
Die Bildverarbeitung hat mit Veröffentlichungen wie Nano Banana und Qwen Picture einen Aufschwung erlebt und die Grenzen des bisher Möglichen erweitert. Von der falschen Anzahl an Fingern und Tippfehlern im Textual content sind wir weit entfernt. Diese Modelle können lebensechte Bilder und Illustrationen erzeugen, die die Arbeit eines Designers nachahmen. Die neueste Model von Meta, SAM3, soll einen eigenen Beitrag zu diesem Ökosystem leisten. Mit einem einheitlichen Ansatz zur Erkennung, Segmentierung und Nachverfolgung verleiht es visuellen Inhalten Struktur und Verständnis, anstatt sie nur zu generieren.
In diesem Artikel erfahren Sie, was SAM3 ist, warum es in der Branche für Aufsehen sorgt und wie Sie es in die Hände bekommen können.
Was ist SAM3?
SAM3 oder Section Something Mannequin 3 ist eine nächste Era Laptop-Imaginative and prescient-Modell zur Segmentierung und Nachverfolgung in Bildern und Movies, die Textual content oder Eingabeaufforderungen (z. B. ein Bildbeispiel) und nicht nur feste Klassenbezeichnungen erfordert. Dies ist die Objekterkennung und -extraktion, die zugrunde liegt KI angetriebene Erkennung. Während vorhandene Modelle allgemeine Konzepte wie Mensch, Tabelle usw. segmentieren können, kann SAM3 differenziertere Konzepte wie segmentieren „Der Typ mit dem Ananashemd“.
SAM3 überwindet die oben genannten Einschränkungen mithilfe des Promptable-Konzepts Segmentierung Fähigkeit. Es kann alles, was Sie in einem Bild oder Video wünschen, finden und isolieren, unabhängig davon, ob Sie es mit einem kurzen Satz beschreiben oder ein Beispiel zeigen, ohne sich auf eine feste Liste von Objekttypen verlassen zu müssen.
Wie greife ich auf SAM3 zu?
Hier sind einige Möglichkeiten, wie Sie auf das SAM3-Modell zugreifen können:
Webbasierter Spielplatz/Demo: Es gibt ein Webinterface „Segmentieren Sie den Spielplatz“, wo Sie ein Bild oder Video hochladen, eine Textaufforderung (oder ein Beispiel) bereitstellen und mit der Segmentierungs- und Monitoring-Funktionalität von SAM 3 experimentieren können.
Modellgewichte + Code auf GitHub: Das offizielle Repository von Meta Analysis (facebookresearch/sam3) enthält Code für Inferenz und Feinabstimmung sowie Hyperlinks zum Herunterladen trainierter Modellprüfpunkte.
Hugging Face-Modellhub: Das Modell ist auf Hugging Face verfügbar (fb/sam3) mit Beschreibung, wie das Modell geladen wird, Beispielverwendung für Bilder/Movies.
Weitere Möglichkeiten zum Zugriff auf das Modell finden Sie auf der offiziellen Veröffentlichungsseite von SAM3.
Praktische Implementierung von SAM3
Machen wir uns die Hände schmutzig. Um zu sehen, wie intestine SAM3 funktioniert, würde ich es anhand der beiden Aufgaben testen:
- Bildsegmentierung
- Videosegmentierung
Bildsegmentierung
Während die meisten Leute versuchen würden, verschiedene Arten von Objekten innerhalb des Bildes herauszufinden, dachte ich, es wäre besser, wenn ich es bei einer praktischeren Arbeitsbelastung versuche. Für diese Aufgabe würde ich ihm additionally ein Bild präsentieren, das aus einer Reihe von Tabellen besteht, um zu sehen, wie intestine es diese erkennt und abgrenzt. Dies ist eine der am häufigsten verwendeten Aufgaben für Bildprozessoren.
Eingabebild:
Antwort:
Nach dem Betreten erhielt ich folgende Antwort Tische im Überprüfen Sie Objekte Kasten.
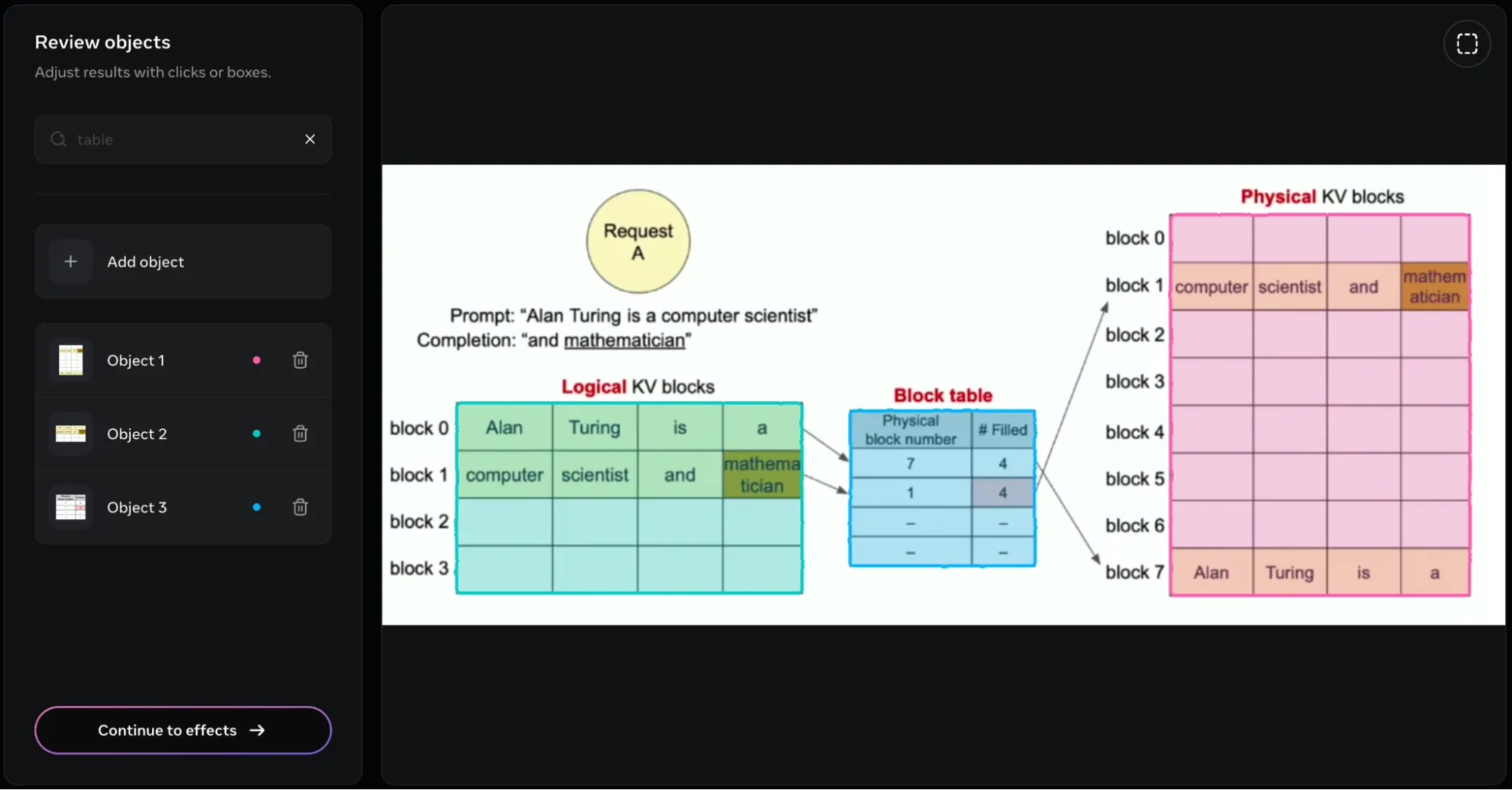
Das Modell konnte einen Begrenzungsrahmen um alle im Bild vorhandenen Tabellen erstellen. Es präsentiert die 3 Tabellen in Type von 3 Objekten, die wir separat benennen und ändern können. Aber das ist es nicht. Wir können zusätzlich verschiedene Effekte auf die im Bild erkannten Objekte hinzufügen. Im folgenden Bild hatte ich das hinzugefügt verwischen Wirkung:

Sie können die Intensität dieser Effekte auch ändern, indem Sie die Effekteinstellungen direkt neben dem Effektnamen verwenden.
Videosegmentierung
Für die Videosegmentierung würde ich testen, wie intestine das Modell Menschen über das Fußballfeld verfolgt, wobei sich der Kamerawinkel und der Zoom entsprechend ändern. Zur Demonstration würde ich diesen Clip von Lionel Messis Tor verwenden:
Antwort:
Ich habe die folgende Antwort erhalten, nachdem ich das Objekt als bereitgestellt habe Spieler:
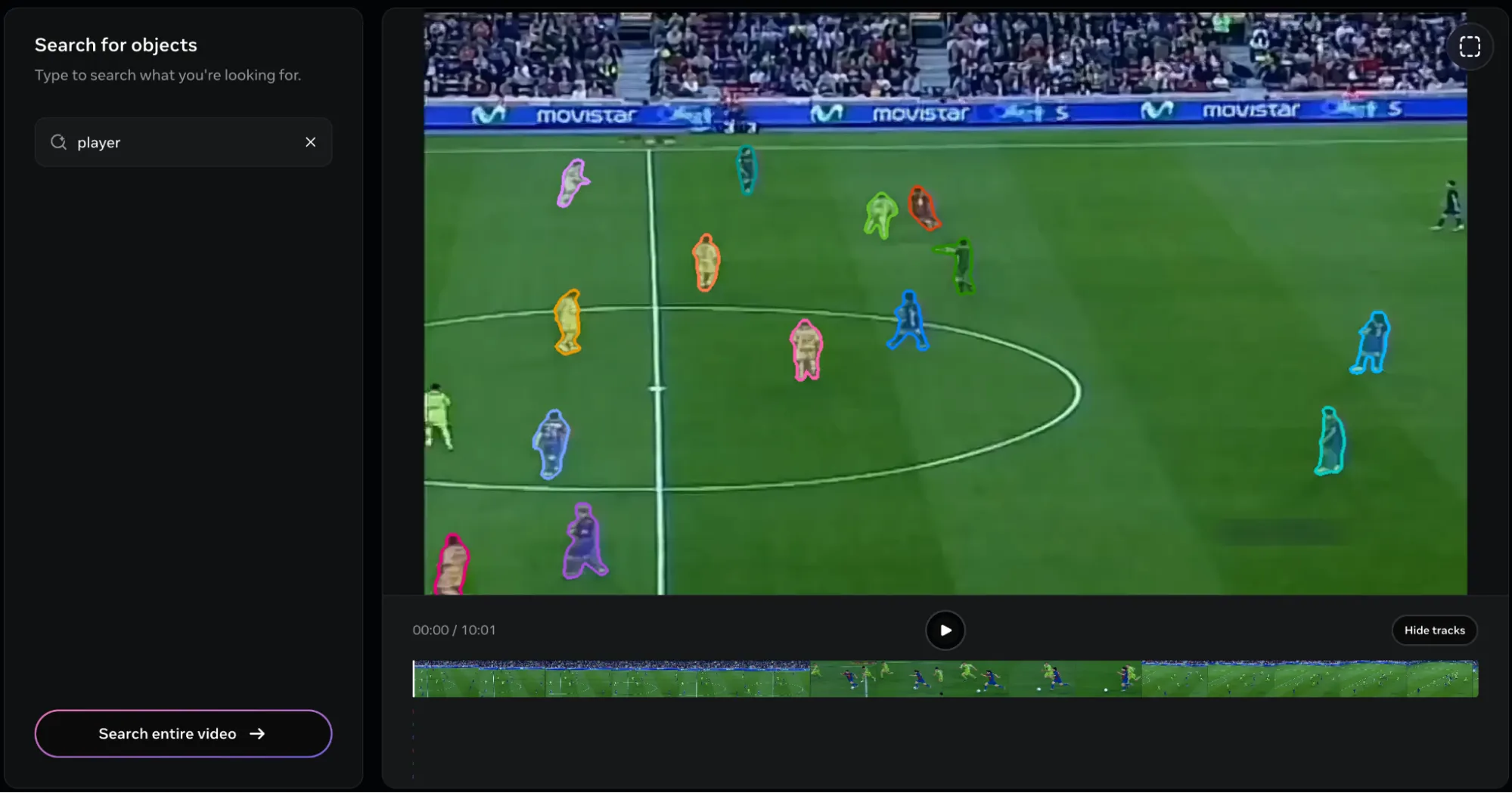
Angesichts der umfassenden Objektbeschreibung ist es verständlich, dass das Modell alle Spieler im Clip markiert hat. Aber hier liegt das Downside. Es gibt keine Möglichkeit, einen einzelnen Spieler herauszugreifen!
Ich habe versucht, beschreibende Beschreibungen wie „Dribbler“, „Stürmer“, „Flügelspieler“ und viele mehr zu verwenden, aber die einzige, die zufriedenstellende Ergebnisse lieferte, warfare Spieler. Und sobald die Spieler ausgewählt wurden, gibt es keine Möglichkeit, sie aus der Liste zu entfernen. Das ist eigenartig, da ich bei der Bildsegmentierungsaufgabe das ROI-Software (oben rechts im Software) verwendet habe, um den Spieler zu markieren, der mich interessiert. Aber bei Movies ist es fehlerhaft.
Eine weitere Sache, die mir auffiel, warfare, dass das Video 45 Sekunden lang warfare, im Videoplayer jedoch nur 10 Sekunden.
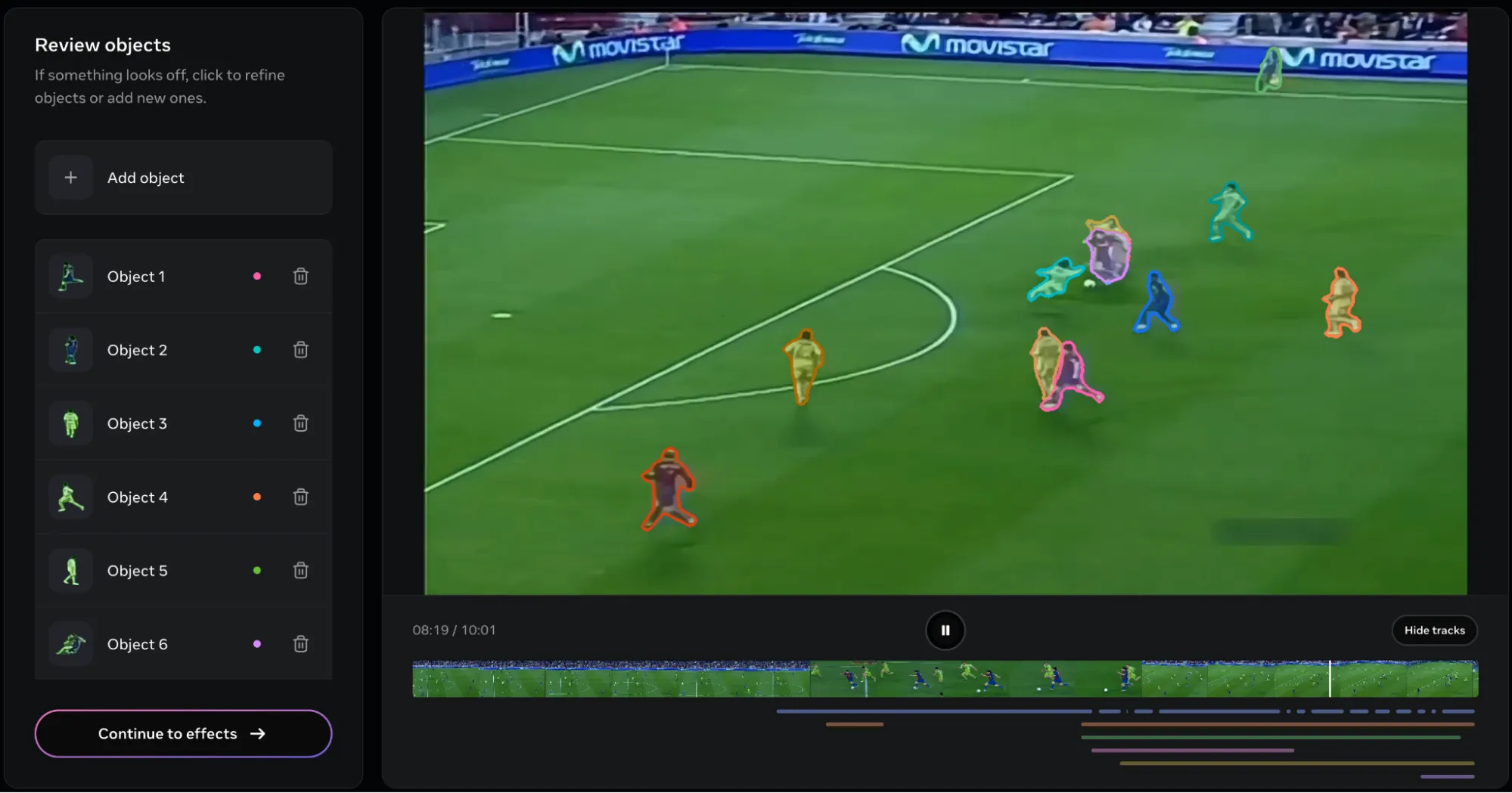
Das ist das Ergebnis. Wie Sie sehen können, wurden letztendlich alle Spieler verfolgt. Hier ist ein weiteres Downside. Es ist viel zu schwierig, die Gegenstände zu entfernen. Selbst wenn ein einzelnes Objekt entfernt wird, würde das gesamte Video neu gerendert werden, was eine zeitaufwändige Angelegenheit wäre, insbesondere wenn mehrere Objekte (24 in diesem Clip) entfernt werden sollen.
Falls es Sie interessiert, hier ist der letzte Clip:
Urteil
Das Modell ist auf jeden Fall dazu in der Lage. Die Möglichkeit, nicht nur Objekte im Bild vorzuschlagen, sondern sie auch anhand von Eingaben herauszufinden, ist mit Sicherheit ein großes Characteristic. Das Modell verarbeitet sowohl Bilder als auch Movies in kurzer Zeit, was ein großes Plus ist. Die Bildsegmentierung hat mich weit mehr beeindruckt als der Videosegmentierungsmodus. Aber wenn Sie wirklich verzweifelt wären, könnten Sie wahrscheinlich mit den Einschränkungen der Videosegmentierung arbeiten.
Hier sind ein paar Dinge, die ich bei der Verwendung von SAM3 empfehlen würde:
- Verwenden Sie nach Möglichkeit die ROI-Markierung, um das Objekt Ihrer Wahl hervorzuheben.
- Wenn Movies länger als 10 Sekunden sind, teilen Sie sie in mehrere Teile von 10 Sekunden auf.
- Versuchen Sie nach dem Hochladen der Medien, die Aufgabe innerhalb von 5 Minuten abzuschließen, andernfalls könnte ein Serverfehler auftreten:

Abschluss
SAM3 ist das Beste, wenn es darum geht, den Zugang zu modernsten Bildverarbeitungstools und Filtern zu erleichtern. Was es an Bildern bietet, ist bahnbrechend, während seine Videosegmentierungsfunktionen großes Potenzial haben. SAM3 gepaart mit SAM3D macht es zum unverzichtbaren Software für jeden Bildbegeisterten, der seine Arbeitslasten mit KI-Unterstützung ausstatten möchte. Die Modelle werden derzeit verbessert und ihre Funktionen werden sich mit der Zeit weiterentwickeln.
Häufig gestellte Fragen
A. SAM3 kann Objekte anhand kurzer Textaufforderungen oder Beispielbilder segmentieren, nicht nur anhand vordefinierter Beschriftungen. Es versteht spezifischere Konzepte wie „Der Typ mit dem Ananashemd“ und funktioniert sowohl mit Bildern als auch mit Movies.
A. Sie können es über den webbasierten Section Something Playground ausprobieren, die Gewichte und den Code von GitHub herunterladen oder es vom Hugging Face-Modell-Hub laden.
A. Bei der Videosegmentierung gibt es noch einige Einschränkungen. Es kann schwierig sein, ein einzelnes Objekt aus einer breiten Klasse zu isolieren, das Entfernen von Objekten erzwingt ein erneutes Rendern und Clips, die länger als 10 Sekunden dauern, müssen möglicherweise aufgeteilt werden.
Ich bin auf die Überprüfung und Verfeinerung von KI-gestützter Forschung, technischer Dokumentation und Inhalten im Zusammenhang mit neuen KI-Technologien spezialisiert. Meine Erfahrung umfasst KI-Modelltraining, Datenanalyse und Informationsabruf und ermöglicht es mir, Inhalte zu erstellen, die sowohl technisch korrekt als auch zugänglich sind.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.