

Bild vom Autor
# Einführung
Wenn Sie Anwendungen mit großen Sprachmodellen (LLMs) erstellen, haben Sie wahrscheinlich schon einmal dieses Szenario erlebt, bei dem Sie eine Eingabeaufforderung ändern, sie ein paar Mal ausführen und die Ausgabe sich besser anfühlt. Aber ist es tatsächlich besser? Ohne objektive Kennzahlen stecken Sie in dem fest, was die Branche heute als „Vibe-Testing“ bezeichnet, was bedeutet, Entscheidungen auf der Grundlage Ihrer Instinct und nicht auf Grundlage von Daten zu treffen.
Die Herausforderung ergibt sich aus einem grundlegenden Merkmal von KI-Modellen: der Unsicherheit. Im Gegensatz zu herkömmlicher Software program, bei der dieselbe Eingabe immer dieselbe Ausgabe erzeugt, können LLMs unterschiedliche Reaktionen auf ähnliche Eingabeaufforderungen generieren. Dies macht herkömmliche Unit-Assessments wirkungslos und lässt Entwickler rätseln, ob ihre Änderungen wirklich die Leistung verbessert haben.
Dann kam Google Stax, ein neues experimentelles Toolkit von Google DeepMind Und Google Labs Entwickelt, um der KI-Bewertung Genauigkeit zu verleihen. In diesem Artikel werfen wir einen Blick darauf, wie Stax es Entwicklern und Datenwissenschaftlern ermöglicht, Modelle und Eingabeaufforderungen anhand ihrer eigenen benutzerdefinierten Kriterien zu testen und so subjektive Urteile durch wiederholbare, datengesteuerte Entscheidungen zu ersetzen.
# Google Stax verstehen
Stax ist ein Entwicklertool, das die Evaluierung generativer KI-Modelle und -Anwendungen vereinfacht. Betrachten Sie es als ein Check-Framework, das speziell für die besonderen Herausforderungen der Arbeit mit LLMs entwickelt wurde.
Im Kern löst Stax ein einfaches, aber kritisches Drawback: Woher wissen Sie, ob ein Modell oder eine Eingabeaufforderung für Ihren spezifischen Anwendungsfall besser ist als ein anderes? Anstatt sich auf allgemeine Kriterien zu verlassen, die möglicherweise nicht den Anforderungen Ihrer Anwendung entsprechen, können Sie mit Stax definieren, was „intestine“ für Ihr Projekt bedeutet, und es anhand dieser Requirements messen.
// Erkundung der wichtigsten Fähigkeiten
- Es hilft dabei, Ihre eigenen Erfolgskriterien zu definieren, die über allgemeine Kennzahlen wie Sprachkompetenz und Sicherheit hinausgehen
- Sie können verschiedene Eingabeaufforderungen verschiedener Modelle nebeneinander testen
- Sie können datengesteuerte Entscheidungen treffen, indem Sie gesammelte Leistungsmetriken visualisieren, einschließlich Qualität, Latenz und Token-Nutzung
- Es kann maßstabsgetreue Bewertungen mit Ihren eigenen Datensätzen durchführen
Stax ist flexibel und unterstützt nicht nur Googles Zwillinge Modelle aber auch GPT von OpenAI, Claude von Anthropic, Mistralund andere über API-Integrationen.
# Über Normal-Benchmarks hinausgehen
Allgemeine KI-Benchmarks erfüllen einen wichtigen Zweck, beispielsweise dabei, den Modellfortschritt auf hohem Niveau zu verfolgen. Sie berücksichtigen jedoch oft nicht die domänenspezifischen Anforderungen. Ein Modell, das sich beim Denken im offenen Bereich auszeichnet, könnte bei speziellen Aufgaben wie den folgenden schlecht abschneiden:
- Compliance-orientierte Zusammenfassung
- Analyse von Rechtsdokumenten
- Unternehmensspezifische Fragen und Antworten
- Einhaltung der Markenstimme
In der Lücke zwischen allgemeinen Benchmarks und realen Anwendungen bietet Stax einen Mehrwert. Es ermöglicht Ihnen, KI-Systeme anhand Ihrer Daten und Kriterien zu bewerten, nicht anhand abstrakter globaler Bewertungen.
# Erste Schritte mit Stax
// Schritt 1: Hinzufügen eines API-Schlüssels
Um Modellausgaben zu generieren und Auswertungen auszuführen, müssen Sie einen API-Schlüssel hinzufügen. Stax empfiehlt, mit a zu beginnen Gemini-API-Schlüsselda die integrierten Evaluatoren es standardmäßig verwenden. Sie können sie jedoch auch für die Verwendung anderer Modelle konfigurieren. Sie können Ihren ersten Schlüssel beim Onboarding oder später in den Einstellungen hinzufügen.
Um mehrere Anbieter zu vergleichen, fügen Sie Schlüssel für jedes Modell hinzu, das Sie testen möchten. Dies ermöglicht einen parallelen Vergleich ohne Werkzeugwechsel.
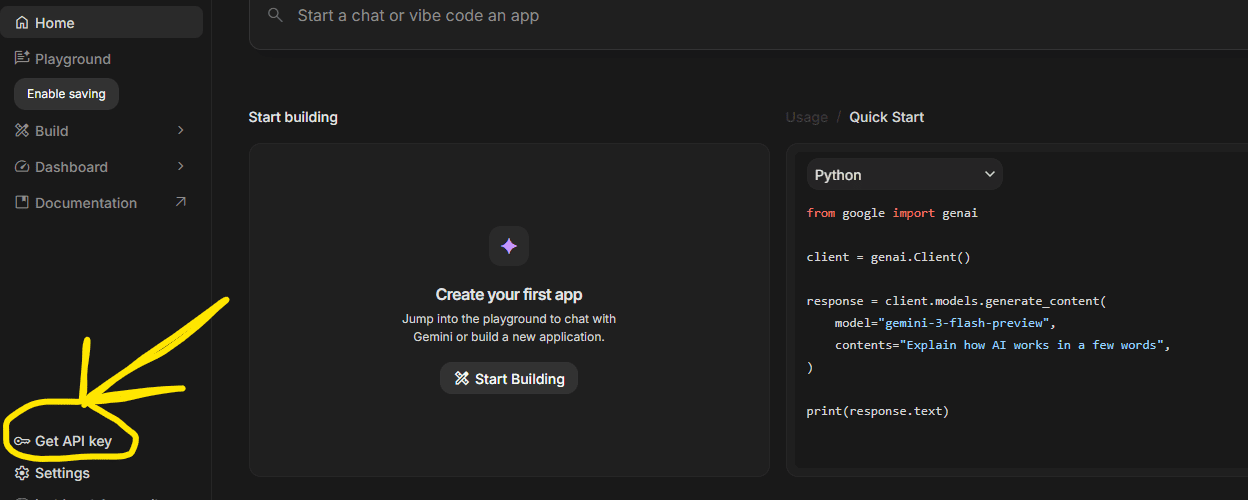
Einen API-Schlüssel erhalten
// Schritt 2: Erstellen eines Evaluierungsprojekts
Projekte sind der zentrale Arbeitsbereich in Stax. Jedes Projekt entspricht einem einzelnen Evaluierungsexperiment, beispielsweise dem Testen eines neuen System-Prompts oder dem Vergleich zweier Modelle.
Sie können zwischen zwei Projekttypen wählen:
| Projekttyp | Am besten für |
|---|---|
| Einzelmodell |
Baseline-Leistung oder Testen einer Iteration eines Modells oder einer Systemaufforderung |
| Seite an Seite |
Direkter Vergleich zweier verschiedener Modelle oder Eingabeaufforderungen im selben Datensatz |

Abbildung 1: Ein Flussdiagramm für einen Vergleich nebeneinander, das zeigt, wie zwei Modelle dieselben Eingabeaufforderungen erhalten und wie ihre Ausgaben in einen Evaluator fließen, der Vergleichsmetriken erstellt
// Schritt 3: Erstellen Sie Ihren Datensatz
Eine solide Bewertung beginnt mit Daten, die genau sind und Ihre realen Anwendungsfälle widerspiegeln. Stax bietet zwei Hauptmethoden an, um dies zu erreichen:
Possibility A: Manuelles Hinzufügen von Daten im Immediate Playground
Wenn Sie noch keinen Datensatz haben, erstellen Sie einen von Grund auf:
- Wählen Sie die Modelle aus, die Sie testen möchten
- Legen Sie eine Systemaufforderung fest (non-obligatory), um die Rolle der KI zu definieren
- Fügen Sie Benutzeraufforderungen hinzu, die echte Benutzereingaben darstellen
- Geben Sie menschliche Bewertungen ein (non-obligatory), um grundlegende Qualitätsbewertungen zu erstellen
Jede Eingabe, Ausgabe und Bewertung wird automatisch als Testfall gespeichert.
Possibility B: Hochladen eines vorhandenen Datensatzes
Für Groups mit Produktionsdaten laden Sie CSV-Dateien direkt hoch. Wenn Ihr Datensatz keine Modellausgaben enthält, klicken Sie auf „Ausgaben generieren“ und wählen Sie ein Modell aus, um diese zu generieren.
Finest Follow: Beziehen Sie Randfälle und widersprüchliche Beispiele in Ihren Datensatz ein, um umfassende Assessments sicherzustellen.
# Auswertung von KI-Ausgaben
// Durchführung einer manuellen Bewertung
Sie können menschliche Bewertungen zu einzelnen Ergebnissen direkt auf dem Spielplatz oder im Projekt-Benchmark abgeben. Obwohl die menschliche Bewertung als „Goldstandard“ gilt, ist sie langsam, teuer und schwer zu skalieren.
// Durchführen einer automatisierten Bewertung mit Autoratern
Um viele Ausgaben gleichzeitig zu bewerten, verwendet Stax LLM-als-Richter Auswertung, bei der ein leistungsstarkes KI-Modell die Ergebnisse eines anderen Modells anhand Ihrer Kriterien bewertet.
Stax enthält vorinstallierte Evaluatoren für gängige Metriken:
- Geläufigkeit
- Sachliche Konsistenz
- Sicherheit
- Anweisungen folgen
- Prägnanz

Die Stax-Bewertungsoberfläche zeigt eine Spalte mit Modellausgaben mit angrenzenden Bewertungsspalten von verschiedenen Evaluatoren sowie eine Schaltfläche „Bewertung ausführen“.
// Nutzung benutzerdefinierter Evaluatoren
Während vorinstallierte Evaluatoren einen hervorragenden Ausgangspunkt bieten, ist die Erstellung benutzerdefinierter Evaluatoren die beste Möglichkeit, zu messen, was für Ihren spezifischen Anwendungsfall wichtig ist.
Mit benutzerdefinierten Evaluatoren können Sie bestimmte Kriterien definieren, wie zum Beispiel:
- „Ist die Antwort hilfreich, aber nicht übermäßig vertraut?“
- „Enthält die Ausgabe personenbezogene Daten (PII)?“
- „Entspricht der generierte Code unserem internen Styleguide?“
- „Steht die Markenstimme im Einklang mit unseren Leitlinien?“
So erstellen Sie einen benutzerdefinierten Evaluator: Definieren Sie Ihre klaren Kriterien, schreiben Sie eine Eingabeaufforderung für das Richtermodell, die eine Bewertungscheckliste enthält, und testen Sie es anhand einer kleinen Stichprobe manuell bewerteter Ergebnisse, um eine Übereinstimmung sicherzustellen.
# Erkundung praktischer Anwendungsfälle
// Überprüfung von Anwendungsfall 1: Kundensupport-Chatbot
Stellen Sie sich vor, Sie erstellen einen Chatbot für den Kundensupport. Ihre Anforderungen könnten Folgendes umfassen:
- Professioneller Ton
- Präzise Antworten basierend auf Ihrer Wissensdatenbank
- Keine Halluzinationen
- Lösung gemeinsamer Probleme innerhalb von drei Börsen
Mit Stax würden Sie:
- Laden Sie einen Datensatz mit echten Kundenanfragen hoch
- Generieren Sie Antworten aus verschiedenen Modellen (oder verschiedenen Eingabeaufforderungsversionen)
- Erstellen Sie einen benutzerdefinierten Evaluator, der durch Professionalität und Genauigkeit punktet
- Vergleichen Sie die Ergebnisse nebeneinander, um den besten Leistungsträger auszuwählen
// Überprüfung von Anwendungsfall 2: Inhaltszusammenfassungstool
Für eine Anwendung zur Nachrichtenzusammenfassung ist Folgendes wichtig:
- Prägnanz (Zusammenfassungen unter 100 Wörtern)
- Sachliche Übereinstimmung mit dem Originalartikel
- Bewahrung wichtiger Informationen
Mit dem vorgefertigten Summarization High quality Evaluator von Stax erhalten Sie sofortige Messwerte, während benutzerdefinierte Evaluatoren bestimmte Längenbeschränkungen oder Markenanforderungen durchsetzen können.
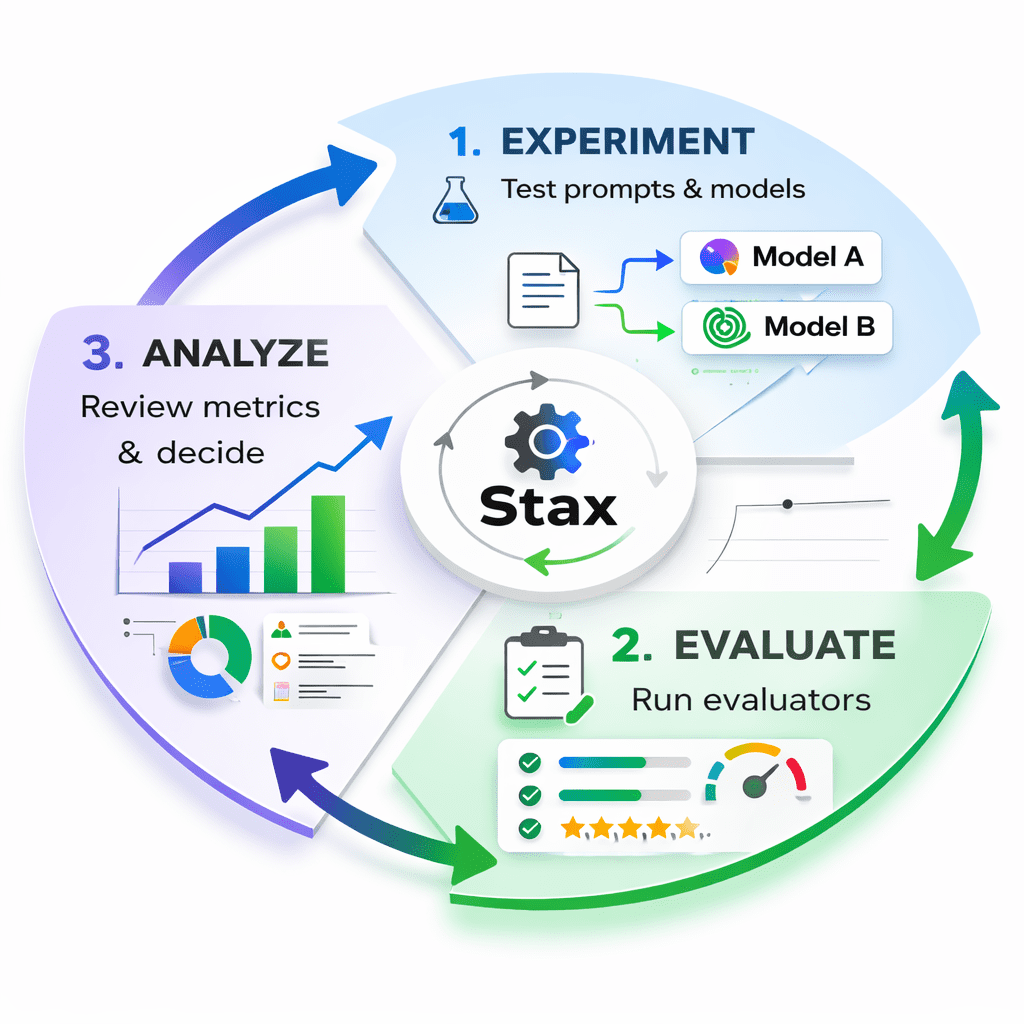
Abbildung 2: Eine visuelle Darstellung des Stax-Schwungrads mit drei Phasen: Experiment (Testaufforderungen/Modelle), Evaluieren (Ausführen von Evaluatoren) und Analysieren (Metriken überprüfen und entscheiden).
# Ergebnisse interpretieren
Sobald die Auswertungen abgeschlossen sind, fügt Stax Ihrem Datensatz neue Spalten hinzu, die Bewertungen und Begründungen für jede Ausgabe anzeigen. Der Abschnitt „Projektmetriken“ bietet eine aggregierte Ansicht von:
- Menschliche Bewertungen
- Durchschnittliche Bewertung der Bewerter
- Inferenzlatenz
- Token zählt
Nutzen Sie diese quantitativen Daten, um:
- Iterationen vergleichen: Ist Immediate A durchweg besser als Immediate B?
- Wählen Sie zwischen Modellen: Ist das schnellere Modell den leichten Qualitätsverlust wert?
- Verfolgen Sie den Fortschritt: Verbessern Ihre Optimierungen tatsächlich die Leistung?
- Fehler identifizieren: Welche Eingaben führen durchweg zu schlechten Ergebnissen?

Abbildung 3: Eine Dashboard-Ansicht mit Balkendiagrammen, die zwei Modelle anhand mehrerer Metriken (Qualitätsfaktor, Latenz, Kosten) vergleichen.
# Implementierung von Finest Practices für effektive Bewertungen
- Fangen Sie klein an und skalieren Sie dann: Sie benötigen nicht Hunderte von Testfällen, um einen Mehrwert zu erzielen. Ein Bewertungssatz mit nur zehn hochwertigen Eingabeaufforderungen ist unendlich wertvoller, als sich allein auf Vibe-Assessments zu verlassen. Beginnen Sie mit einem fokussierten Satz und erweitern Sie ihn, während Sie lernen.
- Regressionstests erstellen: Ihre Bewertungen sollten Assessments beinhalten, die die bestehende Qualität schützen. Beispiel: „Immer gültiges JSON ausgeben“ oder „Niemals Mitbewerbernamen einbeziehen“. Dadurch wird verhindert, dass neue Änderungen das, was bereits funktioniert, zerstören.
- Baue Herausforderungssets: Erstellen Sie Datensätze, die auf Bereiche abzielen, in denen Sie Ihre KI verbessern möchten. Wenn Ihr Modell mit komplexen Argumenten zu kämpfen hat, erstellen Sie ein Herausforderungsset speziell für diese Fähigkeit.
- Geben Sie die menschliche Überprüfung nicht auf: Auch wenn sich automatisierte Auswertungen intestine skalieren lassen, bleibt es für die Entwicklung der Instinct von entscheidender Bedeutung, dass Ihr Group Ihr KI-Produkt nutzt. Verwenden Sie Stax, um überzeugende Beispiele aus menschlichen Assessments zu erfassen und sie in Ihre formalen Bewertungsdatensätze zu integrieren.
# Beantwortung häufig gestellter Fragen
- Was ist Google STAX? Stax ist ein Entwicklertool von Google zur Evaluierung von LLM-basierten Anwendungen. Es hilft Ihnen, Modelle und Eingabeaufforderungen anhand Ihrer eigenen Kriterien zu testen, anstatt sich auf allgemeine Benchmarks zu verlassen.
- Wie funktioniert Stax AI? Stax verwendet einen „LLM-as-Choose“-Ansatz, bei dem Sie Bewertungskriterien definieren und ein KI-Modell die Ergebnisse auf der Grundlage dieser Kriterien bewertet. Sie können vorgefertigte Evaluatoren verwenden oder benutzerdefinierte Evaluatoren erstellen.
- Mit welchem Software von Google können Einzelpersonen ihre Modelle für maschinelles Lernen erstellen? Während sich Stax eher auf die Bewertung als auf die Modellerstellung konzentriert, funktioniert es zusammen mit anderen Google-KI-Instruments. Zum Erstellen und Trainieren von Modellen verwenden Sie normalerweise TensorFlow oder Vertex AI. Stax hilft Ihnen dann bei der Bewertung der Leistung dieser Modelle.
- Was ist Googles Äquivalent zu ChatGPT? Die primäre Konversations-KI von Google ist Gemini (ehemals Bard). Stax kann Ihnen dabei helfen, Eingabeaufforderungen für Gemini zu testen und zu optimieren und seine Leistung mit anderen Modellen zu vergleichen.
- Kann ich KI anhand meiner eigenen Daten trainieren? Stax trainiert keine Modelle; es bewertet sie. Sie können jedoch Ihre eigenen Daten als Testfälle verwenden, um vorab trainierte Modelle zu bewerten. Zum Trainieren benutzerdefinierter Modelle auf Ihren Daten verwenden Sie Instruments wie Vertex AI.
# Abschluss
Die Ära des Vibe-Assessments geht zu Ende. Während die KI von experimentellen Demos zu Produktionssystemen übergeht, wird eine detaillierte Bewertung immer wichtiger. Google Stax bietet den Rahmen, um zu definieren, was „intestine“ für Ihren individuellen Anwendungsfall bedeutet, und die Instruments, um dies systematisch zu messen.
Indem Stax subjektive Urteile durch wiederholbare, datengesteuerte Bewertungen ersetzt, hilft es Ihnen:
- Versenden Sie KI-Funktionen mit Zuversicht
- Treffen Sie fundierte Entscheidungen zur Modellauswahl
- Schnellere Iteration bei Eingabeaufforderungen und Systemanweisungen
- Erstellen Sie KI-Produkte, die die Benutzeranforderungen zuverlässig erfüllen
Ganz gleich, ob Sie ein Datenwissenschaftler-Anfänger oder ein erfahrener ML-Ingenieur sind: Die Einführung strukturierter Bewertungspraktiken wird die Artwork und Weise, wie Sie mit KI bauen, verändern. Fangen Sie klein an, definieren Sie, worauf es für Ihre Anwendung ankommt, und lassen Sie sich bei Ihren Entscheidungen von Daten leiten.
Sind Sie bereit, über das Vibe-Testen hinauszugehen? Besuchen stax.withgoogle.com um das Software zu erkunden und der Group von Entwicklern beizutreten, die bessere KI-Anwendungen entwickeln.
// Referenzen
Shittu Olumid ist ein Software program-Ingenieur und technischer Autor, der sich leidenschaftlich dafür einsetzt, modernste Technologien zu nutzen, um fesselnde Erzählungen zu erschaffen, mit einem scharfen Blick fürs Element und einem Gespür für die Vereinfachung komplexer Konzepte. Sie können Shittu auch auf finden Twitter.