
LLMs sind nicht mehr auf ein Frage-Antwort-Format beschränkt. Sie bilden nun die Grundlage für intelligente Anwendungen, die bei realen Problemen in Echtzeit helfen. In diesem Zusammenhang ist Kimi K2 ein Mehrzweck-LLM, das weltweit bei AI-Nutzern sehr beliebt ist. Während jeder seine leistungsstarken agierenden Fähigkeiten kennt, sind sich nicht viele sicher, wie er auf der API funktioniert. Hier testen wir Kimi K2 in einem realen Produktionsszenario über einen API-basierten Workflow, um zu bewerten, ob Kimi K2 sein Versprechen eines großen LLM entspricht.
Lesen Sie auch: Möchten Sie das beste Open-Supply-System finden? Lesen Sie hier unsere Vergleichsbewertung zwischen Kimi K2 und Lama 4.
Was ist Kimi K2?
Kimi K2 ist ein hochmodernes Open-Supply-Großsprachmodell, das von Moonshot AI erstellt wurde. Es beschäftigt a Mischung aus Experten (MOE) Architektur und hat 1 Billionen Gesamtparameter (32 Milliarden professional Token aktiviert). Kimi K2 umfasst insbesondere zukunftslokende Anwendungsfälle für fortschrittliche Agenten-Intelligenz. Es ist nicht nur in der Lage, natürliche Sprache zu erzeugen und zu verstehen, sondern auch autonom komplexe Probleme zu lösen, Werkzeuge zu nutzen und mehrstufige Aufgaben über eine breite Palette von Domänen zu erledigen. Wir haben in einem früheren Artikel alles über seine Benchmark-, Leistung und Zugangspunkte ausführlich behandelt: Kimi K2 Das beste Open-Supply-Agentenmodell.
Modellvarianten
Es gibt zwei Varianten von Kimi K2:
- Kimi-K2-Base: Das Naked-Bones-Modell, ein guter Ausgangspunkt für Forscher und Bauherren, die die volle Kontrolle über Feinabstimmung und benutzerdefinierte Lösungen haben möchten.
- Kimi-K2-Instruktur: Das nachgebildete Modell, das am besten für ein Drop-In-, Allzweck-Chat- und Agentenerlebnis geeignet ist. Es ist ein Reflex-Modell ohne tiefes Denken.
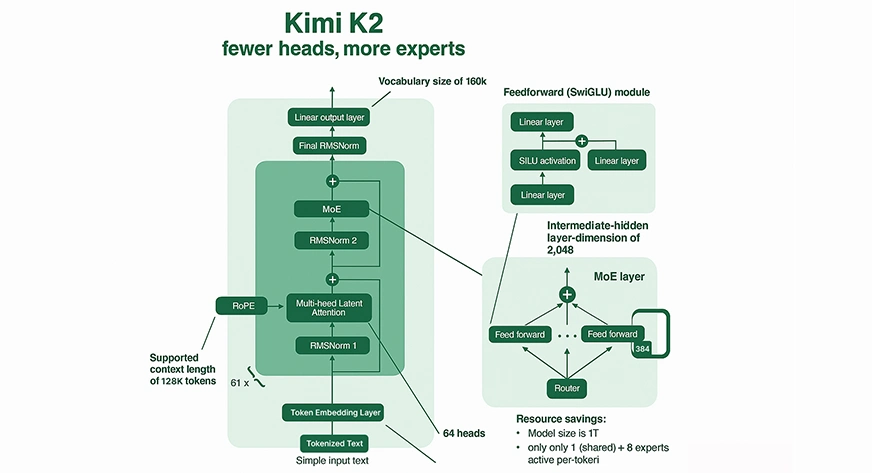
Mischungsmischung (MEE) Mechanismus
Fraktionsberechnung: Kimi K2 aktiviert nicht alle Parameter für jede Eingabe. Stattdessen leitet Kimi K2 jeden Token in 8 seiner 384 spezialisierten „Experten“ (plus ein gemeinsamer Experte), was im Vergleich zum MOE -Modell und dichten Modellen mit vergleichbarer Größe eine signifikante Rücknahme der Berechnung professional Inferenz darstellt.
Expertenspezialisierung: Jeder Experte in der MOE ist auf verschiedene Wissensbereiche oder Argumentationsmuster spezialisiert, was zu reichhaltigen und effizienten Outputs führt.
Spärmer Routing: Kimi K2 nutzt Good Gating, um relevante Experten für jedes Token zu leiten, was sowohl enorme Kapazitäten als auch recheninternen machbare Inferenz unterstützt.
Aufmerksamkeit und Kontext
Massives Kontextfenster: Kimi K2 hat eine Kontextlänge von bis zu 128.000 Token. Es kann extrem lange Dokumente oder Codebasen in einem einzigen Move verarbeiten, ein beispielloses Kontextfenster, das die meisten Legacy -LLMs weit überschreitet.
Komplexe Aufmerksamkeit: Das Modell verfügt über 64 Aufmerksamkeitsköpfe professional Schicht, sodass es komplizierte Beziehungen und Abhängigkeiten über die Reihenfolge der Token verfolgt und nutzen kann, die typischerweise bis zu 128.000 sind.
Schulungsinnovationen
Muonclip Optimierer: Um ein stabiles Coaching in dieser beispiellosen Skala zu ermöglichen, entwickelte Moonshot AI einen neuen Optimierer namens Muonclip. Es begrenzt die Skala der Aufmerksamkeitslogiten, indem es bei jedem Replace die Abfrage- und Schlüsselgewichtsmatrizen neu skaliert, um die excessive Instabilität (dh explodierende Werte) zu vermeiden, die in groß angelegten Modellen üblich sind.
Datenskala: Kimi K2 wurde auf 15,5 Billionen Token vorgebracht, was das Wissen und die Fähigkeit des Modells zur Verallgemeinerung entwickelt.
Wie kann man Kimi K2 zugreifen?
Wie bereits erwähnt, kann auf Kimi K2 auf zwei Arten zugegriffen werden:
Net/Anwendungsschnittstelle: Kimi kann sofort für den Gebrauch aus dem zugegriffen werden Offizieller Net -Chat.
API: Kimi K2 kann entweder mit der API von Collectively API oder Moonshot in Ihren Code integriert werden, die agierischen Workflows und die Verwendung von Instruments unterstützt.
Schritte, um einen API -Schlüssel zu erhalten
Um Kimi K2 durch eine API zu leiten, benötigen Sie einen API -Schlüssel. Hier erfahren Sie, wie man es bekommt:
Mondshot -API:
- Melden Sie sich an oder melden Sie sich bei der Mondshot -AI -Entwicklerkonsole an.
- Gehen Sie in den Abschnitt „API Keys“.
- Klicken Sie auf „API -Style erstellen“, geben Sie einen Namen und ein Projekt an (oder lassen Sie es standardmäßig hinterlassen) und speichern Sie Ihren Schlüssel für die Verwendung.
Zusammen ai api:
- Registrieren Sie sich oder melden Sie sich bei Collectively AI an.
- Suchen Sie den Bereich „API -Keys“ in Ihrem Dashboard.
- Generieren Sie einen neuen Schlüssel und zeichnen Sie ihn für die spätere Verwendung auf.
Lokale Set up
Laden Sie die Gewichte aus dem Umarmen oder Github herunter und führen Sie sie lokal mit VllM, Tensorrt-LlM oder Sglang aus. Befolgen Sie einfach diese Schritte.
Schritt 1: Erstellen Sie eine Python -Umgebung
Verwenden Sie Conda:
conda create -n kimi-k2 python=3.10 -y
conda activate kimi-k2Verwenden von Venv:
python3 -m venv kimi-k2
supply kimi-k2/bin/activateSchritt 2: Installieren Sie die erforderlichen Bibliotheken
Für alle Methoden:
pip set up torch transformers huggingface_hubvllm:
pip set up vllmTensorrt-Llm:
Folgen Sie dem Beamten (Tensorrt-Llm Set up Dokumentation) (erfordert Pytorch> = 2.2 und CUDA == 12.x; für alle Systeme nicht installierbar).
Für Sglang:
pip set up sglangSchritt 3: Modellgewichte herunterladen
Vom umarmen Gesicht:
Mit Git-LFS:
git lfs set up
git clone https://huggingface.co/moonshot-ai/Kimi-K2-InstructOder mit Huggingface_hub:
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="moonshot-ai/Kimi-K2-Instruct",
local_dir="./Kimi-K2-Instruct",
local_dir_use_symlinks=False,
)Schritt 4: Überprüfen Sie Ihre Umgebung
Um sicherzustellen, dass Cuda, Pytorch und Abhängigkeiten bereit sind:
import torch
import transformers
print(f"CUDA Out there: {torch.cuda.is_available()}")
print(f"CUDA Units: {torch.cuda.device_count()}")
print(f"CUDA Model: {torch.model.cuda}")
print(f"Transformers Model: {transformers.__version__}")Schritt 5: Führen Sie Kimi K2 mit Ihrem bevorzugten Backend aus
Mit vllm:
python -m vllm.entrypoints.openai.api_server
--model ./Kimi-K2-Instruct
--swap-space 512
--tensor-parallel-size 2
--dtype float16Passen Sie die Tensor-Parallel-Größe und DTYPE anhand Ihrer {Hardware} an. Ersetzen Sie durch quantisierte Gewichte, wenn Sie Int8- oder 4-Bit-Varianten verwenden.
Praktisch mit Kimi K2
In dieser Übung werden wir einen Blick darauf werfen, wie große Sprachmodelle wie Kimi K2 im wirklichen Leben mit echten API -Aufrufen arbeiten. Ziel ist es, seine Wirksamkeit in Bewegung zu testen und zu prüfen, ob es eine starke Leistung liefert.
Aufgabe 1: Erstellen eines 360 ° -Berichtungsgenerators mit Langgraph und Kimi K2:
In dieser Aufgabe erstellen wir einen 360-Grad-Berichtsgenerator mit der Langgraph Framework und der Kimi K2 LLM. Die Anwendung ist ein Präsent, wie agenten -Workflows choreografiert werden können, um Informationen durch die Verwendung von API -Interaktionen automatisch abzurufen, zu verarbeiten und zusammenzufassen.
Code -Hyperlink: https://github.com/sjsoumil/tutorials/blob/major/kimi_k2_hands_on.py
Codeausgabe:
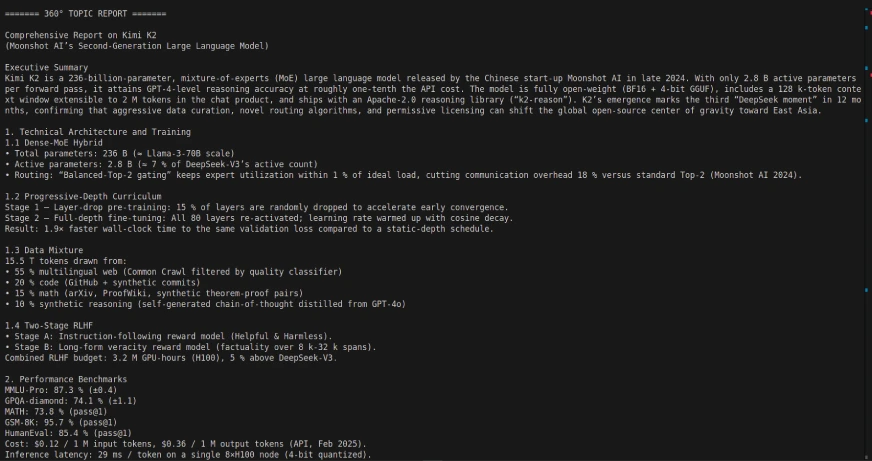
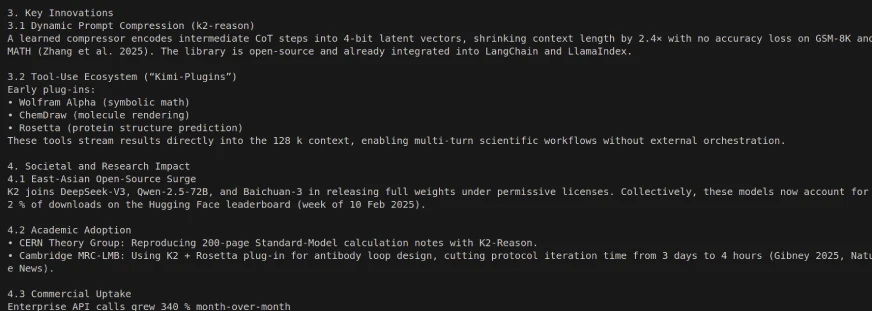
Die Verwendung von Kimi K2 mit Langgraph kann einige leistungsstarke, autonome multi-stufige Agenten-Workflows ermöglichen, da Kimi K2 so konzipiert ist, dass Multi-Step-Aufgaben wie Datenbankabfrage, Berichterstattung und Dokumentverarbeitung unter Verwendung von Instrument-/API-Integrationen autonom zerlegt werden. Temperieren Sie Ihre Erwartungen für einige Reaktionszeiten einfach.
Aufgabe 2: Erstellen eines einfachen Chatbots mit Kimi K2
Code:
from dotenv import load_dotenv
import os
from openai import OpenAI
load_dotenv()
OPENROUTER_API_KEY = os.getenv("OPENROUTER_API_KEY")
if not OPENROUTER_API_KEY:
elevate EnvironmentError("Please set your OPENROUTER_API_KEY in your .env file.")
shopper = OpenAI(
api_key=OPENROUTER_API_KEY,
base_url="https://openrouter.ai/api/v1"
)
def kimi_k2_chat(messages, mannequin="moonshotai/kimi-k2:free", temperature=0.3, max_tokens=1000):
response = shopper.chat.completions.create(
mannequin=mannequin,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
)
return response.decisions(0).message.content material
# Dialog loop
if __name__ == "__main__":
historical past = ()
print("Welcome to the Kimi K2 Chatbot (sort 'exit' to stop)")
whereas True:
user_input = enter("You: ")
if user_input.decrease() == "exit":
break
historical past.append({"function": "consumer", "content material": user_input})
reply = kimi_k2_chat(historical past)
print("Kimi:", reply)
historical past.append({"function": "assistant", "content material": reply})Ausgabe:
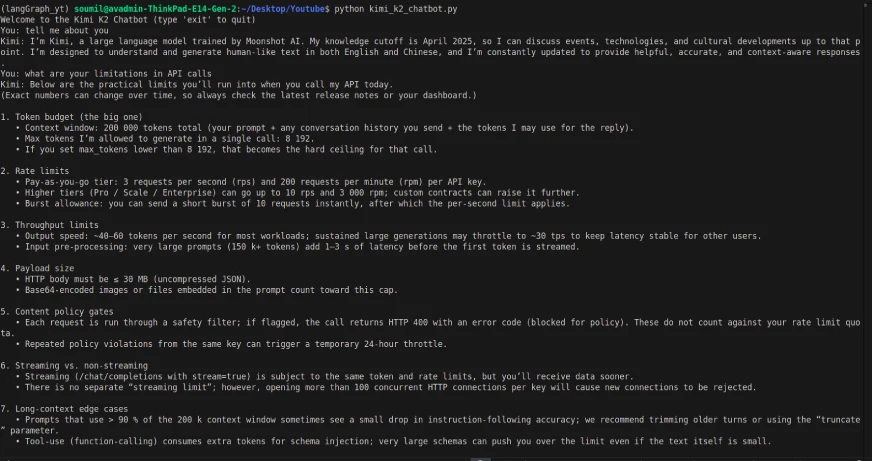
Obwohl das Modell multimodal conflict, hatte die API-Aufrufe nur die Möglichkeit, textbasierte Eingabe/Ausgabe bereitzustellen (und die Texteingabe hatte eine Verzögerung). Die Schnittstelle und der API -Anruf handeln additionally ein wenig anders.
Meine Bewertung nach dem Handpunkt
Der Kimi K2 ist ein Open-Supply- und großes Sprachmodell, was bedeutet, dass es kostenlos ist, und dies ist ein großes Plus für Entwickler und Forscher. Für diese Übung habe ich mit einem Openrouter -API -Schlüssel auf Kimi K2 zugegriffen. Während ich zuvor über die benutzerfreundliche Weboberfläche auf das Modell zugegriffen habe, habe ich es vorgezogen, die API für mehr Flexibilität zu verwenden und einen benutzerdefinierten agentischen Workflow in Langgraph zu erstellen.
Während des Testens des Chatbots wurden die Antwortzeiten, die ich mit den API-Aufrufen erlebt habe, merklich verzögert, und das Modell kann jedoch nicht multimodale Funktionen (z. B. Bild oder Dateiverarbeitung) über die API wie möglich unterstützen. Unabhängig davon hat das Modell intestine mit Langgraph zusammengearbeitet, was es mir ermöglichte, eine vollständige Pipeline für die Erzeugung von dynamischen 360 ° -Berichten zu entwerfen.
Während es nicht erdschüttelnd conflict, zeigt es, wie Open-Supply-Modelle holen sich schnell die proprietären Führer wie Openai und Gemini ein, und sie werden die Lücken mit Modellen wie Kimi K2 weiter schließen. Es ist eine beeindruckende Leistung und Flexibilität für ein kostenloses Modell, und es zeigt, dass die Messlatte bei multimodalen Funktionen mit Open-Supply-LLMs höher wird.
Abschluss
Kimi K2 ist eine großartige Choice in der Open-Supply-LLM-Landschaft, insbesondere für agierende Workflows und eine einfache Integration. Während wir einige Einschränkungen wie langsamere Reaktionszeiten über API und mangelnde Multimodalitätsunterstützung begegnen, bietet es einen großartigen Ort, um intelligente Anwendungen in der realen Welt zu entwickeln. Außerdem ist es ein großer Vorteil, diesen Fähigkeiten nicht zu bezahlen, der Entwicklern, Forschern und Begin-ups hilft. Wenn sich das Ökosystem weiterentwickelt und reift, werden Modelle wie Kimi K2 schnell fortgeschrittene Fähigkeiten gewinnen, da sie die Lücke zu proprietären Unternehmen schnell schließen. Insgesamt ist Kimi K2 eine mögliche Choice, die Ihre Zeit und Experimente wert ist, wenn Sie über Open-Supply-LLMs für den Produktionsgebrauch in Betracht ziehen.
Häufig gestellte Fragen
A. Kimi K2 ist Moonshot AIs Mischung der nächsten Technology (MOE) großes Sprachmodell mit 1 Billionen Gesamtparametern (32 Milliarden aktivierte Parameter professional Interaktion). Es ist für Agentenaufgaben, erweiterte Argumentation, Codegenerierung und Instruments ausgelegt.
– Erweiterte Codegenerierung und -Debugging
– automatisierte Agentenaufgabenausführung
-Komplexe, mehrstufige Probleme argumentieren und lösen
– Datenanalyse und Visualisierung
– Planung, Forschungsunterstützung und Inhaltserstellung
– – Architektur: Expertenmischungstransformator
– – Gesamtparameter: 1T (Billion)
– – Aktivierte Parameter: 32b (Milliarden) für jede Abfrage
– – Kontextlänge: Bis zu 128.000 Token
– – Spezialisierung: Werkzeuggebrauch, Agenten -Workflows, Codierung, lange Sequenzverarbeitung
– – API -Zugang: Erhältlich bei der API -Konsole von Moonshot AI (und auch von zusammen AI und OpenRouter unterstützt)
– – Lokale Bereitstellung: Vor Ort möglich; Benötigt leistungsstarke lokale {Hardware} normalerweise (für eine effektive Verwendung erfordert mehrere Excessive-Finish-GPUs)
– – Modellvarianten: Veröffentlicht als „Kimi-K2-Base“ (zur Anpassung/Feinabstimmung) und „Kimi-K2-Instruction“ (für allgemeine Chat, Agenteninteraktionen).
A. Kimi K2 entspricht typischerweise entspricht oder übertrifft typischerweise Open-Supply-Modelle (z. B. Deepseek V3, Qwen 2.5). Es ist wettbewerbsfähig mit proprietären Modellen für Benchmarks für Codierung, Argumentation und Agentenaufgaben. Es ist auch bemerkenswert effizient und kostengünstig im Vergleich zu anderen Modellen ähnlicher oder kleinerer Maßstäbe!
Datenwissenschaftler | AWS Licensed Options Architect | KI & ML Innovator
Als Datenwissenschaftler bei Analytics Vidhya spezialisiere ich mich auf maschinelles Lernen, Deep Studying und KI-gesteuerte Lösungen, die NLP-, Laptop-Imaginative and prescient- und Cloud-Technologien nutzen, um skalierbare Anwendungen zu erstellen.
Mit einem B.Tech in Informatik (Information Science) aus VIT- und Zertifizierungen wie AWS Licensed Options Architect und TensorFlow umfasst meine Arbeit generative KI, Anomalie -Erkennung, falsche Nachrichtenerkennung und Emotionserkennung. Ich bemühe mich, intelligente Systeme zu entwickeln, die die Zukunft der KI prägen.
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.