
https://www.youtube.com/watch?v=5bgr1ynlsyk
In diesem Projektleitwechsel werden wir untersuchen, wie reale Umfragedaten mithilfe von Python und Pandas reinigen und analysiert werden, während wir in die faszinierende Welt des Star Wars -Fandoms eintauchen. Durch die Zusammenarbeit mit Umfrageergebnissen aus FivethirtyEight werden wir Einblicke in die Präferenzen der Zuschauer, Filmrankings und demografische Traits aufdecken, die über das Offensichtliche hinausgehen.
Die Analyse der Umfragedaten ist eine kritische Fähigkeit für jeden Datenanalyst. Im Gegensatz zu sauberen, strukturierten Datensätzen sind Umfragantworten mit einzigartigen Herausforderungen verbunden: inkonsistente Formatierung, gemischte Datentypen, Kontrollkästchen Antworten, die strategische Handhabung erfordern, und fehlende Werte, die ihre eigene Geschichte erzählen. Dieses Projekt befasst sich mit diesen realen Herausforderungen und bereitet Sie auf die unordentlichen Datensätze vor, auf die Sie in Ihrer Karriere begegnen werden.
In diesem Tutorial werden wir professionelle Visualisierungen in Qualität erstellen, die eine überzeugende Geschichte über das Star Wars-Fandom erzählen und zeigen, wie die ordnungsgemäße Datenreinigung und das durchdachte Visualisierungsdesign Rohumfragendaten in Stakeholder-fähige Erkenntnisse umwandeln können.
Warum dieses Projekt wichtig ist
Die Umfrageanalyse stellt eine Kernkompetenz für die Datenwissenschaft dar, die in der Branche anwendbar ist. Unabhängig davon, ob Sie Umfragen zur Kundenzufriedenheit, die Mitarbeiter des Arbeitnehmers oder die Marktforschung analysieren, bilden die hier gezeigten Techniken die Grundlage für die professionelle Datenanalyse:
- Datenreinigungskenntnisse zum Umgang mit unordentlichen, realen Datensätzen
- Boolesche Umbautechniken Für Umfragesteuerungsprüfungen
- Demografische Segmentierungsanalyse zum Aufdecken von Gruppenunterschieden
- Professionelles Visualisierungsdesign Für Präsentationen der Stakeholder
- Perception -Synthese Um Datenergebnisse in Enterprise Intelligence zu übersetzen
Das Star Wars -Thema macht das Lernen angenehm, diese Fähigkeiten übertragen jedoch direkt auf geschäftliche Kontexte. Beherrschen Sie diese Techniken und Sie werden bereit sein, aus jedem Umfragedatensatz aussagekräftige Erkenntnisse zu extrahieren, die Ihren Schreibtisch überqueren.
Am Ende dieses Tutorials werden Sie wissen, wie man:
- Reinigen Sie die Daten zum chaotischen Umfrage durch Zuordnung von Ja/Nein -Spalten und Konvertieren der Kontrollkästchen -Antworten
- Behandeln Sie unbenannte Spalten und erstellen Sie aussagekräftige Spaltennamen für die Analyse
- Verwenden Sie Boolesche Mapping-Techniken, um die Verfälschung von Daten zu vermeiden
- Berechnen Sie zusammenfassende Statistiken und Rankings aus Umfragantworten
- Erstellen Sie professionell aussehende horizontale Balkendiagramme mit benutzerdefiniertem Styling
- Bauen Sie vergleichende Visualisierungen für die demografische Analyse nebeneinander auf
- Anwenden Sie objektorientierte Matplotlib zur genauen Steuerung über das Erscheinungsbild der Diagramme
- Präsentieren Sie klare, umsetzbare Erkenntnisse an die Stakeholder
Bevor Sie beginnen: Vorabstrukturierung
Folgen Sie diese vorbereitenden Schritte, um das Beste aus diesem Projekt zu machen:
Überprüfen Sie das Projekt
Greifen Sie auf das Projekt zu und machen Sie sich mit den Zielen und Struktur vertraut: Star Wars -Umfrageprojekt
Greifen Sie auf das Lösungsnotizbuch zu
Sie können es hier anzeigen und herunterladen, um zu sehen, was wir behandeln werden: Lösungsnotizbuch
Bereiten Sie Ihre Umgebung vor
- Wenn Sie die DataQuest -Plattform verwenden, ist für Sie bereits alles eingerichtet
- Wenn Sie lokal arbeiten, stellen Sie sicher, dass Sie Python mit Pandas, Matplotlib und Numpy installiert haben
- Laden Sie den Datensatz aus dem Fivethirtyeight Github -Repository herunter
Voraussetzungen
- Bequem mit Python -Grundlagen und Pandas -Datenfaktoren
- Vertrautheit mit Wörterbüchern, Schleifen und Methoden in Python
- Grundlegendes Verständnis von Matplotlib (wir werden Zwischentechniken anwenden)
- Das Verständnis der Umfragendatenstruktur ist hilfreich, aber nicht erforderlich
Neu im Markdown? Wir empfehlen, die Grundlagen zu lernen, um Header zu formatieren und Ihrem Jupyter -Notizbuch Kontext hinzuzufügen: Markdown -Handbuch.
Einrichten Ihrer Umgebung
Beginnen wir mit dem Importieren der erforderlichen Bibliotheken und dem Laden unseres Datensatzes:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inlineDer %matplotlib inline Befehl ist Jupyter Magic, die sicherstellt, dass unsere Handlungen direkt im Notizbuch rendern. Dies ist für einen interaktiven Workflow für die Datenerforschung von entscheidender Bedeutung.
star_wars = pd.read_csv("star_wars.csv")
star_wars.head()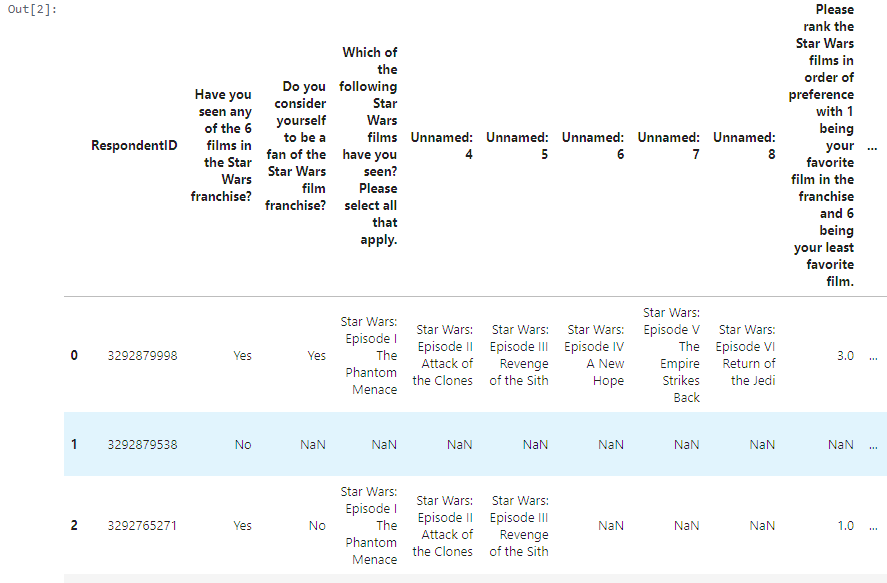
Unser Datensatz enthält Umfrageantworten von über 1.100 Befragten über ihre Star Wars -Betrachtungsgewohnheiten und -präferenzen.
Erkenntnisse lernen: Beachten Sie die namenlosen Spalten (unbenannt: 4, Unbenannt: 5 usw.) und extrem lange Spaltennamen? Dies ist typisch für Umfragedaten, die aus Plattformen wie SurveyMonkey exportiert wurden. Die ungenannten Spalten repräsentieren tatsächlich verschiedene Filme im Franchise, und die Reinigung dieser wird unsere erste große Aufgabe sein.
Die Datenherausforderung: Umfragestruktur erklärt
Umfragedaten stellen einzigartige strukturelle Herausforderungen dar. Betrachten Sie diese typische Umfragefrage:
„Welche der folgenden Star Wars -Filme haben Sie gesehen? Bitte wählen Sie alles, was zutreffen.“
Diese Frage im CheckBox-Stil wird als mehrere Spalten exportiert, wobei:
- Spalte 1 enthält „Star Wars: Episode I The Phantom Menace“, wenn nicht ausgewählt, wenn nicht
- Spalte 2 enthält „Star Wars: Episode II -Angriff der Klone“, falls dies ausgewählt wird, wenn nicht
- Und so weiter für alle sechs Filme …
Diese Struktur erschwert die Analyse, sodass wir sie in saubere booleale Säulen umwandeln.
Datenreinigungsprozess
Schritt 1: Konvertieren von Ja/Nein -Antworten auf Booleschen
Umfrageantworten werden häufig als Textual content („Ja“/“Nein“), aber boolesche Werte (Werte („(“ Ja „/“ Nein „erhältlichTrue/False) sind viel einfacher mit programmgesteuerter Arbeit:
yes_no = {"Sure": True, "No": False, True: True, False: False}
for col in (
"Have you ever seen any of the 6 movies within the Star Wars franchise?",
"Do you think about your self to be a fan of the Star Wars movie franchise?",
"Are you conversant in the Expanded Universe?",
"Do you think about your self to be a fan of the Star Trek franchise?"
):
star_wars(col) = star_wars(col).map(yes_no, na_action='ignore')Erkenntnisse lernen: Warum der scheinbar überflüssige True: True, False: False Einträge? Dies verhindert Überschreiben von Daten, wenn Jupyter-Zellen erneut abgerufen werden. Ohne diese Einträge, wenn Sie versehentlich die Zelle zweimal laufen lassen, alle Ihre True Werte würden werden NaN Weil das Mapping -Wörterbuch nicht mehr enthält True als Schlüssel. Dies ist eine übliche Jupyter -Fallstrick, die Ihre Analyse stillschweigend zerstören kann!
Schritt 2: Daten zur Anzeige des Movies transformieren
Der schwierigste Teil besteht darin, die Kontrollkästchen -Filmdaten zu konvertieren. Jede unbenannte Spalte zeigt, ob jemand eine bestimmte Star Wars -Episode gesehen hat:
movie_mapping = {
"Star Wars: Episode I The Phantom Menace": True,
np.nan: False,
"Star Wars: Episode II Assault of the Clones": True,
"Star Wars: Episode III Revenge of the Sith": True,
"Star Wars: Episode IV A New Hope": True,
"Star Wars: Episode V The Empire Strikes Again": True,
"Star Wars: Episode VI Return of the Jedi": True,
True: True,
False: False
}
for col in star_wars.columns(3:9):
star_wars(col) = star_wars(col).map(movie_mapping)Schritt 3: Strategische Säule umbenennen
Lange, unhandliche Spaltennamen erschweren die Analyse. Wir werden sie in etwas Managbares umbenennen:
star_wars = star_wars.rename(columns={
"Which of the next Star Wars movies have you ever seen? Please choose all that apply.": "seen_1",
"Unnamed: 4": "seen_2",
"Unnamed: 5": "seen_3",
"Unnamed: 6": "seen_4",
"Unnamed: 7": "seen_5",
"Unnamed: 8": "seen_6"
})Wir werden auch die Rating -Spalten aufräumen:
star_wars = star_wars.rename(columns={
"Please rank the Star Wars movies so as of desire with 1 being your favourite movie within the franchise and 6 being your least favourite movie.": "ranking_ep1",
"Unnamed: 10": "ranking_ep2",
"Unnamed: 11": "ranking_ep3",
"Unnamed: 12": "ranking_ep4",
"Unnamed: 13": "ranking_ep5",
"Unnamed: 14": "ranking_ep6"
})Analyse: Aufdecken der Datengeschichte
Welcher Movie regiert oberste?
Berechnen wir das durchschnittliche Rating für jeden Movie. Denken Sie daran, dass niedrigere Zahlen bei Rating -Fragen eine höhere Präferenz anzeigen:
mean_ranking = star_wars(star_wars.columns(9:15)).imply().sort_values()
print(mean_ranking)ranking_ep5 2.513158
ranking_ep6 3.047847
ranking_ep4 3.272727
ranking_ep1 3.732934
ranking_ep2 4.087321
ranking_ep3 4.341317Die Ergebnisse sind entscheidend: Episode V (The Empire Strikes Again) tritt mit einem durchschnittlichen Rang von 2,51 als klarer Fanfavorit auf. Die ursprüngliche Trilogie (Episoden IV-Vi) übertrifft die Prequel-Trilogie (Episoden I-III) signifikant.
Filmzuschauermuster
Welche Filme haben die Leute tatsächlich gesehen?
total_seen = star_wars(star_wars.columns(3:9)).sum()
print(total_seen)seen_1 673
seen_2 571
seen_3 550
seen_4 607
seen_5 758
seen_6 738Episoden V und VI führen in der Zuschauerschaft, während die Prequels deutlich niedrigere Betrachtungszahlen zeigen. Episode III hat die wenigsten Zuschauer bei 550 Befragten.
Professionelle Visualisierung: von grundlegend zu Stakeholder-fähig
Erstellen Sie unser erstes Diagramm
Beginnen wir mit einer grundlegenden Visualisierung und verbessern sie schrittweise:
plt.bar(vary(6), star_wars(star_wars.columns(3:9)).sum())Dies erstellt ein funktionales Diagramm, ist aber nicht bereit für Stakeholder. Lassen Sie uns auf eine objektorientierte Matplotlib für eine präzise Kontrolle einrüsten:
fig, ax = plt.subplots(figsize=(6,3))
rankings = ax.barh(mean_ranking.index, mean_ranking, shade='#fe9b00')
ax.set_facecolor('#fff4d6')
ax.set_title('Common Rating of Every Film')
for backbone in ('high', 'proper', 'backside', 'left'):
ax.spines(backbone).set_visible(False)
ax.invert_yaxis()
ax.textual content(2.6, 0.35, '*Lowest rank is the mostn preferred', fontstyle='italic')
plt.present()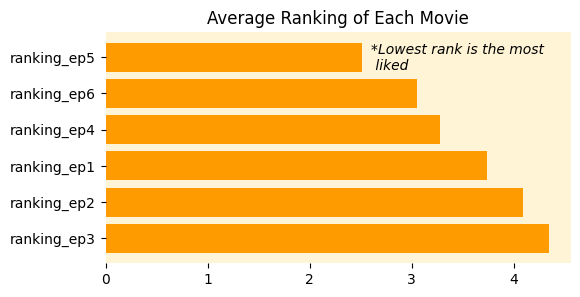
Erkenntnisse lernen: Denken Sie an fig als deine Leinwand und ax als Panel oder Diagrammbereich auf dieser Leinwand. Objektorientierte Matplotlib scheint anfangs einschüchternd zu sein, bietet jedoch eine präzise Kontrolle über jedes visuelle Factor. Der fig Objekt behandelt die Gesamteigenschaften der Figuren während ax kontrolliert einzelne Diagrammelemente.
Erweiterte Visualisierung: Geschlechtsvergleich
Unsere anspruchsvollste Visualisierung vergleicht Rankings und Zuschauerzahlen nach Geschlecht mit Facet-by-Facet-Balken:
# Create gender-based dataframes
males = star_wars(star_wars("Gender") == "Male")
females = star_wars(star_wars("Gender") == "Feminine")
# Calculate statistics for every gender
male_ranking_avgs = males(males.columns(9:15)).imply()
female_ranking_avgs = females(females.columns(9:15)).imply()
male_tot_seen = males(males.columns(3:9)).sum()
female_tot_seen = females(females.columns(3:9)).sum()
# Create side-by-side comparability
ind = np.arange(6)
top = 0.35
offset = ind + top
fig, ax = plt.subplots(1, 2, figsize=(8,4))
# Rankings comparability
malebar = ax(0).barh(ind, male_ranking_avgs, shade='#fe9b00', top=top)
femalebar = ax(0).barh(offset, female_ranking_avgs, shade='#c94402', top=top)
ax(0).set_title('Film Rankings by Gender')
ax(0).set_yticks(ind + top / 2)
ax(0).set_yticklabels(('Episode 1', 'Episode 2', 'Episode 3', 'Episode 4', 'Episode 5', 'Episode 6'))
ax(0).legend(('Males', 'Girls'))
# Viewership comparability
male2bar = ax(1).barh(ind, male_tot_seen, shade='#ff1947', top=top)
female2bar = ax(1).barh(offset, female_tot_seen, shade='#9b052d', top=top)
ax(1).set_title('# of Respondents by Gender')
ax(1).set_xlabel('Variety of Respondents')
ax(1).legend(('Males', 'Girls'))
plt.present()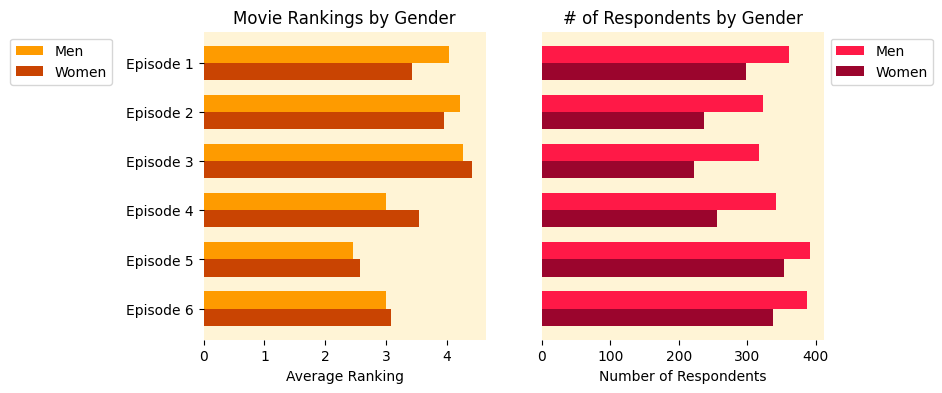
Erkenntnisse lernen: Die Offset -Technik (ind + top) ist der Schlüssel zum Erstellen von Facet-By-Facet-Balken. Dies verschiebt die weiblichen Balken leicht von den männlichen Balken und erzeugt den vergleichenden Effekt. Die gleichen Achsengrenzen sorgen für einen fairen visuellen Vergleich zwischen den Diagrammen.
Schlüsselergebnisse und Erkenntnisse
Durch unsere systematische Analyse haben wir festgestellt:
Filmvorstellungen:
- Episode V (Empire Strikes Again) entsteht als definitiver Fanfavorit in allen Demografien
- Die ursprüngliche Trilogie übertrifft die Prequels sowohl in Bewertungen als auch in der Zuschauerschaft signifikant
- Episode III erhält die niedrigsten Bewertungen und hat die wenigsten Zuschauer
Geschlechtsanalyse:
- Sowohl Männer als auch Frauen bezeichnen Episode V als ihren klaren Favoriten
- Geschlechtsspezifische Unterschiede in den Präferenzen sind minimal, bevorzugen jedoch konsequent das männliche Engagement
- Männer neigten dazu, Episode IV etwas höher zu bewerten als Frauen
- Mehr Männer haben jede der sechs Filme gesehen als Frauen, aber die Muster bleiben konsistent
Demografische Erkenntnisse:
- Die Rating -Unterschiede zwischen den Geschlechtern sind in den meisten Filmen in den meisten Filmen vernachlässigbar
- Episoden V und VI repräsentieren den universell ansprechendsten Inhalt des Franchise
- Das Stereotyp über Geschlechterpräferenzen im Science-Fiction zeigt eine gewisse Unterstützung bei den Engagements, aber Geschmackspräferenzen bleiben bemerkenswert ähnlich
Die Zusammenfassung der Stakeholder
Jede Analyse sollte mit klaren, umsetzbaren Erkenntnissen abschließen. Hier ist, was die Stakeholder wissen müssen:
- Episode V (Empire Strikes Again) ist der definitive Fanfavorit mit dem niedrigsten durchschnittlichen Rating über alle demografischen Merkmale
- Geschlechtsspezifische Unterschiede in den Filmpräferenzen sind minimalherausfordernde gemeinsame Stereotypen über Science-Fiction-Vorlieben
- Die ursprüngliche Trilogie übertrifft die Prequels erheblich Sowohl im kritischen Empfang als auch im Publikum Reichweite
- Die männlichen Befragten zeigen ein höheres Gesamtbetrieb mit dem Franchise, nachdem er im Durchschnitt mehr Filme gesehen hatte
Über diese Analyse hinaus: nächste Schritte
Dieser Datensatz enthält reichhaltige zusätzliche Dimensionen, die es wert sind, erkundet zu werden:
- Charakteranalyse: Welche Charaktere werden allgemein geliebt, gehasst oder kontrovers in der Fangemeinde?
- Die Debatte „Han Shot First“: Analysieren Sie diese berüchtigte Star Wars -Kontroverse und was sie über Fandom offenbart
- Cross-Franchise-Vorlieben: Erforschen Sie Korrelationen zwischen Star Wars und Star Trek Fandom
- Ausbildung und Alterskorrelationen: Unterscheiden sich die Betrachtungsmuster nach demografischen Faktoren, die über das Geschlecht hinausgehen?
Dieses Projekt gleicht die Entwicklung von technischen Fähigkeiten mit ansprechenden Themen perfekt aus. Sie werden mit einem polierten Portfolio -Stück entstehen, das Datenreinigungskenntnisse, fortschrittliche Visualisierungsfunktionen und die Fähigkeit, unordentliche Umfragedaten in umsetzbare geschäftliche Erkenntnisse umzuwandeln, nachzuweisen.
Egal, ob Sie Crew Jedi oder Sith sind, die Daten erzählen eine überzeugende Geschichte. Und jetzt haben Sie die Fähigkeiten, es schön zu sagen.
Wenn Sie dieses Projekt versuchen, teilen Sie bitte Ihre Ergebnisse in der Dataquest -Group und markieren Sie mich (@Ana_strahl). Ich würde gerne sehen, welche Muster Sie entdecken!
Weitere Projekte zu versuchen
Wir haben einige andere Projekte zur Walkthrough -Tutorials, die Sie auch genießen können: