Vor ein paar Jahren fühlte es sich magisch an, ein Bild aus Textual content zu erstellen. Dann verwandelte Textual content-to-Video die Aufforderungen in bewegende Szenen. Jetzt generieren Modelle komplette Videosequenzen ohne Kameras, Schauspieler oder Bearbeitungszeitleisten. Seedance 2.0 von ByteDance treibt dies noch weiter voran. Anstelle kurzer Stummfilme liefert es ein multimodales System, das Szenen in Aufnahmen plant, Audio nativ synchronisiert und eine referenzgesteuerte Steuerung von Textual content, Bild, Video und Ton unterstützt. In diesem Artikel werden die Architektur, die wichtigsten Funktionen und Vergleiche erläutert Sora 2, Veo 3.1und Kling 3.0.
Was ist Seedance 2.0?
Seedance 2.0 ist das fortschrittliche multimodale Videogenerierungsmodell von ByteDance, das filmische Multi-Shot-Movies mit synchronisiertem Audio erstellt. Es akzeptiert Textual content-, Bild-, Video- und Audioeingaben und ermöglicht so eine referenzgesteuerte Steuerung und strukturierte Szenenplanung innerhalb einer einheitlichen, auf Diffusion basierenden Architektur.
Quelle: Ivanna | KI-Kunst und Eingabeaufforderungen
Wie greife ich auf Seedance 2.0 zu?
Derzeit verfügt Seedance 2.0 nicht über eine vollständig offene globale API, einige Apps und Modell-Internet hosting-Plattformen von Drittanbietern bieten jedoch eingeschränkten Zugriff. Bei den meisten davon handelt es sich um UI-basierte Kreativtools, mit denen Sie Movies mit Nutzungsbeschränkungen, regionalen Einschränkungen oder Zugriff nur auf Einladung erstellen können.
Sie können sich diese Seite als Referenz ansehen.
Hauptmerkmale
Immersives audiovisuelles Erlebnis
Durch außergewöhnliche Bewegungsstabilität und native Audio-Video-Joint-Generierung wird ein immersives audiovisuelles Erlebnis geboten. Durch die Erzeugung synchronisierter Bilder und Töne innerhalb desselben Generierungsprozesses erzielt das Modell eine ultrarealistische Ausgabe, die zusammenhängend und filmisch wirkt und nicht künstlich zusammengesetzt.
Erstellen Sie mit Kontrolle auf Direktorenebene
Durch die Unterstützung von Bildern, Audio und Video als Referenzeingaben können Entwickler Ideen mit einem hohen Maß an Kontrolle in visuelle Darstellungen umwandeln. Leistung, Beleuchtung, Schatten und Kamerabewegung können alle gesteuert werden, was eine strukturierte Szenenerstellung ermöglicht, die eher einer absichtlichen Regie als einer reinen Eingabeaufforderung ähnelt.
Filmische, branchengerechte Ausgabe
Hinweis: Alle oben genannten Movies stammen von ByteDance Webseite.
Leistung von Seedance 2.0
Benchmark-Ergebnisse von SeedVideoBench-2.0 weisen auf eine führende Leistung in mehreren Aufgabenkategorien hin. Das Modell bietet eine starke Leistung bei Textual content-zu-Video-, Bild-zu-Video- und multimodalen Aufgaben und zeigt eine konsistente Leistungsfähigkeit über verschiedene Generierungsszenarien hinweg.
Wie funktioniert Seedance 2.0?
Seedance 2.0 fungiert als einheitliches multimodales Diffusionssystem, das gemeinsam Video und Audio aus strukturierten Konditionierungseingaben generiert. Anstatt Textual content, Bilder, Videoreferenzen und Ton als separate Signale zu behandeln, kodiert es sie in einen gemeinsamen latenten Raum und führt über die Zeit hinweg eine koordinierte Entrauschung durch. Das Ergebnis ist eine synchronisierte Audio-Video-Sequenz mit mehreren Aufnahmen, die in einer einzigen Pipeline generiert wird.
So ist das System aufgebaut.
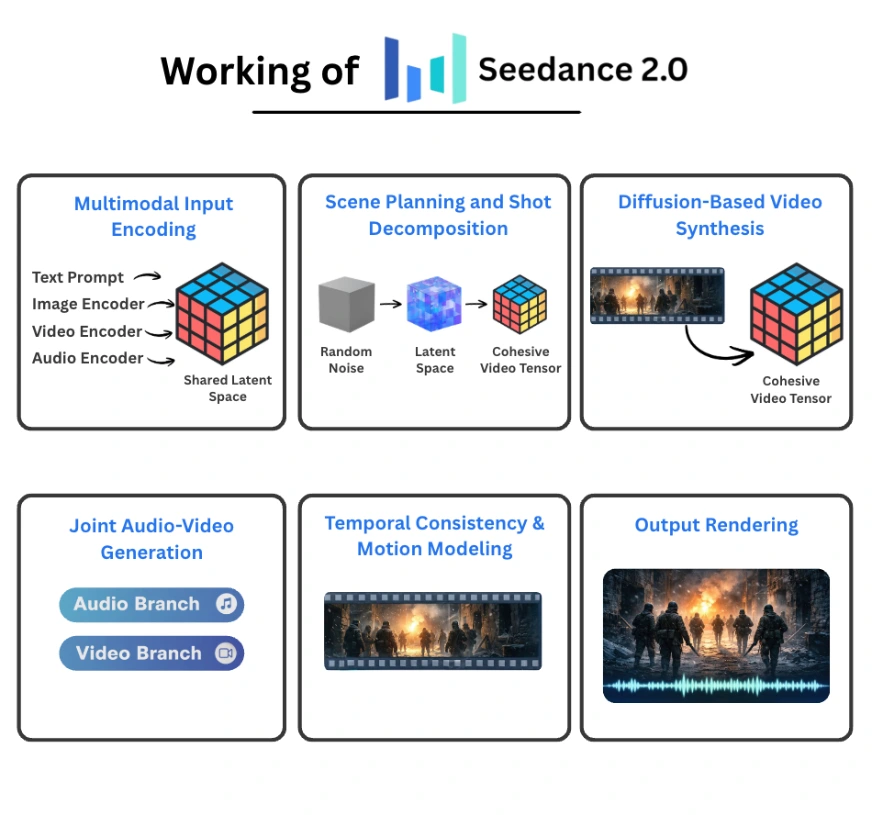
Multimodale Eingabekodierung
Jede Modalität wird von einem eigenen Encoder verarbeitet:
- Ein Textencoder wandelt Eingabeaufforderungen in semantische Einbettungen um.
- Ein Bildencoder wandelt Bilder in visuelle Token auf Patch-Ebene um.
- Ein Video-Encoder erzeugt raumzeitliche Token, die Bewegung und Szenenstruktur erfassen.
- Ein Audio-Encoder extrahiert Wellenform- oder Spektrogrammdarstellungen.
Alle Einbettungen werden in eine gemeinsame latente Darstellung projiziert. Dieser einheitliche Raum ermöglicht eine modalübergreifende Interaktion. Eine Textanweisung zur Beleuchtung kann den visuellen Ton beeinflussen, während eine Musikreferenz das Tempo und die Bewegung beeinflussen kann. Da sich alles im selben Repräsentationsraum befindet, ist die Konditionierung kohärent und nicht lose zusammengefügt.
Szenenplanung und Bildzerlegung
Bevor die Rahmensynthese beginnt, interpretiert Seedance die Eingabeaufforderung und erstellt einen strukturierten internen Plan.
Anstatt einen einzigen ununterbrochenen Clip zu generieren, führt das System Folgendes durch:
- Analysiert die narrative Absicht.
- Unterteilt die Szene in mehrere Einstellungen.
- Plant Übergänge und deren Kontinuität.
Diese Planungsebene funktioniert wie ein automatisierter Storyboard-Generator. Charakteridentität, Lichtverhältnisse und räumliche Anordnung bleiben über alle Schnitte hinweg erhalten. Dies verhindert Identitätsdrift und abrupte visuelle Inkonsistenzen, die bei naiven Videoverbreitungssystemen häufig auftreten.
Das Ergebnis ist nicht nur eine zeitliche Bewegung, sondern eine Sequenz, die einer absichtlichen Kinematografie ähnelt.
Diffusionsbasierte Videosynthese
Die Videoerzeugung erfolgt über einen räumlich-zeitlichen Diffusionsprozess.
Die Pipeline funktioniert wie folgt:
- Initialisieren Sie zufälliges Rauschen im latenten Raum.
- Konditionieren Sie die Entrauschungsschritte für multimodale Einbettungen.
- Verfeinern Sie räumliche und zeitliche Darstellungen iterativ.
- Erzeugen Sie einen kohärenten Videotensor.
Im Gegensatz zur Bildverbreitung muss die Videoverbreitung über die Zeit konsistent bleiben. Das Transformer-Spine sorgt für die Wahrung der Objektstruktur und Bewegungskontinuität über Frames hinweg. Dadurch wird Flimmern reduziert, Objektveränderungen verhindert und die Kamerabewegung stabilisiert.
Gemeinsame Audio-Video-Generierung
Eines der markantesten Elemente von Seedance 2.0 ist die gleichzeitige Audio- und Videoerzeugung.
Die Architektur umfasst:
- Ein Videozweig, der für die visuelle Rauschunterdrückung verantwortlich ist.
- Ein Audiozweig, der für die Wellenformerzeugung verantwortlich ist.
Diese Zweige tauschen während der Inferenz zeitliche Signale aus. Wenn im Videostream ein sichtbares Ereignis auftritt, generiert der Audiozweig den entsprechenden Ton, der genau auf diesen Second abgestimmt ist. Lippenbewegungen können mit Sprache synchronisiert werden. Umwelteinflüsse entsprechen physikalischen Wechselwirkungen.
Die gemeinsame Generierung beider Modalitäten verbessert die Ausrichtung im Vergleich zu Systemen, die Audio erst nach Abschluss der Videosynthese anhängen.
Zeitliche Stabilität und Bewegungsmodellierung
Die Videosynthese bringt Herausforderungen mit sich, denen sich statische Bildmodelle nicht stellen müssen:
- Langfristige zeitliche Kohärenz
- Konsistente Charakteridentität
- Physikalisch believable Bewegung
Seedance begegnet diesen Problemen durch:
- Raumzeitliche Aufmerksamkeitsmechanismen
- Bewegungsbewusste latente Konditionierung
- Umfangreiche Video-Audio-Trainingsdaten
Durch die Modellierung von Bewegungstrajektorien anstelle unabhängiger Frames sorgt das System für sanftere Übergänge und ein stabileres Objektverhalten über die Zeit.
Ausgabe-Rendering
Nachdem alle geplanten Aufnahmen generiert wurden:
- Schusssegmente werden intern kombiniert.
- Audiostreams werden an der visuellen Zeitleiste ausgerichtet.
- Die endgültige Videodatei wird gerendert.
Die Ausgabe kann bis zu etwa 15 Sekunden dauern und mehrere Kamerawinkel innerhalb einer einzigen Generierungsanforderung umfassen.
Seedance 2.0 vs. Sora 2
Sora 2 wird oft als Realitätssimulator beschrieben. Es zeichnet sich durch die Modellierung der Physik aus, einschließlich der Schwerkraft, der Flüssigkeitsbewegung und der Objektpermanenz, selbst wenn sich Objekte außerhalb des Bildschirms bewegen. Für langanhaltenden Realismus und physisch kohärente Umgebungen bleibt Sora äußerst stark.
Seedance konkurriert eng mit dem Realismus, unterscheidet sich jedoch durch sein quadmodales Referenzsystem. Im Gegensatz zu Sora, das hauptsächlich auf Textual content- und begrenzte Bildeingaben setzt, ermöglicht Seedance die direkte Zuweisung von Textual content-, Foto-, Video- und Audioreferenzen. Dies ermöglicht Stilübertragung, Bewegungsklonen und sprachgesteuerte Generierung auf dynamischere Weise als der auf Eingabeaufforderungen basierende Ansatz von Sora.
Ein weiterer wichtiger Unterschied liegt in der Audioerzeugung. Seedance verwendet einen Twin-Department-Transformator, um Video und Audio gleichzeitig zu erzeugen. Dies führt zu einer engeren Synchronisierung zwischen sichtbaren Ereignissen und Ton. Sora behandelt Audio eher als sekundären Prozess und nicht als eng gekoppelten Erzeugungsstrom.
Seedance 2.0 vs. Google Veo 3.1
Veo 3.1 bietet präzise Steuerung durch maskierte Bearbeitung und kameraspezifische Befehle wie Schwenken, Neigen und Zoomen. Dadurch wirkt es wie eine digitale Bearbeitungssuite, in der Entwickler bestimmte Bereiche eines Bildes verfeinern können, ohne die gesamte Szene neu zu generieren.
Seedance verfolgt einen referenzgesteuerten Ansatz anstelle einer maskengesteuerten Bearbeitung. Anstatt Teile eines Movies manuell zu ändern, können Benutzer Referenzclips hochladen, um Bewegungsstil, Beleuchtung oder Stimmung auf eine neue Era zu übertragen. Während bei Veo die chirurgische Bearbeitung im Vordergrund steht, legt Seedance den Schwerpunkt auf die kontrollierte Stilreplikation.
In Bezug auf die Audio-Video-Ausrichtung behält Seedance aufgrund seiner gemeinsamen Generationsarchitektur einen Vorteil. Die Synchronisierung von Veo ist stark, aber nicht so eng integriert wie die gleichzeitige Audio-Video-Verbreitung von Seedance.
Seedance 2.0 vs. Kling 3.0
Sowohl Seedance als auch Kling leisten gute Arbeit bei der Wahrung der Charakterkonsistenz, ihre Methoden unterscheiden sich jedoch.
Mit dem Omni-Modus von Kling können Benutzer bestimmte Gesichter, Outfits und Elemente zu wiederverwendbaren Property verknüpfen. Dies ist nützlich, wenn Sie wiederkehrende Charaktere für episodische Inhalte erstellen. Es erstellt eine kontrollierte Asset-Bibliothek, die szenenübergreifend wiederverwendet werden kann.
Seedance konzentriert sich mehr auf das Klonen von Referenzen und den Stiltransfer. Anstatt interne Property zu binden, können Benutzer Bewegung, Beleuchtung und Efficiency-Stil von externen Medien übertragen. Kling eignet sich besser zum Aufbau einer wiederverwendbaren Besetzung, während Seedance besser dazu geeignet ist, ein bestimmtes Kinogefühl aus einer vorhandenen Referenz zu reproduzieren.
Kling bietet außerdem eine starke Kontrolle über den Dialogton und die mehrsprachige Spracherzeugung. Seine Synchronisierung übertrifft mehrere Konkurrenten. Allerdings hat Seedance bei der bildgenauen Audio-Video-Ausrichtung immer noch einen leichten Vorsprung.
Lesen Sie auch: High 10 KI-Videogeneratoren
Abschluss
Seedance 2.0 scheint ein echter Fortschritt in der KI-Videogenerierung zu sein. Die quadmodalen Eingaben, die enge Audio-Video-Synchronisierung und die integrierte Aufnahmeplanung machen es zu mehr als nur einem weiteren Immediate-to-Video-Instrument. Es sieht aus wie ein leichtes virtuelles Produktionssystem. Sora 2, Veo 3.1 und Kling 3 haben jeweils klare Stärken, aber Seedance 2.0 zeichnet sich dadurch aus, wie viel Kontrolle es den Entwicklern gibt. Wenn der globale Zugriff eröffnet und die API-Unterstützung ausgeweitet wird, könnte dies zu einem leistungsstarken Werkzeug für reale kreative Arbeitsabläufe werden.
Hallo, ich bin Nitika, eine technisch versierte Content material-Erstellerin und Vermarkterin. Kreativität und das Lernen neuer Dinge sind für mich selbstverständlich. Ich habe Erfahrung in der Erstellung ergebnisorientierter Content material-Strategien. Ich kenne mich intestine mit Web optimization-Administration, Key phrase-Operationen, Net-Content material-Schreiben, Kommunikation, Content material-Strategie, Redaktion und Schreiben aus.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.