
Im Jahr 2021 habe ich unterrichtet Umfrageforschungsmethoden an der NYU (Danke an Daphna Harel für diese Gelegenheit!). Wir haben das Lehrbuch von verwendet Groves et al. (in dieser Blogserie Hier). Es hat dieses hilfreiche Bild, das sogar Twitter geliked:
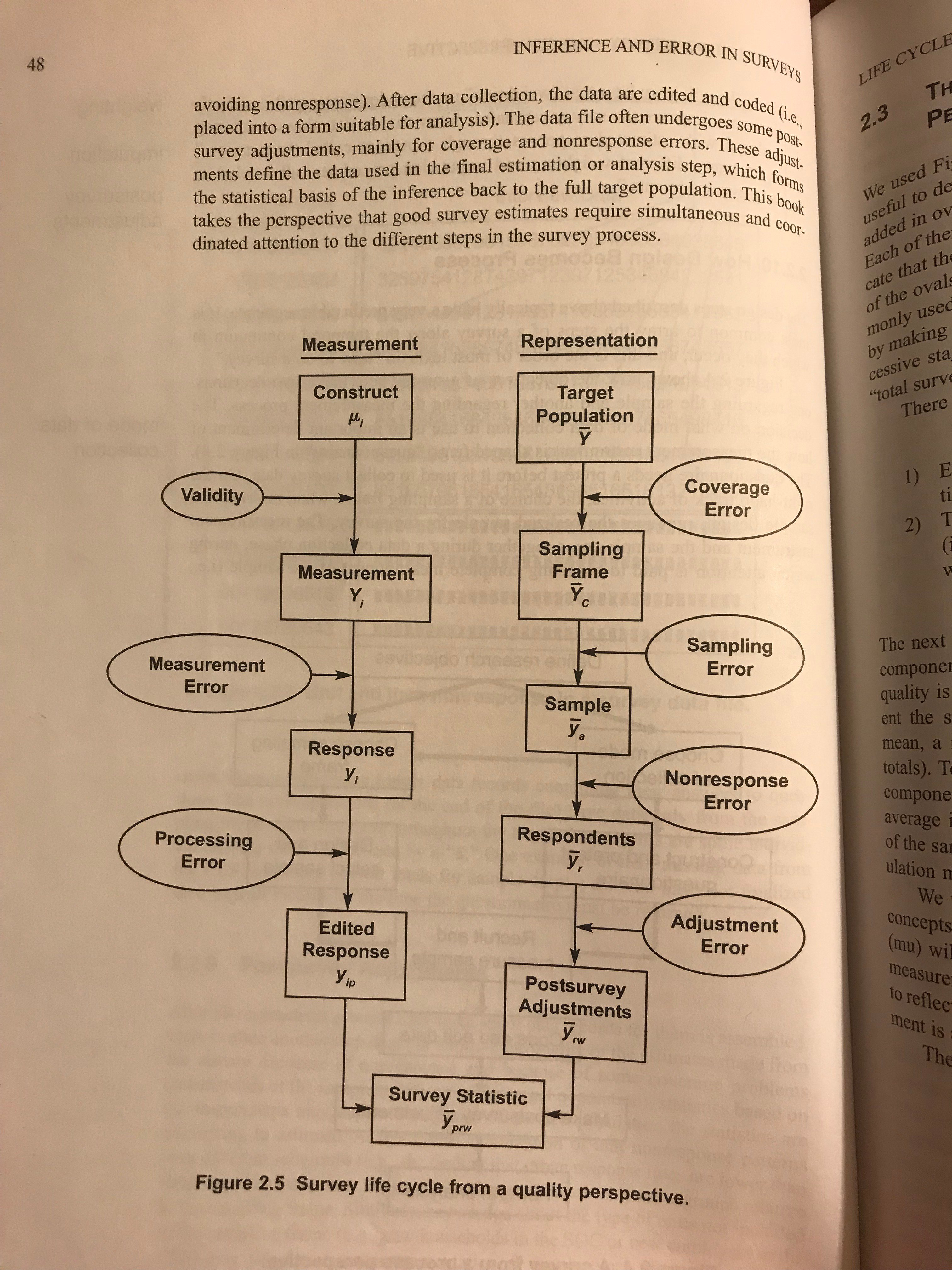
Ich magazine dieses Bild, weil es uns daran erinnert, alle Fehlerquellen zu berücksichtigen, auch wenn das etwas stressig ist. Betrachtet man beispielsweise verschiedene Befragungsmodi (persönlich vs. Telefon vs. E-Mail), Groves et al. S.151 vergleicht Rücklaufquote, Kosten, Abdeckung und Messfehler. Meng 2018 „Statistische Paradiese und Paradoxien“ (in dieser Blogserie Hier) erinnert uns daran, dass große Verwaltungsdatensätze möglicherweise eine große Abdeckung und Stichprobengröße haben, ein kleinerer Datensatz mit höherer Qualität jedoch in wichtigen Punkten besser sein könnte. In einem sprechen Meng fragt, ob eine nicht zufällige Stichprobe von 80 % (oder sogar 99 %) besser ist als eine zufällige Stichprobe von 5 %.

Betrachten Sie zwei Datenquellen, möglicherweise aus verschiedenen Umfragemodi:
- 100 % Abdeckung, dh Ihr Stichprobenrahmen umfasst die gesamte Grundgesamtheit. Aber die Antwortwahrscheinlichkeit P(R = 1 | Y) unterscheidet sich stark um Y, eine Variable von Interesse. Diese Unterschiede werden bei mehreren Kontaktversuchen möglicherweise nicht kleiner. Sie könnten tatsächlich schlimmer werden.
- Nur 5 % Abdeckung, dh Sie können nur 5 % der Bevölkerung kontaktieren und sie bitten, an Ihrer Umfrage teilzunehmen, additionally P(R = 1) <= 5 %. Nehmen wir jedoch an, dass die Antwortwahrscheinlichkeit P(R = 1 | Y) über Y ungefähr konstant ist. Hier umfasst R = 1 sowohl die Abdeckung als auch die Antwort.
(Um diesen Vergleich einfach zu halten, habe ich die Diskussion der Hilfsdaten X weggelassen, die wir haben viel diskutiert in dieser Blogserie.) Die erste Datenquelle weist keinen Protection-Fehler, aber viele Non-Response-Fehler auf. Die zweite Datenquelle weist viele Abdeckungsfehler auf, führt aber letztendlich nicht zu einer Verzerrung. Dies sind beide Cartoon-Beispiele, die reale Welt ist meist etwas subtiler.
Andrew befürwortet (2011, 2018Und 2025) beide Umfragen in einem Modell zusammenfassen mit:
Indikatoren für die einzelnen Erhebungen (unterschiedliche Abschnitte, möglicherweise auch unterschiedliche Steigungen)
In der Praxis ist dies meiner Meinung nach schwieriger, als es sich anhört, da große Modelle viele Hilfs-X-Daten ausmachen und Umfragen sich in ihrer Abdeckung und ihren Non-Response-Mechanismen stark unterscheiden. Könnte es besser sein, sich darauf zu konzentrieren, die Mechanismen einer Umfrage wirklich intestine zu verstehen? Es könnte aber auch besser sein, Datenquellen zu kombinieren.