

Bild vom Autor
# Einführung
Wenn Sie sich für eine Stelle bei Meta (ehemals Fb), Apple, Amazon, Netflix oder Alphabet (Google) – zusammen bekannt als FAANG – bewerben, wird in Vorstellungsgesprächen selten geprüft, ob Sie Lehrbuchdefinitionen aufsagen können. Stattdessen möchten Interviewer sehen, ob Sie Daten kritisch analysieren und ob Sie eine schlechte Analyse erkennen würden, bevor sie in die Produktion geht. Statistische Fallen sind eine der zuverlässigsten Methoden, dies zu testen.

Diese Fallstricke spiegeln die Artwork von Entscheidungen wider, mit denen Analysten täglich konfrontiert sind: eine Dashboard-Zahl, die intestine aussieht, aber tatsächlich irreführend ist, oder ein Experimentergebnis, das umsetzbar erscheint, aber einen strukturellen Fehler enthält. Der Interviewer kennt die Antwort bereits. Was sie beobachten, ist Ihr Denkprozess, einschließlich der Frage, ob Sie die richtigen Fragen stellen, fehlende Informationen bemerken und auf eine Zahl zurückgreifen, die auf den ersten Blick intestine aussieht. Kandidaten stolpern immer wieder über diese Fallen, selbst wenn sie über ausgeprägte mathematische Kenntnisse verfügen.
Wir werden fünf der häufigsten Fallen untersuchen.
# Simpsons Paradoxon verstehen
Ziel dieser Falle ist es, Menschen zu fangen, die aggregierten Zahlen bedingungslos vertrauen.
Das Simpson-Paradoxon tritt auf, wenn ein Development in verschiedenen Datengruppen auftritt, beim Kombinieren dieser Gruppen jedoch verschwindet oder sich umkehrt. Das klassische Beispiel sind die Zulassungsdaten der UC Berkeley aus dem Jahr 1973: Insgesamt begünstigten die Zulassungsquoten Männer, doch nach Abteilungen aufgeschlüsselt hatten Frauen gleiche oder bessere Zulassungsquoten. Die Gesamtzahl struggle irreführend, da sich Frauen in wettbewerbsintensiveren Abteilungen bewarben.
Das Paradoxon ist immer dann unvermeidlich, wenn Gruppen unterschiedliche Größen und unterschiedliche Basistarife haben. Das zu verstehen, ist es, was eine oberflächliche Antwort von einer tiefgründigen Antwort unterscheiden kann.
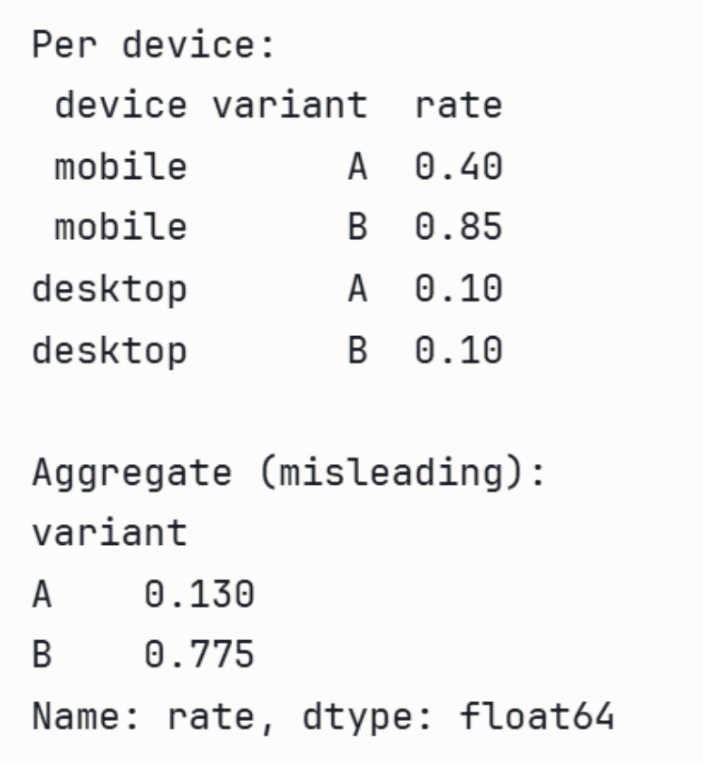
In Interviews könnte eine Frage so aussehen: „Wir haben einen A/B-Check durchgeführt. Insgesamt hatte Variante B eine höhere Conversion-Fee. Wenn wir sie jedoch nach Gerätetyp aufschlüsseln, schnitt Variante A sowohl auf Mobilgeräten als auch auf Desktops besser ab. Was passiert?“ Ein starker Kandidat bezieht sich auf das Simpson-Paradoxon, klärt seine Ursache (die Gruppenanteile unterscheiden sich zwischen den beiden Varianten) und bittet darum, die Aufschlüsselung zu sehen, anstatt der Gesamtzahl zu vertrauen.
Interviewer prüfen damit, ob Sie instinktiv nach Untergruppenverteilungen fragen. Wenn Sie nur die Gesamtzahl melden, haben Sie Punkte verloren.
// Demonstrieren mit A/B-Testdaten
In der folgenden Demonstration mit Pandaskönnen wir sehen, wie die Gesamtrate irreführend sein kann.
import pandas as pd
# A wins on each units individually, however B wins in mixture
# as a result of B will get most visitors from higher-converting cell.
knowledge = pd.DataFrame({
'gadget': ('cell', 'cell', 'desktop', 'desktop'),
'variant': ('A', 'B', 'A', 'B'),
'converts': (40, 765, 90, 10),
'guests': (100, 900, 900, 100),
})
knowledge('price') = knowledge('converts') / knowledge('guests')
print('Per gadget:')
print(knowledge(('gadget', 'variant', 'price')).to_string(index=False))
print('nAggregate (deceptive):')
agg = knowledge.groupby('variant')(('converts', 'guests')).sum()
agg('price') = agg('converts') / agg('guests')
print(agg('price'))Ausgabe:
# Identifizierung von Auswahlverzerrungen
Mit diesem Check können Interviewer beurteilen, ob Sie vor der Analyse darüber nachdenken, woher die Daten stammen.
Eine Selektionsverzerrung entsteht, wenn die Ihnen vorliegenden Daten nicht repräsentativ für die Inhabitants sind, die Sie verstehen möchten. Da die Verzerrung im Datenerhebungsprozess und nicht in der Analyse liegt, kann sie leicht übersehen werden.
Betrachten Sie diese möglichen Rahmen für Vorstellungsgespräche:
- Wir haben eine Umfrage unter unseren Nutzern analysiert und festgestellt, dass 80 % mit dem Produkt zufrieden sind. Sagt uns das, dass unser Produkt intestine ist? Ein guter Kandidat würde darauf hinweisen, dass zufriedene Benutzer eher auf Umfragen antworten. Der Wert von 80 % übertreibt wahrscheinlich die Zufriedenheit, da sich unzufriedene Benutzer höchstwahrscheinlich gegen eine Teilnahme entschieden haben.
- Wir untersuchten Kunden, die das Unternehmen im letzten Quartal verließen, und stellten fest, dass sie vor allem schlechte Engagement-Werte aufwiesen. Sollte unser Augenmerk auf dem Engagement liegen, um die Abwanderung zu reduzieren? Das Downside hierbei ist, dass Sie nur Engagement-Daten für abgewanderte Benutzer haben. Sie verfügen über keine Engagement-Daten für Benutzer, die geblieben sind, sodass es unmöglich ist zu wissen, ob ein geringes Engagement tatsächlich eine Abwanderung vorhersagt oder ob es sich lediglich um ein Merkmal abgewanderter Benutzer im Allgemeinen handelt.
Eine verwandte, wissenswerte Variante ist der Survivorship Bias: Man beobachtet nur die Ergebnisse, die es durch einen Filter geschafft haben. Wenn Sie nur Daten erfolgreicher Produkte verwenden, um zu analysieren, warum sie erfolgreich waren, ignorieren Sie diejenigen, die aus denselben Gründen gescheitert sind, die Sie als Stärken betrachten.
// Simulation der Nichtbeantwortung einer Umfrage
Wir können simulieren, wie der Non-Response-Bias die Ergebnisse verzerrt NumPy.
import numpy as np
import pandas as pd
np.random.seed(42)
# Simulate customers the place happy customers usually tend to reply
satisfaction = np.random.alternative((0, 1), measurement=1000, p=(0.5, 0.5))
# Response likelihood: 80% for happy, 20% for unhappy
response_prob = np.the place(satisfaction == 1, 0.8, 0.2)
responded = np.random.rand(1000) < response_prob
print(f"True satisfaction price: {satisfaction.imply():.2%}")
print(f"Survey satisfaction price: {satisfaction(responded).imply():.2%}")Ausgabe:

Interviewer verwenden Auswahlfragen, um zu sehen, ob Sie „was die Daten zeigen“ und „was über Benutzer wahr ist“ unterscheiden können.
# P-Hacking verhindern
P-Hacking (auch Knowledge Dredging genannt) tritt auf, wenn Sie viele Checks ausführen und nur diejenigen mit ( p < 0,05 ) melden. Das Downside besteht darin, dass ( p )-Werte nur für einzelne Checks gedacht sind. Ein falsch positives Ergebnis wäre allein durch Zufall zu erwarten, wenn 20 Checks mit einem Signifikanzniveau von 5 % durchgeführt würden. Die Falscherkennungsrate wird durch die Suche nach einem signifikanten Ergebnis erhöht. Ein Interviewer könnte Sie Folgendes fragen: „Im letzten Quartal haben wir fünfzehn Characteristic-Experimente durchgeführt. Bei ( p < 0,05 ) erwiesen sich drei als signifikant. Müssen alle drei versendet werden?“ Eine schwache Antwort sagt ja. Eine aussagekräftige Antwort würde zunächst fragen, wie die Hypothesen vor der Durchführung der Checks lauteten, ob der Signifikanzschwellenwert im Voraus festgelegt wurde und ob das Group mehrere Vergleiche korrigiert hat. Im Anschluss geht es oft darum, wie Sie Experimente gestalten würden, um dies zu vermeiden. Die vorherige Registrierung von Hypothesen vor der Datenerfassung ist die direkteste Lösung, da dadurch die Möglichkeit entfällt, im Nachhinein zu entscheiden, welche Checks „echt“ waren.
// Beobachten Sie, wie sich Fehlalarme häufen
Wir können beobachten, wie durch Zufall Fehlalarme entstehen SciPy.
import numpy as np
from scipy import stats
np.random.seed(0)
# 20 A/B exams the place the null speculation is TRUE (no actual impact)
n_tests, alpha = 20, 0.05
false_positives = 0
for _ in vary(n_tests):
a = np.random.regular(0, 1, 1000)
b = np.random.regular(0, 1, 1000) # equivalent distribution!
if stats.ttest_ind(a, b).pvalue < alpha:
false_positives += 1
print(f'Checks run: {n_tests}')
print(f'False positives (p<0.05): {false_positives}')
print(f'Anticipated by probability alone: {n_tests * alpha:.0f}')Ausgabe:

Selbst ohne tatsächliche Wirkung löscht ~1 von 20 Checks zufällig ( p < 0,05 ). Wenn ein Group 15 Experimente durchführt und nur die signifikanten Experimente meldet, handelt es sich bei diesen Ergebnissen höchstwahrscheinlich um Rauschen. Ebenso wichtig ist es, die explorative Analyse als eine Type der Hypothesengenerierung und nicht als Bestätigung zu behandeln. Bevor jemand auf der Grundlage eines Explorationsergebnisses Maßnahmen ergreift, ist ein bestätigendes Experiment erforderlich.
# Verwalten mehrerer Checks
Dieser Check ist eng mit P-Hacking verbunden, es lohnt sich jedoch, ihn für sich genommen zu verstehen.
Das Downside der Mehrfachtests ist ein formalstatistisches Downside: Wenn Sie viele Hypothesentests gleichzeitig durchführen, steigt die Wahrscheinlichkeit, dass mindestens ein falsch positives Ergebnis vorliegt, schnell. Auch wenn die Behandlung keine Wirkung zeigt, sollten Sie mit etwa fünf falsch positiven Ergebnissen rechnen, wenn Sie 100 Metriken in einem A/B-Check testen und alles mit ( p < 0,05 ) als signifikant deklarieren. Die Korrekturen hierfür sind bekannt: Bonferroni-Korrektur (Dividieren Sie Alpha durch die Anzahl der Checks) und Benjamini-Hochberg (steuert die Falscherkennungsrate und nicht die familienbezogene Fehlerrate).
Bonferroni ist ein konservativer Ansatz: Wenn Sie beispielsweise 50 Metriken testen, sinkt Ihr Schwellenwert professional Check auf 0,001, wodurch es schwieriger wird, echte Effekte zu erkennen. Benjamini-Hochberg ist besser geeignet, wenn Sie bereit sind, einige falsche Entdeckungen im Austausch für mehr statistische Aussagekraft zu akzeptieren.
In Interviews kommt dies zur Sprache, wenn es darum geht, wie ein Unternehmen Experimentkennzahlen verfolgt. Eine Frage könnte lauten: „Wir überwachen 50 Messwerte professional Experiment. Wie entscheiden Sie, welche davon wichtig sind?“ In einer soliden Antwort wird die Vorabfestlegung primärer Metriken vor der Durchführung des Experiments und die Behandlung sekundärer Metriken als explorativ erörtert, wobei gleichzeitig das Downside mehrerer Checks anerkannt wird.
Interviewer versuchen herauszufinden, ob Sie sich darüber im Klaren sind, dass die Durchführung weiterer Checks eher zu mehr Lärm als zu mehr Informationen führt.
# Umgang mit Störvariablen
Diese Falle fängt Kandidaten, die Korrelation als Kausalität betrachten, ohne zu fragen, was die Beziehung sonst noch erklären könnte.
A Störvariable beeinflusst sowohl die unabhängigen als auch die abhängigen Variablen und erzeugt die Phantasm einer direkten Beziehung, wo keine besteht.
Das klassische Beispiel: Eisverkäufe und Ertrinkungsraten korrelieren miteinander, aber der Störfaktor ist die Sommerhitze; beide steigen in warmen Monaten. Auf dieser Korrelation zu reagieren, ohne den Störfaktor zu berücksichtigen, führt zu schlechten Entscheidungen.
Besonders gefährlich ist die Verwechslung bei Beobachtungsdaten. Im Gegensatz zu einem randomisierten Experiment verteilen Beobachtungsdaten potenzielle Störfaktoren nicht gleichmäßig zwischen den Gruppen, sodass die Unterschiede, die Sie sehen, möglicherweise überhaupt nicht durch die Variable verursacht werden, die Sie untersuchen.
Eine häufige Formulierung in Interviews lautet: „Wir haben festgestellt, dass Benutzer, die unsere cell App häufiger nutzen, tendenziell deutlich höhere Einnahmen erzielen. Sollten wir Push-Benachrichtigungen senden, um die Anzahl der App-Öffnungen zu erhöhen?“ Ein schwacher Kandidat sagt ja. Eine starke Frage stellt zunächst die Frage, welche Artwork von Benutzer die App häufig öffnet: wahrscheinlich die engagiertesten Benutzer mit dem höchsten Wert.
Engagement steigert sowohl das Öffnen von Apps als auch die Ausgaben. Die App-Öffnungen verursachen keine Einnahmen; Sie sind ein Symptom derselben zugrunde liegenden Benutzerqualität.
Interviewer verwenden Confounding, um zu testen, ob Sie Korrelation von Kausalität unterscheiden, bevor Sie Schlussfolgerungen ziehen, und ob Sie auf randomisierte Experimente oder Propensity-Rating-Matching drängen würden, bevor Sie Maßnahmen empfehlen.
// Simulation einer verwirrten Beziehung
import numpy as np
import pandas as pd
np.random.seed(42)
n = 1000
# Confounder: consumer high quality (0 = low, 1 = excessive)
user_quality = np.random.binomial(1, 0.5, n)
# App opens pushed by consumer high quality, not unbiased
app_opens = user_quality * 5 + np.random.regular(0, 1, n)
# Income additionally pushed by consumer high quality, not app opens
income = user_quality * 100 + np.random.regular(0, 10, n)
df = pd.DataFrame({
'user_quality': user_quality,
'app_opens': app_opens,
'income': income
})
# Naive correlation appears sturdy — deceptive
naive_corr = df('app_opens').corr(df('income'))
# Inside-group correlation (controlling for confounder) is close to zero
corr_low = df(df('user_quality')==0)('app_opens').corr(df(df('user_quality')==0)('income'))
corr_high = df(df('user_quality')==1)('app_opens').corr(df(df('user_quality')==1)('income'))
print(f"Naive correlation (app opens vs income): {naive_corr:.2f}")
print(f"Correlation controlling for consumer high quality:")
print(f" Low-quality customers: {corr_low:.2f}")
print(f" Excessive-quality customers: {corr_high:.2f}")Ausgabe:
Naive correlation (app opens vs income): 0.91
Correlation controlling for consumer high quality:
Low-quality customers: 0.03
Excessive-quality customers: -0.07Die naive Zahl scheint ein starkes Sign zu sein. Sobald Sie den Störfaktor kontrollieren, verschwindet er vollständig. Interviewer, die sehen, wie ein Kandidat diese Artwork der geschichteten Prüfung durchführt (anstatt die Gesamtkorrelation zu akzeptieren), wissen, dass sie mit jemandem sprechen, der keine fehlerhafte Empfehlung abgibt.
# Zusammenfassung
Alle fünf dieser Fallen haben eines gemeinsam: Sie erfordern, dass Sie langsamer werden und die Daten hinterfragen, bevor Sie akzeptieren, was die Zahlen auf den ersten Blick zu zeigen scheinen. Interviewer verwenden diese Szenarien speziell, weil Ihr erster Instinkt oft falsch ist und die Tiefe Ihrer Antwort nach diesem ersten Instinkt das ist, was einen Kandidaten, der unabhängig arbeiten kann, von einem Kandidaten unterscheidet, der bei jeder Analyse eine Anleitung benötigt.

Keine dieser Ideen ist schwer zu verstehen, und Interviewer fragen nach ihnen, da es sich um typische Fehlermodi in der realen Datenarbeit handelt. Der Kandidat, der das Simpson-Paradoxon in einer Produktmetrik erkennt, einen Auswahlfehler in einer Umfrage feststellt oder sich fragt, ob ein Experimentergebnis mehrere Vergleiche überstanden hat, ist derjenige, der weniger schlechte Entscheidungen treffen wird.
Wenn Sie hineingehen FAANG Wenn Sie in Vorstellungsgesprächen den Reflex haben, die folgenden Fragen zu stellen, sind Sie den meisten Kandidaten bereits voraus:
- Wie wurden diese Daten erhoben?
- Gibt es Untergruppen, die eine andere Geschichte erzählen?
- Wie viele Checks haben zu diesem Ergebnis beigetragen?
Diese Gewohnheiten helfen nicht nur bei Vorstellungsgesprächen, sondern können auch verhindern, dass Fehlentscheidungen in die Produktion gelangen.
Nate Rosidi ist Datenwissenschaftler und in der Produktstrategie tätig. Er ist außerdem außerordentlicher Professor für Analytik und Gründer von StrataScratch, einer Plattform, die Datenwissenschaftlern hilft, sich mit echten Interviewfragen von Prime-Unternehmen auf ihre Interviews vorzubereiten. Nate schreibt über die neuesten Tendencies auf dem Karrieremarkt, gibt Ratschläge zu Vorstellungsgesprächen, stellt Knowledge-Science-Projekte vor und behandelt alles rund um SQL.