Die manuelle Dateneingabe von Rechnungen ist eine langsame, fehleranfällige Aufgabe, die Unternehmen seit Jahrzehnten kämpfen. Kürzlich hat Uber Engineering enthüllt, wie sie diese Herausforderung mit ihrer „Texsen“ -Plattform, einem ausgeklügelten System für die Genai -Rechnungsverarbeitung, angepasst haben. Dieses System zeigt die Leistung der intelligenten Dokumentenverarbeitung und kombiniert optische Charaktererkennung (OCR) mit Großsprachmodellen (LLMs) für eine hoch genaue automatisierte Datenextraktion. Dieser fortgeschrittene Ansatz scheint für kleinere Projekte unerreichbar zu sein. Die Kernprinzipien sind jetzt für alle zugänglich. Dieser Leitfaden zeigt Ihnen, wie Sie den grundlegenden Workflow des Uber -Programs replizieren. Wir werden einfache, leistungsstarke Instruments verwenden, um ein System zu erstellen, das die Rechnungsdatenextraktion automatisiert.
Ubers „Texsen“ -System verstehen
Bevor wir unsere Model erstellen, ist es hilfreich zu verstehen, was sie inspiriert hat. Das Ziel von Uber struggle es, die Verarbeitung von Millionen von Dokumenten von Rechnungen bis hin zu Quittungen zu automatisieren. Ihre „Texten“ -Plattform, die in ihrem technischen Weblog beschrieben ist, ist eine robuste, mehrstufige Pipeline für diesen Zweck.
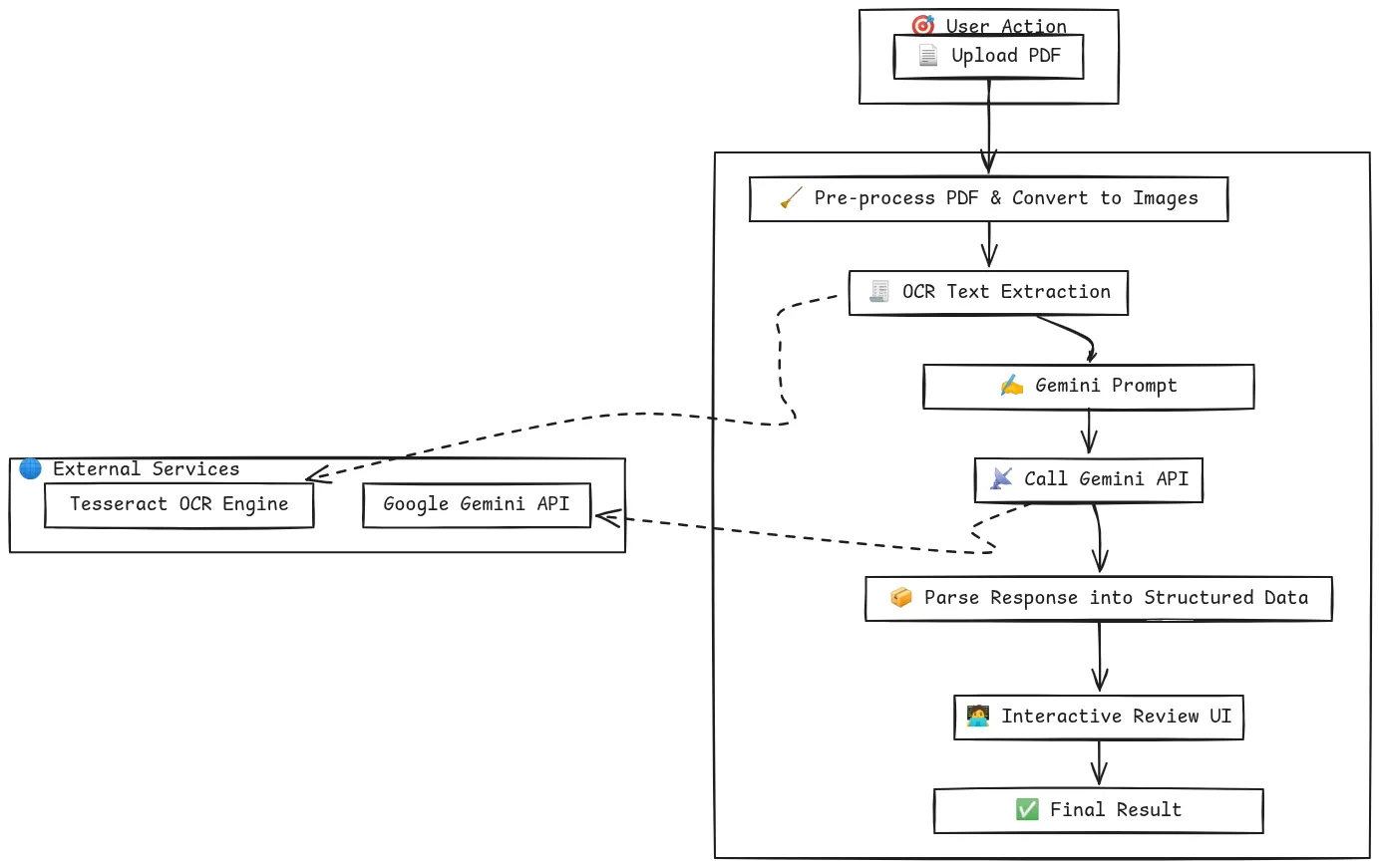
Die Abbildung zeigt die vollständige Dokumentverarbeitungspipeline. Für die Verarbeitung eines Dokuments ist die Vorverarbeitung in der Regel häufig vor dem Aufruf eines Llm.
Im Kern arbeitet das System in drei Hauptphasen:
- Digitalisierung (through OCR): Erstens nimmt das System ein Dokument wie ein PDF oder ein Bild einer Rechnung. Es verwendet eine erweiterte OCR-Engine, um das Dokument zu lesen und den gesamten visuellen Textual content in maschinenlesbare Textual content umzuwandeln. Dieser rohe Textual content ist die Grundlage für den nächsten Schritt.
- Intelligente Extraktion (über LLM): Der rohe Textual content aus dem OCR -Prozess ist oft unordentlich und unstrukturiert. Hier passiert die Genai -Magie. Uber füttert diesen Textual content an ein großes Sprachmodell. Das LLM wirkt wie ein Experte, der den Kontext einer Rechnung versteht. Es kann bestimmte Informationen identifizieren und extrahieren, z. B. die „Rechnungsnummer“, „Gesamtmenge“ und „Lieferantenname“ und sie in ein strukturiertes Format wie JSON organisieren.
- Überprüfung (Mensch-in-the-Schleife): Keine KI ist perfekt. Um eine 100% ige Genauigkeit zu gewährleisten, implementierte Uber ein AI-System des Menschen in der Schleife. Dieser Überprüfungsschritt zeigt das Originaldokument neben den AI-extrahierten Daten an einen menschlichen Operator. Der Bediener kann schnell bestätigen, dass die Daten korrekt sind oder bei Bedarf geringfügige Anpassungen vornehmen. Diese Suggestions -Schleife verbessert auch das Modell im Laufe der Zeit.
Diese Kombination von OCR mit KI und menschlicher Aufsicht macht ihr System sowohl effizient als auch zuverlässig. Die folgende Abbildung erläutert den Workflow von Texten in detaillierter Weise, wie in den oben genannten Punkten erläutert.
Unser Spielplan: den Kern -Workflow nachbilden
Unser Ziel ist es nicht, die gesamte Plattform von Ubers produzierter Produkte wieder aufzubauen. Stattdessen werden wir seine Kernintelligen auf vereinfachte und zugängliche Weise replizieren. Wir werden unsere bauen Genai Rechnungsverarbeitung POC in einem einzigen Google Colab -Pocket book.
Unser Plan folgt den gleichen logischen Schritten:
- Einnahmedokument: Wir erstellen eine einfache Möglichkeit, eine PDF -Rechnung direkt in unser Pocket book hochzuladen.
- OCR ausführen: Wir werden Tesseract, einen leistungsstarken Open-Supply-OCR-Motor, verwenden, um den gesamten Textual content aus der hochgeladenen Rechnung zu extrahieren.
- Entitäten mit KI extrahieren: Wir werden die verwenden Google Gemini API um die automatisierte Datenextraktion durchzuführen. Wir werden eine bestimmte Eingabeaufforderung erstellen, das Modell anzuweisen, die wichtigsten Felder herauszuziehen, die wir benötigen.
- Erstellen Sie eine Überprüfungs -Benutzeroberfläche: Wir werden eine einfache interaktive Schnittstelle verwenden ipywidgets Als unser KI-System mit menschlichem Menschen zu dienen und eine schnelle Validierung der extrahierten Daten zu ermöglichen.
Dieser Ansatz gibt uns eine leistungsstarke und kostengünstige Möglichkeit, eine intelligente Dokumentverarbeitung zu erreichen, ohne eine komplexe Infrastruktur zu benötigen.
Praktische Implementierung: POC Schritt für Schritt aufbauen
Beginnen wir mit dem Aufbau unseres Programs. Sie können diese Schritte in einem neuen Google Colab -Pocket book befolgen.
Schritt 1: Einrichten der Umgebung
Zunächst müssen wir die notwendigen Python -Bibliotheken installieren. Dieser Befehl installiert Pakete zum Umgang mit PDFs (Pymupdf), OCR leiten (Pytesseract), interagieren mit der Gemini -API und bauen Sie die Benutzeroberfläche (ipywidgets). Es installiert auch den Tesseract OCR -Motor selbst.
!pip set up -q -U google-generativeai PyMuPDF pytesseract pandas ipywidgets
!apt-get -qq set up tesseract-ocrSchritt 2: Konfigurieren der Google Gemini -API
Als nächstes müssen Sie Ihren Gemini -API -Schlüssel konfigurieren. Um Ihren Schlüssel sicher zu halten, verwenden wir den integrierten geheimen Supervisor von Colab.
- Holen Sie sich Ihren API -Schlüssel von Google AI Studio.
- Klicken Sie in Ihrem Colab -Notizbuch auf das Schlüsselsymbol in der linken Seitenleiste.
- Erstellen Sie ein neues Geheimnis mit dem Namen Gemini_api_key und fügen Sie Ihren Schlüssel als Wert ein.
Der folgende Code greift sicher auf Ihren Schlüssel zu und konfiguriert die API.
import google.generativeai as genai
from google.colab import userdata
import fitz # PyMuPDF
import pytesseract
from PIL import Picture
import pandas as pd
import ipywidgets as widgets
from ipywidgets import Structure
from IPython.show import show, clear_output
import json
import io
# Configure the Gemini API
attempt:
api_key = userdata.get(“GEMINI_API_KEY”)
genai.configure(api_key=api_key)
print("Gemini API configured efficiently.")
besides userdata.SecretNotFoundError:
print("ERROR: Secret 'GEMINI_API_KEY' not discovered. Please observe the directions to set it up.")Schritt 3: Hochladen und Vorverarbeitung des PDF
Dieser Code lädt eine PDF -Datei hoch, die eine Rechnungs -PDF ist. Wenn Sie ein PDF hochladen, wandelt es jede Seite in ein hochauflösendes Bild um, das das ideale Format für OCR ist.
import fitz # PyMuPDF
from PIL import Picture
import io
import os
invoice_images = ()
uploaded_file_name = "/content material/sample-invoice.pdf" # Substitute with the precise path to your PDF file
# Make sure the file exists (optionally available however advisable)
if not os.path.exists(uploaded_file_name):
print(f"ERROR: File not discovered at '{uploaded_file_name}'. Please replace the file path.")
else:
print(f"Processing '{uploaded_file_name}'...")
# Convert PDF to photographs
doc = fitz.open(uploaded_file_name)
for page_num in vary(len(doc)):
web page = doc.load_page(page_num)
pix = web page.get_pixmap(dpi=300) # Increased DPI for higher OCR
img = Picture.open(io.BytesIO(pix.tobytes()))
invoice_images.append(img)
doc.shut()
print(f"Efficiently transformed {len(invoice_images)} web page(s) to photographs.")
# Show the primary web page as a preview
if invoice_images:
print("n--- Bill Preview (First Web page) ---")
show(invoice_images(0).resize((600, 800)))Ausgabe:

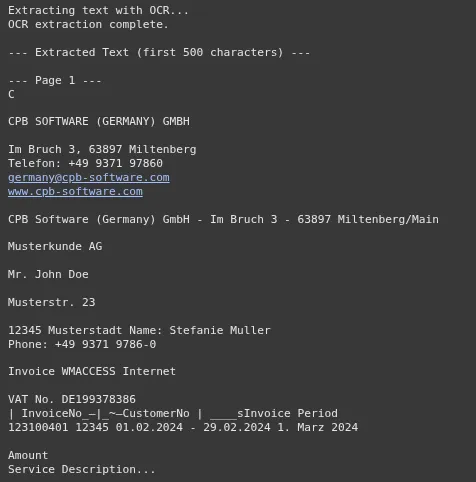
Jetzt führen wir den OCR -Prozess auf den gerade erstellten Bildern aus. Der Textual content von allen Seiten wird zu einer einzigen Zeichenfolge kombiniert. Dies ist der Kontext, den wir an die senden werden Zwillinge Modell. Dieser Schritt ist ein entscheidender Bestandteil der OCR mit KI -Workflow.
full_invoice_text = ""
if not invoice_images:
print("Please add a PDF bill within the step above first.")
else:
print("Extracting textual content with OCR...")
for i, img in enumerate(invoice_images):
textual content = pytesseract.image_to_string(img)
full_invoice_text += f"n--- Web page {i+1} ---n{textual content}"
print("OCR extraction full.")
print("n--- Extracted Textual content (first 500 characters) ---")
print(full_invoice_text(:500) + "...")Ausgabe:
Hier erfolgt die Genai -Rechnungsverarbeitung. Wir erstellen eine detaillierte Eingabeaufforderung, die dem Gemini -Modell seine Rolle mitteilt. Wir wenden es an, bestimmte Felder zu extrahieren und das Ergebnis in ein sauberes JSON -Format zurückzugeben. Nach JSON zu fragen ist eine leistungsstarke Technik, mit der die Ausgabe des Modells strukturiert und einfach zu arbeiten.
extracted_data = {}
if not full_invoice_text.strip():
print("Can't proceed. The extracted textual content is empty. Please verify the PDF high quality.")
else:
# Instantiate the Gemini Professional mannequin
mannequin = genai.GenerativeModel('gemini-2.5-pro')
# Outline the fields you wish to extract
fields_to_extract = "Bill Quantity, Bill Date, Due Date, Provider Title, Provider Tackle, Buyer Title, Buyer Tackle, Whole Quantity, Tax Quantity"
# Create the detailed immediate
immediate = f"""
You might be an professional in bill information extraction.
Your job is to investigate the supplied OCR textual content from an bill and extract the next fields: {fields_to_extract}.
Comply with these guidelines strictly:
1. Return the output as a single, clear JSON object.
2. The keys of the JSON object should be precisely the sphere names supplied.
3. If a discipline can't be discovered within the textual content, its worth within the JSON ought to be `null`.
4. Don't embrace any explanatory textual content, feedback, or markdown formatting (like ```json) in your response. Solely the JSON object is allowed.
Right here is the bill textual content:
---
{full_invoice_text}
---
"""
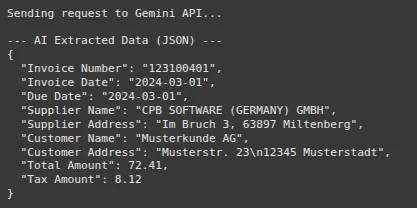
print("Sending request to Gemini API...")
attempt:
# Name the API
response = mannequin.generate_content(immediate)
# Robustly parse the JSON response
response_text = response.textual content.strip()
# Clear potential markdown formatting
if response_text.startswith('```json'):
response_text = response_text(7:-3).strip()
extracted_data = json.masses(response_text)
print("n--- AI Extracted Knowledge (JSON) ---")
print(json.dumps(extracted_data, indent=2))
besides json.JSONDecodeError:
print("n--- ERROR ---")
print("Didn't decode the mannequin's response into JSON.")
print("Mannequin's Uncooked Response:", response.textual content)
besides Exception as e:
print(f"nAn surprising error occurred: {e}")
print("Mannequin's Uncooked Response (if accessible):", getattr(response, 'textual content', 'N/A'))Ausgabe:
Schritt 6: Bauen Sie die UI der Menschen in der Schleife (HITL)
Schließlich haben wir die Verifizierungsschnittstelle erstellt. Dieser Code zeigt das Rechnungsbild hyperlinks an und erstellt auf der rechten Seite eine bearbeitbare Kind, die mit den Daten von Gemini vorgefüllt wird. Der Benutzer kann die Informationen schnell überprüfen, die erforderlichen Änderungen vornehmen und bestätigen.
# UI Widgets
text_widgets = {}
if not extracted_data:
print("No information was extracted by the AI. Can't construct verification UI.")
else:
form_items = ()
# Create a textual content widget for every extracted discipline
for key, worth in extracted_data.objects():
text_widgets(key) = widgets.Textual content(
worth=str(worth) if worth will not be None else "",
description=key.change('_', ' ').title() + ':',
type={'description_width': 'preliminary'},
format=Structure(width="95%")
)
form_items.append(text_widgets(key))
# The shape container
type = widgets.VBox(form_items, format=Structure(padding='10px'))
# Picture container
if invoice_images:
img_byte_arr = io.BytesIO()
invoice_images(0).save(img_byte_arr, format="PNG")
image_widget = widgets.Picture(
worth=img_byte_arr.getvalue(),
format="png",
width=500
)
image_box = widgets.HBox((image_widget), format=Structure(justify_content="middle"))
else:
image_box = widgets.HTML("No picture to show.")
# Affirmation button
confirm_button = widgets.Button(description="Verify and Save", button_style="success")
output_area = widgets.Output()
def on_confirm_button_clicked(b):
with output_area:
clear_output()
final_data = {key: widget.worth for key, widget in text_widgets.objects()}
# Create a pandas DataFrame
df = pd.DataFrame((final_data))
df('Supply File') = uploaded_file_name
print("--- Verified and Finalized Knowledge ---")
show(df)
# Now you can save this DataFrame to CSV, and so on.
df.to_csv('verified_invoice.csv', index=False)
print("nData saved to 'verified_invoice.csv'")
confirm_button.on_click(on_confirm_button_clicked)
# Closing UI Structure
ui = widgets.HBox((
widgets.VBox((widgets.HTML("<b>Bill Picture</b>"), image_box)),
widgets.VBox((
widgets.HTML("<b>Confirm Extracted Knowledge</b>"),
type,
widgets.HBox((confirm_button), format=Structure(justify_content="flex-end")),
output_area
), format=Structure(flex='1'))
))
print("--- Human-in-the-Loop (HITL) Verification ---")
print("Evaluation the information on the precise. Make any corrections and click on 'Verify and Save'.")
show(ui)Ausgabe:
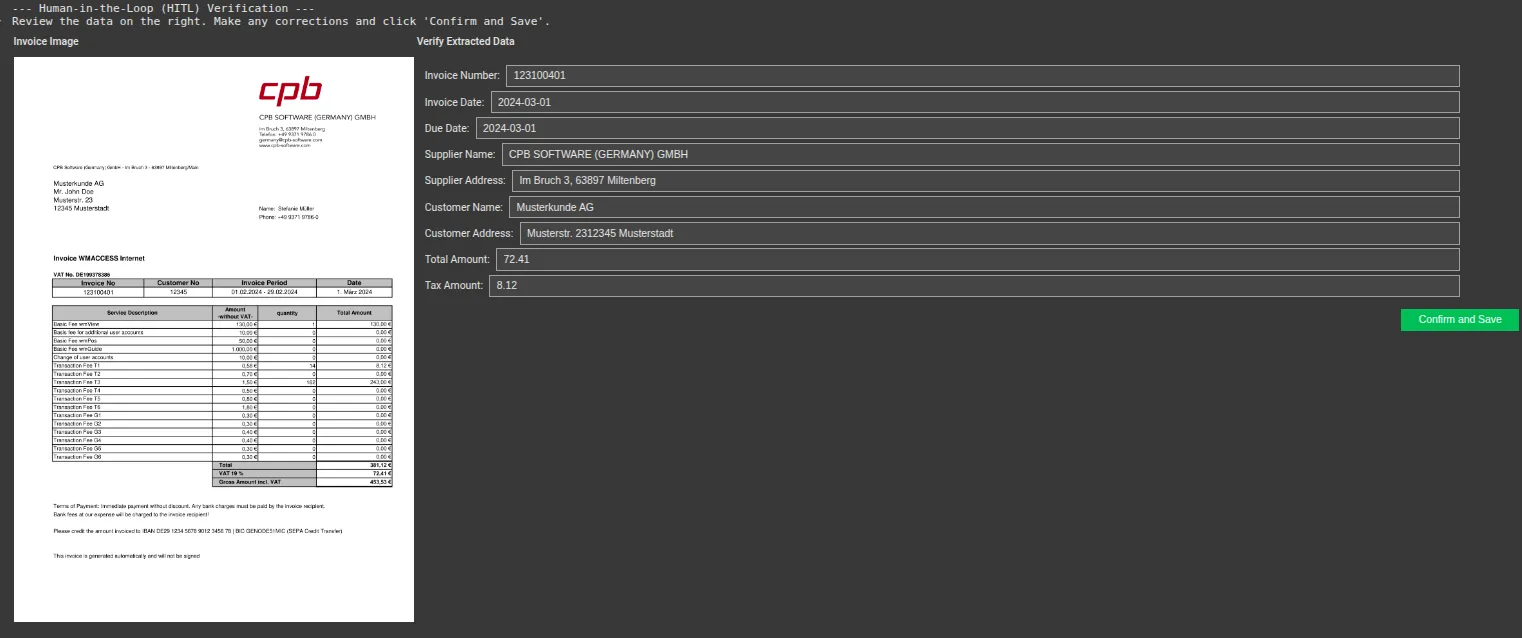
Ändern Sie einige Werte und speichern Sie dann.
Ausgabe:
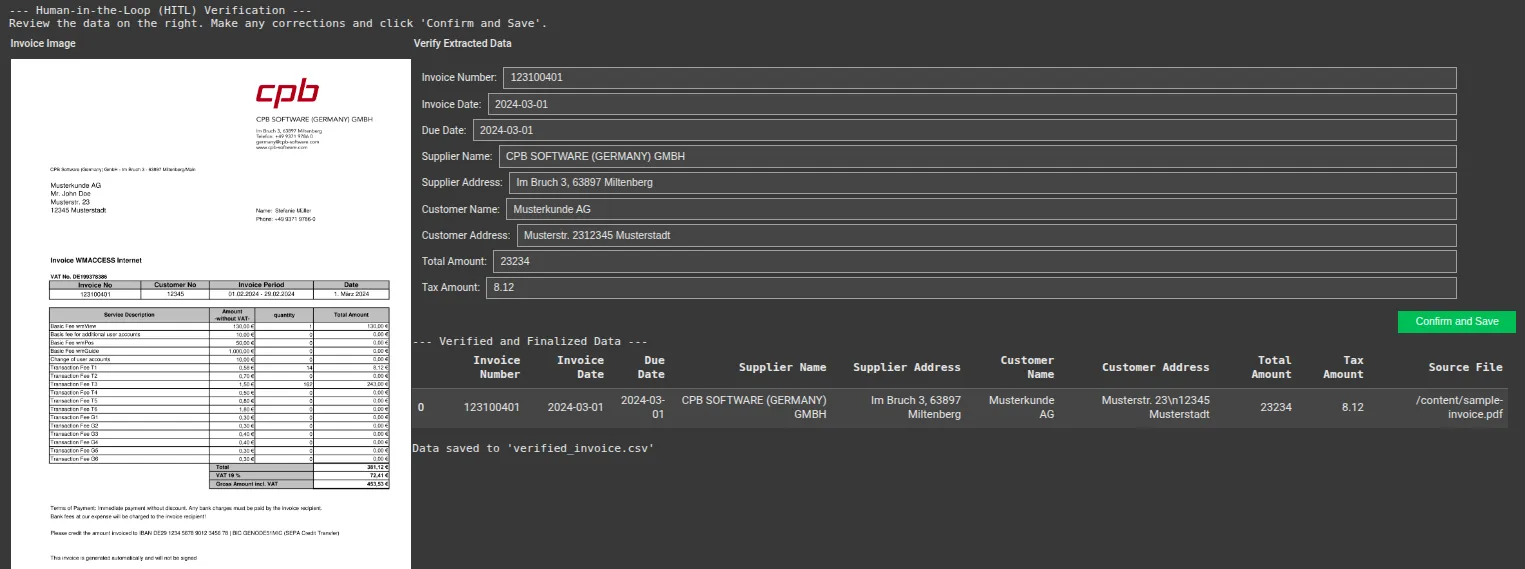
Sie können hier auf den vollständigen Code zugreifen: GithubAnwesend Colab
Abschluss
Dieser POC zeigt erfolgreich, dass die Kernlogik hinter einem ausgefeilten System wie Ubers „Texsen“ reproduzierbar ist. Durch die Kombination von Open-Supply-OCR mit einem leistungsstarken LLM wie Googles Gemini können Sie ein effektives System für die Verarbeitung von Genai-Rechnungen erstellen. Dieser Ansatz zur Verarbeitung intelligenter Dokumente reduziert die manuelle Anstrengung dramatisch und verbessert die Genauigkeit. Die Hinzufügung einer einfachen KI-Schnittstelle zwischen Menschen in der Schleife stellt sicher, dass die endgültigen Daten vertrauenswürdig sind.
Fühlen Sie sich frei, diese Stiftung zu erweitern, indem Sie weitere Felder hinzufügen, die Validierung verbessern und in größere Workflows integrieren.
Häufig gestellte Fragen
A. Die Genauigkeit ist sehr hoch, insbesondere bei klaren Rechnungen. Das Gemini-Modell kann den Kontext hervorragend verstehen, aber die Qualität kann abnehmen, wenn der OCR-Textual content aufgrund eines minderwertigen Scans schlecht ist.
A. Ja. Im Gegensatz zu vorlagenbasierten Systemen versteht der LLM Sprache und Kontext. Auf diese Weise kann es unabhängig von ihrer Place auf der Seite Felder wie „Rechnungsnummer“ oder „Gesamt“ finden.
A. Die Kosten sind minimal. Tesseract und die anderen Bibliotheken sind kostenlos. Sie zahlen nur für Ihre Verwendung der Google Gemini -API, die für diese Artwork von Aufgabe sehr erschwinglich ist.
A. Absolut. Fügen Sie einfach die neuen Feldnamen der Fields_to_extract -String in Schritt 5 hinzu, und das Gemini -Modell wird versuchen, sie für Sie zu finden.
A. Stellen Sie sicher, dass Ihre Quelle PDFs hochauflösend sind. Im Code setzen wir DPI = 300 Beim Konvertieren des PDF in ein Bild, was ein guter Normal für OCR ist. Höheres DPI kann manchmal bessere Ergebnisse für verschwommene Dokumente erzielen.
Harsh Mishra ist ein KI/ML -Ingenieur, der mehr Zeit damit verbringt, mit großen Sprachmodellen zu sprechen als mit tatsächlichen Menschen. Leidenschaft über Genai, NLP und Maschinen schlauer (damit sie ihn noch nicht ersetzen). Wenn er Fashions nicht optimiert, optimiert er wahrscheinlich seine Kaffeeaufnahme. 🚀☕
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.