![]() Von Petros Koutoupis, VDURA
Von Petros Koutoupis, VDURA
Bei all dem Hype um künstliche Intelligenz und maschinelles Lernen verliert man leicht den Überblick darüber, welche Hochleistungs-Computing-Speicheranforderungen unerlässlich sind, um einen echten, transformativen Mehrwert für Ihr Unternehmen zu schaffen.
Bei der Bewertung einer Datenspeicherlösung sind Eingabe-/Ausgabeoperationen professional Sekunde (IOPS) eine der häufigsten Leistungsmetriken. Es ist seit langem der Commonplace zur Messung der Speicherleistung und je nach Arbeitslast können die IOPS eines Programs von entscheidender Bedeutung sein.
Wenn ein Anbieter in der Praxis IOPS ankündigt, zeigt er in Wirklichkeit, wie viele nicht zusammenhängende 4-KiB-Lese- oder Schreibvorgänge das System im schlimmsten Fall vollständig zufälliger E/A verarbeiten kann. Die Messung der Speicherleistung anhand von IOPS ist nur dann sinnvoll, wenn die Arbeitslasten IOPS-intensiv sind (z. B. Datenbanken, virtualisierte Umgebungen oder Webserver). Aber während wir in die Ära der KI eintreten, bleibt die Frage: Spielt IOPS immer noch eine Rolle?
Eine Aufschlüsselung Ihrer Commonplace-KI-Arbeitslast
KI-Workloads laufen über den gesamten Datenlebenszyklus, und jede Part verleiht der GPU-Rechenleistung (wobei CPUs Orchestrierung und Vorverarbeitung unterstützen), Speicher- und Datenverwaltungsressourcen ihre eigene Notice. Hier sind einige der häufigsten Typen, auf die Sie beim Aufbau und der Einführung von KI-Lösungen stoßen.
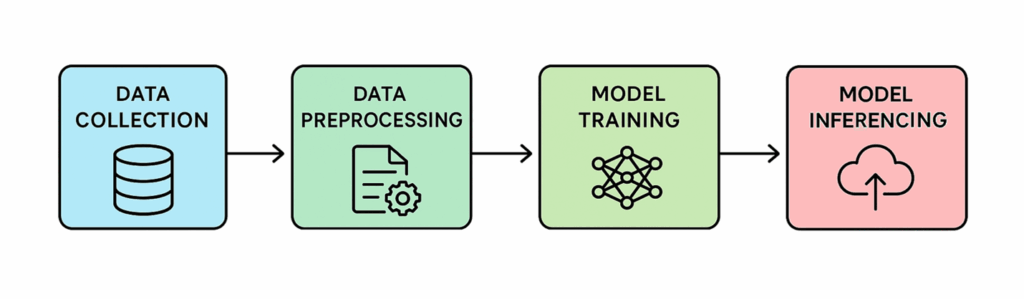
KI-Workflows (Quelle: VDURA)
Datenaufnahme und Vorverarbeitung
In dieser Part werden Rohdaten aus Quellen wie Datenbanken, Social-Media-Plattformen, IoT-Geräten und APIs (als Beispiele) gesammelt und dann in KI-Pipelines eingespeist, um sie für die Analyse vorzubereiten. Bevor diese Analyse durchgeführt werden kann, müssen die Daten jedoch bereinigt werden, indem Inkonsistenzen, beschädigte oder irrelevante Einträge entfernt, fehlende Werte ergänzt und Formate angeglichen werden (z. B
B. Zeitstempel oder Maßeinheiten), unter anderem.
Modelltraining
Nachdem die Daten vorbereitet sind, ist es Zeit für die anspruchsvollste Part: das Coaching. Hier werden große Sprachmodelle (LLMs) erstellt, indem Daten verarbeitet werden, um Muster und Beziehungen zu erkennen, die zu genauen Vorhersagen führen. Diese Part stützt sich stark auf Hochleistungs-GPUs mit häufigen Kontrollpunkten für den Speicher, damit das Coaching sich schnell nach {Hardware}- oder Jobfehlern erholen kann. In vielen Fällen können auch gewisse Feinabstimmungen oder ähnliche Anpassungen Teil des Prozesses sein.
Feinabstimmung
Beim Modelltraining geht es in der Regel darum, anhand großer Datenmengen ein grundlegendes Modell von Grund auf zu erstellen, um umfassendes, allgemeines Wissen zu erfassen. Durch die Feinabstimmung wird dieses vorab trainierte Modell dann für eine bestimmte Aufgabe oder Domäne unter Verwendung kleinerer, spezialisierter Datensätze verfeinert und so seine Leistung verbessert.
KI-Workflows (Quelle: VDURA)
Modellinferenz
Nach dem Coaching kann das KI-Modell Vorhersagen zu neuen statt historischen Daten treffen, indem es die gelernten Muster anwendet, um umsetzbare Ergebnisse zu generieren. Wenn Sie dem Mannequin beispielsweise ein Bild eines Hundes zeigen, das es noch nie zuvor gesehen hat, sagt es voraus: „Das ist ein Hund.“
Auswirkungen auf die Hochleistungsdateispeicherung
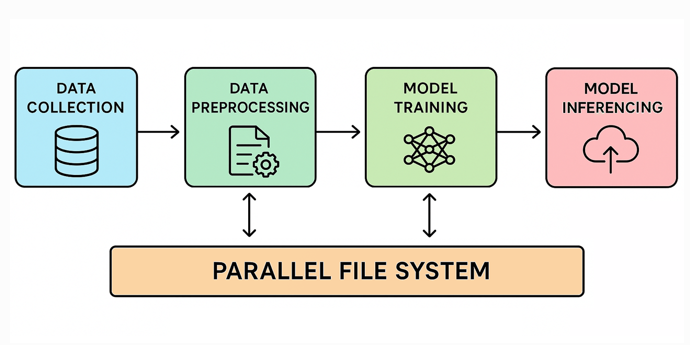
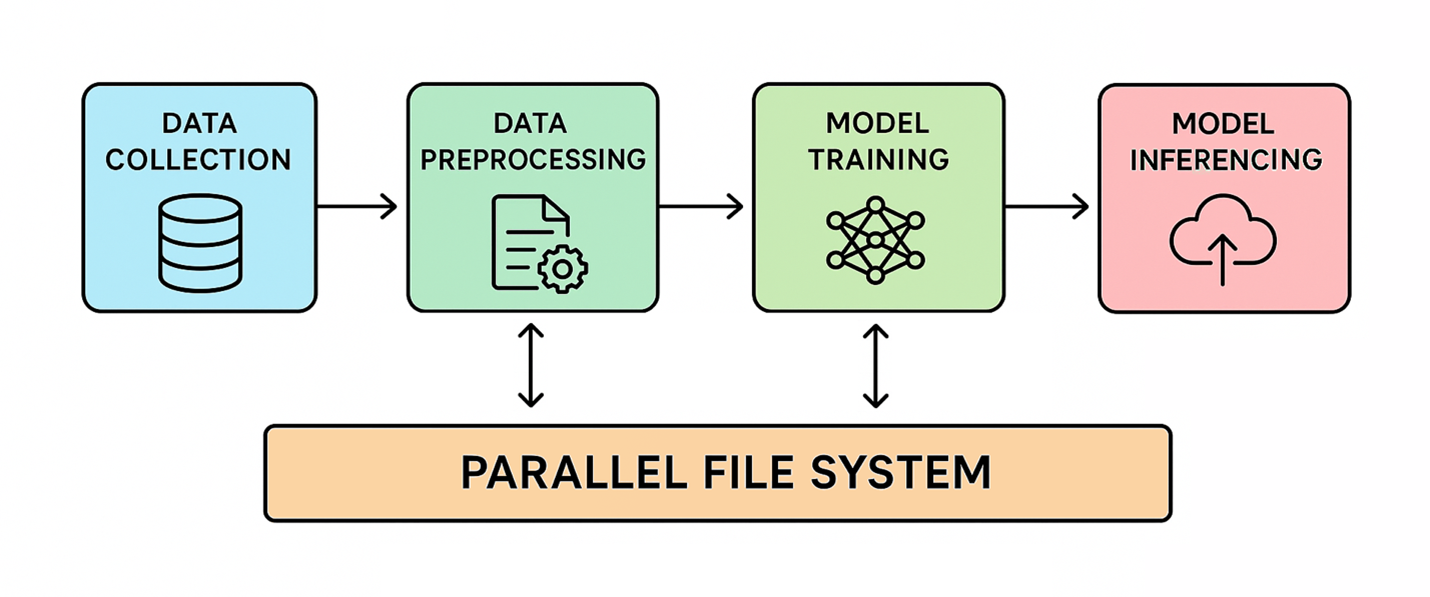
Ein HPC-Paralleldateisystem zerlegt Daten in Blöcke und verteilt sie auf mehrere vernetzte Speicherserver. Dadurch können viele Rechenknoten gleichzeitig mit hoher Geschwindigkeit auf die Daten zugreifen. Daher ist diese Architektur für datenintensive Workloads, einschließlich KI, unverzichtbar geworden.
Während der Datenaufnahmephase stammen Rohdaten aus vielen Quellen und parallele Dateisysteme spielen möglicherweise nur eine begrenzte Rolle. Ihre Bedeutung nimmt während der Vorverarbeitung und des Modelltrainings zu, wo Systeme mit hohem Durchsatz erforderlich sind, um große Datensätze schnell zu laden und zu transformieren. Dies reduziert den Zeitaufwand für die Vorbereitung von Datensätzen sowohl für das Coaching als auch für die Inferenz.
Checkpointing während des Modelltrainings speichert regelmäßig den aktuellen Standing des Modells, um Fortschrittsverluste aufgrund von Unterbrechungen zu verhindern. Dieser Prozess erfordert, dass alle Knoten den Zustand des Modells gleichzeitig speichern, was einen hohen Spitzenspeicherdurchsatz erfordert, um die Prüfpunktzeit minimal zu halten. Eine unzureichende Speicherleistung beim Checkpointing kann die Trainingszeiten verlängern und das Risiko eines Datenverlusts erhöhen.
Es ist offensichtlich, dass KI-Workloads vom Durchsatz und nicht von IOPS gesteuert werden. Das Coaching großer Modelle erfordert das Streamen riesiger sequenzieller Datensätze, oft mit einer Größe von Gigabyte bis Terabyte, in GPUs. Der eigentliche Engpass ist die Gesamtbandbreite (GB/s oder TB/s) und nicht die Verarbeitung von Millionen kleiner, zufälliger I/O-Vorgänge professional Sekunde. Ineffizienter Speicher kann zu Engpässen führen, GPUs und andere Prozessoren im Leerlauf lassen, das Coaching verlangsamen und die Kosten in die Höhe treiben.
Anforderungen, die ausschließlich auf IOPS basieren, können das Speicherbudget erheblich in die Höhe treiben oder die am besten geeigneten Architekturen ausschließen. Parallele Dateisysteme hingegen zeichnen sich durch Durchsatz und Skalierbarkeit aus. Um bestimmte IOPS-Ziele zu erreichen, werden Produktionsdateisysteme oft überentwickelt, was zu höheren Kosten oder unnötigen Funktionen führt, anstatt auf optimalen Durchsatz ausgelegt zu sein.
Abschluss
KI-Workloads erfordern eher Speicher mit hohem Durchsatz als hohe IOPS. Während IOPS seit langem eine Standardmetrik sind, verlässt sich moderne KI – insbesondere bei der Datenvorverarbeitung, dem Modelltraining und dem Checkpointing – auf die effiziente Übertragung riesiger sequenzieller Datensätze, um GPUs und Rechenknoten voll auszulasten. Parallele Dateisysteme bieten die nötige Skalierbarkeit und Bandbreite, um diese Arbeitslasten effektiv zu bewältigen, während die Konzentration ausschließlich auf IOPS zu überentwickelten, kostspieligen Lösungen führen kann, die die Trainingsleistung nicht optimieren. Für KI im großen Maßstab sind Durchsatz und Gesamtbandbreite die wahren Treiber für Produktivität und Kosteneffizienz.
Autor: Petros Koutoupis ist mehr als zwei Jahrzehnte in der Datenspeicherbranche tätig und hat für Unternehmen wie Xyratex, Cleversafe/IBM, Seagate, Cray/HPE und jetzt auch für KI- und HPC-Datenplattformunternehmen gearbeitet VDURA.