Heute, MLCommons gab neue Ergebnisse für die Benchmark-Suite MLPerf Coaching v5.1 bekannt, die die schnelle Entwicklung und den zunehmenden Reichtum des KI-Ökosystems sowie erhebliche Leistungsverbesserungen durch neue Systemgenerationen hervorheben.
Gehen Sie hier zur Ansicht Die vollständigen Ergebnisse für MLPerf Coaching v5.1 und finden Sie weitere Informationen zu den Benchmarks.
Die Benchmark-Suite MLPerf Coaching umfasst vollständige Systemtests, die Modelle, Software program und {Hardware} für eine Reihe von Anwendungen des maschinellen Lernens (ML) betonen. Die Open-Supply- und Peer-Evaluation-Benchmark-Suite bietet gleiche Wettbewerbsbedingungen, die Innovation, Leistung und Energieeffizienz für die gesamte Branche vorantreiben.
Model 5.1 stellte neue Rekorde für die Vielfalt der eingereichten Systeme auf. Die Teilnehmer dieser Benchmark-Runde reichten 65 einzigartige Systeme mit 12 verschiedenen Hardwarebeschleunigern und einer Vielzahl von Software program-Frameworks ein. Quick die Hälfte der Einsendungen waren Multi-Node-Lösungen, was einer Steigerung von 86 Prozent gegenüber der Model 4.1-Runde vor einem Jahr entspricht. Bei den Einreichungen mit mehreren Knoten kamen mehrere unterschiedliche Netzwerkarchitekturen zum Einsatz, von denen viele kundenspezifische Lösungen beinhalteten.
Diese Runde verzeichnete erhebliche Leistungsverbesserungen gegenüber den Ergebnissen der Model 5.0 für zwei Benchmark-Exams, die sich auf generative KI-Szenarien konzentrierten, und übertraf damit die vom Mooreschen Gesetz vorhergesagte Verbesserungsrate.
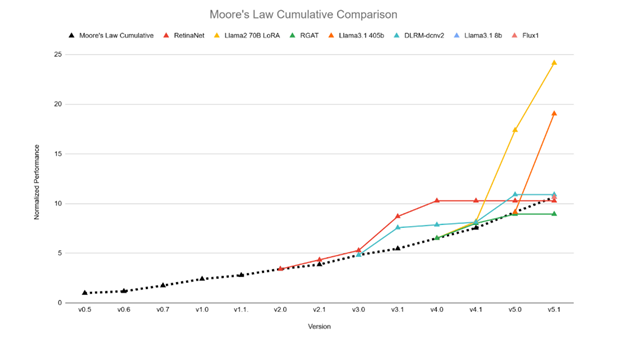
Relative Leistungsverbesserungen über die MLPerf Coaching-Benchmarks hinweg, normalisiert auf die Mooresche Gesetz-Trendlinie zum Zeitpunkt der Einführung jedes Benchmarks. (Quelle: MLCommons)
„Eine größere Auswahl an Hardwaresystemen ermöglicht es Kunden, Systeme anhand modernster MLPerf-Benchmarks zu vergleichen und fundierte Kaufentscheidungen zu treffen“, sagte Shriya Rishab, Co-Vorsitzende der MLPerf Coaching-Arbeitsgruppe. „Hardwareanbieter nutzen MLPerf als Möglichkeit, ihre Produkte in Multi-Node-Umgebungen mit großer Skalierungseffizienz zu präsentieren, und die in dieser Runde verzeichneten Leistungsverbesserungen zeigen, dass die dynamische Innovation im KI-Ökosystem einen großen Unterschied macht.“
Die MLPerf Coaching v5.1-Runde umfasst Leistungsergebnisse von 20 einreichenden Organisationen: AMD, ASUSTeK, Cisco, Datacrunch, Dell, Giga Computing, HPE, Krai, Lambda, Lenovo, MangoBoost, MiTAC, Nebius, NVIDIA, Oracle, Quanta Cloud Know-how, Supermicro, Supermicro + MangoBoost, College of Florida, Wiwynn. „Wir würden uns besonders freuen, Ersteinreicher von MLPerf-Schulungen, Datacrunch, der College of Florida und Wiwynn willkommen zu heißen“, sagte David Kanter, Leiter von MLPerf bei MLCommons.
Das Muster der Einsendungen zeigt auch eine zunehmende Betonung von Benchmarks, die sich auf Aufgaben der generativen KI (genAI) konzentrieren, mit einem Anstieg der Einsendungen für den Llama 2 70B LoRA-Benchmark um 24 Prozent und einem Anstieg um 15 Prozent für den neuen Llama 3.1 8B-Benchmark gegenüber dem Take a look at, den er ersetzte (BERT). „Zusammengenommen machen die zunehmenden Einreichungen zu GenAI-Benchmarks und die beträchtlichen Leistungsverbesserungen, die in diesen Exams verzeichnet wurden, deutlich, dass sich die Group stark auf GenAI-Szenarien konzentriert, was in gewissem Maße auf Kosten anderer potenzieller Anwendungen der KI-Technologie geht“, sagte Kanter. „Wir sind stolz darauf, diese Artwork von wichtigen Erkenntnissen über die Entwicklung des Fachgebiets zu liefern, die es allen Beteiligten ermöglichen, fundiertere Entscheidungen zu treffen.“
Die starke Beteiligung einer breiten Palette von Branchenakteuren stärkt das KI-Ökosystem als Ganzes und trägt dazu bei, sicherzustellen, dass der Benchmark den Bedürfnissen der Group gerecht wird. Wir laden Einreicher und andere Interessengruppen ein, sich dem anzuschließen Arbeitsgruppe MLPerf Coaching und helfen Sie uns, den Maßstab weiterzuentwickeln.
MLPerf Coaching v5.1 aktualisiert 2 Benchmarks
Die Sammlung von Exams in der Suite wird kuratiert, um mit der Branche Schritt zu halten, wobei einzelne Exams je nach Bedarf von einem Expertengremium aus der KI-Group hinzugefügt, aktualisiert oder entfernt werden.
In der Benchmark-Model 5.1 wurden zwei frühere Exams durch neue ersetzt, die die modernsten Technologielösungen für dieselbe Aufgabe besser darstellen. Konkret: Llama 3.1 8B ersetzt BERT; und Flux.1 ersetzt Secure Diffusion v2.
Llama 3.1 8B ist ein Benchmark-Take a look at für das Vortraining eines großen Sprachmodells (LLM). Es gehört zur gleichen „Herde“ von Modellen wie der Llama 3.1 405B-Benchmark, der bereits in der Suite enthalten ist, aber da es über weniger trainierbare Parameter verfügt, kann es auf nur einem einzigen Knoten ausgeführt und auf einem breiteren Spektrum von Systemen bereitgestellt werden. Dadurch wird der Take a look at einem breiteren Spektrum potenzieller Einsender zugänglich und bleibt gleichzeitig ein guter Indikator für die Leistung größerer Cluster. Weitere Particulars zum Llama 3.1 8B Benchmark finden Sie in diesem Whitepaper https://mlcommons.org/2025/10/training-llama-3-1-8b/.
Flux.1 ist ein transformatorbasierter Textual content-zu-Bild-Benchmark. Seit Secure Diffusion v2 im Jahr 2023 in die MLPerf Coaching Suite eingeführt wurde, haben sich Textual content-zu-Bild-Modelle auf zwei wichtige Arten weiterentwickelt: Sie haben eine Transformatorarchitektur in den Diffusionsprozess integriert und ihre Parameteranzahl ist um eine Größenordnung gestiegen. Flux.1, das ein transformatorbasiertes 11,9-Milliarden-Parameter-Modell enthält, spiegelt den aktuellen Stand der Technik in der generativen KI für Textual content-zu-Bild-Aufgaben wider. Dieses Whitepaper https://mlcommons.org/2025/10/training-flux1/ bietet weitere Informationen zum Flux.1-Benchmark.
„Der Bereich der KI ist ein bewegliches Ziel, das sich ständig mit neuen Szenarien und Fähigkeiten weiterentwickelt“, sagte Paul Baumstarck, Co-Vorsitzender der Arbeitsgruppe MLPerf Coaching. „Wir werden die Benchmark-Suite MLPerf Coaching weiterentwickeln, um sicherzustellen, dass wir messen, was für die Group heute und morgen wichtig ist.“