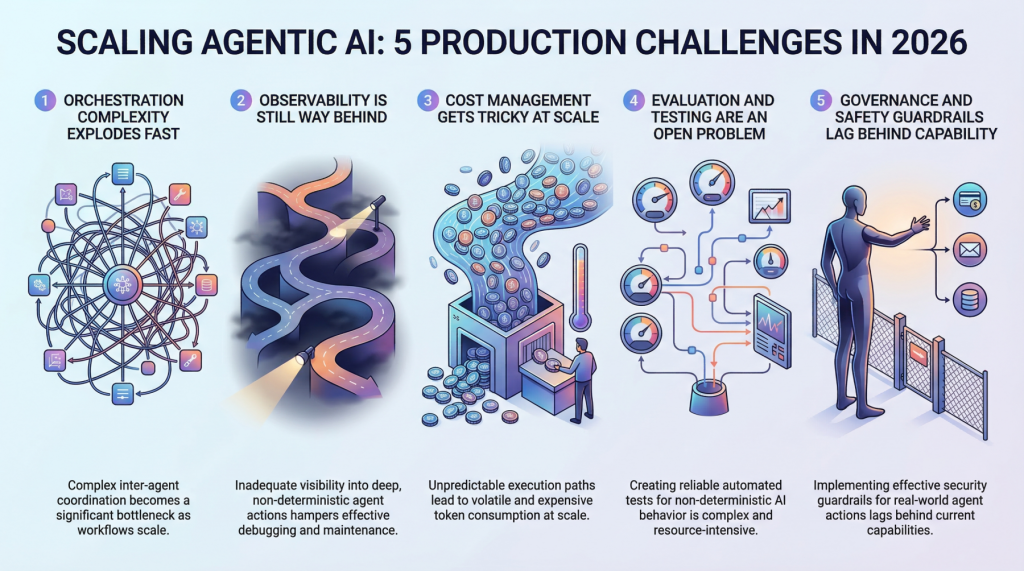
In diesem Artikel erfahren Sie mehr über fünf große Herausforderungen, denen sich Groups bei der Skalierung von Agenten-KI-Systemen vom Prototyp bis zur Produktion im Jahr 2026 gegenübersehen.
Zu den Themen, die wir behandeln werden, gehören:
- Warum die Orchestrierungskomplexität in Multiagentensystemen schnell zunimmt.
- Wie schwierig Beobachtbarkeit, Bewertung und Kostenkontrolle in Produktionsumgebungen bleiben.
- Warum Governance- und Sicherheitsleitplanken immer wichtiger werden, wenn Agentensysteme reale Maßnahmen ergreifen.
Verschwenden wir keine Zeit mehr.
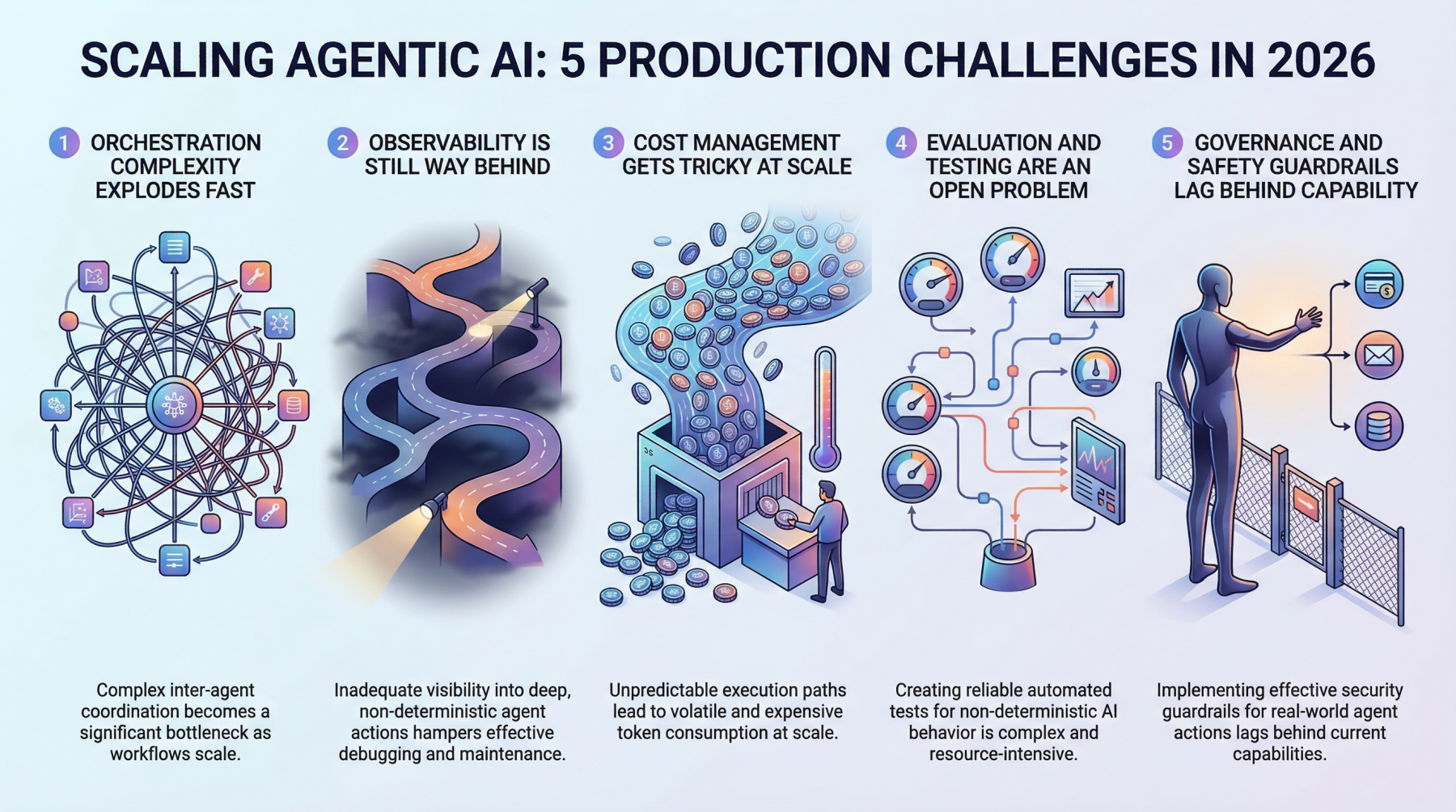
5 Herausforderungen bei der Produktionsskalierung für Agentische KI im Jahr 2026
Bild vom Herausgeber
Einführung
Jedermanns Wir bauen derzeit Agenten-KI-Systeme aufim Guten wie im Schlechten. Die Demos sehen unglaublich aus, die Prototypen fühlen sich magisch an und die Pitch-Decks schreiben sich praktisch von selbst.
Aber darüber twittert niemand: Diese Dinge tatsächlich im großen Maßstab, in der Produktion, mit echten Benutzern und echten Einsätzen zum Laufen zu bringen, ist ein völlig anderes Spiel. Die Kluft zwischen einer raffinierten Demo und einem zuverlässigen Produktionssystem gab es beim maschinellen Lernen schon immer, aber die Agenten-KI reicht noch weiter als alles, was wir bisher gesehen haben.
Diese Systeme treffen autonom Entscheidungen, ergreifen Maßnahmen und verketten komplexe Arbeitsabläufe. Das ist mächtig, und es ist auch erschreckend, wenn die Dinge im großen Maßstab schiefgehen. Sprechen wir additionally über die fünf größten Probleme, mit denen Groups konfrontiert sind, wenn sie versuchen, die Agenten-KI im Jahr 2026 zu skalieren.
1. Die Komplexität der Orchestrierung explodiert schnell
Wenn ein einzelner Agent eine begrenzte Aufgabe übernimmt, scheint die Orchestrierung überschaubar zu sein. Sie definieren einen Workflow, Setzen Sie einige Leitplankenund die Dinge verhalten sich meistens. Aber Produktionssysteme bleiben selten so einfach. Sobald Sie Multi-Agent-Architekturen einführen, in denen Agenten an andere Agenten delegieren, fehlgeschlagene Schritte wiederholen oder dynamisch auswählen, welche Instruments aufgerufen werden sollen, sind Sie dabei Umgang mit Orchestrierungskomplexität das wächst quick exponentiell.
Groups stellen fest, dass der Koordinationsaufwand zwischen Agenten zum Flaschenhals wird und nicht die einzelnen Modellaufrufe. Es gibt Agenten, die auf andere Agenten warten, Race Situations, die in asynchronen Pipelines auftauchen, und kaskadierende Fehler, die in Staging-Umgebungen wirklich schwer zu reproduzieren sind. Traditionelle Workflow-Engines waren nicht für dieses Maß an dynamischer Entscheidungsfindung konzipiertund die meisten Groups erstellen am Ende benutzerdefinierte Orchestrierungsebenen, die schnell zum am schwierigsten zu verwaltenden Teil des gesamten Stacks werden.
Der eigentliche Clou ist, dass sich diese Systeme unter Final unterschiedlich verhalten. Ein Orchestrierungsmuster, das bei 100 Anfragen professional Minute wunderbar funktioniert kann bei 10.000 völlig auseinanderfallen. Um diese Lücke zu schließen, ist eine Artwork Systemdenken erforderlich, das die meisten Groups für maschinelles Lernen noch entwickeln.
2. Die Beobachtbarkeit liegt immer noch weit zurück
Man kann nicht reparieren, was man nicht sieht, und derzeit können die meisten Groups nicht annähernd genug sehen, was ihre Agentensysteme in der Produktion tun. Die herkömmliche Überwachung durch maschinelles Lernen verfolgt Dinge wie Latenz, Durchsatz und Modellgenauigkeit. Diese Kennzahlen sind immer noch wichtig, kratzen aber kaum an der Oberfläche der Agenten-Workflows.
Wenn ein Agent einen 12-stufigen Weg beschreitet, um eine Benutzeranfrage zu beantworten, müssen Sie jeden Entscheidungspunkt auf dem Weg verstehen. Warum wurde Werkzeug A gegenüber Werkzeug B ausgewählt? Warum wurde Schritt 4 dreimal wiederholt? Warum hat die endgültige Ausgabe völlig das Ziel verfehlt, obwohl jeder Zwischenschritt intestine aussah? Die Nachverfolgungsinfrastruktur für diese Artwork der tiefen Beobachtbarkeit ist noch unausgereift. Die meisten Groups stellen eine Kombination aus LangSmith, benutzerdefinierter Protokollierung und viel Hoffnung zusammen.
Was macht es schwieriger? ist, dass Agentenverhalten von Natur aus nicht deterministisch ist. Die gleiche Eingabe kann völlig unterschiedliche Ausführungspfade erzeugen, was bedeutet, dass Sie nicht einfach einen Fehler erfassen und ihn zuverlässig wiedergeben können. Der Aufbau einer robusten Beobachtbarkeit für Systeme, die von Natur aus unvorhersehbar sind, bleibt eines der größten ungelösten Probleme in diesem Bereich.
3. Das Kostenmanagement wird im großen Maßstab schwierig
Hier ist etwas, das viele Groups überrascht: Der Betrieb von Agentensystemen ist teuer. Normalerweise jede Agentenaktion umfasst einen oder mehrere LLM-Aufrufeund wenn Agenten Dutzende Schritte professional Anfrage verketten, summieren sich die Token-Kosten erschreckend schnell. Ein Workflow, der 0,15 $ professional Ausführung kostet, klingt intestine, bis Sie 500.000 Anfragen professional Tag bearbeiten.
Intelligente Groups werden bei der Kostenoptimierung kreativ. Sie leiten einfachere Teilaufgaben an kleinere, günstigere Modelle weiter, während sie die Schwergewichte für komplexe Argumentationsschritte reservieren. Sie speichern Zwischenergebnisse aggressiv zwischen und bauen Kill-Switches ein, die außer Kontrolle geratene Agentenschleifen beenden, bevor sie das Price range sprengen. Es besteht jedoch ein ständiges Spannungsverhältnis zwischen Kosteneffizienz und Ausgabequalität, und um das richtige Gleichgewicht zu finden, sind ständige Experimente erforderlich.
Die Unvorhersehbarkeit der Abrechnung ist es, was die technischen Leiter wirklich belastet. Im Gegensatz zu herkömmlichen APIs, bei denen Sie die Kosten ziemlich genau abschätzen können, ist dies bei Agentensystemen der Fall Variable Ausführungspfade, die eine Kostenprognose wirklich erschweren. Ein Grenzfall kann eine Kette von Wiederholungsversuchen auslösen, die 50-mal mehr kostet als der normale Pfad.
4. Bewertung und Check sind ein offenes Downside
Wie testet man ein System, das bei jedem Betrieb einen anderen Weg einschlagen kann? Das ist die Frage, die Ingenieure des maschinellen Lernens schlaflose Nächte bereitet. Herkömmliche Softwaretests gehen von deterministischem Verhalten aus und Bei der herkömmlichen maschinellen Lernauswertung wird eine feste Eingabe-Ausgabe-Zuordnung vorausgesetzt. Agentische KI durchbricht beide Annahmen gleichzeitig.
Die Groups experimentieren mit verschiedenen Ansätzen. Manche bauen LLM-als-Richter-Pipelines auf bei dem ein separates Modell die Ausgaben des Agenten auswertet. Andere erstellen szenariobasierte Testsuiten, die eher auf Verhaltenseigenschaften als auf exakte Ergebnisse prüfen. Einige investieren in Simulationsumgebungen, in denen Agenten anhand tausender synthetischer Szenarien einem Stresstest unterzogen werden können, bevor sie in Produktion gehen.
Aber noch keiner dieser Ansätze fühlt sich wirklich ausgereift an. Die Bewertungstools sind fragmentiert, Benchmarks sind inkonsistent und es besteht kein Branchenkonsens darüber, wie „intestine“ für einen komplexen Agenten-Workflow überhaupt aussieht. Die meisten Groups verlassen sich am Ende stark auf die menschliche Überprüfung, was offensichtlich nicht skalierbar ist.
5. Governance- und Sicherheitsleitplanken bleiben hinter den Fähigkeiten zurück
Agentische KI-Systeme können reale Aktionen in der realen Welt durchführen. Sie können E-Mails versenden, Datenbanken ändern, Transaktionen ausführen und mit externen Diensten interagieren. Die Auswirkungen dieser Autonomie auf die Sicherheit sind erheblichund Governance-Frameworks haben mit der Geschwindigkeit, mit der diese Funktionen bereitgestellt werden, nicht Schritt gehalten.
Die Herausforderung besteht darin, Leitplanken zu implementieren, die sturdy genug sind, um schädliche Aktionen zu verhindern, ohne jedoch so restriktiv zu sein, dass sie den Nutzen des Agenten zunichte machen. Es ist ein heikles Gleichgewicht, und die meisten Groups lernen durch Versuch und Irrtum. Berechtigungssysteme, Aktionsgenehmigungsworkflowsund Umfangsbeschränkungen sorgen für zusätzliche Spannungen, die den Sinn und Zweck eines autonomen Agenten überhaupt untergraben können.
Auch der regulatorische Druck nimmt zu. Da Agentensysteme beginnen, Entscheidungen zu treffen, die sich direkt auf Kunden auswirken, werden Fragen zu Verantwortlichkeit, Überprüfbarkeit und Compliance immer dringlicher. Groups, die jetzt nicht über Governance nachdenken, werden an schmerzhafte Grenzen stoßen, wenn die Vorschriften aufholen.
Letzte Gedanken
Agentische KI ist wirklich transformativ, aber der Weg vom Prototyp bis zur maßstabsgetreuen Produktion ist mit Herausforderungen übersät, die die Branche immer noch in Echtzeit bewältigt.
Die gute Nachricht ist, dass das Ökosystem schnell reift. Bessere Instruments, klarere Muster und hart erkämpfte Lehren von Early Adopters machen den Weg jeden Monat ein wenig einfacher.
Wenn Sie gerade Agentensysteme skalieren, sollten Sie sich darüber im Klaren sein, dass der Schmerz, den Sie verspüren, universell ist. Die Groups, die frühzeitig in die Lösung dieser grundlegenden Probleme investieren, sind diejenigen, die Systeme aufbauen, die tatsächlich standhalten, wenn es darauf ankommt.