein Downside finden, ist es immer eine gute Idee, GPU zur Verbesserung der Ausführung zu verwenden.
Der komplette Code ist in Colab Pocket book verfügbar, auf das Sie zugreifen können Hier. Fühlen Sie sich frei, es zu testen und einfache Änderungen vorzunehmen, um ein besseres Verständnis dafür zu erhalten, wie CUDA -Indexierung und Ausführung intern funktioniert.
Kanwal Mehreen ist ein Ingenieur für maschinelles Lernen und technischer Schriftsteller mit einer tiefgreifenden Leidenschaft für die Datenwissenschaft und die Schnittstelle von KI mit Medizin. Sie hat das eBook „Produktivität mit Chatgpt maximieren“. Als Google -Era -Gelehrte 2022 für APAC setzt sie sich für Vielfalt und akademische Exzellenz ein. Sie wird auch als Teradata -Vielfalt in Tech Scholar, MITACS Globalink Analysis Scholar und Harvard Wecode Scholar anerkannt. Kanwal ist ein leidenschaftlicher Verfechter der Veränderung, nachdem er Femcodes gegründet hat, um Frauen in STEM -Bereichen zu stärken.