Im aktuellen Zeitalter der KI wären alle technischen Ingenieure mit LLMs vertraut. Diese LLMs haben es uns leichter gemacht, Aufgaben zu erledigen, indem wir sie mit der Übernahme bestimmter sich wiederholender Aufgaben beauftragen. Als KI-Ingenieure hat dies zweifellos unsere Leistung gesteigert.
Jedes Mal, wenn wir LLMs verwenden, verwenden wir jedoch eine erhebliche Anzahl von Token. Diese Token dienen uns als Eintrittskarte für die Kommunikation mit diesen Modellen. Bei der Verwendung eines Argumentationsmodells werden zusätzliche Token als Argumentationstoken verwendet. Leider sind die verwendeten Token auch sehr teuer, was dazu führt, dass der Benutzer das Tariflimit oder eine Abonnement-Paywall erreicht.
Um unsere Token-Nutzung und damit die Gesamtkosten zu senken, werden wir eine neue Notation untersuchen, die gerade aufgetaucht ist und die Token-Oriented Object Notation (TOON) genannt wird.
Was ist JSON?
JavaScript Object Notation, oder JSON, ist ein leichtes Datenaustauschformat, das sowohl für Pc einfach zu analysieren und zu erstellen als auch für Menschen leicht zu lesen und zu schreiben ist. Es eignet sich perfekt für den Austausch strukturierter Daten zwischen Systemen, beispielsweise zwischen einem Consumer und einem Server in Webanwendungen, da es Daten als Schlüssel-Wert-Paare, Arrays und verschachtelte Strukturen darstellt. Nahezu alle Programmiersprachen können JSON nativ akzeptieren, da es textbasiert und sprachunabhängig ist. JSON-formatierte Daten sehen etwa so aus:
{
"title": "Hamzah",
"age": 22,
"expertise": ("Gen AI", "CV", "NLP"),
"work": {
"group": "Analytics Vidhya",
"position": "Information Scientist"
}
}Mehr lesen: JSON-Eingabeaufforderung
Was ist TOON?
Token-Oriented Object Notation (TOON) ist ein kompaktes, für Menschen lesbares Serialisierungsformat, das für die effiziente Weitergabe strukturierter Daten entwickelt wurde Große Sprachmodelle (LLMs) bei deutlich geringerem Einsatz von Token. Es dient als verlustfreier Drop-in-Ersatz für JSON und ist speziell für die LLM-Eingabe optimiert.
Für Datensätze mit einheitlichen Arrays von Objekten, bei denen jedes Factor die gleiche Struktur hat (z. B. Zeilen in einer Tabelle), funktioniert TOON besonders intestine. Es schafft ein strukturiertes und tokeneffizientes Format, indem es die tabellarische Kompaktheit von CSV mit der einrückungsbasierten Lesbarkeit von YAML verbindet. JSON ist möglicherweise immer noch eine bessere Darstellung für tief verschachtelte oder unregelmäßige Daten, auch wenn TOON sich bei der Verwaltung tabellarischer oder zuverlässig strukturierter Daten auszeichnet.
Im Wesentlichen bietet TOON die Kompaktheit von CSV mit der Strukturkenntnis von JSON und hilft LLMs dabei, Daten zuverlässiger zu analysieren und zu analysieren. Betrachten Sie es als eine Übersetzungsebene: Sie können JSON programmgesteuert verwenden und es dann für eine effiziente LLM-Eingabe in TOON konvertieren.
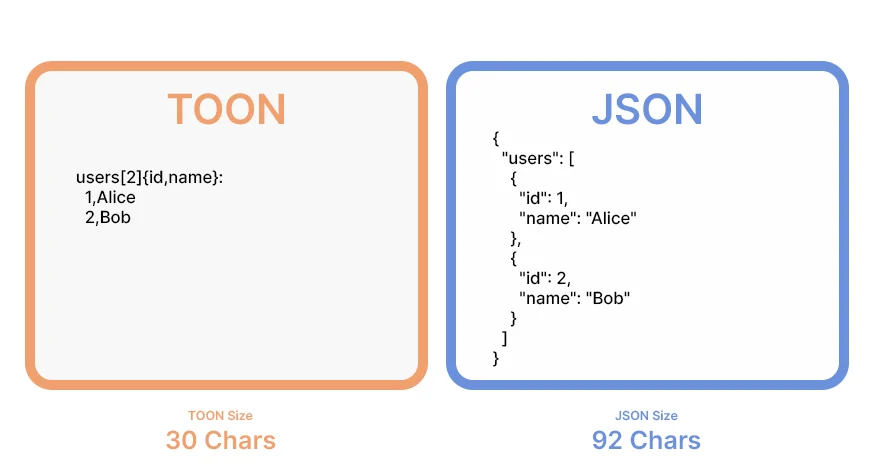
Zum Beispiel:
JSON (tokenlastig):
{
"customers": (
{
"id": 1,
"title": "Alice",
"position": "admin"
},
{
"id": 2,
"title": "Bob",
"position": "person"
}
)
}TOON (Token-effizient):
customers(2){id,title,position}:1,Alice,admin2,Bob,personHauptmerkmale
- Tokeneffizient: Erzielt 30–60 % weniger Token als formatiertes JSON für große, einheitliche Datensätze, wodurch die LLM-Eingabekosten erheblich gesenkt werden.
- LLM-freundliche Leitplanken: Explizite Feldnamen und deklarierte Array-Längen erleichtern Modellen die Validierung der Struktur und die Aufrechterhaltung der Konsistenz.
- Minimale Syntax: Eliminiert überflüssige Satzzeichen wie geschweifte Klammern und die meisten Anführungszeichen und sorgt so für ein übersichtliches und lesbares Format.
- Einrückungsbasierte Struktur: Ähnlich wie YAML verwendet TOON Einrückungen anstelle von geschachtelten Klammern, um die Hierarchie darzustellen und so die Übersichtlichkeit zu erhöhen.
- Tabellarische Arrays: Definiert Schlüssel einmal und streamt dann Datenzeilen effizient, preferrred für Datensätze mit einem konsistenten Schema.
- Optionale Schlüsselklappfunktion: Ermöglicht das Zusammenfassen verschachtelter Einzelschlüssel-Wrapper in gepunktete Pfade (z. B. information.metadata.objects), wodurch die Einrückung und die Tokenanzahl weiter reduziert werden.
Benchmark-Leistung
Den Testergebnissen zufolge schneidet TOON hinsichtlich Genauigkeit und Token-Effizienz regelmäßig besser ab als herkömmlichere Datenformate wie JSON, YAML und XML. Mit einer Genauigkeit von 73,9 % und nur 2.744 Token weist TOON das beste Gleichgewicht zwischen Korrektheit und Kompaktheit bei 209 Abrufproblemen und vier verschiedenen LLMs auf. Im Vergleich zu JSON, das eine geringere Genauigkeit von 69,7 % erreicht und gleichzeitig 39,6 % mehr Token verwendet, ist dies weitaus effizienter. Unter allen untersuchten Formen weist TOON die höchste Gesamteffizienz auf, da beim Benchmark-Scoring die Genauigkeit professional 1.000 Token berücksichtigt wird.
Insgesamt zeigt der Benchmark, dass TOON ein besseres Gleichgewicht zwischen struktureller Klarheit, Token-Kosten und Genauigkeit bietet. Aufgrund seines Designs können LLMs Informationen konsistenter extrahieren, tabellarische und verschachtelte Muster leichter verstehen und über eine Vielzahl von Datensatztypen hinweg eine hervorragende Leistung aufrechterhalten. In vielen realen Abrufanwendungen machen diese Eigenschaften TOON zu einem LLM-freundlicheren Datenformat als JSON, YAML, XML oder sogar CSV.
Auf einem Spielplatz können Sie die TOON-Leistung testen:
Wann sollte TOON nicht verwendet werden?
Während TOON eine außergewöhnlich gute Leistung erbringt einheitliche Arrays von Objektengibt es Szenarien, in denen andere Datenformate effizienter oder praktischer sind:
- Tief verschachtelte oder uneinheitliche Strukturen: Wenn Daten viele verschachtelte Ebenen oder inkonsistente Felder aufweisen (tabellarische Eignung ≈ 0 %), verwendet kompaktes JSON möglicherweise tatsächlich weniger Token. Dies ist häufig bei komplexen Konfigurationsdateien oder hierarchischen Metadaten der Fall.
- Halbeinheitliche Arrays (~40–60 % tabellarische Berechtigung): Mit abnehmender Strukturkonsistenz verlieren Token-Einsparungen an Bedeutung. Wenn Ihre vorhandenen Datenpipelines bereits auf JSON basieren, ist es möglicherweise bequemer, dabei zu bleiben.
- Reine tabellarische Daten: Für flache Datensätze: CSV bleibt das kompakteste Format. TOON führt einen kleinen Overhead (~5–10 %) ein, um Strukturelemente wie Feldheader und Array-Deklarationen einzubinden, die die LLM-Zuverlässigkeit verbessern, aber die Größe leicht erhöhen.
- Latenzkritische Anwendungen: In Setups, in denen die Finish-to-Finish-Reaktionszeit oberste Priorität hat, vergleichen Sie TOON und JSON, bevor Sie eine Entscheidung treffen. Einige Bereitstellungen, insbesondere mit lokalen oder quantisierten Modellen (z. B. Ollama) – kann kompaktes JSON trotz der Token-Einsparungen von TOON schneller verarbeiten. Vergleichen Sie immer TTFT (Time To First Token), Token professional Sekunde und Gesamtverarbeitungszeit für beide Formate.
Läuft TOON
Derzeit gibt es eine breite Palette von TOON-Implementierungen in mehreren Programmiersprachen, die sowohl von offiziellen als auch von der Neighborhood betriebenen Bemühungen unterstützt werden. Viele ausgereifte Versionen sind bereits verfügbar Fünf Implementierungen befinden sich noch in der aktiven Entwicklungwas auf anhaltendes Wachstum und eine Erweiterung des Ökosystems hinweist. Die derzeit in Entwicklung befindlichen Implementierungen sind: .NET (toon_format), Dart (toon), Go (gotoon), Python (toon_format) und Rust (toon_format).
Sie können die Set up von TOON hier verfolgen. Aber vorerst werde ich TOON mit Hilfe von implementieren Toon-Python Paket.
Lassen Sie uns einen einfachen Code ausführen, um die Hauptfunktion von toon-python zu sehen:
Set up
Beginnen wir zunächst mit der Set up
!pip set up git+https://github.com/toon-format/toon-python.git -qDer TOON-API konzentriert sich auf zwei Hauptfunktionen: kodieren Und dekodieren.
encode() Konvertiert jeden JSON-serialisierbaren Wert in das kompakte TOON-Format, verarbeitet verschachtelte Objekte, Arrays, Datumsangaben und BigInts automatisch und bietet optionale Steuerelemente wie Einrückung und Schlüsselfaltung.
decode() kehrt diesen Prozess um, liest TOON-Textual content und rekonstruiert die ursprünglichen JavaScript-Werte, wobei eine strenge Validierung verfügbar ist, um fehlerhafte oder inkonsistente Strukturen zu erkennen.
TOON unterstützt auch anpassbare Trennzeichen wie Kommas, Tabulatoren und Pipes. Diese wirken sich darauf aus, wie Array-Zeilen und Tabellendaten getrennt werden, sodass Benutzer die Lesbarkeit oder Token-Effizienz optimieren können. Insbesondere Tabs können den Token-Verbrauch weiter reduzieren, da sie kostengünstig tokenisiert werden und die Quotierung minimieren.
Sie können dies überprüfen Hier.
Code-Implementierung
Schauen wir uns additionally einige Code-Implementierungen an.
Ich habe nach dem Abschlussteil einen Hyperlink zu meinem Github-Repository eingefügt, in dem ich TOON in einem einfachen Chatbot verwendet habe, falls Sie sehen möchten, wie Sie TOON in Ihren Code integrieren können.
Die Hauptimportfunktion für Python Umsetzung wäre von toon_format.
1. geschätzte_Einsparungen + vergleichende_Formate + count_tokens
Dieser Block nimmt ein Python-Wörterbuch, konvertiert es sowohl in JSON als auch in TOON und berechnet, wie viele Token jedes Format verwenden würde. Anschließend wird der Prozentsatz der Token-Einsparungen ausgedruckt, ein direkter Vergleich angezeigt und schließlich werden die Token für eine TOON-Zeichenfolge direkt gezählt.
from toon_format import estimate_savings, compare_formats, count_tokens
# Measure financial savings
information = {
"customers": (
{
"id": 1,
"title": "Alice"
},
{
"id": 2,
"title": "Bob"
}
)
}
consequence = estimate_savings(information)
print(f"Saves {consequence('savings_percent'):.1f}% tokens") # Saves 42.3% tokens
# Visible comparability
print(compare_formats(information))
# Rely tokens straight
toon_str = encode(information)
tokens = count_tokens(toon_str) # Makes use of tiktoken (gpt5/gpt5-mini)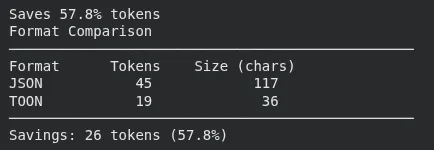
2. geschätzte_Einsparungen für Benutzerdaten
In diesem Abschnitt wird gemessen, wie viele Token die Daten des Benutzers in JSON vs. TOON erzeugen würden. Es druckt die Tokenanzahl für beide Formate und die prozentualen Einsparungen, die durch den Wechsel zu TOON erzielt wurden.
from toon_format import estimate_savings
# Your precise information construction
user_data = {
"customers": (
{"id": 1, "title": "Alice", "electronic mail": "(electronic mail protected)", "energetic": True},
{"id": 2, "title": "Bob", "electronic mail": "(electronic mail protected)", "energetic": True},
{"id": 3, "title": "Charlie", "electronic mail": "(electronic mail protected)", "energetic": False}
)
}
# Evaluate codecs
consequence = estimate_savings(user_data)
print(f"JSON: {consequence('json_tokens')} tokens")
print(f"TOON: {consequence('toon_tokens')} tokens")
print(f"Financial savings: {consequence('savings_percent'):.1f}%")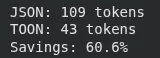
3. Schätzung der mit TOON eingesparten Kosten
Dieser Block führt Token-Einsparungen für einen größeren Datensatz (100 Elemente) durch und gilt dann GPT-5 Preisgestaltung, um zu berechnen, wie viel jede Anfrage in JSON im Vergleich zu TOON kostet. Es druckt die Kostendifferenz professional Anfrage und die prognostizierten Einsparungen über 10.000 Anfragen.
from toon_format import estimate_savings
# Your typical immediate information
prompt_data = {
"context": (
{"position": "system", "content material": "You're a useful assistant"},
{"position": "person", "content material": "Analyze this information"}
),
"information": (
{"id": i, "worth": f"Merchandise {i}", "rating": i * 10}
for i in vary(1, 101) # 100 objects
)
}
consequence = estimate_savings(prompt_data("information"))
# GPT-5 pricing (instance: $0.01 per 1K tokens)
cost_per_1k = 0.01
json_cost = (consequence('json_tokens') / 1000) * cost_per_1k
toon_cost = (consequence('toon_tokens') / 1000) * cost_per_1k
print(f"JSON value per request: ${json_cost:.4f}")
print(f"TOON value per request: ${toon_cost:.4f}")
print(f"Financial savings per request: ${json_cost - toon_cost:.4f}")
print(f"Financial savings per 10,000 requests: ${(json_cost - toon_cost) * 10000:.2f}")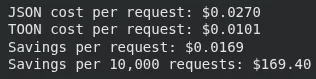
Abschluss
Durch die Bereitstellung eines organisierten, kompakten und äußerst tokeneffizienten Ersatzes für herkömmliche Formate wie JSON stellt TOON eine bedeutende Veränderung in der Artwork und Weise dar, wie wir Daten für LLMs vorbereiten. Die Reduzierung der Token-Nutzung führt unmittelbar zu geringeren Betriebskosten, insbesondere für Benutzer, die professional Token über API-Gutschriften zahlen, da immer mehr Entwickler auf LLMs für Automatisierung, Analyse und Anwendungsworkflows angewiesen sind. TOON erhöht außerdem die Extraktionsgenauigkeit, verringert Mehrdeutigkeiten und erhöht die Modellzuverlässigkeit in einer Vielzahl von Datensätzen, indem es Daten vorhersehbarer und für Modelle einfacher zu verarbeiten macht.
Formate wie TOON haben das Potenzial, die Artwork und Weise, wie LLMs in Zukunft mit strukturierten Daten umgehen, völlig zu verändern. Effiziente Darstellungen werden bei der Verwaltung von Kosten, Verzögerungen und Leistung immer wichtiger KI Systeme entwickeln sich weiter, um größere, kompliziertere Kontexte zu bewältigen. Entwickler werden in der Lage sein, umfangreichere Apps zu erstellen, ihre Arbeitslasten effektiver zu skalieren und schnellere, genauere Ergebnisse zu liefern, indem sie Instruments verwenden, die den Token-Verbrauch reduzieren, ohne die Struktur zu beeinträchtigen. TOON ist nicht nur ein neues Datenformat. Es ist ein Schritt in eine Zeit, in der jeder intelligenter, kostengünstiger und effektiver mit LLMs umgehen kann.
Häufig gestellte Fragen
A. TOON reduziert die Token-Nutzung, indem es strukturierte Daten in einem kompakten, übersichtlichen Format an LLMs sendet.
A. Es entfernt die meisten Satzzeichen, verwendet Einrückungen und definiert Felder einmal, wodurch die Anzahl der Token verringert wird, während die Struktur lesbar bleibt.
A. Es glänzt mit einheitlichen Arrays von Objekten, insbesondere mit Tabellendaten, bei denen jede Zeile dasselbe Schema verwendet.
Datenwissenschaftler @ Analytics Vidhya | CSE AI und ML @ VIT Chennai
Ich interessiere mich leidenschaftlich für KI und maschinelles Lernen und freue mich darauf, Rollen als KI/ML-Ingenieur oder Datenwissenschaftler zu übernehmen, in denen ich wirklich etwas bewirken kann. Mit einem Händchen für schnelles Lernen und einer Liebe zur Teamarbeit freue ich mich darauf, modern Lösungen und bahnbrechende Fortschritte auf den Markt zu bringen. Meine Neugier treibt mich dazu, KI in verschiedenen Bereichen zu erforschen und die Initiative zu ergreifen, mich in die Datentechnik zu vertiefen, um sicherzustellen, dass ich die Nase vorn habe und wirkungsvolle Projekte umsetze.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.