
Bei allen Aufgaben, die sich auf Datenwissenschaft und maschinelles Lernen beziehen, hängt das Wichtigste, was ein Modell ausführen wird, davon ab, wie intestine unsere Daten sind. Python Pandas und SQL gehören zu den leistungsstarken Instruments, die zum effizienten Extrahieren und Manipulieren von Daten helfen können. Durch die Kombination dieser beiden können Datenanalysten eine komplexe Analyse auch für große Datensätze durchführen. In diesem Artikel werden wir untersuchen, wie Sie sich kombinieren können Python Pandas mit Sql Verbesserung der Qualität der Datenanalyse.
Pandas und SQL: Übersicht
Bevor Sie Pandas und SQL zusammen verwenden. Zunächst werden wir Pandas durchgehen und SQL ist fähig und ihre wichtigsten Funktionen.
Was ist Pandas?
Pandas ist eine Softwarebibliothek, die für die Python -Programmiersprache für Datenmanipulation und -analyse geschrieben wurde. Es bietet Operationen zum Manipulieren von Tabellen, Datenstrukturen und Zeitreihendaten.
Schlüsselmerkmale von Pandas
- Mit Pandas DataFrames können wir mit strukturierten Daten arbeiten.
- Es bietet unterschiedliche Funktionen wie Sortieren, Gruppieren, Zusammenführen, Umgestalten und Filtern von Daten.
- Es ist effizient, fehlende Datenwerte zu behandeln.
Erfahren Sie mehr: Der ultimative Leitfaden zu Pandas für Knowledge Science!
Was ist SQL?
SQL steht für die strukturierte Abfragesprache, die zum Extrahieren, Verwalten und Manipulieren von relationalen Datenbanken verwendet wird. Es ist nützlich, um strukturierte Daten zu behandeln, indem Beziehungen zwischen Entitäten und Variablen einbezogen werden. Es ermöglicht das Einsetzen, Aktualisieren, Löschen und Verwalten der gespeicherten Daten in Tabellen.
Schlüsselmerkmale von SQL
- Es bietet eine robuste Möglichkeit, große Datensätze abzufragen.
- Es ermöglicht die Erstellung, Änderung und Löschung von Datenbankschemata.
- Die Syntax von SQL ist für effiziente und komplexe Abfragevorgänge wie Be part of, GroupBy optimiert.
Erfahren Sie mehr: SQL für Knowledge Science: Ein Anfängerführer!
Warum Pandas mit SQL kombinieren?
Durch die Verwendung von Pandas und SQL zusammen wird der Code lesbarer und in bestimmten Fällen einfacher zu implementieren. Dies gilt für komplexe Workflows, da SQL -Abfragen viel klarer und leichter zu lesen sind als der äquivalente Pandas -Code. Darüber hinaus stammen die meisten relationalen Daten aus Datenbanken, und SQL ist eines der Hauptwerkzeuge, um mit relationalen Daten umzugehen. Dies ist einer der Hauptgründe, warum Berufstätige wie Datenanalysten und Datenwissenschaftler es vorziehen, ihre Funktionen zu integrieren.
Wie funktioniert Pandasql?
Um SQL -Abfragen mit Pandas zu kombinieren, braucht man eine gemeinsame Brücke zwischen diesen beiden, um dieses Downside zu überwinden. ‚Pandasql‚kommt ins Bild. Mit Pandasql können Sie SQL -Abfragen direkt innerhalb von Pandas ausführen. Auf diese Weise können wir die SQL -Syntax nahtlos verwenden, ohne die dynamische Pandas -Umgebung zu verlassen.
Installieren von Pandasql
Der erste Schritt, um Pandas und SQL zusammen zu verwenden, besteht darin, Pandasql in unsere Umgebung zu installieren.
pip set up pandasql
Sobald die Set up abgeschlossen ist, können wir die Pandasql in unseren Code importieren und die SQL -Abfragen auf Pandas DataFrame ausführen.
Ausführen von SQL -Abfragen in Pandas
Sobald die Set up beendet ist, können wir die Pandasql importieren und damit beginnen, sie zu erkunden.
import pandas as pd
import pandasql as psql
# Create a pattern DataFrame
knowledge = {'Title': ('Alice', 'Bob', 'Charlie'), 'Age': (25, 30, 35)}
df = pd.DataFrame(knowledge)
# SQL question to pick all knowledge
question = "SELECT * FROM df"
end result = psql.sqldf(question, locals())
end result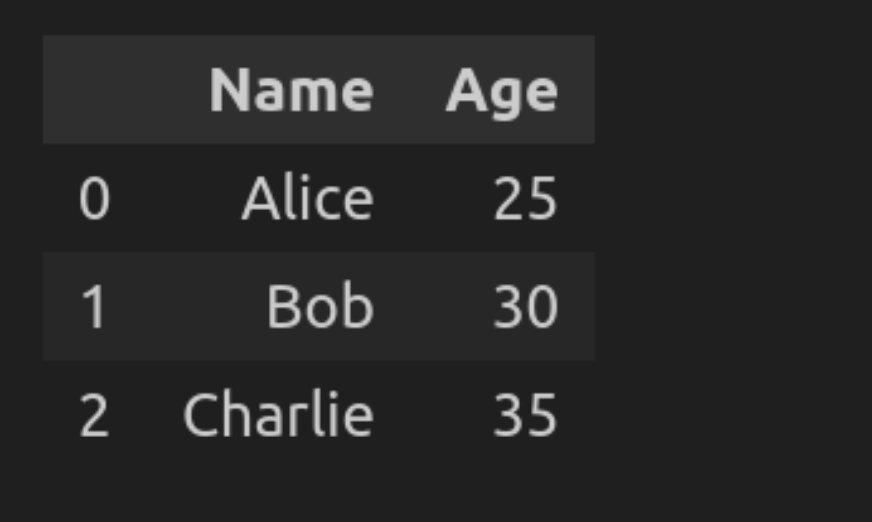
Lassen Sie uns den Code aufschlüsseln
- Pd.Dataframe konvertiert die Beispieldaten in ein tabellarisches Format.
- Abfrage (aus DF auswählen) wählt alles in Type des Datenrahmens aus.
- PSQL.SQLDF (Abfrage, Lokale ()) führt die SQL -Abfrage auf dem DataFrame mithilfe des lokalen Bereichs aus.
Datenanalyse mit Pandasql
Sobald alle Bibliotheken importiert sind, ist es Zeit, die Datenanalyse mit Pandasql durchzuführen. Der folgende Abschnitt zeigt einige Beispiele, wie man die Datenanalyse durch Kombination von Pandas und SQL verbessern kann. Um dies zu tun:
Schritt 1: Laden Sie die Daten
# Required libraries
import pandas as pd
import pandasql as ps
import plotly.specific as px
import ipywidgets as widgets
# Load the dataset
car_data = pd.read_csv("cars_datasets.csv")
car_data.head()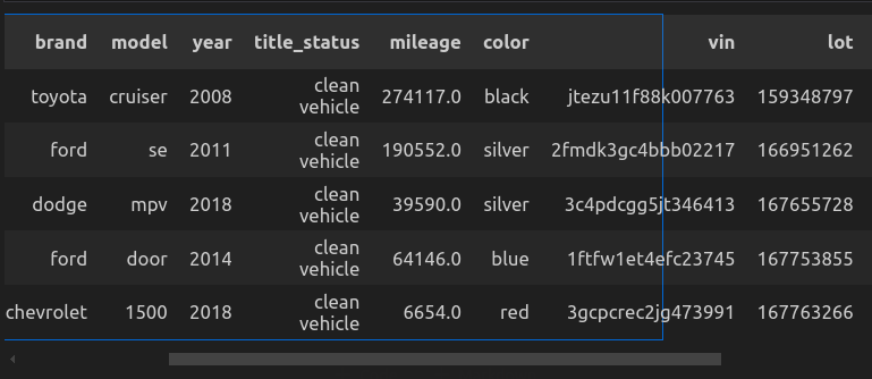
Lassen Sie uns den Code aufschlüsseln
- Importieren der erforderlichen Bibliotheken: Pandas zum Umgang mit Daten, Pandasql zum Abfragen der Datenrahmen, plottely für interaktive Diagramme.
- pd.read_csv („cars_datasets.csv“), um die Daten aus dem lokalen Verzeichnis zu laden.
- car_data.head () zeigt die Prime 5 Zeilen an.
Schritt 2: Erforschen Sie die Daten
In diesem Abschnitt werden wir versuchen, Daten vertraut zu machen, indem wir Dinge wie die Namen der Spalten, den Datentyp der Funktionen und die Frage, ob die Daten irgendwelche Nullwerte haben oder nicht, untersuchen.
- Überprüfen Sie die Spaltennamen.
# Show column names
column_names = car_data.columns
column_names
"""
Output:
Index(('Unnamed: 0', 'value', 'model', 'mannequin', 'yr', 'title_status',
'mileage', 'colour', 'vin', 'lot', 'state', 'nation', 'situation'),
dtype="object")
""”- Identifizieren Sie den Datentyp der Spalten.
# Show dataset information
car_data.information()
"""
Ouput:
<class 'pandas.core.body.DataFrame'>
RangeIndex: 2499 entries, 0 to 2498
Knowledge columns (whole 13 columns):
# Column Non-Null Rely Dtype
--- ------ -------------- -----
0 Unnamed: 0 2499 non-null int64
1 value 2499 non-null int64
2 model 2499 non-null object
3 mannequin 2499 non-null object
4 yr 2499 non-null int64
5 title_status 2499 non-null object
6 mileage 2499 non-null float64
7 colour 2499 non-null object
8 vin 2499 non-null object
9 lot 2499 non-null int64
10 state 2499 non-null object
11 nation 2499 non-null object
12 situation 2499 non-null object
dtypes: float64(1), int64(4), object(8)
reminiscence utilization: 253.9+ KB
"""- Überprüfen Sie die Nullwerte.
# Test for null values
car_data.isnull().sum()
"""Output:
Unnamed: 0 0
value 0
model 0
mannequin 0
yr 0
title_status 0
mileage 0
colour 0
vin 0
lot 0
state 0
nation 0
situation 0
dtype: int64
"""Schritt 3: Analysieren Sie die Daten
Sobald wir den Datensatz in den Workflow geladen haben. Jetzt beginnen wir mit der Durchführung von Datenanalysen.
Beispiele für die Datenanalyse mit Python Pandas und SQL
Versuchen wir nun, Pandasql zu verwenden, um den obigen Datensatz zu analysieren, indem einige unserer Abfragen ausgeführt werden.
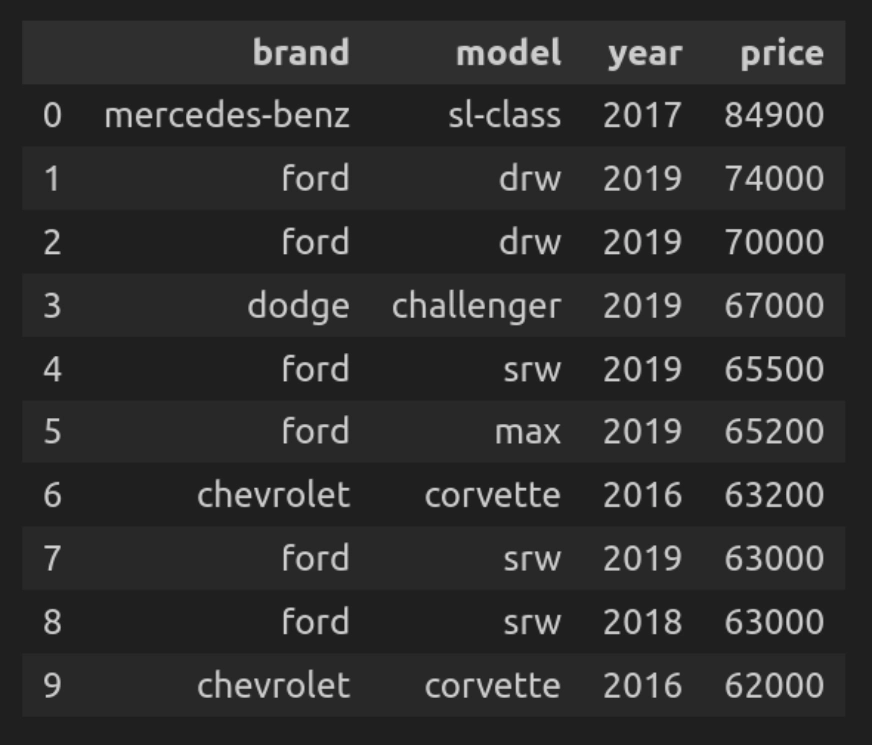
Abfrage 1: Auswählen der 10 teuersten Autos
Finden wir zunächst die 10 teuersten Autos aus dem gesamten Datensatz.
def q(question):
return ps.sqldf(question, {'car_data': car_data})
q("""
SELECT model, mannequin, yr, value
FROM car_data
ORDER BY value DESC
LIMIT 10
""")
Lassen Sie uns den Code aufschlüsseln
- Q (Abfrage) ist eine benutzerdefinierte Funktion, die die SQL -Abfrage im DataFrame ausführt.
- Die Abfrage iteriert über den vollständigen Datensatz und wählt Spalten wie Marke, Modell, Jahr, Preis aus und sortiert sie dann in absteigender Reihenfolge nach Preis.
Abfrage 2: Durchschnittlicher Preis nach Marke
Hier finden wir den Durchschnittspreis für Autos für jede Marke.
def q(question):
return ps.sqldf(question, {'car_data': car_data})
q("""
SELECT model, ROUND(AVG(value), 2) AS avg_price
FROM car_data
GROUP BY model
ORDER BY avg_price DESC""")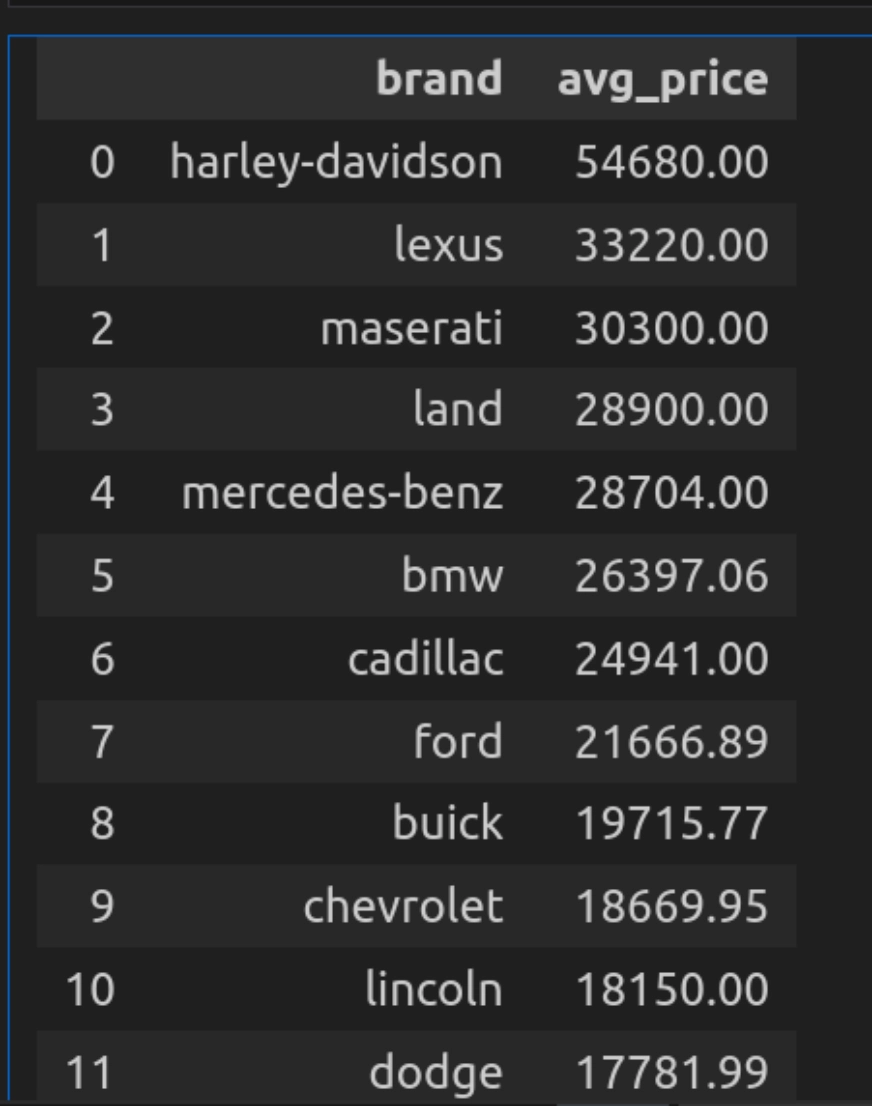
Lassen Sie uns den Code aufschlüsseln
- Hier verwendet die Abfrage AVG (Preis), um den Durchschnittspreis für jede Marke zu berechnen, und runden Sie den Ergebnis auf 2 Dezimalstellen ab.
- Und GroupBy wird die Daten von den Automarken gruppieren und sie sortieren, indem sie den AVG (Preis) in absteigender Reihenfolge verwenden.
Abfrage 3: Autos, die nach 2015 hergestellt wurden
Lassen Sie uns eine Liste der nach 2015 hergestellten Autos erstellen.
def q(question):
return ps.sqldf(question, {'car_data': car_data})
q("""
SELECT *
FROM car_data
WHERE yr > 2015
ORDER BY yr DESC
""")
Lassen Sie uns den Code aufschlüsseln
- Hier wählt die Abfrage nach 2015 alle Autohersteller aus und bestellt sie in absteigender Reihenfolge.
Abfrage 4: Prime 5 Marken nach Anzahl der aufgelisteten Autos
Lassen Sie uns nun die Gesamtzahl der von jeder Marke produzierten Autos finden.
def q(question):
return ps.sqldf(question, {'car_data': car_data})
q("""
SELECT model, COUNT(*) as total_listed
FROM car_data
GROUP BY model
ORDER BY total_listed DESC
LIMIT 5
""")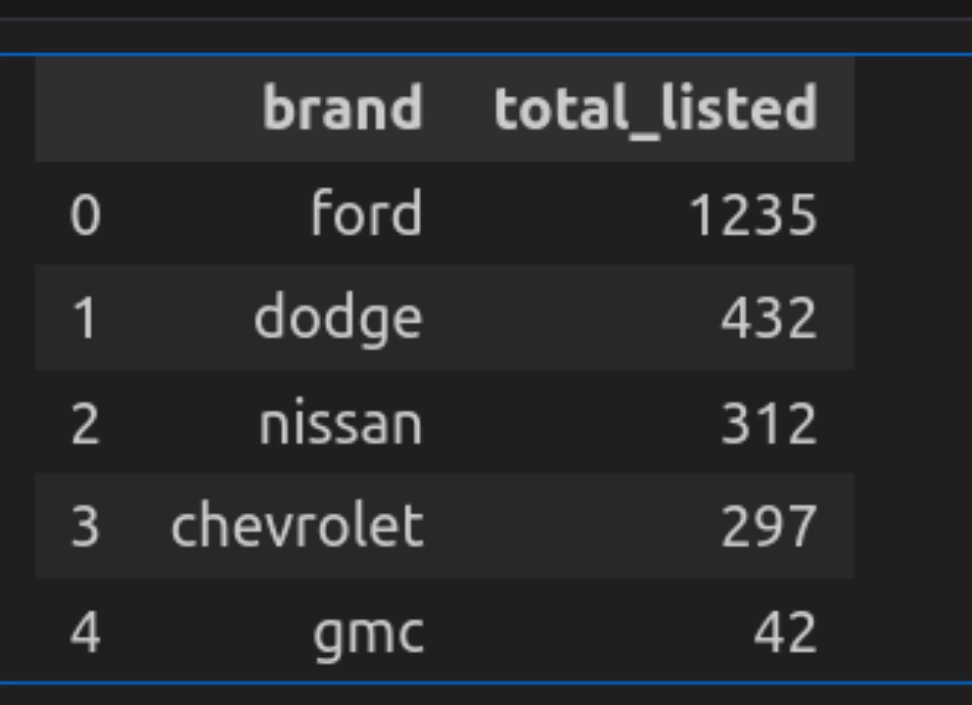
Lassen Sie uns den Code aufschlüsseln
- Hier zählt die Abfrage die Gesamtzahl der Autos von jeder Marke mit der Gruppe nach Betrieb.
- Es listet sie in absteigender Reihenfolge auf und verwendet ein Restrict von 5, um nur die Prime 5 auszuwählen.
Abfrage 5: Durchschnittlicher Preis nach Zustand
Mal sehen, wie wir die Autos basierend auf einem Zustand gruppieren können. Hier zeigt die Konditionsspalte die Zeit, in der die Auflistung hinzugefügt wurde oder wie viel Zeit übrig bleibt. Basierend darauf können wir die Autos kategorisieren und ihre durchschnittlichen Preisgestaltung erhalten.
def q(question):
return ps.sqldf(question, {'car_data': car_data})
q("""
SELECT situation, ROUND(AVG(value), 2) AS avg_price, COUNT(*) as listings
FROM car_data
GROUP BY situation
ORDER BY avg_price DESC
""")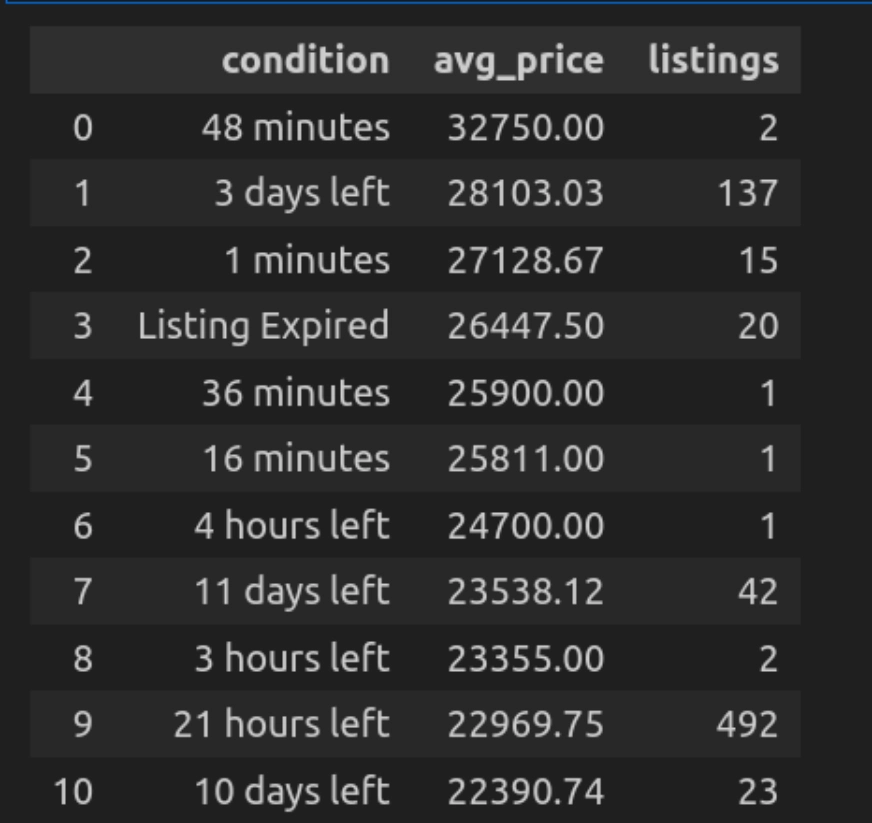
Lassen Sie uns den Code aufschlüsseln
- Hier gruppiert sich die Anfragebusse die Autos unter Zustand (z. B. neu oder gebraucht) und berechnet den Preis mit AVG (Preis).
- Bestellen Sie sie in absteigender Reihenfolge, um zuerst die teuersten Autos zu zeigen.
Abfrage 6: Durchschnittlicher Kilometerstand und Preis von Marke
Hier finden wir die durchschnittliche Kilometerleistung der Autos für jede Marke und ihren Durchschnittspreis.
def q(question):
return ps.sqldf(question, {'car_data': car_data})
q("""
SELECT model,
ROUND(AVG(mileage), 2) AS avg_mileage,
ROUND(AVG(value), 2) AS avg_price,
COUNT(*) AS total_listings
FROM car_data
GROUP BY model
ORDER BY avg_price DESC
LIMIT 10
""")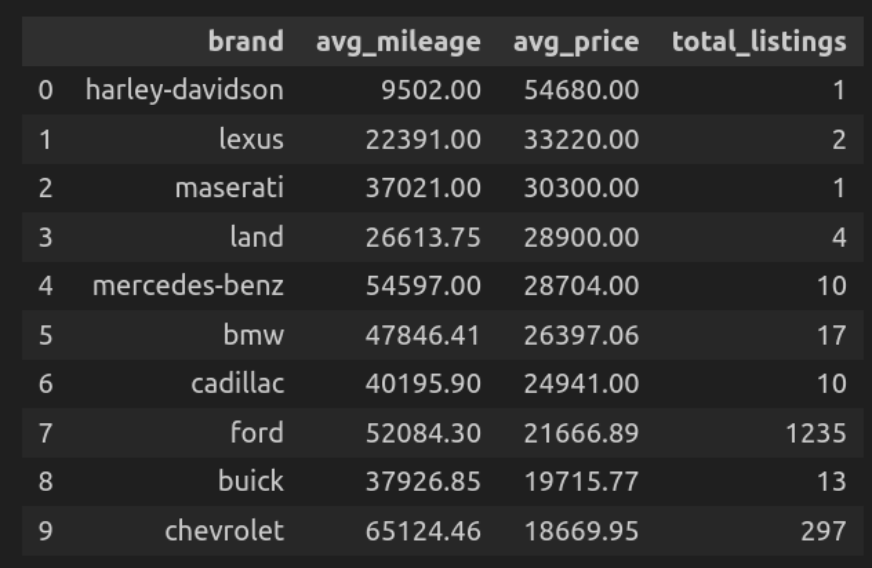
Lassen Sie uns den Code aufschlüsseln
- Hier gruppiert sich die Abfrageberätigungen, die die Autos verwenden, und berechnet ihre durchschnittliche Kilometerleistung und ihren Durchschnittspreis und zählt die Gesamtzahl der Auflistungen jeder Marke in dieser Gruppe.
- Bestellen Sie sie in absteigender Reihenfolge nach Preis.
Abfrage 7: Preis professional Kilometerleistung für Prime -Marken
Lassen Sie uns nun die Prime -Marken auf der Grundlage ihres kalkulierten Kilometerverhältnisses sortieren, dh dem Durchschnittspreis professional Meile der Autos für jede Marke.
def q(question):
return ps.sqldf(question, {'car_data': car_data})
q("""
SELECT model,
ROUND(AVG(value/mileage), 4) AS price_per_mile,
COUNT(*) AS whole
FROM car_data
WHERE mileage > 0
GROUP BY model
ORDER BY price_per_mile DESC
LIMIT 10
""")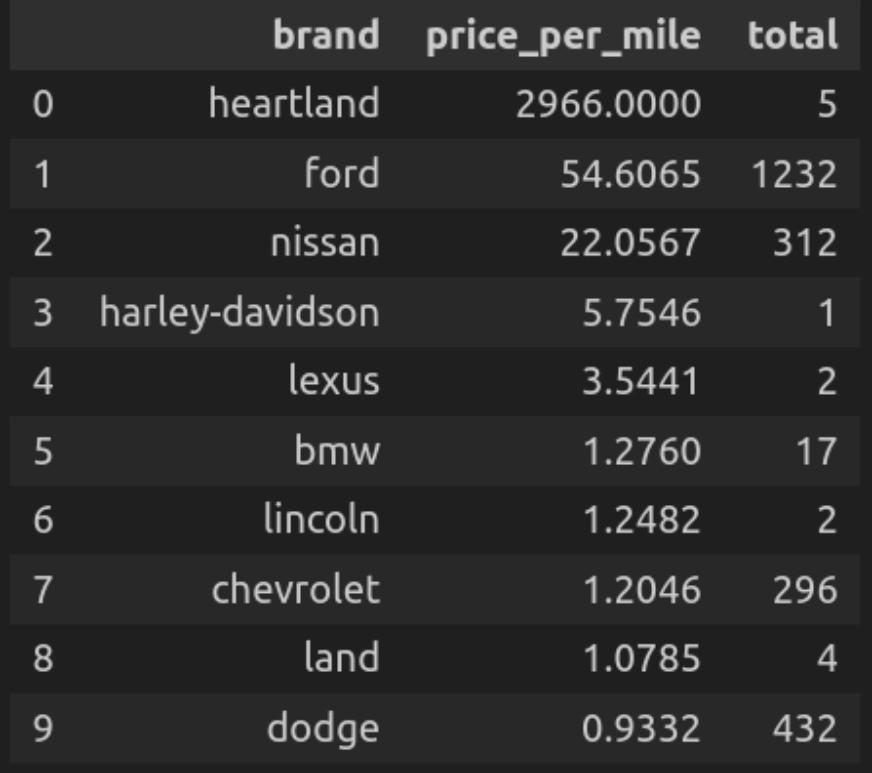
Lassen Sie uns den Code aufschlüsseln
- Hier berechnet die Abfrage den Preis professional Kilometerleistung für jede Marke und zeigt dann Autos jeder Marke mit diesem spezifischen Preis professional Kilometerleistung. In absteigender Reihenfolge nach Preis professional Meile.
Abfrage 8: Durchschnittlicher Autopreis nach Gebiet
Hier finden und planen wir die Anzahl der Autos jeder Marke in einer bestimmten Stadt.
state_dropdown = widgets.Dropdown(
choices=car_data('state').distinctive().tolist(),
worth=car_data('state').distinctive()(0),
description='Choose State:',
format=widgets.Format(width="50%")
)
def plot_avg_price_state(state_selected):
question = f"""
SELECT model, AVG(value) AS avg_price
FROM car_data
WHERE state="{state_selected}"
GROUP BY model
ORDER BY avg_price DESC
"""
end result = q(question)
fig = px.bar(end result, x='model', y='avg_price', colour="model",
title=f"Common Automobile Value in {state_selected}")
fig.present()
widgets.work together(plot_avg_price_state, state_selected=state_dropdown)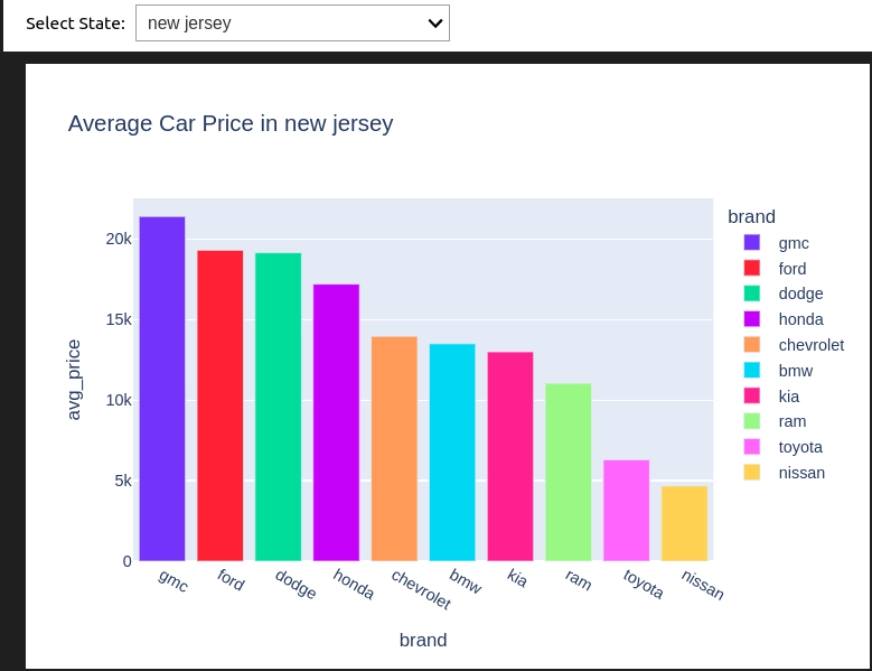
Lassen Sie uns den Code aufschlüsseln
- State_dropdown erstellt eine Dropdown, um die verschiedenen US -Zustände aus den Daten auszuwählen, und ermöglicht es dem Benutzer, einen Standing auszuwählen.
- plot_avg_price_state (state_selected) führt die Abfrage aus, um den Durchschnittspreis professional Marke zu berechnen, und gibt ein Balkendiagramm mit Plotly an.
- Widgets.Work together () verknüpft den Dropdown mit der Funktion, sodass das Diagramm selbst aktualisieren kann, wenn der Benutzer einen anderen Standing auswählt.
Für das hier verwendete Pocket book und den hier verwendeten Datensatz finden Sie bitte besuchen Sie Dieser Hyperlink.
Einschränkungen von Pandasql
Obwohl Pandasql viele effiziente Funktionen und eine bequeme Möglichkeit bietet, SQL -Abfragen mit Pandas auszuführen, hat es auch einige Einschränkungen. In diesem Abschnitt werden wir diese Einschränkungen untersuchen und versuchen, herauszufinden, wann sie sich auf traditionelle Pandas oder SQL verlassen und wann Pandasql verwendet werden soll.
- Nicht mit großen Datensätzen kompatibel: Während wir ausführen, erstellt die Pandasql -Abfrage vor der vollständigen Ausführung der aktuellen Abfrage eine Kopie der Daten im Speicher. Diese Methode zur Ausführung der Überfragen, die sich mit großen Datensätzen befassen, kann zu einer hohen Speicherverwendung und einer langsamen Ausführung führen.
- Begrenzte SQL -Funktionen: Pandasql unterstützt viele grundlegende SQL -Funktionen, implementiert jedoch nicht alle erweiterten Funktionen wie Unterabfragen, komplexe Verknüpfungen und Fensterfunktionen.
- Kompatibilität mit komplexen Daten: Pandas funktioniert intestine mit tabellarischen Daten. Während der Arbeit mit komplexen Daten wie verschachtelten JSON- oder Multi-Index-Datenfaktoren liefert es nicht die gewünschten Ergebnisse.
Abschluss
Die Verwendung von Pandas und SQL verbessert den Datenanalyse -Workflow signifikant. Durch die Nutzung von Pandasql kann man SQL -Abfragen in den Datenrahmen nahtlos ausführen. Dies hilft denen, die mit SQL vertraut sind und in Python -Umgebungen arbeiten möchten. Diese Integration von Pandas und SQL kombiniert die Flexibilität beider und eröffnet neue Möglichkeiten für die Datenmanipulation und -analyse. Damit kann man die Fähigkeit verbessern, eine breite Palette von Datenherausforderungen anzugehen. Es ist jedoch wichtig, die Einschränkungen von Pandasql zu berücksichtigen und andere Ansätze im Umgang mit großen und komplexen Datensätzen zu untersuchen.
Hallo! Ich bin Vipin, ein leidenschaftlicher Knowledge Science und maschinelles Lernen, der eine starke Grundlage für die Datenanalyse, Algorithmen und Programmierung maschinelles Lernens und Programmierung hat. Ich habe praktische Erfahrungen beim Aufbau von Modellen, beim Verwalten unordentlicher Daten und die Lösung realer Probleme. Mein Ziel ist es, datengesteuerte Erkenntnisse anzuwenden, um praktische Lösungen zu erstellen, die Ergebnisse erzielen. Ich bin bestrebt, meine Fähigkeiten in einer kollaborativen Umgebung beizutragen und gleichzeitig in den Bereichen Datenwissenschaft, maschinelles Lernen und NLP zu lernen und zu wachsen.
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.