
Yajuan Si, James Wagner und Ron Kessler schreiben:
Der traditionelle Einsatz hochwertiger Wahrscheinlichkeitsstichproben zur Durchführung psychiatrischer epidemiologischer Erhebungen der Haushaltsbevölkerung steht vor zunehmenden finanziellen und betrieblichen Herausforderungen. Umfragen aus nichtwahrscheinlichkeitsbasierten und wahrscheinlichkeitsbasierten On-line-Panels haben sich als kostengünstige Alternativen mit dem zusätzlichen Vorteil einer schnellen Bearbeitungszeit herausgestellt, wenn auch mit teilweise erheblichen Verzerrungen.
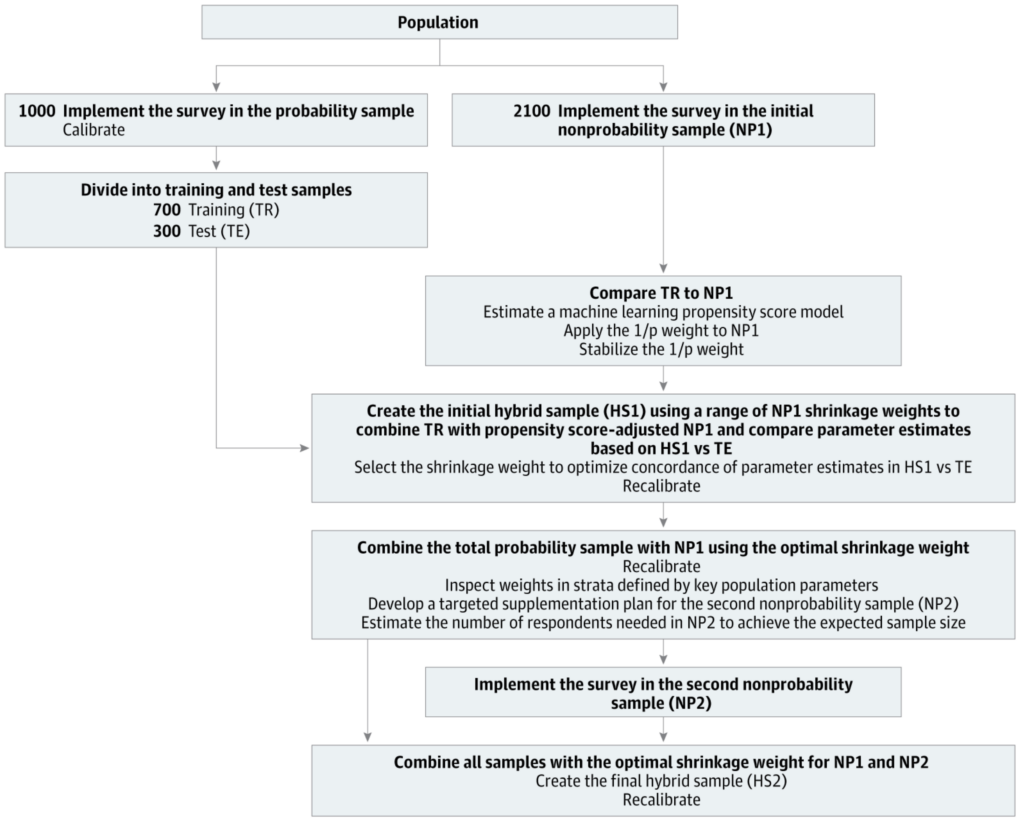
Wir empfehlen einen Mittelweg, Umfragen von On-line-Panels mit kleinen parallelen Wahrscheinlichkeitsstichproben hoher Qualität zu integrieren. . . Die Hauptmerkmale solcher „Hybrid-Designs“ sind folgende: Verwendung einer hochwertigen Wahrscheinlichkeitsstichprobe als Ersatz für die Grundgesamtheit, um Informationen über die Verteilungen ansonsten nicht verfügbarer Variablen bereitzustellen, die Teilnehmer an On-line-Panels von der größeren Haushaltspopulation unterscheiden, Einbeziehung von Kennzahlen in beide Umfragen, die sowohl stark mit den interessierenden Ergebnissen verbunden sind als auch stark die Mitgliedschaft im On-line-Panel vorhersagen, und Verwendung von Finest-Follow-Statistikmethoden, die die Ergebnisse beider Stichproben kombinieren.
Ein solches Hybriddesign sollte angesichts der bekannten Vorurteile in On-line-Panels das minimal akzeptable Design für psychiatrische epidemiologische Umfragen in der Haushaltsbevölkerung sein. Wir kommentieren jedoch auch mehrere andere Designs, die für schnellere und kostengünstigere explorative Analysen verwendet werden könnten.
Es ist interessant, Multi-Body- und Multi-Mode-Sampling eher als Finest Follow an sich und nicht als solche zu betrachten ein heikles Downside nur dann behandelt werden, wenn dies unbedingt erforderlich ist.
Yajuan bietet einige Hintergrundinformationen zum Projekt:
Dies ist das erste Mal, dass ich eine Arbeit ohne Gleichungen oder Datenmodellierung schreibe, sondern mich auf solide statistische Kenntnisse, das Verständnis der umfangreichen Literatur und das Sammeln vieler Daten verlassen muss. Und Ron Kesser ist ein phänomenaler Mitarbeiter. Durch die Zusammenarbeit mit ihm habe ich viel gelernt.
Wie auch immer, hier ist die Idee des Papiers: Wir schlagen eine hybride Datensammlung aus großen Nichtwahrscheinlichkeitsstichproben und kleinen parallelen Wahrscheinlichkeitsstichproben hoher Qualität als gängige Praxis für bevölkerungsbasierte Forschung vor. Bei MRP-Anwendungen haben wir oft Probleme mit der Verfügbarkeit von Populationsinformationen von X. Wir schlagen vor, die Populationsverteilung von X in einer kleinen Wahrscheinlichkeitsstichprobe zu schätzen, nachdem wir die Liste der hoch prädiktiven Kovariaten Wir schlagen die sequentielle Gewichtungsanpassung vor, indem wir zuerst die Wahrscheinlichkeitsstichprobe mit den Volkszählungsdaten gewichten (dies sollte auf einer kleinen Liste von Anpassungsfaktoren basieren, sagen wir nur demografische Daten, vorausgesetzt, dass das Design der Wahrscheinlichkeitsstichprobe intestine kontrolliert ist und die Nichtbeantwortungsverzerrung gering ist) und dann die Nichtwahrscheinlichkeitsstichprobe mit der ursprünglich gewichteten Wahrscheinlichkeitsstichprobe gewichten (die Liste der Anpassungsfaktoren könnte umfangreich sein, sogar einschließlich des Ergebnisses). Nach der sequentiellen Gewichtung können uns die kombinierten Stichproben ausreichend Aussagekraft für kleine Flächenschätzungen liefern. Der Einfachheit halber verwende ich hier die Gewichtungsanpassung, aber wir können auch MRP für die Anpassung verwenden, wenn wir ein interessantes Ergebnis haben.
Im Grunde versuche ich, die MRP-Anpassung von der Publish-Assortment-Inferenz zu forcieren, um das Studiendesign zu beeinflussen und die Datensammlung adaptiv zu modifizieren, indem ich die Belastung oder starke Annahmen bei der Analyse entlaste, indem ich das Studiendesign von Anfang an verbessere.
Dies ist aus mehreren Gründen interessant und potenziell wichtig:
1. Die Datenqualität der Umfrageantworten stellt immer mehr ein Downside dar, und es ist sinnvoll, zu versuchen, potenzielle Befragte an bequemeren Orten als im herkömmlichen Umfrageinterview zu erreichen.
2. Wir sollten systematischer darüber nachdenken, wie wir Daten aus mehreren Quellen integrieren können.
3. MRP kann an allgemeinere Datenstrukturen angepasst werden.
4. Wie Yajuan sagt, sollten wir uns all dieser Probleme bei der Datenerfassung und -analyse in der Entwurfsphase bewusst sein.