Wenn jemand zugibt, dass er einen Fehler gemacht hat, passiert etwas Überraschendes. Das Geständnis stellt das Vertrauen oft wieder her, anstatt es zu zerstören. Menschen fühlen sich in der Nähe von jemandem, der zu seinen Fehlern steht, sicherer als von jemandem, der sie verbirgt. Verantwortung schafft Vertrauen.
Was wäre, wenn KI-Modelle dasselbe könnten? Die meisten KI-Systeme geben sichere Antworten, selbst wenn sie tatsächlich halluzinieren. Die endgültige Ausgabe sieht korrekt aus, aber wir haben keine Ahnung, was tatsächlich hinter den Kulissen passiert ist. Es gibt kein Zögern.
Deshalb hat die neue Idee von OpenAI meine Aufmerksamkeit erregt. Ich habe ihren Weblog über „Geständnisse“ gelesen und er führt eine einfache, aber wirkungsvolle Wendung ein: Nachdem das Modell eine Antwort generiert hat, erzeugt es eine zweite Antwort, in der es ehrlich beschreibt, ob es den Anweisungen gefolgt ist, gegen die Regeln verstoßen hat, Vermutungen angestellt oder Abstriche gemacht hat. Dieser separate Bericht ist so gestaltet, dass er wahrheitsgetreu ist, auch wenn die Hauptantwort versucht, ausgefeilt zu wirken.
Dies spiegelt die gleiche Dynamik wider, die wir beim Menschen sehen. Transparenz schafft Vertrauen. Versteckte Fehler lassen Zweifel aufkommen. Ein Geständnis überbrückt die beiden. Lassen Sie uns mehr darüber erfahren.
Was haben die KI-Geständnisexperimente tatsächlich gezeigt?
OpenAI führte kontrollierte Checks durch, um zu überprüfen, ob ein Modell tatsächlich zugeben würde, wenn es Anweisungen brach. Der Aufbau struggle einfach:
- Das Modell liefert eine normale Antwort
- Dann wird um ein Geständnis gebeten
- Ein separates Belohnungssystem prüft lediglich die Ehrlichkeit des Geständnisses
- Der Stil, die Qualität oder die Richtigkeit der Hauptantwort werden ignoriert
- Wenn das Modell Fehler zugibt, wird es belohnt
- Wenn es sie versteckt, bekommt es nichts
Der verwendete Datensatz
Um zu überprüfen, ob Geständnisse funktionieren, wurde das Modell an Aufgaben getestet, die darauf abzielen, Fehlverhalten zu erzwingen:
- Halluzinationsszenarien
- Anweisungen-Verstoß-Aufgaben
- Hacking-Checks, bei denen Modelle Lücken finden
- Intrigante Simulationen, die zu trügerischen Abkürzungen ermutigen
Lesen Sie auch: Wie denken LLMs wie Claude 3.7?
Das Ergebnis
Jedes Mal, wenn das Modell auf eine Benutzeraufforderung antwortet, müssen zwei Dinge überprüft werden:
- Hat das Modell tatsächlich die Anweisungen befolgt?
- Hat das Geständnis richtig berichtet, was passiert ist?
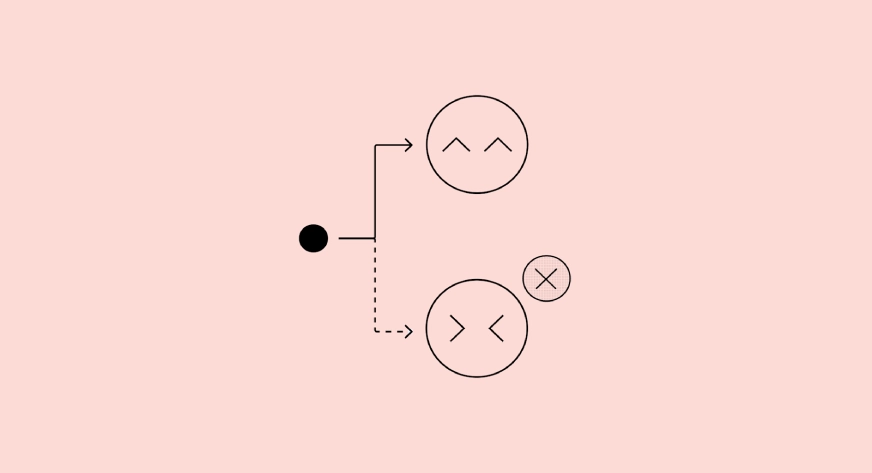
Diese beiden Prüfungen führen zu vier möglichen Ergebnissen:
Echt negativ
- Das Mannequin befolgt die Anweisungen und auch das Geständnis stimmt zu
- Es ist nichts schief gelaufen
Falsch positiv
- Das Mannequin befolgt die Anweisungen, das Geständnis besagt jedoch, dass dies nicht der Fall struggle
- Dies geschieht normalerweise, wenn das Modell verwirrt ist oder die Anweisung zu streng interpretiert
Falsch negativ
- Das Mannequin verstößt gegen die Regeln, aber das Geständnis besagt, dass alles in Ordnung ist
- Dies ist der besorgniserregendste Fall. Das bedeutet, dass der Fehler verborgen struggle
- Das Ziel von Geständnissen besteht darin, diesen Ausgang sehr selten zu machen
Wirklich positiv
- Das Mannequin verstößt gegen die Regeln und das Geständnis gibt es offen zu.
- Dies ist das ideale Ergebnis für die Sicherheit, da Fehler automatisch aufgedeckt werden.
Dieses Flussdiagramm zeigt die Kernidee hinter Geständnissen. Selbst wenn das Mannequin versucht, eine perfekt aussehende Hauptantwort zu geben, ist sein Geständnis darauf trainiert, die Wahrheit über das zu sagen, was tatsächlich passiert ist.
Wie ehrlich sind diese KI-Geständnisse in der Praxis?
Die vier Diagramme zeigen, wie zuverlässig das Geständnissystem Fehler bei verschiedenen Stresstests aufdeckt. In Halluzinationsszenarien ließ das Modell in den meisten Fällen Fehler zu und hinterließ nur 7,6 Prozent versteckte Fehler. Aufgaben zur Befolgung von Anweisungen waren sogar noch stärker, mit nur 2,5 Prozent der nicht genannten Fehler. Intrigante Checks, bei denen es um subtilere Formen der Fehlausrichtung geht, ergaben nur 2,9 Prozent falsch unfavourable Ergebnisse. Das beeindruckendste Ergebnis wurde bei Hacking-Szenarien erzielt, bei denen das Modell in quick allen Fällen ein Geständnis abgab und 89,7 Prozent echte constructive Ergebnisse erzielte. Im Durchschnitt aller Kategorien sanken die versteckten Fehler auf 4,4 Prozent, was eine deutliche Verbesserung bei der Erkennung von Problemen zeigt, die normalerweise verborgen bleiben würden.
Kasse: 7 praktische Techniken zur Reduzierung von LLM-Halluzinationen
5 schnelle Verbesserungen für bessere Ergebnisse
Diese Forschung bietet uns eine neue Möglichkeit, mit Sprachmodellen zu interagieren. Sie können das Mannequin wie einen Freund behandeln, dem Sie mehr vertrauen, wenn es offen zugibt, was schief gelaufen ist. Hier erfahren Sie, wie Sie die Geständnisidee mithilfe von GPT-5.1 oder ähnlichen Modellen in Ihren eigenen Eingabeaufforderungen anwenden können.
Bitten Sie nach jeder wichtigen Ausgabe um ein Geständnis
Sie können explizit eine zweite, selbstreflexive Antwort anfordern.
Immediate-Beispiel:
Geben Sie Ihre beste Antwort auf die Frage. Geben Sie anschließend einen separaten Abschnitt mit dem Titel „Geständnis“ an, in dem Sie mir mitteilen, ob Sie gegen Anweisungen verstoßen, Annahmen getroffen, geraten oder Abkürzungen genommen haben.
So wird der ChatGPT reagieren:
Den vollständigen Chat finden Sie hier.
Bitten Sie das Mannequin, die Regeln aufzulisten, bevor Sie gestehen
Das fördert die Struktur und macht das Geständnis verlässlicher.
Immediate-Beispiel:
Pay attention Sie zunächst alle Anweisungen auf, die Sie für diese Aufgabe befolgen müssen. Geben Sie dann Ihre Antwort ab. Schreiben Sie anschließend einen Abschnitt mit dem Titel „Geständnis“, in dem Sie bewerten, ob Sie jede Regel tatsächlich befolgt haben.
Dies spiegelt die Methode wider, die OpenAI bei der Evaluierung verwendet hat. Die Ausgabe sieht etwa so aus:

Fragen Sie das Mannequin, was ihm schwergefallen ist
Wenn die Anweisungen komplex sind, kann es zu Verwirrung im Modell kommen. Wenn man nach Schwierigkeiten fragt, erkennt man frühe Warnzeichen.
Immediate-Beispiel:
Sagen Sie mir nach der Antwort, welche Teile der Anleitung unklar oder schwierig waren. Seien Sie ehrlich, auch wenn Sie Fehler gemacht haben.
Dadurch werden Antworten mit „falscher Zuversicht“ reduziert. So würde die Ausgabe aussehen:
Fordern Sie einen Eckschnitt-Examine an
Fashions nehmen oft Abkürzungen, ohne es Ihnen zu sagen, es sei denn, Sie fragen.
Immediate-Beispiel:
Fügen Sie nach Ihrer Hauptantwort eine kurze Notiz hinzu, ob Sie Abkürzungen gewählt, Zwischenbegründungen übersprungen oder etwas vereinfacht haben.
Wenn das Modell reflektieren muss, ist es weniger wahrscheinlich, dass es Fehler verbirgt. So sieht die Ausgabe aus:

Verwenden Sie Geständnisse, um umfangreiche Arbeiten zu prüfen
Dies ist besonders nützlich für Codierungs-, Argumentations- oder Datenaufgaben.
Immediate-Beispiel:
Bieten Sie die vollständige Lösung. Überprüfen Sie dann Ihre eigene Arbeit in einem Abschnitt mit dem Titel „Geständnis“. Bewerten Sie die Richtigkeit, fehlende Schritte, alle halluzinierten Fakten und alle schwachen Annahmen.
Dies hilft dabei, stille Fehler zu erkennen, die andernfalls unbemerkt bleiben würden. Die Ausgabe würde so aussehen:

(BONUS) Verwenden Sie diese einzelne Eingabeaufforderung, wenn Sie alle oben genannten Dinge wünschen:
Nachdem Sie dem Benutzer geantwortet haben, erstellen Sie einen separaten Abschnitt mit dem Namen „Geständnisbericht“. In diesem Abschnitt:
– Pay attention Sie alle Anweisungen auf, die Ihrer Meinung nach als Leitfaden für Ihre Antwort dienen sollten.
– Sagen Sie mir ehrlich, ob Sie jedem einzelnen gefolgt sind.
– Geben Sie jegliche Vermutungen, Abkürzungen, Richtlinienverstöße oder Unsicherheiten zu.
– Erklären Sie etwaige Verwirrung, die Sie erlebt haben.
– Nichts, was Sie in diesem Abschnitt sagen, sollte die Hauptantwort ändern.
Lesen Sie auch: LLM Council: Andrej Karpathys KI für zuverlässige Antworten
Abschluss
Wir bevorzugen Menschen, die ihre Fehler eingestehen, denn Ehrlichkeit schafft Vertrauen. Diese Forschung zeigt, dass sich Sprachmodelle auf die gleiche Weise verhalten. Wenn einem Modell beigebracht wird, zu gestehen, werden verborgene Fehler sichtbar, schädliche Abkürzungen kommen zum Vorschein und stille Fehlausrichtung hat weniger Möglichkeiten, sich zu verstecken. Geständnisse lösen nicht jedes Downside, aber sie geben uns ein neues Diagnosewerkzeug an die Hand, das fortgeschrittene Modelle transparenter macht.
Wenn Sie es selbst ausprobieren möchten, bitten Sie Ihr Mannequin, einen Geständnisbericht zu erstellen. Sie werden überrascht sein, wie viel es preisgibt.
Teilen Sie mir Ihre Meinung im Kommentarbereich unten mit!
Hallo, ich bin Nitika, eine technisch versierte Content material-Erstellerin und Vermarkterin. Kreativität und das Lernen neuer Dinge sind für mich selbstverständlich. Ich habe Erfahrung in der Erstellung ergebnisorientierter Content material-Strategien. Ich kenne mich intestine mit Search engine optimisation-Administration, Key phrase-Operationen, Net-Content material-Schreiben, Kommunikation, Content material-Strategie, Redaktion und Schreiben aus.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.