
Jemand fragte mich, warum wir empfehlen, die Wahrheit auf die Y-Achse zu planen und den Wert auf der X-Achse und nicht umgekehrt zu prognostizieren.
Zuerst könnte es sinnvoll sein, die Wahrheit über die X-Achse und den Wert der y-Achse zu planen, da unter dem generativen Modell die Wahrheit an erster Stelle steht.
Der Grund, warum wir empfehlen, die Wahrheit über die y-Achse und den vorhergesagten Wert für die X-Achse zu planen, ist, dass die relevante Reihenfolge bei Berücksichtigung von Vorhersagen nicht generativ, sondern inferentiell ist. Und infertig sind die Daten an erster Stelle, wie es ist, was beobachtet wird.
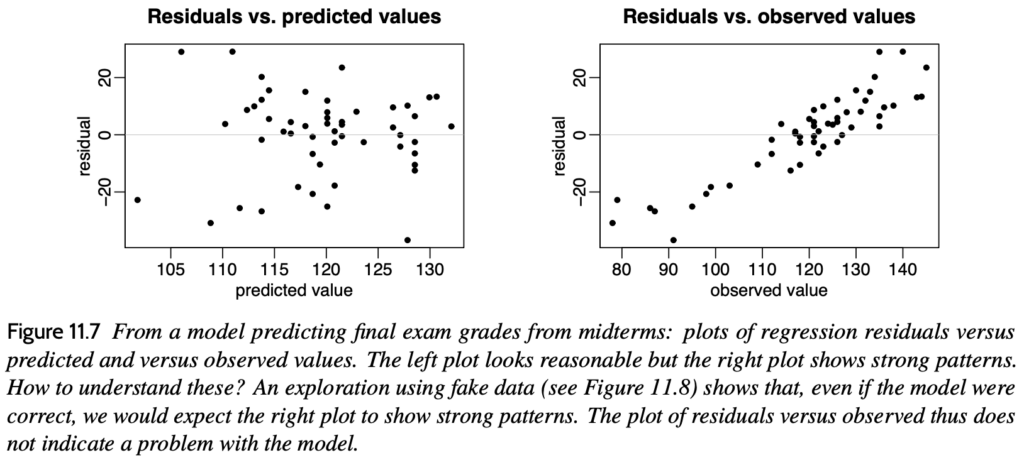
So reagierte ich auf meinen Korrespondenten: Wir diskutieren dies in Abschnitt 11.3 der Regression und anderen Geschichten: „Eine verwirrende Wahl: Verschwindigkeitsreste im Vergleich zu vorhergesagten Werten oder Residuen im Vergleich zu beobachteten Werten?“
Die schnelle Antwort lautet, dass E (y | x) wie eine Regression ist. Und mit einer Regression ist X das, was Sie wissen, und Y ist das, was Sie vorhersagen möchten. Bei beobachteten und vorhergesagten Daten ist die Vorhersage das, was Sie wissen, und der wahre Wert ist das, was Sie nicht wissen, daher ist es sinnvoll, y = true und x = vorhergesagt zu markieren. Eine andere Möglichkeit, es auszudrücken, ist, wenn alles intestine läuft, (wahr | vorhergesagt) = vorhergesagt. Daher sollte die Steigung der angepassten Regressionslinie 1. Equal, E (True – Prognose | vorhergesagt) = 0 sein, weshalb wir Reste im Vergleich zu vorhergesagten, nicht von Residuen im Vergleich zu einem wahren Wert zeichnen. Wir zeigen das in Abschnitt 11.3 auch mit einer Simulation.
Ps Ich habe eine Google -Suche durchgeführt und gefunden Dieses Papier aus dem Jahr 2008 Von Gervasio Piñeiro et al. Das macht den gleichen Punkt. Es hat über 1000 Zitate! Das ist intestine.