
Laut Stack Overflow und Atlassian liegen die Entwickler dazwischen 6 und 10 Stunden professional Woche bei der Suche nach Informationen oder der Klärung unklarer Unterlagen. Für ein 50-köpfiges Entwicklerteam summiert sich das auf 675.000 bis 1,1 Millionen US-Greenback an verschwendeter Produktivität professional Jahr. Dabei handelt es sich nicht nur um ein Werkzeugproblem. Es handelt sich um ein Abrufproblem.
Unternehmen verfügen über zahlreiche Daten, aber es mangelt ihnen an schnellen und zuverlässigen Möglichkeiten, die richtigen Informationen zu finden. Die traditionelle Suche scheitert, da die Systeme komplexer werden, was das Onboarding, die Entscheidungen und den Assist verlangsamt. In diesem Artikel untersuchen wir, wie die moderne Unternehmenssuche diese Lücken schließt.
Warum die traditionelle Unternehmenssuche zu kurz kommt
Die meisten Unternehmenssuchsysteme wurden für eine andere Zeit entwickelt. Sie gehen von relativ statischen Inhalten, vorhersehbaren Fehlern und Abfragen sowie manueller Optimierung aus, um related zu bleiben. In der modernen Datenumgebung ist keine dieser Annahmen von Bedeutung.
Groups arbeiten mit sich schnell ändernden Datensätzen. Anfragen sind mehrdeutig und gesprächig. Der Kontext ist genauso wichtig wie Schlüsselwörter. Dennoch basieren viele Suchtools immer noch auf spröden Regeln und genauen Treffern, wodurch Benutzer gezwungen werden, die richtige Formulierung zu erraten, anstatt ihre tatsächliche Absicht zum Ausdruck zu bringen.
Das Ergebnis ist bekannt. Menschen suchen wiederholt, verfeinern ihre Suchanfragen manuell oder geben die Suche ganz auf. Bei KI-gestützten Anwendungen wird das Downside noch schwerwiegender. Ein schlechter Abruf verlangsamt nicht nur die Benutzer. Es führt häufig unvollständigen oder irrelevanten Kontext in Sprachmodelle ein, was das Risiko minderwertiger oder irreführender Ergebnisse erhöht.
Der Wechsel zum Hybrid-Retrieval
Die nächste Era der Unternehmenssuche basiert auf Hybrid-Retrieval. Anstatt zwischen Stichwortsuche und semantischer Suche zu wählen, kombinieren moderne Systeme beide.
Die Stichwortsuche zeichnet sich durch Präzision aus. Die Vektorsuche erfasst Bedeutung und Absicht. Zusammen ermöglichen sie Sucherlebnisse, die für ein breites Spektrum an Suchanfragen schnell, flexibel und belastbar sind.
Cortex Search ist von Anfang an auf diesen hybriden Ansatz ausgerichtet. Es bietet eine qualitativ hochwertige Fuzzy-Suche mit geringer Latenz direkt über Snowflake-Daten, ohne dass Groups Einbettungen verwalten und Relevanzparameter optimieren oder eine benutzerdefinierte Infrastruktur pflegen müssen. Die Retrieval-Schicht passt sich den Daten an, nicht umgekehrt.
Anstatt die Suche als Zusatzfunktion zu behandeln, macht Coretx Search sie zu einer grundlegenden Funktion, die mit der Komplexität der Unternehmensdaten skaliert.
Cortex Search als Abrufschicht für KI und Unternehmenssuche
Cortex Search unterstützt zwei Hauptanwendungsfälle, die für moderne Datenstrategien immer wichtiger werden.
Erstens ist Augmented Era abrufen. Cortex Search fungiert als Retrieval-Engine, die große Sprachmodelle mit präzisem, aktuellem Unternehmenskontext versorgt. Diese Erdungsschicht ermöglicht es KI-Chat-Anwendungen, Antworten zu liefern, die spezifisch und related sind und auf proprietäre Daten statt auf generische Muster abgestimmt sind.
Zweitens ist Unternehmenssuche. Cortex Search kann hochwertige Sucherlebnisse ermöglichen, die direkt in Anwendungen, Instruments und Workflows eingebettet sind. Benutzer stellen Fragen in natürlicher Sprache und erhalten Ergebnisse, die sowohl nach semantischer Relevanz als auch nach Schlüsselwortgenauigkeit geordnet sind.
Unter der Haube indiziert die Cortex-Suche Textdaten, wendet Hybrid-Retrieval an und nutzt semantisches Reranking, um die relevantesten Ergebnisse anzuzeigen. Aktualisierungen erfolgen automatisiert und inkrementell, sodass die Suchergebnisse ohne manuelles Eingreifen mit dem aktuellen Standing der Daten übereinstimmen.
Dies ist wichtig, da die Abrufqualität das Vertrauen der Benutzer direkt beeinflusst. Wenn die Suche konsistent funktioniert, verlassen sich die Leute darauf. Wenn dies nicht der Fall ist, verwenden sie es nicht mehr und greifen auf langsamere und teurere Wege zurück.
Wie die Cortex-Suche in der Praxis funktioniert
Auf hohem Niveau abstrahiert Cortex Search die schwierigsten Teile beim Aufbau eines modernen Retrieval-Methods.
Beispiel: Unterstützung von RAG-Anwendungen mit Cortex Search
Was wir bauen werden: Ein KI-Assistent für den Kundensupport, der Benutzerfragen beantwortet, indem er fundierten Kontext aus historischen Assist-Tickets und Transkripten abruft und diesen Kontext dann an einen Snowflake Cortex LLM weiterleitet, um genaue, spezifische Antworten zu generieren.
Voraussetzungen
| Erfordernis | Einzelheiten |
| Snowflake-Konto |
Kostenlose Testversion unter attempt.snowflake.com – Enterprise-Stufe oder höher |
| Schneeflockenrolle |
SYSADMIN oder eine Rolle mit den Berechtigungen CREATE DATABASE, CREATE WAREHOUSE, CREATE CORTEX SEARCH SERVICE |
| Python | 3,9+ |
| Pakete | Schneeflocke-Snowpark-Python, Schneeflockenkern |
Snowflake-Konto einrichten
- Gehen Sie rüber zu attempt.snowflake.com und Melden Sie sich für das Enterprise-Konto an
- Jetzt sehen Sie etwa Folgendes:
Schritt 1 – Richten Sie die Snowflake-Umgebung ein
Führen Sie Folgendes in einem Snowflake-Arbeitsblatt aus, um die Datenbank und das Schema zu erstellen
Erstellen Sie zunächst eine neue SQL-Datei.
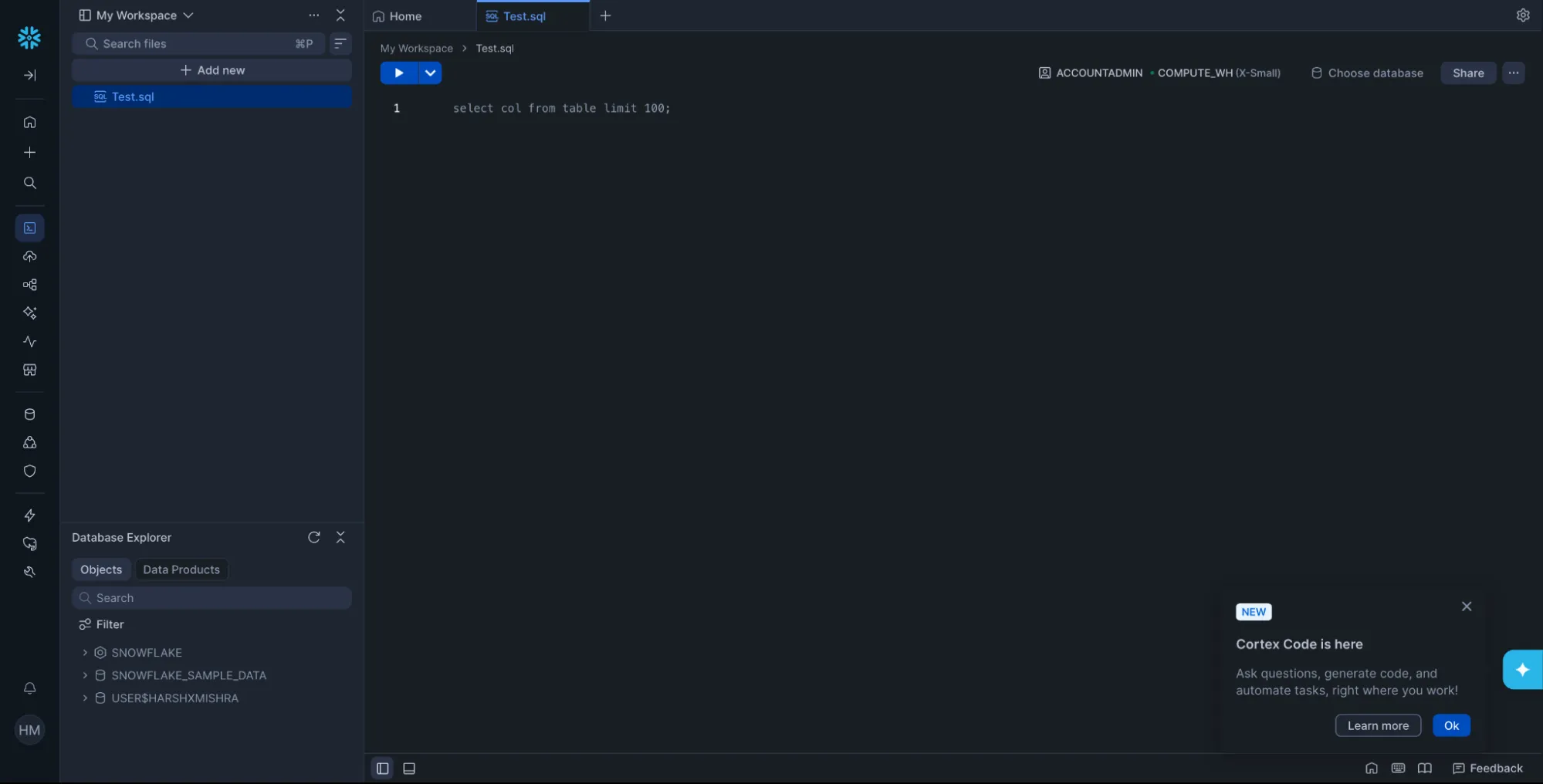
CREATE DATABASE IF NOT EXISTS SUPPORT_DB;
CREATE WAREHOUSE IF NOT EXISTS COMPUTE_WH
WAREHOUSE_SIZE = 'X-SMALL'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE;
USE DATABASE SUPPORT_DB;
USE WAREHOUSE COMPUTE_WH;Schritt 2 – Erstellen und füllen Sie die Quelltabelle
Diese Tabelle simuliert historische Assist-Tickets. In der Produktion könnte dies eine Dwell-Tabelle sein, die von Ihrem CRM, Ticketsystem oder Ihrer Datenpipeline synchronisiert wird.
CREATE TABLE IF NOT EXISTS SUPPORT_DB.PUBLIC.support_tickets (
ticket_id VARCHAR(20),
issue_category VARCHAR(100),
user_query TEXT,
decision TEXT,
created_at TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP()
);
INSERT INTO SUPPORT_DB.PUBLIC.support_tickets (ticket_id, issue_category, user_query, decision) VALUES
('TKT-001', 'Connectivity',
'My web retains dropping each couple of minutes. The router lights look regular.',
'Agent checked line diagnostics. Discovered intermittent sign degradation on the coax line. Dispatched technician to interchange splitter. Problem resolved after {hardware} swap.'),
('TKT-002', 'Connectivity',
'Web may be very sluggish throughout evenings however wonderful within the morning.',
'Community congestion detected in buyer section throughout peak hours (6–10 PM). Upgraded buyer to a much less congested node. Speeds normalized inside 24 hours.'),
('TKT-003', 'Billing',
'I used to be charged twice for a similar month. Want a refund.',
'Duplicate billing confirmed as a result of cost gateway retry error. Refund of $49.99 issued. Buyer notified by way of electronic mail. Root trigger patched in billing system.'),
('TKT-004', 'Gadget Setup',
'My new router just isn't exhibiting up within the Wi-Fi checklist on my laptop computer.',
'Router was broadcasting on 5GHz solely. Buyer laptop computer had outdated Wi-Fi driver that didn't help 5GHz. Guided buyer to replace driver. Each 2.4GHz and 5GHz bands now seen.'),
('TKT-005', 'Connectivity',
'Frequent packet loss throughout video calls. Wired connection additionally affected.',
'Packet loss traced to defective ethernet port on modem. Changed modem beneath guarantee. Buyer confirmed secure connection post-replacement.'),
('TKT-006', 'Account',
'Can't log into the shopper portal. Password reset emails aren't arriving.',
'Electronic mail supply blocked by SPF file misconfiguration on buyer area. Suggested buyer to supply help area. Reset electronic mail delivered efficiently.'),
('TKT-007', 'Connectivity',
'Web unstable solely when microwave is operating within the kitchen.',
'2.4GHz Wi-Fi interference brought on by microwave proximity to router. Beneficial switching router channel from 6 to 11 and enabling 5GHz band. Problem eradicated.'),
('TKT-008', 'Velocity',
'Marketed velocity is 500Mbps however I solely get round 120Mbps on speedtest.',
'Velocity take a look at confirmed 480Mbps at node. Buyer router restricted to 100Mbps as a result of Quick Ethernet port. Beneficial router improve. Put up-upgrade velocity confirmed at 470Mbps.');Schritt 3 – Erstellen Sie den Cortex-Suchdienst
Dieser einzelne SQL-Befehl übernimmt automatisch die Einbettungsgenerierung, die Indizierung und die Einrichtung des Hybridabrufs. Die ON-Klausel gibt an, welche Spalte für die Volltext- und semantische Suche indiziert werden soll. ATTRIBUTES definiert filterbare Metadatenspalten.
CREATE OR REPLACE CORTEX SEARCH SERVICE SUPPORT_DB.PUBLIC.support_search_svc
ON decision
ATTRIBUTES issue_category, ticket_id
WAREHOUSE = COMPUTE_WH
TARGET_LAG = '1 minute'
AS (
SELECT
ticket_id,
issue_category,
user_query,
decision
FROM SUPPORT_DB.PUBLIC.support_tickets
);Was passiert hier: Snowflake generiert automatisch Vektoreinbettungen für die Auflösungsspalte, erstellt sowohl einen Schlüsselwortindex als auch einen Vektorindex und stellt einen einheitlichen Hybrid-Abrufendpunkt bereit. Keine eingebettete Modellverwaltung, keine separate Vektordatenbank.
Sie können überprüfen, ob der Dienst aktiv ist:
SHOW CORTEX SEARCH SERVICES IN SCHEMA SUPPORT_DB.PUBLIC;Ausgabe:

Schritt 4 – Fragen Sie den Suchdienst über Python ab
Stellen Sie eine Verbindung zu Snowflake her und verwenden Sie das Snowflake-Core-SDK, um den Dienst abzufragen:
Installieren Sie zunächst die erforderlichen Pakete:
pip set up snowflake-snowpark-python snowflake-coreUm nun Ihre Kontodaten zu finden, gehen Sie zu Ihrem Konto und klicken Sie auf „Ein Instrument mit Snowflake verbinden“.
from snowflake.snowpark import Session
from snowflake.core import Root
# --- Connection config ---
connection_params = {
"account": "YOUR_ACCOUNT_IDENTIFIER", # e.g. abc12345.us-east-1
"consumer": "YOUR_USERNAME",
"password": "YOUR_PASSWORD",
"function": "SYSADMIN",
"warehouse": "COMPUTE_WH",
"database": "SUPPORT_DB",
"schema": "PUBLIC",
}
# --- Create Snowpark session ---
session = Session.builder.configs(connection_params).create()
root = Root(session)
# --- Reference the Cortex Search service ---
search_svc = (
root.databases("SUPPORT_DB")
.schemas("PUBLIC")
.cortex_search_services("SUPPORT_SEARCH_SVC")
)
def retrieve_context(question: str, category_filter: str = None, top_k: int = 3):
"""Run hybrid search towards the Cortex Search service."""
filter_expr = {"@eq": {"issue_category": category_filter}} if category_filter else None
response = search_svc.search(
question=question,
columns=("ticket_id", "issue_category", "user_query", "decision"),
filter=filter_expr,
restrict=top_k,
)
return response.outcomes
# --- Take a look at retrieval ---
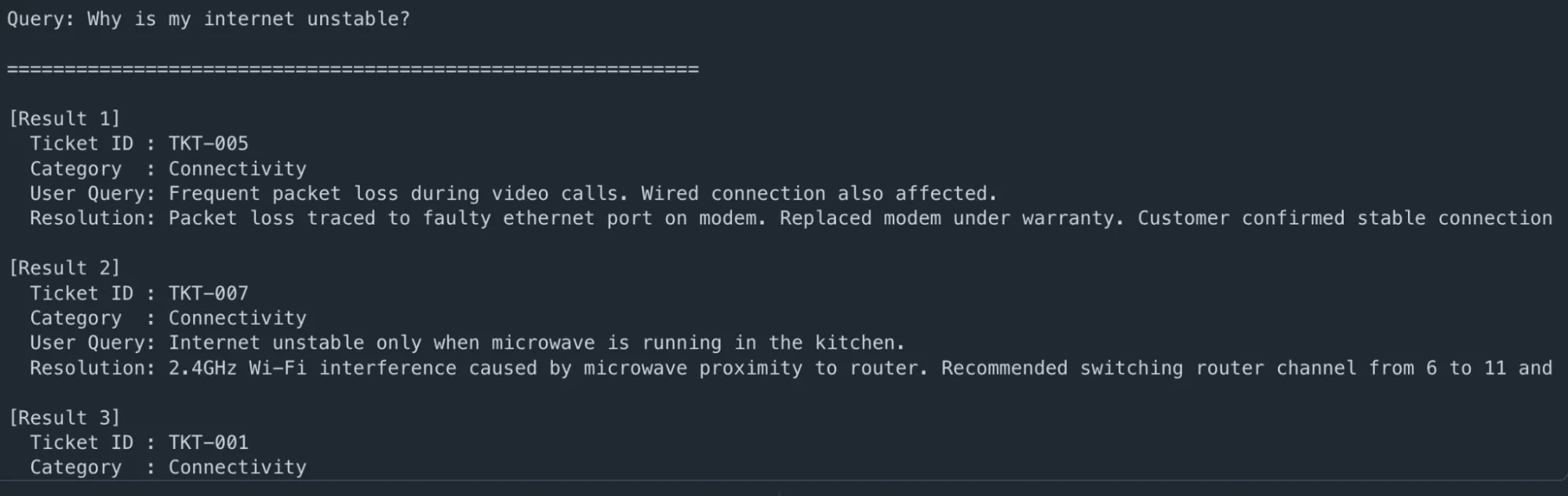
user_question = "Why is my web unstable?"
outcomes = retrieve_context(user_question, top_k=3)
print(f"n🔍 Question: {user_question}n")
print("=" * 60)
for i, r in enumerate(outcomes, 1):
print(f"n(End result {i})")
print(f" Ticket ID : {r('ticket_id')}")
print(f" Class : {r('issue_category')}")
print(f" Consumer Question: {r('user_query')}")
print(f" Decision: {r('decision')(:200)}...")Ausgabe:
Schritt 5 – Erstellen Sie die vollständige RAG-Pipeline
Übergeben Sie nun den abgerufenen Kontext an Snowflake Cortex LLM (mistral-large oder llama3.1-70b), um eine fundierte Antwort zu generieren:
import json
def build_rag_prompt(user_question: str, retrieved_results: checklist) -> str:
"""Format retrieved context into an LLM-ready immediate."""
context_blocks = ()
for r in retrieved_results:
context_blocks.append(
f"- Ticket {r('ticket_id')} ({r('issue_category')}): "
f"Buyer reported '{r('user_query')}'. "
f"Decision: {r('decision')}"
)
context_str = "n".be a part of(context_blocks)
return f"""You're a useful buyer help assistant. Use ONLY the context beneath
to reply the shopper's query. Be particular and concise.
CONTEXT FROM HISTORICAL TICKETS:
{context_str}
CUSTOMER QUESTION: {user_question}
ANSWER:"""
def ask_rag_assistant(user_question: str, mannequin: str = "mistral-large2"):
"""Full RAG pipeline: retrieve → increase → generate."""
print(f"n📡 Retrieving context for: '{user_question}'")
outcomes = retrieve_context(user_question, top_k=3)
print(f" ✅ Retrieved {len(outcomes)} related tickets")
immediate = build_rag_prompt(user_question, outcomes)
safe_prompt = immediate.change("'", "'")
sql = f"""
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'{mannequin}',
'{safe_prompt}'
) AS reply
"""
consequence = session.sql(sql).acquire()
reply = consequence(0)("ANSWER")
return reply, outcomes
# --- Run the assistant ---
questions = (
"Why is my web unstable?",
"I am being charged incorrectly, what ought to I do?",
"My router just isn't seen on my gadgets",
)
for q in questions:
reply, ctx = ask_rag_assistant(q)
print(f"n{'='*60}")
print(f"❓ Buyer: {q}")
print(f"n🤖 AI Assistant:n{reply.strip()}")
print(f"n📎 Grounded in tickets: {(r('ticket_id') for r in ctx)}")Ausgabe:
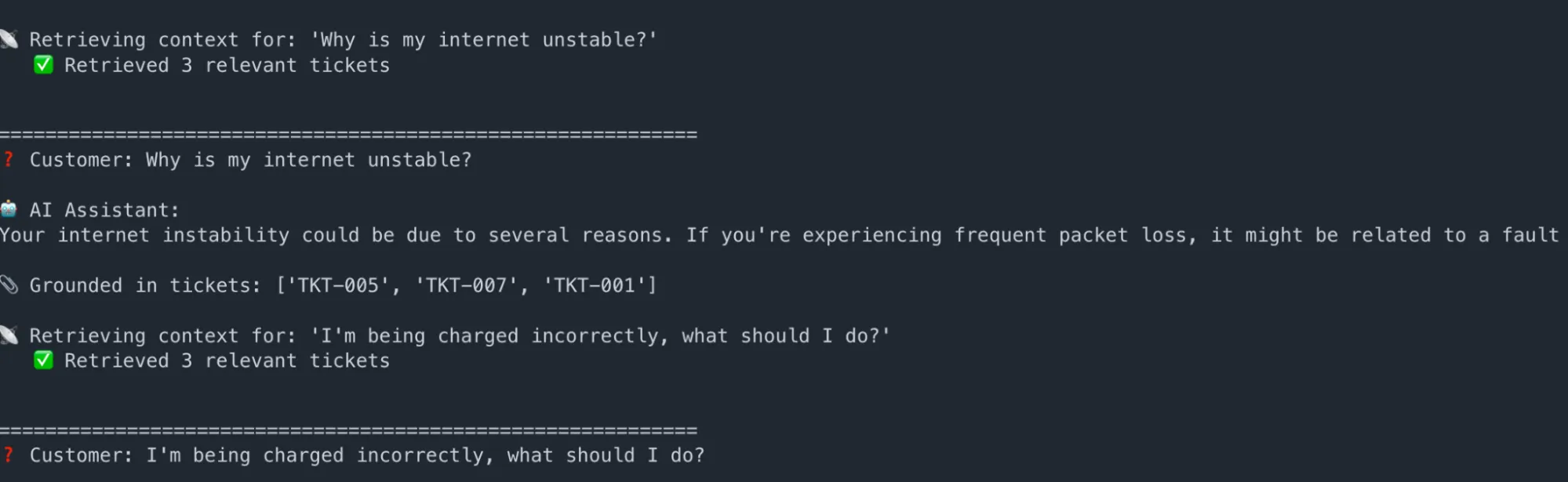
Schlüssel zum Mitnehmen: Die KI generiert niemals generische Antworten. Jede Reaktion lässt sich auf bestimmte historische Tickets zurückführen, was das Halluzinationsrisiko drastisch reduziert und die Ergebnisse überprüfbar macht.
Beispiel: Unternehmenssuche in Anwendungen integrieren
Was wir bauen werden:
Eine direkt in eine Anwendung eingebettete Assist-Ticket-Suchoberfläche in natürlicher Sprache, mit der Agenten und Kunden historische Tickets in einfachem Englisch durchsuchen können. Es ist keine neue Infrastruktur erforderlich: In diesem Beispiel werden genau die gleiche Tabelle „support_tickets“ und der Cortex-Suchdienst „support_search_svc“ wiederverwendet, die im RAG-Abschnitt oben erstellt wurden.
Dies zeigt, wie derselbe Cortex-Suchdienst zwei völlig unterschiedliche Oberflächen betreiben kann: einen KI-Assistenten auf der einen Seite und eine durchsuchbare Suchoberfläche auf der anderen Seite.
Schritt 1 — Bestätigen Sie, dass der vorhandene Dienst aktiv ist
Stellen Sie sicher, dass der im vorherigen Abschnitt erstellte Dienst noch ausgeführt wird:
USE DATABASE SUPPORT_DB;
USE SCHEMA PUBLIC;
SHOW CORTEX SEARCH SERVICES IN SCHEMA RAG_SCHEMA;Ausgabe:
Schritt 2 – Erstellen Sie den Enterprise Search Consumer
Dieses Modul stellt eine Verbindung zur gleichen Snowpark-Sitzung und zum gleichen support_search_svc-Dienst her und stellt eine Suchfunktion mit Kategoriefilterung und geordneter Ergebnisanzeige bereit – die Artwork von Schnittstelle, die Sie in ein Assist-Portal, ein internes Wissenstool oder ein Agenten-Dashboard einbetten würden.
# enterprise_search.py
from snowflake.snowpark import Session
from snowflake.core import Root
# --- Connection config ---
connection_params = {
"account": "YOUR_ACCOUNT_IDENTIFIER", # e.g. abc12345.us-east-1
"consumer": "YOUR_USERNAME",
"password": "YOUR_PASSWORD",
"function": "SYSADMIN",
"warehouse": "COMPUTE_WH",
"database": "SUPPORT_DB",
"schema": "PUBLIC",
}
session = Session.builder.configs(connection_params).create()
root = Root(session)
# --- Similar service because the RAG instance — no new service wanted ---
search_svc = (
root.databases("SUPPORT_DB")
.schemas("RAG_SCHEMA")
.cortex_search_services("SUPPORT_SEARCH_SVC")
)
def search_tickets(question: str, class: str = None, top_k: int = 5) -> checklist:
"""Pure language ticket search with non-compulsory class filter."""
filter_expr = {"@eq": {"issue_category": class}} if class else None
response = search_svc.search(
question=question,
columns=("ticket_id", "issue_category", "user_query", "decision"),
filter=filter_expr,
restrict=top_k,
)
return response.outcomes
def display_tickets(question: str, outcomes: checklist, filter_label: str = None):
"""Render search outcomes as a formatted ticket checklist."""
label = f" ({filter_label})" if filter_label else ""
print(f"n🔎 Search{label}: "{question}"")
print(f" {len(outcomes)} ticket(s) foundn")
print("-" * 72)
for i, r in enumerate(outcomes, 1):
print(f" #{i} {r('ticket_id')} | Class: {r('issue_category')}")
print(f" Buyer: {r('user_query')}")
print(f" Decision: {r('decision')(:160)}...n")Schritt 3 – Führen Sie Ticketsuchen in natürlicher Sprache durch
# --- Search 1: Semantic question — no actual match wanted ---
outcomes = search_tickets("machine not connecting to the community")
display_tickets("machine not connecting to the community", outcomes)Ausgabe:
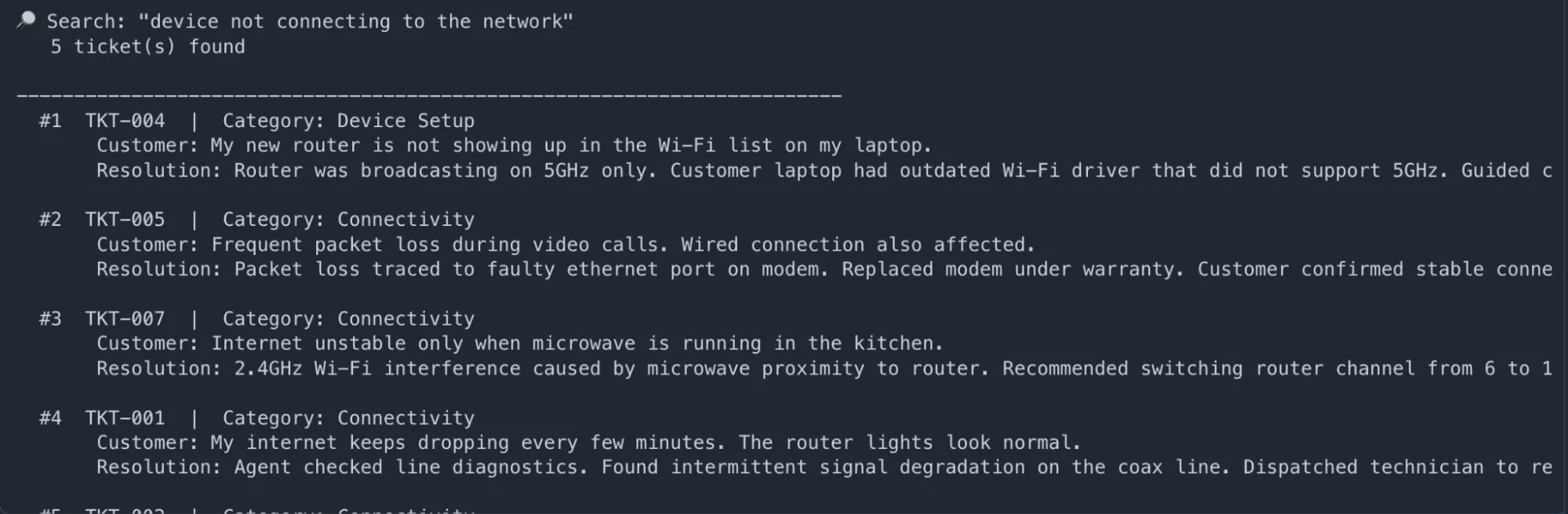
# --- Search 2: Class-filtered search (Billing solely) ---
outcomes = search_tickets(
question="incorrect cost or refund request",
class="Billing"
)
display_tickets(
"incorrect cost or refund request",
outcomes,
filter_label="Billing"
)2. Ausgabe:

# --- Search 3: Account & entry points ---
outcomes = search_tickets("cannot log in or entry my account", class="Account")
display_tickets("cannot log in or entry my account", outcomes, filter_label="Account")Ausgabe:

Schritt 4 – Als Flask Search API verfügbar machen (non-compulsory)
Binden Sie die Suchfunktion in einen REST-Endpunkt ein, um sie in jedes Assist-Portal, interne Instrument oder Chatbot-Backend einzubetten:
# app.py
from flask import Flask, request, jsonify
from enterprise_search import search_tickets
app = Flask(__name__)
@app.route("/tickets/search", strategies=("GET"))
def ticket_search():
question = request.args.get("q", "")
class = request.args.get("class") # non-compulsory filter
top_k = int(request.args.get("restrict", 5))
if not question:
return jsonify({"error": "Question parameter 'q' is required"}), 400
outcomes = search_tickets(question, class=class, top_k=top_k)
return jsonify({
"question": question,
"class": class,
"depend": len(outcomes),
"outcomes": outcomes,
})
if __name__ == "__main__":
app.run(port=5001, debug=True)Take a look at mit Curl:
# Free-text pure language search
curl "http://localhost:5001/tickets/search?q=web+retains+dropping&restrict=3"Ausgabe:
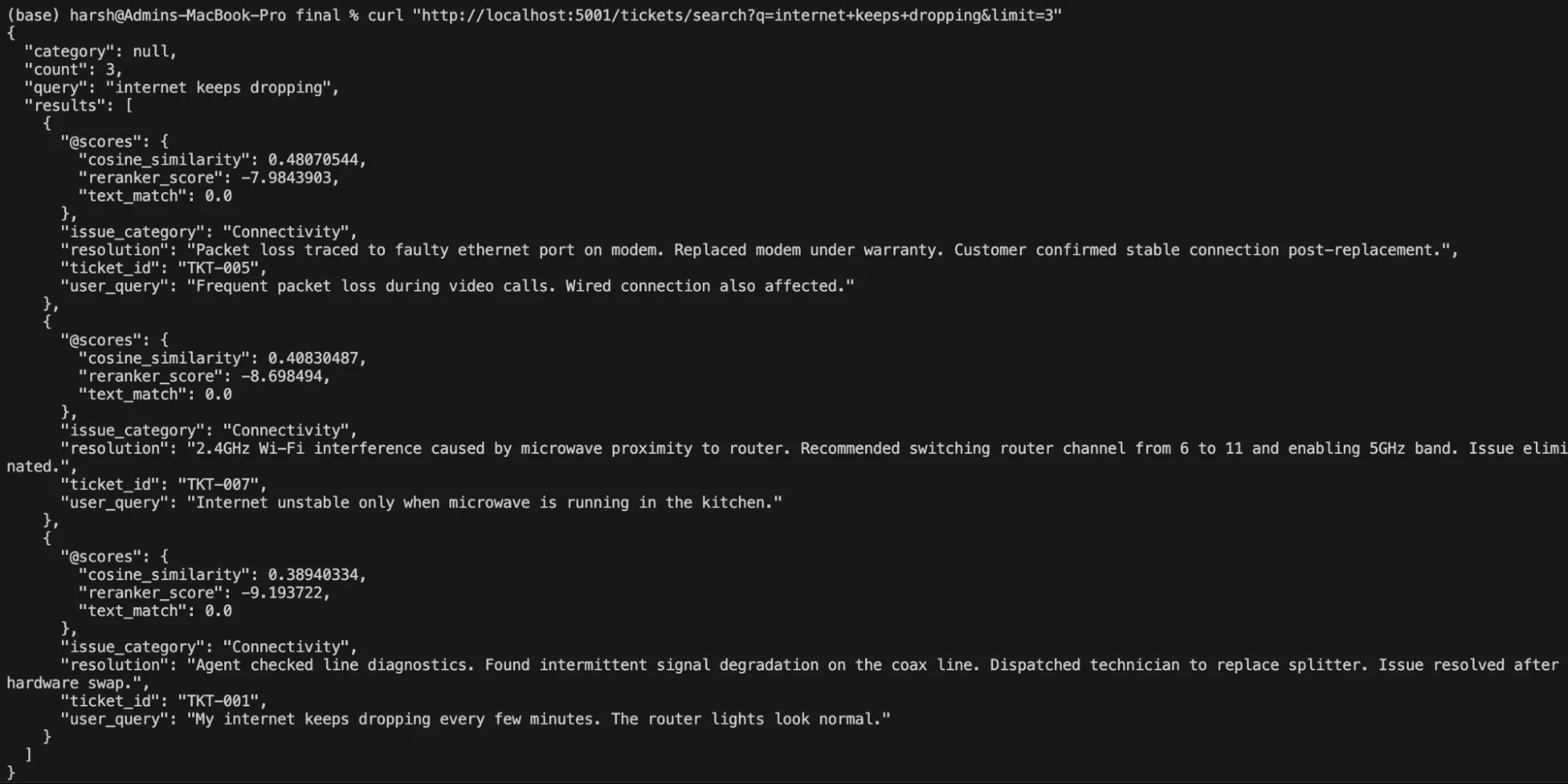
# Filtered by class
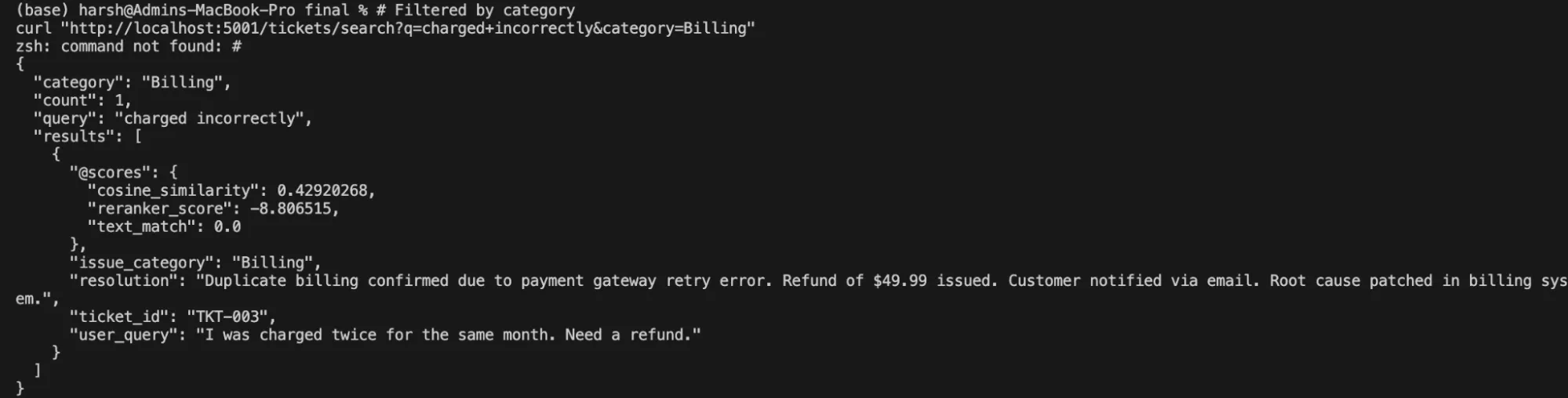
curl "http://localhost:5001/tickets/search?q=charged+incorrectly&class=Billing"Ausgabe:
Schlüssel zum Mitnehmen: Derselbe Cortex-Suchdienst, der dem RAG-Assistenten zugrunde liegt, unterstützt auch eine voll funktionsfähige Benutzeroberfläche für die Unternehmenssuche – keine Duplizierung der Infrastruktur, kein zu pflegender zweiter Index. Eine Servicedefinition stellt beide Erlebnisse bereit und beide bleiben automatisch synchronisiert, wenn Tickets hinzugefügt oder aktualisiert werden.
Die geschäftlichen Auswirkungen einer besseren Retrieval
Schlechte Methoden zur Datensuche beeinträchtigen stillschweigend die Unternehmensleistung. Es geht Zeit durch wiederholte Abfragen und Nacharbeiten verloren. Andererseits engagieren sich Assist-Groups bei der Lösung von Fragen, die eigentlich eigentlich selbst erledigt werden sollten. Neue Mitarbeiter und Kunden brauchen länger, um produktiv zu sein. KI-Initiativen geraten ins Stocken, wenn den Ergebnissen nicht vertraut werden kann.
Im Gegensatz dazu verändert ein starker Abruf die Arbeitsweise von Organisationen.
Groups kommen schneller voran, weil Antworten leichter zu finden sind. KI-Anwendungen sind leistungsfähiger, weil sie auf relevanten, aktuellen Daten basieren. Die Funktionsakzeptanz verbessert sich, da Benutzer Funktionen reibungslos entdecken und verstehen können. Die Supportkosten sinken, da die Suche Routinefragen absorbiert.
Cortex Search verwandelt den Abruf von einem Hintergrunddienstprogramm in einen strategischen Hebel. Es hilft Unternehmen dabei, den bereits in ihren Daten vorhandenen Wert zu erschließen, indem es sie in großem Umfang zugänglich, durchsuchbar und nutzbar macht.
Häufig gestellte Fragen
A. Es basiert auf Schlüsselwortabgleich und statischen Indizes, die es nicht schaffen, Absichten zu erfassen und mit dynamischen, verteilten Datenumgebungen Schritt zu halten.
A. Es kombiniert Schlüsselwortpräzision mit semantischem Verständnis und ermöglicht so schnellere, relevantere Ergebnisse, selbst bei mehrdeutigen oder konversationsbezogenen Abfragen.
A. Es bietet einen präzisen Abruf in Echtzeit, der KI-Antworten begründet und Sucherlebnisse ohne komplexe Infrastruktur oder manuelle Optimierung ermöglicht.
Dentsu World Companies (DGS), das globale Kompetenzzentrum von Dentsu, gestaltet die Zukunft als Innovationsmotor. DGS verfügt über mehr als 5.600 Experten, die sich auf digitale Plattformen, Efficiency-Advertising and marketing, Produktentwicklung, Datenwissenschaft, Automatisierung und KI spezialisiert haben, wobei die Medientransformation im Mittelpunkt steht. DGS liefert KI-orientierte, skalierbare Lösungen über das Netzwerk von Dentsu, das Menschen, Technologie und Handwerk nahtlos integriert. Sie verbinden menschliche Kreativität und fortschrittliche Technologie und bauen eine vielfältige, zukunftsorientierte Organisation auf, die sich schnell an die Bedürfnisse der Kunden anpasst und gleichzeitig Zuverlässigkeit, Zusammenarbeit und Exzellenz bei jedem Auftrag gewährleistet.
DGS bringt erstklassige Talente, bahnbrechende Technologien und mutige Ideen zusammen, um große Wirkung zu erzielen – für die Kunden von dentsu, seine Mitarbeiter und die Welt. Es ist ein zukunftsorientierter, branchenführender Arbeitsplatz, an dem Expertise auf Chancen trifft. Bei DGS können Mitarbeiter ihre Karriere beschleunigen, mit globalen Groups zusammenarbeiten und zu einer Arbeit beitragen, die die Zukunft gestaltet. Erfahren Sie mehr: Dentsu World Companies
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.