Große Sprachmodelle (LLMs) sind über die einfache automatische Vervollständigung hinausgegangen und sagen das nächste Wort oder die nächste Phrase voraus. Jüngste Entwicklungen ermöglichen es LLMs, menschliche Anweisungen zu verstehen und zu befolgen, komplexe Aufgaben auszuführen und sogar Gespräche zu führen. Diese Fortschritte werden durch die Feinabstimmung von LLMs mit speziellen Datensätzen vorangetrieben Verstärkungslernen mit menschlichem Suggestions (RLHF). RLHF definiert neu, wie Maschinen lernen und mit menschlichen Eingaben interagieren.
Was ist RLHF?
RLHF ist eine Technik, die ein großes Sprachmodell trainiert, um seine Ausgaben mithilfe von menschlichem Suggestions an menschliche Vorlieben und Erwartungen anzupassen. Menschen bewerten die Antworten des Modells und geben Bewertungen ab, mit denen das Modell seine Leistung verbessert. Dieser iterative Prozess hilft LLMs, ihr Verständnis menschlicher Anweisungen zu verfeinern und genauere und relevantere Ergebnisse zu generieren. RLHF hat eine entscheidende Rolle bei der Verbesserung der Leistung von gespielt InstructGPTSparrow, Claude und mehr, wodurch sie herkömmliche LLMs wie GPT-3 übertreffen können.
Lassen Sie uns verstehen, wie RLHF funktioniert.
RLHF vs. Nicht-RLHF
Große Sprachmodelle wurden ursprünglich entwickelt, um das nächste Wort oder Token zum Vervollständigen eines Satzes auf der Grundlage der als „Eingabeaufforderung“ bekannten Eingabe vorherzusagen. Um beispielsweise eine Anweisung zu vervollständigen, fordern Sie GPT-3 mit der folgenden Eingabe auf:
Immediate: Vervollständigen Sie den Satz „Menschlicher Enter ermöglicht KI Systeme zum Navigieren in komplexen und nuancierten Szenarien KI könnte damit zu kämpfen haben. Beispielsweise können menschliche Berater im Steuerwesen …….“
Das Modell schließt die Anweisung dann erfolgreich wie folgt ab:
„Menschlicher Enter ermöglicht KI Systeme zum Navigieren in komplexen und nuancierten Szenarien KI könnte damit zu kämpfen haben. Im Steuerwesen können menschliche Berater beispielsweise komplizierte Steuergesetze interpretieren, Ratschläge auf spezifische Kundensituationen zuschneiden und kritisches Denken bei mehrdeutigen Vorschriften anwenden.“

Fragen LLM um eine Eingabeaufforderung fortzusetzen
Von großen Sprachmodellen wird jedoch erwartet, dass sie mehr leisten, als nur eine Eingabeaufforderung zu vervollständigen. LLMs sind erforderlich, um Geschichten, E-Mails, Gedichte, Code und mehr zu schreiben.
RLHF- und Nicht-RLHF-Beispiele
Hier sind einige Beispiele, die den Unterschied zwischen Nicht-RLHF zeigen LLM (Nächster Token-Prädiktor) und RLHF LLM (auf menschliches Suggestions trainiert) Ausgabe.
Nicht-RLHF-Ausgabe – Geschichte
Wenn Sie GPT-3 anweisen, „eine fiktive Geschichte über Prinzessin Anastasia zu schreiben, die sich in einen Soldaten verliebt“, generiert ein Nicht-RLHF-Modell eine Ausgabe wie:
Immediate: Schreiben Sie eine fiktive Geschichte über Prinzessin Anastasia, die sich in einen Soldaten verliebt.
Von großen Sprachmodellen wird jedoch erwartet, dass sie mehr leisten, als nur eine Eingabeaufforderung zu vervollständigen. LLMs sind erforderlich, um Geschichten, E-Mails, Gedichte, Code und mehr zu schreiben.
RLHF- und Nicht-RLHF-Beispiele
Hier sind einige Beispiele, die den Unterschied zwischen Nicht-RLHF zeigen LLM (Nächster Token-Prädiktor) und RLHF LLM (auf menschliches Suggestions trainiert) Ausgabe.
Nicht-RLHF-Ausgabe – Geschichte
Wenn Sie GPT-3 anweisen, „eine fiktive Geschichte über Prinzessin Anastasia zu schreiben, die sich in einen Soldaten verliebt“, generiert ein Nicht-RLHF-Modell eine Ausgabe wie:
Immediate: Schreiben Sie eine fiktive Geschichte über Prinzessin Anastasia, die sich in einen Soldaten verliebt.

Das Modell weiß, wie man Geschichten schreibt, kann die Anfrage jedoch nicht verstehen, da LLMs auf Web-Scrapings trainiert werden, die mit Befehlen wie „Eine Geschichte/E-Mail schreiben“, gefolgt von einer Geschichte oder E-Mail selbst, weniger vertraut sind. Das nächste Wort vorherzusagen unterscheidet sich grundlegend vom intelligenten Befolgen von Anweisungen.
RLHF-Ausgabe – Geschichte
Folgendes erhalten Sie, wenn die gleiche Eingabeaufforderung einem bereitgestellt wird RLHF-Modell trainiert auf menschlichem Suggestions.
Immediate: Schreiben Sie eine fiktive Geschichte über Prinzessin Anastasia, die sich in einen Soldaten verliebt.

Nun, die LLM hat die gewünschte Antwort generiert.
Nicht-RLHF-Ausgang – Mathematik
Immediate: Was ist 4-2 und 3-1?

Das Nicht-RLHF-Modell beantwortet die Frage nicht und betrachtet sie als Teil eines Story-Dialogs.
RLHF-Ausgang – Mathematik
Eingabeaufforderung: Was ist 4-2 und 3-1?

Das RLHF-Modell versteht die Eingabeaufforderung und generiert die Antwort korrekt.
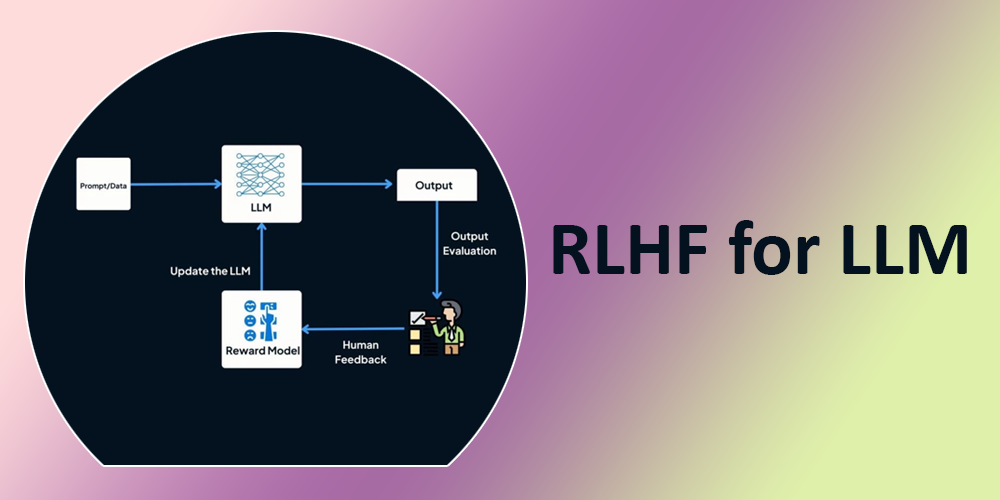
Wie funktioniert RLHF?
Lassen Sie uns verstehen, wie ein großes Sprachmodell auf menschliches Suggestions trainiert wird, um angemessen zu reagieren.
Schritt 1: Beginnen Sie mit vorab trainierten Modellen
Der RLHF-Prozess beginnt mit einem vorab trainierten Sprachmodus oder einem Subsequent-Token-Prädiktor.
Schritt 2: Überwachte Feinabstimmung des Modells
Es werden mehrere Eingabeaufforderungen zu den Aufgaben erstellt, die das Modell ausführen soll, sowie eine von Menschen geschriebene ideale Antwort auf jede Eingabeaufforderung. Mit anderen Worten: Es wird ein Trainingsdatensatz erstellt, der aus
Schritt 3: Erstellen eines Belohnungsmodells für menschliches Suggestions
In diesem Schritt wird ein Belohnungsmodell erstellt, um zu bewerten, wie intestine das ist LLM Die Ausgabe entspricht den Qualitätserwartungen. Wie ein LLMwird ein Belohnungsmodell anhand eines Datensatzes von von Menschen bewerteten Antworten trainiert, die als „Grundwahrheit“ für die Bewertung der Antwortqualität dienen. Wenn bestimmte Ebenen entfernt werden, um es für die Bewertung statt für die Generierung zu optimieren, wird es zu einer kleineren Model von LLM. Das Belohnungsmodell übernimmt die Eingabe und LLM-generierte Antwort als Eingabe und weist der Antwort dann eine numerische Bewertung (eine skalare Belohnung) zu.
Additionally bewerten menschliche Annotatoren das LLM-Generierte Ergebnisse durch Einstufung ihrer Qualität nach Relevanz, Genauigkeit und Klarheit.
Schritt 4: Optimierung mit einem belohnungsgesteuerten Ansatz Verstärkungslernen Politik
Der letzte Schritt im RLHF-Prozess besteht darin, eine RL-Richtlinie zu trainieren (im Wesentlichen ein Algorithmus, der entscheidet, welches Wort oder Token als nächstes in der Textsequenz generiert werden soll), die lernt, Textual content zu generieren, den das Belohnungsmodell vorhersagt, den Menschen bevorzugen würden.
Mit anderen Worten: Die RL-Richtlinie lernt, wie ein Mensch zu denken, indem sie das Suggestions aus dem Belohnungsmodell maximiert.
Auf diese Weise wird ein anspruchsvolles großes Sprachmodell wie ChatGPT erstellt und verfeinert.
Letzte Worte
Große Sprachmodelle haben in den letzten Jahren erhebliche Fortschritte gemacht und tun dies auch weiterhin. Techniken wie RLHF haben dazu geführt modern Modelle wie ChaGPT und Gemini, revolutionierend KI Antworten auf verschiedene Aufgaben. Insbesondere durch die Einbeziehung menschlichen Feedbacks in den Feinabstimmungsprozess sind LLMs nicht nur besser darin, Anweisungen zu befolgen, sondern orientieren sich auch besser an menschlichen Werten und Vorlieben, was ihnen hilft, die Grenzen und Zwecke, für die sie konzipiert sind, besser zu verstehen.
RLHF transformiert große Sprachmodelle (LLMs), indem es ihre Ausgabegenauigkeit und ihre Fähigkeit, menschlichen Anweisungen zu folgen, verbessert. Im Gegensatz zu herkömmlichen LLMs, die ursprünglich dazu konzipiert waren, das nächste Wort oder Token vorherzusagen, nutzen RLHF-trainierte Modelle menschliches Suggestions, um Antworten zu verfeinern und die Antworten an den Benutzerpräferenzen auszurichten.
Zusammenfassung: RLHF transformiert große Sprachmodelle (LLMs), indem es ihre Ausgabegenauigkeit und ihre Fähigkeit, menschlichen Anweisungen zu folgen, verbessert. Im Gegensatz zu herkömmlichen LLMs, die ursprünglich dazu konzipiert waren, das nächste Wort oder Token vorherzusagen, nutzen RLHF-trainierte Modelle menschliches Suggestions, um Antworten zu verfeinern und die Antworten an den Benutzerpräferenzen auszurichten.
Der Beitrag Wie RLHF die Genauigkeit und Wirksamkeit von LLM-Antworten verändert erschien zuerst auf Datenfloq.