Nvidia sagte Nvidia DGX B200 Knoten mit acht Nvidia Blackwell -GPUs erreichte mehr als 1.000 Token professional Sekunde (TPS) professional Benutzer am 400-Milliarden-Parameter-Lama 4-Maverick-Modell.
Nvidia sagte, das Modell sei das größte und leistungsfähigste in der Lama 4 KI -Benchmarking -Service Künstliche Analyse.
Nvidia fügte hinzu, dass Blackwell mit ihrer Konfiguration mit höchster Durchsatz 72.000 TPS/Server erreicht.
Das Unternehmen sagte, es habe Software program -Optimierungen verwendet Tensorrt-Llm und trainierte ein spekulatives Dekodierungsentwurfsmodell mit Verwendung Eagle-3-Techniken. Laut Nvidia hat Nvidia diese Ansätze kombiniert und einen 4-fach-Geschwindigkeitsgrad im Vergleich zur besten Blackwell-Grundlinie erreicht.
„Die nachstehend beschriebenen Optimierungen erhöhen die Leistung signifikant und erhalten Sie gleichzeitig die Reaktionsgenauigkeit“, sagte Nvidia in einem gestern veröffentlichten Weblog. „Wir haben FP8 -Datentypen für GEMMS, Mischung von Experten (MOE) und Aufmerksamkeitsvorgänge eingesetzt Blackwell Tensor Core Expertise. Genauigkeit bei Verwendung des FP8 -Datenformats entspricht dem von Künstliche Analyse BF16 über viele Metriken hinwegDie meisten generativen KI -Anwendungskontexte erfordern ein Gleichgewicht zwischen Durchsatz und Latenz, um sicherzustellen, dass viele Kunden gleichzeitig eine „intestine genug“ Erfahrung genießen können. Bei kritischen Anwendungen, die wichtige Entscheidungen bei Geschwindigkeit treffen müssen, minimieren Sie die Latenz für einen einzelnen Consumer. Wenn der TPS/Benutzerakte zeigt, wird die beste Wahl. dieser Beitrag).
Im Folgenden finden Sie einen Überblick über die Kernel-Optimierungen und -Fusionen (gekennzeichnet in rotgeschmachten Quadraten) Nvidia, die während der Inferenz angewendet werden. NVIDIA implementierte mehrere GEMM-Körner mit niedriger Latenz und verwendete verschiedene Kernelfusionen (wie FC13 + Swiglu, FC_QKV + ATTN_SCALING und AllReduce + RMSNorm), um sicherzustellen, dass Blackwell im Szenario der Mindestlatenz auszeichnet.
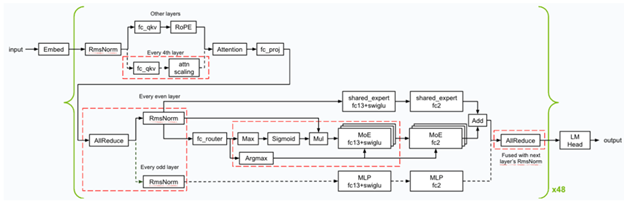
Überblick über die Kernel -Optimierungen und -Fusionen für Lama 4 Maverick
Nvidia optimierte die Cuda -Kerne für Gemms-, MOE- und Aufmerksamkeitsvorgänge, um die beste Leistung für den Blackwell -GPUs zu erzielen.
- Genutzt räumliche Partitionierung (Auch als Warp -Spezialisierung bezeichnet) und entwarf die GEMM -Kernel, um Daten aus dem Speicher effizient zu laden, um die Nutzung der enormen Speicherbandbreite zu maximieren, die das NVIDIA -DGX -System insgesamt bietet – 64TB/S HBM3E -Bandbreite.
- Mischte das Edelsteingewicht in a regelt Format, um ein besseres Structure beim Laden des Berechnungsergebnisses von zu ermöglichen Tensor -Speicher Nach den Matrix-Multiplikationsberechnungen unter Verwendung von Tensor Cores der fünften Era von Blackwell.
- Optimierte die Leistung der Aufmerksamkeitskerne, indem die Berechnungen entlang der Abmessung der Sequenzlängen der Ok- und V -Tensoren geteilt wurden, sodass Berechnungen parallel über mehrere CUDA -Fadenblöcke hinweg ausgeführt werden können. Darüber hinaus verwendete Nvidia verteilter gemeinsamer Speicher Um Resulate effizient über die Fadenblöcke im selben Thread -Block -Cluster zu reduzieren, ohne auf den globalen Speicher zugreifen zu müssen.
Der Relaxation des Blogs kann sein Hier gefunden.